

AI바라기의 인공지능
world model : 논문 리뷰 : Hierarchical Planning with Latent World Models 본문
용어 설명
- Latent World Models: High-dimensional observations (예: pixels)을 압축된 저차원 latent space로 변환하여, 환경의 미래 dynamics를 예측하는 딥러닝 모델.
- Model Predictive Control (MPC): 현재 상태에서 미래 일정 구간(horizon) 동안의 결과를 모델을 통해 시뮬레이션하고, 최적의 action sequence를 탐색해 첫 번째 action만 실행한 뒤 다시 계획을 반복하는 제어 기법.
- Non-greedy task: 단순히 최종 목표 지점을 향해 직진하는 것(greedy)으로는 해결할 수 없고, 물건을 집기 위해 위로 올라갔다가 다시 내려오는 등 일시적으로 목표와 멀어지는 복잡한 action sequence가 필수적인 task.
- Latent macro-action: 여러 스텝의 primitive action(미세 조정 행동)들을 하나의 추상적인 고차원 벡터로 압축한 행동 표현. 고위 계층(high-level)의 탐색 공간을 극적으로 줄여줌.
- Subgoal matching: 별도의 inverse model이나 reward 없이, high-level planner가 예측한 미래의 latent state를 low-level planner가 도달해야 할 중간 목표(subgoal)로 직접 연동하는 방식.
Purpose of the Paper
- 기존 연구의 한계: Learned world models를 이용한 planning은 매 스텝 예측을 반복하면서 compounding prediction errors (오차 누적)가 발생하고, 탐색 공간이 기하급수적으로 커져 long-horizon 제어에 치명적으로 실패함. 대안인 Hierarchical RL은 task-specific reward에 의존해 zero-shot 일반화가 불가능하며, Hierarchical MPC는 low-dimensional state나 알려진 dynamics 환경에만 국한됨.
- 제안하는 접근 방식: Reward나 추가적인 policy 학습 없이, task-agnostic하게 사전 학습된 latent world models 위에 inference 시점에서의 temporal hierarchy를 직접 부여하는 HWM (Hierarchical Planning with Latent World Models) 프레임워크를 제안. 고해상도 pixels 환경에서도 zero-shot으로 long-horizon 및 non-greedy 제어가 가능하도록 만드는 범용적 구조를 고안함.
Key Contributions
- Task-agnostic Hierarchical MPC in Latent Space (참신성): Reward 기반의 Hierarchical RL과 달리, 순수하게 데이터의 next-latent prediction으로만 학습된 두 개의 world model (high/low-level)을 사용하여 zero-shot planning을 구현함. 특정 task에 종속되지 않는 범용성을 확보함.
- Latent Action Encoder 도입 (기여도): 가변적인 길이의 primitive action sequence를 단일 latent macro-action으로 압축하는 encoder를 학습. 이를 통해 high-level planner의 search space를 획기적으로 줄여 연산 복잡도를 낮춤.
- Direct Subgoal Matching Interface (참신성): High-level 모델의 예측 결과를 별도의 가공이나 skill 학습 없이, 즉각적으로 low-level MPC의 목표(subgoal) 벡터로 사용하는 심플하고 강력한 결합 구조를 제시함.
- Model-Agnostic Plug-in Architecture (기여도): HWM이 VJEPA2-AC, DINO-WM, PLDM 등 서로 전혀 다른 구조를 가진 기존의 단일 계층 latent world models에 그대로 결합되어 즉각적인 성능 향상을 이끌어낼 수 있는 모듈식 추상화 기법임을 증명함.
Experimental Highlights
- Real-World Non-greedy Control (Franka Arm Dataset):
- Subgoal 없이 오직 최종 goal image만 주어진 상황에서 단일 계층 planner는 Pick-and-Place 성공률 0%를 기록했으나, HWM은 70%의 성공률을 달성함.
- 약 77배 더 많은 로봇 데이터로 학습된 최신 VLA (Vision-Language-Action) 모델인 Octo, pi0-FAST-DROID의 성능을 크게 압도함.
- Long-horizon Reasoning (Push-T Simulated Env):
- Task horizon을 75스텝까지 확장한 극한의 테스트에서 기존 DINO-WM(flat planner)은 성공률이 17%로 급락한 반면, HWM은 61%의 강건한 방어력을 보여줌.
- Compute Efficiency:
- Push-T 및 Diverse Maze 환경 모두에서, HWM은 flat planner 대비 3배에서 4배 적은 inference-time compute (planning 연산 시간)를 사용하면서도 더 높은 성공률을 기록함.
- Ablation Study (Macro-action의 효과): 단순히 시작-끝 위치의 차이(delta-pose)를 high-level action으로 쓰는 것보다, 행동 시퀀스 전체의 맥락을 압축한 latent macro-action을 학습시켜 사용할 때 expert trajectory와의 코사인 유사도(alignment)가 훨씬 높게 나타남.
Limitations and Future Work
- Limitations (한계점):
- Strictly top-down decomposition: High-level planner가 달성 불가능한 subgoal을 내려주거나 low-level planner가 실패했을 때, 이를 상위 계층에 피드백하여 즉각적으로 계획을 수정하는 메커니즘이 부재함.
- Extreme Horizons & Stochasticity: Horizon이 극단적으로 길어질 경우 성능 저하를 완전히 피할 수 없으며, real-world 특유의 높은 확률적 불확실성(stochasticity)을 완벽히 다루지 못함.
- Future Work (향후 연구 방향):
- 계층 간에 실패 정보와 피드백이 오갈 수 있는 양방향 상호작용 (feedback and interaction across levels) 알고리즘 개발을 통해 시스템의 강건성을 극대화해야 함.
- Long-horizon의 불확실성을 모델에 반영하는 uncertainty-aware planning과 더 추상화된 high-level representation 연구가 필요함.
Overall Summary
이 논문은 pixels 기반의 learned world models가 필연적으로 겪는 compounding errors와 search space 폭발 문제를 해결하기 위해, inference 타임에 동작하는 계층적 구조인 HWM을 제안했습니다. Reward나 policy 학습에 의존하지 않고 두 가지 시간 척도(temporal scales)의 world model을 결합함으로써, 복잡하고 non-greedy한 로봇 조작 임무를 오직 단일 goal image만으로 zero-shot 해결하는 데 성공했습니다. 연산량은 크게 줄이면서 기존 SOTA vision-language 모델들을 압도하는 성능을 보여주었으며, 이는 비지도 학습 기반의 world model이 향후 강력한 범용 인공지능 제어기(general-purpose controller)로 도약하는 데 필수적인 방법론을 제시했다는 큰 의의를 가집니다.
쉬운 설명
낯선 도시에서 목적지까지 운전해서 간다고 상상해 보세요.
매 순간순간의 '핸들 각도'와 '엑셀 밟는 양' (Primitive actions)을 목적지에 도착할 때까지 미리 전부 다 계산(Flat planning)하려고 하면, 머리가 터질 듯이 복잡해지고 중간에 장애물 하나만 나타나도 계획이 완전히 망가집니다.
이 논문이 제안한 HWM 방식은 우리가 실제로 길을 찾는 방식과 같습니다.
- 먼저 큰 지도(High-level world model)를 보고 "고속도로 톨게이트 진입", "시청 앞 교차로" 같은 큰 단위의 중간 목적지(Subgoals)와 큼직한 이동 경로(Latent macro-actions)를 짭니다.
- 그런 다음, 운전대(Low-level planner)를 잡고 당장 눈앞에 보이는 '고속도로 톨게이트'까지만 차선을 유지하며 세밀하게 조작합니다.
이렇게 역할과 시야를 두 계층으로 나누었기 때문에, 인공지능은 연산량을 획기적으로 줄이면서도 중간에 뒤로 후진해야 하는 등 복잡한 상황(Non-greedy task)을 처음 보는 환경(Zero-shot)에서도 능숙하게 해결할 수 있게 되었습니다.
Abstract
learned world models를 활용한 Model predictive control (MPC)은 새로운 환경에 배포될 때 zero-shot으로 generalize하는 능력 덕분에 embodied control을 위한 유망한 패러다임으로 부상했습니다.
그러나 learned world models는 prediction errors의 누적과 기하급수적으로 커지는 search space로 인해 long-horizon control에서 종종 어려움을 겪습니다.
본 연구에서는 여러 temporal scales에 걸쳐 latent world models를 학습하고 이를 바탕으로 hierarchical planning을 수행하여 이러한 문제들을 해결합니다. 이를 통해 inference-time의 planning complexity를 크게 줄이면서도 long-horizon reasoning을 가능하게 합니다.
우리의 접근 방식은 다양한 latent world-model architectures와 domains에 범용적으로 적용할 수 있는 plug-in planning abstraction으로 기능합니다.
우리는 이 hierarchical approach가 실제 환경의 non-greedy robotic tasks에서 zero-shot control을 가능하게 한다는 것을 입증했습니다. 구체적으로 single-level world model이 0%의 성공률을 보인 것에 비해, 우리의 방법은 final goal specification만을 사용하여 pick-&-place 작업에서 70%의 성공률을 달성했습니다.
추가적으로 push manipulation과 maze navigation을 포함한 physics-based simulated environments 전반에서, hierarchical planning은 planning-time compute를 최대 3배 적게 요구하면서도 더 높은 성공률을 달성합니다.
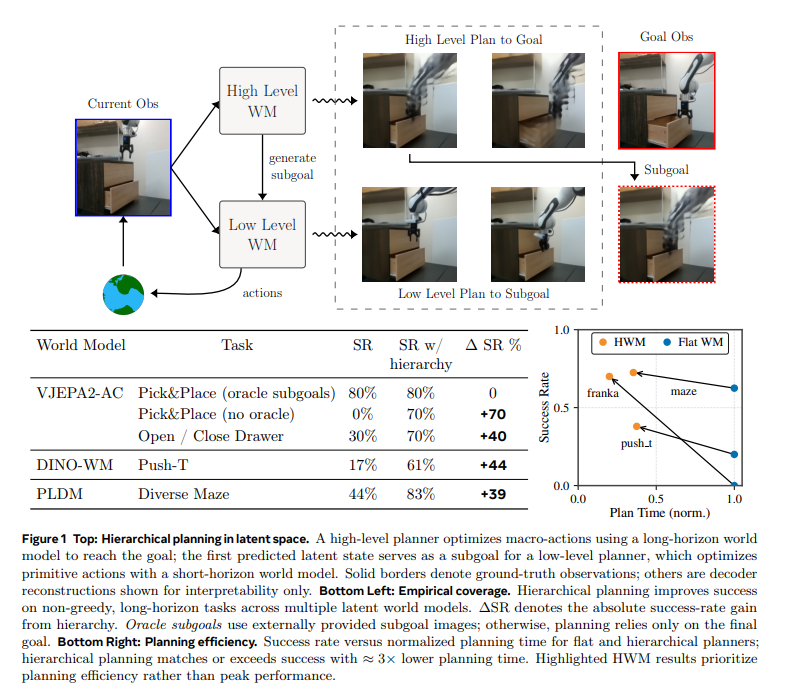
Figure 1: Hierarchical planning in latent space 구조 및 실험 결과
이 이미지는 HWM이 실제로 어떻게 작동하는지 보여주는 개념도와, 이를 통해 얻은 성능 향상 결과를 요약하고 있습니다.
- 상단 다이어그램 (개념도): 로봇이 서랍을 여는 Pick&Place 작업을 예시로 보여줍니다. Current Obs(현재 관측된 이미지)가 High Level WM과 Low Level WM 두 곳으로 동시에 들어갑니다. High Level WM은 최종 목표(Goal Obs)를 달성하기 위해 듬성듬성한 거시적 계획(High Level Plan to Goal)을 세우고, 이 중 첫 번째로 예측된 상태를 Subgoal로 만들어 Low Level WM에 전달합니다. 그러면 Low Level WM은 이 Subgoal에 도달하기 위한 아주 촘촘하고 세밀한 행동들(Low Level Plan to Subgoal)을 계획하여 실제 actions를 수행합니다.
- 좌측 하단 표 (성능 향상): 기존 단일 계층(Flat WM) 방식과 계층적 구조를 도입한 방식의 Success Rate(SR, 성공률)를 비교합니다. 외부에서 정답 형태의 Subgoal을 주지 않은 Pick&Place (no oracle) 작업의 경우 기존 0%였던 성공률이 70%로 급격히 상승했습니다. 또한 DINO-WM이나 PLDM 같은 다양한 형태의 world model 구조에서도 일관되게 큰 폭의 성능 향상($\Delta$ SR)을 이뤄냈습니다.
- 우측 하단 그래프 (계획 효율성): x축은 Plan Time(계획에 소요된 시간), y축은 Success Rate입니다. 주황색 점(HWM)들이 파란색 점(Flat WM)들보다 좌측 상단에 위치한 것을 볼 수 있습니다. 이는 계층적 계획 방식을 도입하면 계산 시간은 약 3배가량 크게 줄어들면서도 목표 달성 성공률은 훨씬 높아진다는 것을 명확히 보여줍니다.

Figure 2: HWM의 세부 연산 그래프 (Computational Graph)
이 다이어그램은 두 개의 world model이 latent space 안에서 구체적으로 어떻게 최적화되고 상호작용하는지 수식적인 흐름으로 보여줍니다.
- High-Level Planning (상단 흐름): 먼저 초기 상태 $s_1$과 최종 목표 이미지 $s_{\text{goal}}$이 인코더 $E$를 통과하여 각각 압축된 형태인 $z_1$과 $z_{\text{goal}}$로 변환됩니다. High-level world model인 $P^{(2)}$는 이 $z_1$에서 출발하여 거시적인 macro-actions인 $l_{t_1}, l_{t_2}$ 등을 연속적으로 입력받아 먼 미래의 상태들인 $\hat{z}_{t_2}, \dots, \hat{z}_H$를 예측합니다. 이때 마지막으로 예측한 $\hat{z}_H$가 최종 목표 $z_{\text{goal}}$과 최대한 같아지도록 오차인 $\mathcal{L}_{\text{high}}$를 최소화하는 방향으로 전체 계획이 세워집니다.
- Low-Level Planning (하단 흐름): 이번에는 Low-level world model인 $P^{(1)}$이 동일한 $z_1$에서 출발하여, 아주 세밀한 primitive actions인 $a_1, \dots, a_h$를 입력받아 가까운 미래의 상태 $\hat{z}_h$를 예측합니다. 여기서 가장 중요한 점은 상단 흐름에서 예측했던 첫 번째 미래 상태인 $\hat{z}{t_2}$가 하단 흐름의 Subgoal로 바로 사용된다는 것입니다. 예측된 $\hat{z}_h$가 이 Subgoal에 도달할 수 있도록 오차인 $\mathcal{L}{\text{low}}$를 최소화하며 당장 실행할 세부 actions를 결정하게 됩니다.
1 Introduction
learned world models를 활용한 Planning은 embodied decision making을 위한 강력한 패러다임으로 부상했습니다. 경험을 통해 environment dynamics의 predictive models를 학습하고 이를 사용하여 미래의 outcomes를 시뮬레이션함으로써, world models는 agents가 actions의 장기적인 결과에 대해 reasoning 할 수 있게 해줍니다. representation learning과 latent-space modeling의 최근 발전은 이 방식의 확장성을 향상시켰으며, 이미지와 비디오 같은 high-dimensional observations로부터 직접 world models를 train하는 것을 가능하게 만들었습니다. 더 최근에는 self-supervised learning을 통해 레이블이 없고 task-agnostic한 offline trajectories의 대규모 컬렉션에서 world models를 training하는 것이 가능해졌으며, downstream robotic control 및 navigation에서 zero-shot 배포를 허용합니다. 이러한 진전에도 불구하고, learned world models는 두 가지 근본적인 문제로 인해 long-horizon control에서 계속해서 어려움을 겪고 있습니다: (i) 시간이 지남에 따라 prediction errors가 누적되어 점점 더 부정확한 rollouts이 발생하며, (ii) 완벽한 model 하에서도 horizon에 따라 search space가 기하급수적으로 커짐에 따라 planning의 계산 비용이 비싸집니다.
long-horizon control에 대한 고전적인 접근 방식은 의사 결정 구조에 hierarchy를 도입하는 것입니다. 여러 temporal scales에서 reasoning 함으로써, agents는 짧은 horizons에서의 fine-grained control을 유지하면서 긴 horizons에 걸쳐 coarsely하게 plan을 세울 수 있습니다. 이러한 직관은 reinforcement learning의 temporal abstraction에 대한 많은 연구(options, skills, hierarchical policies 포함)뿐만 아니라 여러 timescales에서 dynamics를 포착하는 hierarchical world models의 기반이 됩니다. 이와 병행하여, optimal control 문헌에서는 multi-task 설정을 위한 hierarchical model predictive control (MPC)를 탐구해 왔습니다. 그러나 이러한 접근 방식들은 상호 보완적인 방식으로 여전히 제한적입니다. Reinforcement learning methods는 일반적으로 task-specific rewards에 의존하는데, 이는 zero-shot 설정에서의 적용 가능성을 제한합니다; goal-conditioned 및 zero-shot RL methods조차도 training distribution을 넘어서는 환경 및 tasks에 generalize하는 데 여전히 어려움을 겪습니다. 반대로, 기존의 hierarchical MPC methods는 task-specific하지는 않지만 주로 low-dimensional state spaces, hand-engineered representations 또는 알려진 dynamics로 제한되어 있어 raw pixels와 같은 high-dimensional observation spaces에 대한 적용 가능성이 제한됩니다. 결과적으로, high-dimensional observations로부터 learned world models에서 직접 zero-shot control을 위한 hierarchical planning을 실현하는 방법은 여전히 불분명합니다.
본 연구에서는 learned latent world models를 사용하여 zero-shot hierarchical model predictive control을 위한 프레임워크인 Hierarchical Planning with Latent World Models (HWM)를 제안합니다. hierarchical policies를 학습하는 대신, HWM은 next-latent prediction을 통해 trained된 task-agnostic world models에서 여러 timescales에 걸쳐 planning을 수행함으로써 inference time에 직접 temporal hierarchy를 도입합니다. 결정적으로 우리의 접근 방식은 hierarchical levels이 어떻게 상호 작용하는지에 의해 정의됩니다. HWM은 shared latent space 내에서 다양한 temporal resolutions로 작동하는 world models를 학습하여 levels 간의 직접적인 결합을 가능하게 합니다: high-level predictions는 latent-state matching을 통해 low-level MPC의 subgoals 역할을 합니다. 이는 inverse models, skill learning 또는 goal-conditioned policies의 필요성을 제거하고 hierarchical planning이 전적으로 pretrained world models에서 작동할 수 있게 합니다. 효율적인 long-horizon planning을 지원하기 위해, waypoint states 사이의 primitive actions의 sequences를 latent macro-actions로 압축하는 learned action encoder를 추가로 도입합니다. 이는 high-level search space의 dimensionality를 줄이고 planning을 더 다루기 쉽게 만듭니다. long-horizon reasoning을 fine-grained control에서 분리함으로써, HWM은 error accumulation을 완화하고 전반적인 planning complexity를 줄입니다.
우리의 기여는 다음과 같이 요약할 수 있습니다:
- 우리는 shared latent space를 통해 여러 learned world models를 결합하는 hierarchical MPC 프레임워크인 HWM을 제안하며, hierarchical policies, skill learning 또는 task-specific rewards 없이 levels 간의 직접적인 subgoal transfer를 가능하게 합니다.
- 우리는 HWM이 zero-shot world-model planning을 위한 새로운 기능을 실현한다는 것을 보여줍니다: 시각적 입력으로부터 non-greedy real-robot tasks를 해결하는 것으로, 성공을 위해서는 일시적으로 목표에서 멀어지는 것이 필요합니다. HWM은 단일 목표 이미지로부터 Franka pick-&-place에서 70%의 성공률을 달성했으며(VJEPA2-AC의 0%와 비교), 약 77배 더 많은 robotic interaction data로 trained된 강력한 vision-language-action models보다 뛰어난 성능을 보였습니다.
- 우리는 HWM이 VJEPA2-AC (robot manipulation), DINO-WM (push manipulation) 및 PLDM (maze navigation)을 포함한 다양한 latent world models에서 일관되게 zero-shot performance를 향상시키는 모듈식의 model-agnostic planning abstraction임을 입증합니다.
- 우리는 hierarchical planning이 long-horizon tasks에서 성능과 효율성을 모두 향상시킨다는 것을 보여줍니다. 구체적으로 상당한 success-rate 향상(최대 +44% 및 +39%)을 달성하면서 동시에 single-level planners에 비해 inference-time planning 비용을 최대 4배까지 절감합니다.
Introduction 핵심 정리 노트
연구 배경 및 한계점 (Problem Statement)
- 현재의 한계: learned world models는 high-dimensional observations (이미지, 비디오 등) 기반의 zero-shot 배포에 강점이 있으나, long-horizon control에서는 두 가지 치명적 약점을 가집니다.
- 시간이 지날수록 누적되는 prediction errors.
- horizon이 길어질수록 기하급수적으로 팽창하는 search space로 인한 연산량 폭발.
- 기존 방법론의 맹점:
- Hierarchical RL: task-specific rewards나 goal-conditioned policies에 의존하여 zero-shot generalization에 취약합니다.
- Hierarchical MPC: task-agnostic하지만, low-dimensional state spaces나 수작업 representation에 국한되어 raw pixels와 같은 환경에 적용이 불가합니다.
제안 방법론: HWM (Hierarchical Planning with Latent World Models) 이 논문은 learned latent world models 상에서 직접 작동하는 zero-shot hierarchical MPC 프레임워크인 HWM을 제안합니다.
- 핵심 메커니즘:
- Inference-time Hierarchy: 별도의 hierarchical policies를 학습하는 것이 아니라, next-latent prediction으로 학습된 task-agnostic world models를 활용해 추론 단계에서 직접 temporal hierarchy를 부여합니다.
- Shared Latent Space Coupling (가장 중요): 서로 다른 temporal resolutions를 가진 world models가 하나의 shared latent space를 공유합니다. 이를 통해 high-level predictions가 별도의 inverse models나 skill learning 없이 latent-state matching을 통해 low-level MPC의 subgoals로 직접 작동합니다.
- Learned Action Encoder: primitive actions의 시퀀스를 latent macro-actions로 압축하여 high-level search space의 차원을 획기적으로 줄이고 planning을 효율적으로 만듭니다.
주요 기여 및 실험 결과 (Key Contributions)
- Non-greedy real-robot tasks 해결: 시각적 입력만으로 일시적으로 목표에서 멀어져야 하는 복잡한 작업을 zero-shot으로 해결합니다. (단일 목표 이미지 프롬프트만으로 Franka pick-&-place에서 70% 성공률 달성, baseline은 0% 및 77배 더 많은 데이터로 학습된 VLA models 압도).
- Model-agnostic Plug-in: VJEPA2-AC, DINO-WM, PLDM 등 다양한 latent world models에 범용적으로 결합되어 성능을 일관되게 향상시킵니다.
- Efficiency & Performance: single-level planners 대비 success-rate를 최대 44% 향상시키면서도, inference-time planning 연산 비용은 최대 4배 절감합니다.
쉬운 설명 : Introduction 섹션
우리가 서울에서 부산까지 직접 운전해서 간다고 상상해 봅시다.
기존의 world models (AI가 세상의 법칙을 시뮬레이션하는 모델)가 가진 문제는, 서울에서 부산까지 가는 **수만 번의 운전대 조작과 페달 밟기(low-level)**를 처음부터 끝까지 한 번에 다 계획하려고 한다는 것입니다. 이렇게 하면 중간에 차선 하나만 잘못 예측해도 뒤로 갈수록 오차가 눈덩이처럼 불어나고(prediction errors 누적), 머릿속으로 계산해야 할 경우의 수가 우주 폭발 수준으로 많아집니다(search space 팽창).
그래서 사람들은 보통 계층적(Hierarchical) 계획을 세웁니다. "일단 서울 톨게이트를 지나서, 대전 IC를 거쳐, 부산으로 가자!" 이게 High-level 계획입니다. 그리고 막상 운전할 때는 당장 내 앞에 있는 차와의 간격을 조절하는 데 집중하죠. 이게 Low-level 제어입니다.
이 논문이 제안하는 HWM이 바로 이 사람의 방식을 AI에게 그대로 적용한 것입니다.
하지만 이 논문이 정말 획기적인 이유는 이 두 계층을 연결하는 방식에 있습니다. 보통 AI에게 큰 계획(대전 가기)과 작은 계획(핸들 꺾기)을 연결해주려면 목적지마다 보상(reward)을 주거나 복잡한 연결 기술을 따로 가르쳐야 했습니다. 하지만 HWM은 두 모델이 **같은 상상 속 공간(shared latent space)**을 공유하게 만들었습니다.
즉, 큰 계획을 짜는 AI가 "다음은 대전 IC의 모습이야"라고 상상(high-level prediction)하면, 작은 계획을 짜는 AI가 그 상상된 이미지를 그대로 자신의 단기 목표(subgoals)로 삼아서 당장의 핸들 조작(low-level MPC)을 해내는 것입니다.
결과적으로 복잡한 추가 학습 없이, 로봇이 스스로 큼직큼직한 징검다리를 놓고 그 징검다리를 향해 디테일한 움직임을 제어할 수 있게 되어, 훨씬 적은 계산량으로 압도적으로 똑똑하게 긴 작업을 완수할 수 있게 되었습니다.
2 Hierarchical Planning with Latent World Models
2.1 Problem Setting
우리는 Markov decision process (MDP) $\mathcal{M} = (\mathcal{S}, \mathcal{A}, \mu, p)$를 고려한다. 여기서 $\mathcal{S}$는 state space, $\mathcal{A}$는 action space, $\mu \in \mathcal{P}(\mathcal{S})$는 initial state distribution, 그리고 $p : \mathcal{S} \times \mathcal{A} \rightarrow \mathcal{S}$는 transition dynamics를 나타낸다. 우리는 state-action trajectories $\tau = (s_1, a_1, s_2, \dots, a_{T-1}, s_T)$의 dataset $\mathcal{D}$에 접근할 수 있는 offline 환경에서 작업한다.
우리의 목표는 $\mathcal{D}$를 사용하여 다양한 goal-conditioned tasks 전반에 걸쳐 zero-shot control을 가능하게 하는 것이다. 명시적인 parametric policy를 학습하는 대신, 우리는 실제 transition dynamics $p$를 approximate하기 위해 world models를 학습하고, inference time에 model predictive control (MPC)를 통해 actions를 선택하여 goal-conditioned policy를 유도한다.
우리는 evaluation time에 goal-reaching tasks를 고려하며, 여기서 agent에게 goal state $s_g$가 제공되고 이에 도달함으로써 성공한다. 이 설정에서 task space $\mathcal{Z}$는 state space $\mathcal{S}$와 일치한다.
2.2 Latent World Models
world model은 agent의 actions에 반응하여 환경이 어떻게 진화하는지를 approximate하는 학습된 dynamical model이며, $p(s_{t+1} | s_t, a_t)$ 형태의 transition dynamics를 추정한다. high-dimensional 환경에서 world models는 일반적으로 효율성과 robustness를 향상시키기 위해 latent space에서 학습된다.
encoder는 observations $s_t$를 latent states $z_t$로 매핑하고, latent world model은 actions를 조건으로 하여 미래의 latents를 예측한다 ($p(z_{t+1} | z_t, a_t)$).
최근 연구들은 보상이 없고 task-agnostic한 offline 데이터로부터 학습된 latent world models가 downstream planning tasks에서 zero-shot, goal-conditioned control을 지원할 수 있음을 보여주었다. 그러나 flat MPC를 사용하여 이러한 models로 직접 planning하는 것은 누적되는 prediction errors와 확장되는 search space로 인해 task horizons가 길어짐에 따라 점점 더 취약해진다.
2.3 Top-Down Hierarchical Planning
Latent world models는 다양한 수준의 abstraction이 공유된 predictive framework 내에서 서로 다른 temporal horizons에 걸쳐 reasoning할 수 있으므로 자연스럽게 hierarchical planning을 지원한다. 적절한 temporal resolution에서 planning함으로써, hierarchical methods는 긴 primitive actions의 sequence에 대한 직접적인 optimization을 피하면서도 fine-grained control을 유지한다.
본 연구에서 우리는 완전히 학습된 latent space에서 작동하는 top-down hierarchical planning 전략을 채택한다 (Fig. 2). high level에서 agent는 long-horizon world model을 사용하여 최종 goal을 향해 추상적인 latent actions를 계획(plan)한다. 그 결과로 예측된 latent states는 중간 subgoals 역할을 한다. 그런 다음 low-level planner는 다음 subgoal에 도달하기 위해 짧은 horizon의 primitive actions의 sequences를 optimize하며, 이 과정을 receding-horizon MPC 방식으로 반복한다.
이제 우리는 hierarchical planner가 사용하는 latent representations와 world models에 대해 설명한다. observations $s_t$를 latent states $z_t = \mathcal{E}(s_t)$로 매핑하는 encoder를 $\mathcal{E}$라고 하자. 우리는 서로 다른 temporal resolutions에서 작동하는 두 개의 학습된 latent world models에 접근할 수 있다고 가정한다:
(i) primitive actions를 조건으로 short-horizon transitions를 예측하는 low-level model $\mathcal{P}^{(1)}(z_{t+1} | z_t, a_t)$
(ii) latent macro-actions $l_t$를 조건으로 long-horizon transitions를 예측하는 high-level model $\mathcal{P}^{(2)}(z_{t+h} | z_t, l_t)$
macro-actions $l_t$는 시간적으로 연장된 low-level actions의 sequences를 요약하는 학습된 action encoder에 의해 생성된다. fixed-stride 방식을 사용하는 temporal abstraction methods와 달리, 우리는 고정된 high-level horizon $h$를 가정하지 않으며, 각 high-level transition이 가변 길이의 low-level execution 세그먼트에 대응되도록 허용한다.
High-Level Planning. 초기 observation $s_1$과 goal observation $s_g$가 주어지면, 우리는 이를 latent space의 $z_1 = \mathcal{E}(s_1)$ 및 $z_g = \mathcal{E}(s_g)$로 인코딩한다. high level에서, 우리는 latent space 내의 goal-conditioned energy function을 최소화함으로써 $H$개의 latent actions의 sequence $\hat{l}_{1:H}$에 대한 plan을 세운다:
여기서 $\mathcal{P}^{(2)}(\hat{l}{1:H}; z_1)$는 $z_1$에서 시작하여 latent actions $\hat{l}{1:H}$와 함께 world model $\mathcal{P}^{(2)}$를 autoregressively unrolling하여 얻은 최종 latent state를 나타낸다. optimal latent action sequence는 다음과 같이 주어진다:
optimized latent plan을 unrolling하면 high-level temporal resolution에서 중간 latent subgoals의 sequence를 얻는다: $\tilde{z}_i \triangleq \mathcal{P}^{(2)}(l^*_{1:i}; z_1)$, $i = 1, \dots, H$.
Low-Level Planning. 실행 시간에 agent는 첫 번째 latent subgoal $\tilde{z}_1$에 도달하기 위한 primitive actions를 계획(plan)한다. 현재의 latent state $z_1$에서 시작하여, 우리는 $h$ steps의 horizon에 대한 low-level energy function을 다음과 같이 정의한다:
optimal low-level action sequence는 $a^*{1:h} = \arg \min{\hat{a}{1:h}} E_1(\hat{a}{1:h}; z_1, \tilde{z}_1)$를 통해 얻어지며, 이는 controller로 전달된다. agent는 hierarchical planner를 사용하여 매 $k$번의 interactions마다 다시 plan을 세운다.
2.4 Low-Level Latent World Model
low-level latent world model $\mathcal{P}^{(1)}{\theta}$는 primitive actions를 조건으로 latent space에서의 short-horizon transitions를 예측한다. observation $s_t$가 주어지면, 이를 latent representation $z_t = \mathcal{E}(s_t)$로 인코딩하고 $\mathcal{P}^{(1)}{\theta}$를 사용하여 $p(z_{t+1} | z_t, a_t)$를 모델링한다.
이 model은 JEPA-style predictive models에 관한 이전 연구를 따라 teacher-forcing 및 multi-step autoregressive rollout losses를 포함한 표준 latent world-model objectives를 사용하여 trained된다. 우리의 실험에서는 기본 backbone world models (VJEPA2-AC, DINO-WM 및 PLDM)의 training 방식과 architectures를 재사용하여, 성능 향상이 low-level dynamics model의 변경이 아닌 hierarchical planning에서 기인했음을 보장한다.
2.5 High-Level Latent World Model
우리는 더 긴 time horizons에 걸쳐 예측하는 high-level latent world model $\mathcal{P}^{(2)}_{\phi}$를 train하는 방법을 설명한다 (Fig. 3). trajectory $\tau = (s_1, a_1, s_2, a_2, \dots, s_T)$가 주어지면, 먼저 $N < T$ 이고 $1 = t_1 < t_2 < t_3 < \dots < t_{N-1} < t_N$ 이 되도록 $N$개의 waypoint 인덱스를 선택한다. 그러면 waypoint states는 $(s_{t_1}, s_{t_2}, \dots, s_{t_{N-1}}, s_{t_N})$이 된다.
각 high-level transition은 waypoint $s_{t_k}$, 다음 waypoint $s_{t_{k+1}}$, 그리고 그 사이의 action subsequence로 구성된다. 형식적으로, $k$번째 transition은 $(s_{t_k}, (a_{t_k:t_{k+1}}), s_{t_{k+1}})$이다. high-level world model은 low-level world model과 동일한 latent space에서 예측을 수행하며, 공유된 encoder $\mathcal{E}$를 사용하여 waypoint states $(s_{t_k}){k \in [N]}$를 latent features $(z{t_k})_{k \in [N]}$로 변환한다.
action encoder $\mathcal{A}{\psi}$는 waypoints 사이의 action subsequences $(a{t_k:t_{k+1}}){k \in [N]}$를 macro latent actions $(l{t_k}){k \in [N]}$로 인코딩한다. 우리는 waypoint latent actions와 features의 교차된(interleaved) sequence $(l{t_k}, z_{t_k}){k \in [N]}$를 world model $\mathcal{P}^{(2)}{\phi}$에 입력하여 다음 waypoint representation predictions $(\hat{z}{t{k+1}})_{k \in [N]}$를 예측한다. teacher-forcing loss는 다음과 같다:
2 Hierarchical Planning with Latent World Models 정리 노트
핵심 과제 및 기존의 한계 (Problem Setting & Limitations)
- Latent World Models는 high-dimensional 환경에서 효과적이지만, 긴 horizon의 작업에서는 prediction errors 누적과 search space 폭발로 인해 flat MPC 적용이 매우 취약해집니다.
HWM의 핵심 아키텍처 (Top-Down Hierarchical Planning)
- 별도의 계층적 정책(hierarchical policy)을 학습하는 대신, Inference time에 receding-horizon MPC 방식으로 계층적 계획을 수행합니다.
- Shared Latent Space(가장 중요한 기여점): High-level과 Low-level 모델이 완전히 동일한 encoder $E$를 공유하여 같은 latent space $\mathcal{Z}$ 내에서 작동합니다. 이를 통해 복잡한 역모델(inverse model)이나 목표 변환 과정 없이, 상위 레벨의 예측이 하위 레벨의 latent subgoals $\tilde{z}_i$로 직접 전달됩니다.
주요 구성 요소 및 최적화 메커니즘
- Action Encoder $\mathcal{A}_\psi$:
- 기존의 고정된 길이(fixed-stride) 단위 추상화와 달리, waypoint 간의 가변적인 길이를 가진 primitive actions 시퀀스를 하나의 latent macro-actions $l_t$로 압축합니다.
- High-Level Planning $\mathcal{P}^{(2)}$:
- 초기 상태 $z_1$에서 목표 상태 $z_g$에 도달하기 위한 최적의 거시적 행동 시퀀스 $l^*_{1:H}$를 탐색합니다.
- 탐색 시 아래의 goal-conditioned energy function을 최소화합니다.
- $E_2(\hat{l}_{1:H}; z_1, z_g) \triangleq \|z_g - \mathcal{P}^{(2)}(\hat{l}_{1:H}; z_1)\|_1$
- 도출된 중간 예측값들은 low-level을 위한 latent subgoals가 되며, 학습 시 waypoint 간의 teacher-forcing loss $\mathcal{L}_{\text{tf}}$를 사용하여 최적화합니다.
- Low-Level Planning $\mathcal{P}^{(1)}$:
- High-level이 넘겨준 첫 번째 subgoal $\tilde{z}_1$을 타겟으로 삼아 아래의 low-level energy function을 최소화합니다.
- $E_1(\hat{a}_{1:h}; z_1, \tilde{z}_1) \triangleq \|\tilde{z}_1 - \mathcal{P}^{(1)}(\hat{a}_{1:h}; z_1)\|_1$
- 이를 달성하기 위한 short-horizon 단위의 primitive actions $a^*_{1:h}$를 최적화하여 실제 controller에 전달합니다. 기존 JEPA-style 모델의 학습 구조를 그대로 재사용합니다.
쉬운 설명 : 2. Hierarchical Planning with Latent World Models
아주 복잡하고 거대한 레고 성을 조립하는 로봇을 상상해 보세요.
- 기존 방식(Flat MPC): 1번 레고 브릭부터 10000번 브릭까지 어떤 순서로 어디에 끼울지 시작하기 전에 한 번에 다 계획하려고 합니다. 이렇게 하면 중간에 브릭 하나만 잘못 끼워도 뒤의 계획이 다 어긋나버리고(prediction errors 누적), 머릿속으로 계산해야 할 경우의 수가 너무 많아져서 시스템이 마비됩니다.
- 논문의 방식(HWM):
- 거시적 계획 (High-Level Planning): 작업 반장(High-level model)이 "1. 1층 성벽 완성 -> 2. 중앙 탑 완성 -> 3. 지붕 완성(최종 목표)"이라는 큼직한 중간 목표(subgoals)들을 세웁니다.
- 행동 압축 (Action Encoder): 여기서 '1층 성벽 조립'이라는 행동은 단순히 '블록 10번 끼우기'처럼 정해진 횟수가 아니라, 상황에 따라 수십 번의 세밀한 조립 동작이 하나로 유연하게 압축된 덩어리 행동(macro-actions)입니다.
- 미시적 실행 (Low-Level Planning): 실제 조립 로봇(Low-level model)은 반장이 지시한 첫 번째 중간 목표인 '1층 성벽 완성' 상태만 타겟으로 삼고, 당장 눈앞의 브릭을 어떻게 끼울지 세밀한 손동작(primitive actions)만 짧게 계획하고 실행합니다.
- 같은 도면 공유 (Shared Latent Space): 반장과 조립 로봇이 완전히 동일한 형태의 상상 속 설계도(latent space)를 공유합니다. 반장이 상상한 '1층 성벽이 완성된 모습'을 넘겨주면, 조립 로봇이 복잡한 번역 과정 없이 직관적으로 이해하고 바로 세부 작업을 시작할 수 있는 것이 이 시스템의 가장 큰 장점입니다.
현재 상태와 목표 상태가 입력임
아웃풋은 액션 시퀀스 : 현재부터 액션을 진행하며 목표가 되게 끔 하는
움직인 기록인 궤적(Trajectory) 데이터를 준비
매 프레임의 RGB 이미지(256 x 256 해상도),
로봇 팔의 현재 상태 벡터(7 차원),
행동 벡터(7 차원)
먼저 Low-level 모델 학습을 위해, 전체 궤적 중 연속된 15 개의 프레임을 한 묶음으로 떼어옴.
떼어온 15 개의 이미지들을 미리 학습되어 파라미터가 고정된 이미지 인코더(ViT-g/16)에 차례대로 밀어 넣어, 각각 1408 차원의 압축된 특징 벡터(Latent feature) 15 개를 뽑아냄.
Low-level 예측 모델(ViT)에 아까 뽑은 현재 특징 벡터, 로봇 상태 벡터, 그리고 행동 벡터를 시간 순서대로 엮어서 인풋으로 집어넣고 다음 스텝의 특징 벡터를 뽑음
loss 계산 후
방금 예측할건 다시 그 다음 스텝으로 예측하게 만드는 롤아웃을 거쳐서 두번째 loss를 구해서
합쳐서 파라이터 업데이트 (15개까지 쭉 해버린다고 함)
다음으로 High-level 모델을 학습하기 위해, 이번에는 훨씬 더 긴 시간(최대 4 초 분량)의 궤적 데이터를 크게 한 묶음 가져옴.
가져온 긴 궤적 안에서 시작점, 중간 랜덤 지점, 끝점 이렇게 총 3 개의 징검다리 지점(Waypoint)을 콕 집어냄.
징검다리 지점 사이사이에 로봇이 자잘하게 움직인 수많은 행동 벡터들을 한꺼번에 모아서 Transformer 구조의 행동 인코더(Action Encoder)에 밀어 넣음.
행동 인코더는 이 자잘한 원시 행동 묶음들을 4 차원 크기의 뭉뚱그린 잠재 행동 벡터(Latent macro-action) 단 하나로 압축해서 아웃풋으로 뽑아냄.
징검다리 지점의 이미지들 역시 아까 썼던 이미지 인코더에 똑같이 넣어서 특징 벡터로 만들어둠.
High-level 예측 모델(Low-level과 동일한 ViT 구조)에 현재 징검다리 지점의 특징 벡터와 방금 압축해낸 잠재 행동 벡터를 인풋으로 집어넣음.
High-level 모델은 "이 뭉뚱그린 행동을 했으니, 다음 징검다리 지점의 특징 벡터는 이거일 거야"라고 성큼 건너뛴 미래의 특징 벡터를 아웃풋으로 뱉어냄.
예측한 징검다리 특징 벡터와 실제 다음 징검다리 이미지의 진짜 특징 벡터 사이의 차이(L1 거리)를 계산하여 High-level Loss를 구함 (여기서는 Rollout loss 없이 단일 스텝 예측 Loss만 씀).
최종적으로 이 Loss를 바탕으로 High-level 예측 모델과 행동 인코더를 동시에 업데이트(학습)하며 한 번의 학습 사이클을 마침.
그니까 로우레벨로 15스텝 롤아웃으로 강건하게 만들고
하이레벨은 그간의 액션들을 뭉뚱 그려서 목표로 한번에 만드는걸 학습하는거네
그래서 하이레벨이 목표까지 가기 위해 뭉뚱그린 액션 시퀀스들을 탐색하고 나면
그중 하나떼서 로우레벨 모델이 서브골까지 디테일하게 가는 느낌의 액션들을 찾을 수 있겠군