

AI바라기의 인공지능
Survey : Continual Learning for Generative AI: From LLMs to MLLMs and Beyond 본문
Survey : Continual Learning for Generative AI: From LLMs to MLLMs and Beyond
AI바라기 2025. 12. 12. 14:18Terminology (용어 설명)
- Continual Learning (CL): 모델이 이전에 학습한 지식을 잊지 않으면서(Catastrophic Forgetting 방지), 새로운 데이터나 태스크를 순차적으로 학습하는 방법론.
- Catastrophic Forgetting: 신경망이 새로운 정보를 학습할 때, 이전에 학습했던 정보(파중치)가 급격하게 변경되어 이전 태스크의 성능이 대폭 하락하는 현상.
- Discriminative vs. Generative Models:
- Discriminative: 데이터의 결정 경계(Decision Boundary)를 학습 (예: 분류기). P(y∣x) 모델링
- Generative: 데이터의 확률 분포(Probability Distribution)를 학습하여 새로운 콘텐츠 생성.
- VLA (Vision-Language-Action Models): 시각(Vision)과 언어(Language) 정보를 받아 로봇의 행동(Action)을 제어하는 멀티모달 모델.
- PEFT (Parameter-Efficient Fine-Tuning): 모델의 전체 파라미터를 튜닝하는 대신, LoRA나 Adapter 같은 소수의 파라미터만 학습하여 효율성을 높이는 기법. CL에서 'Architecture-based' 방식의 핵심 요소로 쓰임.
- Replay-based Methods: 과거 데이터의 일부를 저장하거나(Direct Replay), 모델이 스스로 과거 데이터를 생성하여(Generative Replay) 현재 학습 데이터와 섞어서 학습하는 방식.
Purpose of the Paper
- Why this paper? (연구 배경 및 목적):
- 기존의 Continual Learning 연구와 Survey들은 주로 Discriminative Models(Image Classification 등)에 집중되어 있었습니다.
- Generative AI(LLM, Diffusion 등)가 부상함에 따라, 이들은 단순한 분류를 넘어 **'새로운 콘텐츠 생성'**과 **'의미적 연결(Semantic Association)'**이 필요하므로 기존 CL 방법론을 그대로 적용하기 어렵습니다.
- Gap: 기존의 Generative AI 관련 Survey들은 특정 모델(LLM 또는 MLLM)에만 국한되어 있어, 다양한 생성형 모델을 아우르는 통합된 시각이 부재했습니다.
- Goal: 이 논문은 LLM, MLLM, VLA, Diffusion Model을 포함한 주류 Generative AI 전체를 아우르는 최초의 포괄적인 Survey를 제공하고, 이를 통합된 분류 체계(Taxonomy)로 정리하여 연구의 나침반을 제시하고자 합니다.
Key Contributions
- Unified Taxonomy based on Biological Mechanisms:
- 인간 뇌(Hippocampus, Neocortex)의 기억 메커니즘에서 영감을 받아, 모든 Generative AI의 CL 방법론을 3가지 패러다임으로 명확히 분류했습니다.
- Architecture-based: 모델 구조 변경 (예: PEFT 모듈 추가, 파라미터 격리).
- Regularization-based: 중요 파라미터가 변하지 않도록 손실 함수에 제약 추가.
- Replay-based: 과거 데이터를 저장하거나 생성하여 재학습.
- 인간 뇌(Hippocampus, Neocortex)의 기억 메커니즘에서 영감을 받아, 모든 Generative AI의 CL 방법론을 3가지 패러다임으로 명확히 분류했습니다.
- Comprehensive Coverage of Generative Models:
- LLMs: Instruction Tuning 및 Pre-training 관점에서의 CL 분석.
- MLLMs: Modality 간의 상호작용 및 Vision-Language Alignment 유지 문제 분석.
- VLA Models: 로보틱스 환경에서의 Embodied AI가 겪는 Lifelong Learning 문제(Skill acquisition)를 다룸.
- Diffusion Models: 사용자의 새로운 개념(Concept)을 추가할 때 발생하는 Forgetting 문제(Personalized Generation)를 다룸.
- Structured Analysis of Benchmarks & Setups:
- 각 모델 타입별로 상이한 Problem Setup (Training Objectives)과 Representative Benchmarks(TRACE, CLiMB, LIBERO, CLoG 등)를 체계적으로 정리하여 후속 연구자들이 진입하기 쉽게 만듦.
Experimental Highlights (Survey Findings)
이 논문은 Survey이므로 특정 모델의 성능보다는, 분야별 실험 동향과 주요 발견을 요약합니다.
- Dominance of Architecture & Replay Methods:
- Discriminative model에서는 Regularization 기법이 흔하지만, Generative AI(특히 LLM/MLLM)에서는 Architecture-based(특히 PEFT 활용)와 Replay-based 접근법이 더 효과적이고 주류를 이루고 있음이 확인됨.
- 이유: Generative Model은 파라미터 수가 방대하여 전체를 규제(Regularization)하기 어렵고, Task variety가 매우 크기 때문.
- Evolution of Metrics:
- 단순 정확도(Accuracy) 외에 Zero-shot Transfer (ZT) 능력이 학습 과정에서 얼마나 유지되는지가 중요한 평가 지표로 부상함.
- Generative AI 특성에 맞춰 Forgetting Measure (FM) 뿐만 아니라 생성된 콘텐츠의 품질(예: FID, BLEU)과 Instruction Following 능력을 동시에 평가해야 함.
- Domain-Specific Challenges:
- VLA: 시뮬레이션 환경(LIBERO 등) 위주로 실험이 진행되나, 실제 로봇 환경(Real-world)으로의 확장성(Sim-to-Real)이 주요 실험 과제임.
- Diffusion: 소수의 이미지(3-5장)로 새로운 개념을 학습하는 Few-shot 설정이 주를 이루며, 이 과정에서 기존 개념이 붕괴되지 않도록 하는 것이 핵심 실험 목표임.
Limitations and Future Work
- Efficient Continual Learning (Efficiency Bottleneck):
- Limitation: 현재 주류인 Architecture-based 방식(모델 확장)은 태스크가 늘어날수록 메모리와 추론 비용이 증가함. Replay 방식은 데이터 저장 비용과 프라이버시 문제가 있음.
- Future Work: Model Compression, Pruning, Quantization과 CL을 결합하거나, 데이터를 압축된 토큰 형태로 저장하는 Dataset Distillation 연구가 필요함.
- Shift to RL Paradigm:
- Limitation: 대부분의 CL 연구가 Supervised Fine-Tuning (SFT)에 의존하고 있어, 패턴 암기에 치중하고 일반화 성능이 떨어질 수 있음.
- Future Work: Reinforcement Learning (RL) 기반 학습(예: GRPO)을 도입하여, 단순 암기가 아닌 구조적 이해를 돕고 Long-term adaptation을 가능하게 해야 함.
- Self-generation for CL:
- Limitation: 이전 데이터를 사용할 수 없는 경우(Privacy 이슈), 외부 모델(GAN 등)을 쓰는 것은 비효율적임.
- Future Work: Generative Model 자체가 가진 생성 능력을 활용해 스스로 과거 데이터를 합성(Self-synthesized rehearsal) 하여 Replay에 활용하는 방향이 유망함.
- Evaluation on Large Scale Models:
- Limitation: 대부분 7B~13B 사이즈 모델에서 실험됨. 모델이 거대해질수록(70B+) Emergent Ability가 나타나므로 CL 거동이 달라질 수 있음.
- Future Work: 초대형 모델에 적합한 Parameter-Efficient 지식 통합 전략(RAG, In-Context Learning 활용 등) 연구가 필요함.
Overall Summary
이 논문은 LLM부터 Diffusion Model에 이르기까지 Generative AI 전반에 걸친 Continual Learning 기술을 집대성한 Survey입니다. 인간의 기억 메커니즘에 기반한 3가지 분류 체계(Architecture, Regularization, Replay)를 통해 방대한 연구들을 체계적으로 정리하였으며, 단순 분류를 넘어 '생성(Generation)'이라는 특성이 CL에 미치는 고유한 영향과 도전 과제를 심도 있게 분석했습니다. 이 연구는 파편화되어 있던 Generative AI의 연속 학습 방법론을 통합하고, 향후 효율적이고(Efficient), 자가 생성적이며(Self-generating), 멀티모달(Multimodal)로 확장 가능한 통합 학습 프레임워크로 나아가는 이정표를 제시합니다.
쉬운 설명 (Easy Explanation)
이 논문의 핵심 아이디어는 다음과 같습니다:
- 문제 상황: AI에게 새로운 것(예: 새로운 언어, 새로운 그림 스타일)을 가르치면, 용량이 꽉 찬 USB에 파일을 덮어쓰는 것처럼 옛날에 배운 것을 까먹어버립니다. 이를 **'재앙적 망각(Catastrophic Forgetting)'**이라고 합니다.
- 기존 연구의 한계: 예전에는 "강아지 vs 고양이"를 구분하는 AI(판별 모델)가 안 까먹게 하는 연구만 많았습니다. 하지만 요즘은 글도 쓰고 그림도 그리는 생성형 AI(Generative AI) 시대입니다. 생성형 AI는 단순히 구분하는 게 아니라 '창조'를 해야 해서 훨씬 더 복잡하고 예민합니다.
- 이 논문의 역할: 이 논문은 "요즘 유행하는 모든 생성형 AI(ChatGPT, 그림 그리는 AI, 로봇 AI 등)들이 어떻게 하면 안 까먹고 계속 똑똑해질 수 있을까?" 에 대한 모든 기술을 정리한 백과사전입니다.
- 해결책 3가지 (뇌를 흉내 냄):
- 뇌 용량 늘리기 (Architecture): 새로운 걸 배울 때마다 뇌의 특정 부분(모듈)을 조금씩 추가해서 따로 저장합니다. (요즘 제일 잘 나가는 방식!)
- 중요한 기억 잠그기 (Regularization): 옛날 지식이 담긴 뇌세포는 건드리지 말고, 덜 중요한 부분만 바꿔서 학습합니다.
- 복습하기 (Replay): 새로운 걸 배울 때, 예전에 배운 내용도 살짝 섞어서 같이 공부합니다. (시험 기간 벼락치기 대신 꾸준한 복습!)
1 INTRODUCTION
Artificial intelligence의 진화는 "세상을 이해하는 것"에서 "세상을 창조하는 것"으로 paradigm shift를 겪고 있습니다. Classification networks 및 object detectors와 같은 전통적인 discriminative models는 지난 10년 동안 놀라운 성공을 거두었습니다. 이러한 models는 large-scale labeled datasets에서 decision boundaries를 학습하는 데 유능하여, 알려진 concepts에 대한 정확한 인식과 판단을 가능하게 합니다. 그러나 discrimination에 기반한 이러한 지능은 creativity와 generation에서 한계를 보였습니다. 이는 single modality 내에서 알려진 concepts를 구별하는 데는 탁월하지만, novel content를 generate하거나 multiple modalities 간의 semantic associations를 구축하는 데는 어려움을 겪습니다. Generative AI의 부상은 underlying data distribution을 capture하기 위해 large-scale pre-training을 채택함으로써 이러한 한계를 해결합니다. 그 결과, Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Vision-Language-Action (VLA) Models, Diffusion Models와 같은 주류 generative AI models는 이제 input features를 해석할 수 있을 뿐만 아니라 coherent text, realistic images, 심지어 cross-modal content까지 능동적으로 generate할 수 있습니다. 분야가 discriminative paradigm에서 generative paradigm으로 전환됨에 따라, AI는 단순히 알려진 것을 인식하는 것에서 새로운 것을 능동적으로 creating하는 것으로 진화하고 있습니다. 이러한 변화는 더 유연하고 multimodal generation capabilities를 가능하게 함으로써 human-machine collaboration의 기초를 재정의하고 있습니다.
GPT-4와 같은 generative models의 성공은 근본적으로 large-scale generative pre-training과 human alignment에 의존합니다. 그러나 언어, data distributions, user demands가 지속적으로 진화하기 때문에 이 과정은 본질적으로 dynamic합니다. 더 중요한 것은, Figure 1 (a)에 묘사된 것처럼 models가 인간과 유사한 continual learning capabilities를 갖추어야 할 필요성을 강조하면서, 미래의 모든 가능한 scenarios를 미리 고려하는 것은 불가능하다는 점입니다. 따라서 이러한 capabilities는 generative models가 closed-world assumption을 넘어 open-ended, real-world scenarios에 배포될 수 있도록 하는 데 필수적입니다. 이 맥락에서 핵심적인 challenge는 새로운 정보를 학습하면 이전에 습득한 knowledge가 덮어씌워지는 catastrophic forgetting입니다. 예를 들어, specialized domains(예: 수학)에 대해 general-domain models(예: ChatGPT)를 fine-tuning하면 in-domain performance는 향상될 수 있지만 prior capabilities를 잊어버리는 대가를 치를 수 있습니다. Models가 여러 downstream tasks에 대해 순차적으로 trained될 때, 각 새로운 업데이트는 이 효과를 가중시켜 knowledge retention의 점진적인 저하를 초래합니다. 간단한 해결책은 이전 tasks의 data를 유지하고 새로운 data와 joint training을 수행하는 것입니다. 그러나 이 접근 방식은 막대한 storage costs와 data privacy concerns로 인해 종종 비실용적입니다. 대조적으로, 어린이와 성인은 일반적으로 이전 지식을 명시적으로 회상하지 않는 경우에도 새로운 정보를 학습할 때 catastrophic forgetting을 나타내지 않으며, 이는 인공 학습 시스템과 생물학적 학습 시스템 간의 근본적인 격차를 강조합니다. 이 격차를 해소하기 위해 continual learning에 대한 연구가 탄력을 받고 있으며, 특히 이전 tasks의 data가 제한적이거나 완전히 사용할 수 없는 실용적인 시나리오에서 prior skills를 유지하면서 시간이 지남에 따라 새로운 knowledge를 학습할 수 있는 능력을 models에 부여하는 것을 목표로 합니다.
Perceptual tasks에 중점을 둔 전통적인 discriminative models와 비교할 때, continual learning 설정의 generative models는 Figure 1 (b)와 같이 이해와 인식에 기반하여 새로운 content를 creating함으로써 한 단계 더 나아갈 것으로 기대됩니다. 우리는 continual learning에서의 증가된 challenges를 두 가지 주요 측면으로 요약합니다: (1) 더 복잡한 modeling objectives. Discriminative methods는 posterior 및 discriminative probabilities(즉, $P(y|x)$)를 modeling하는 데 중점을 두며, 여기서 catastrophic forgetting은 주로 classification space 내의 decision boundary의 이동으로 나타납니다. 대조적으로, generative models는 underlying probability distribution(즉, $P(x)$)을 파악하는 것을 목표로 하며, 이는 open-ended generative space 내에서 semantic coherence와 knowledge completeness를 모두 유지하기 위한 continual learning을 필요로 합니다. 이를 달성하기 위해서는 generative reasoning process를 underlying factual knowledge representation과 함께 다듬어 hallucinations와 semantic inconsistencies를 완화하는 것이 필수적입니다. (2) Task formats의 더 큰 다양성. Generative models는 continual learning 중에 새로운 input modalities, 새로운 domain knowledge, 진화하는 task characteristics와 같은 요인으로 인해 발생하는 차이점과 함께 매우 다양한 tasks에 직면합니다. 이러한 가변성은 catastrophic forgetting의 위험을 증가시키고 multi-task knowledge integration에 대한 요구를 높입니다. 대조적으로, discriminative models는 일반적으로 classification, detection, segmentation과 같은 좁은 범위의 tasks에 집중하므로 continual learning이 상대적으로 덜 까다롭습니다. Figure 2는 4가지 대표적인 generative models에 걸친 continual learning scenarios를 보여줍니다. 인상적인 capabilities에도 불구하고, 이러한 models가 지속적으로 학습할 수 있도록 하는 것은 여전히 도전적이며 충분히 탐구되지 않았습니다.
Continual learning과 catastrophic forgetting을 해결하는 데 초점을 맞춘 여러 surveys가 있지만, 일정한 한계를 보입니다. 첫째, discriminative models에 초점을 맞춘 리뷰들이 상당한 관심을 끌었지만, discriminative paradigms와 generative paradigms 간의 근본적인 차이로 인해 이러한 methods를 generative models의 continual learning에 그대로 적용할 수 없습니다. 또한, generative models를 위한 continual learning에 대한 기존 surveys는 일반적으로 LLMs 또는 MLLMs와 같은 특정 architectures에 집중합니다. 이러한 연구들은 각자의 domains 내에서 체계적인 개요를 제공하지만, 다양한 유형의 generative models 간의 관계, 유사점, 차이점에 대한 포괄적인 논의가 부족한 경우가 많습니다. 이러한 공백을 메우기 위해, 본 연구에서는 LLM, MLLM, VLA, Diffusion Model을 포함한 광범위한 주류 generative models 전반에 걸친 continual learning에 대한 최초의 포괄적인 리뷰를 제시합니다. 구체적으로, 우리는 통합된 관점에서 이러한 유형의 models 전반에 걸쳐 공유되는 continual learning 맥락의 기본 원칙을 밝히는 것으로 시작합니다. 그 후, 각 유형의 generative model에서의 주요 approaches와 challenges를 각각 체계적으로 분석합니다. 전체적으로, 우리 논문은 문헌의 최신 진전을 제공하고 미래 연구를 위한 전체론적 관점을 제시합니다.
논문의 구성은 다음과 같습니다: Section 2에서는 continual learning의 기본 formulation, evaluation metrics, taxonomy를 다루는 setup을 제시합니다. Section 3에서 6까지는 Large Language Models (Section 3), Multimodal Large Language Models (Section 4), Vision-Language-Action Models (Section 5), Diffusion Models (Section 6)에서의 continual learning에 대한 심층적인 논의를 제공합니다. 각 domain은 continual learning tasks를 위한 training strategies, 대표적인 benchmarks, model architectures, 그리고 기존 approaches의 동기와 실제 구현 측면에서 검토됩니다. Section 7에서는 generative models를 기반으로 구축된 continual learning methods의 잠재적인 미래 research directions와 새로운 trends를 추가로 탐구합니다. 마지막으로, Section 8은 논문을 결론짓고 generative models를 위한 continual learning의 최신 진행 상황을 추적하기 위해 지속적으로 업데이트되는 GitHub repository를 소개합니다.
1. INTRODUCTION 정리노트 (AI 연구자용)
본 논문은 Discriminative models에서 Generative models로의 AI Paradigm shift에 주목하며, Generative AI를 위한 **Continual Learning (CL)**의 필요성과 고유한 Challenges를 체계적으로 분석한 최초의 통합 Survey입니다.
1. 배경 및 필요성: Static Pre-training의 한계
- Paradigm Shift: AI의 역할이 "Understanding"(Classification, Detection)에서 "Creating"(LLMs, MLLMs, VLA, Diffusion Models)으로 전환됨.
- Dynamic Nature: GPT-4와 같은 모델은 Large-scale pre-training에 의존하지만, 실제 세상의 Data distributions와 User demands는 지속적으로 변화함.
- Closed-world Assumption 탈피: 모든 시나리오를 사전에 학습하는 것은 불가능하므로, Open-ended scenarios에서 새로운 지식을 학습하면서도 Prior skills를 유지하는 Human-like CL 능력이 필수적임.
- Catastrophic Forgetting: 새로운 Task 학습 시 이전 지식이 덮어씌워지는 현상. Joint training은 Storage costs 및 Data privacy 문제로 인해 비현실적이므로 효율적인 CL 방법론이 요구됨.
2. Generative Models에서의 CL Challenges (vs Discriminative Models)
본 논문은 Generative models의 CL이 Discriminative models보다 훨씬 복잡함을 다음 두 가지 핵심 이유로 설명함:
- Complex Modeling Objectives:
- Discriminative: Posterior probability $P(y|x)$ 모델링에 집중. Catastrophic forgetting은 주로 Decision boundary의 Drift로 나타남.
- Generative: Underlying probability distribution $P(x)$를 모델링해야 함. 단순한 결정 경계 유지가 아니라, Open-ended generative space에서 Semantic coherence와 Knowledge completeness를 동시에 유지해야 함. (Hallucinations 및 Semantic inconsistencies 방지 필요).
- Greater Diversity in Task Formats:
- 단일 Task(Classification 등)에 집중하는 Discriminative models와 달리, Generative models는 New input modalities, Novel domain knowledge 등 Task 다양성이 매우 높아 Multi-task knowledge integration 난이도가 높음.
3. 기존 연구의 한계 및 본 논문의 기여 (Contribution)
- Existing Surveys:
- Discriminative models 중심이거나(Generative paradigm에 적용 불가), 특정 Architecture(LLM or MLLM)에 국한되어 있음.
- 서로 다른 Generative models 간의 관계나 공통된 원리에 대한 논의가 부재함.
- This Work:
- LLM, MLLM, VLA, Diffusion Models를 아우르는 최초의 포괄적 Review.
- 다양한 Generative models 전반에 공유되는 CL의 기본 원리를 통합된 관점에서 규명하고, 각 모델 유형별 핵심 Approaches와 Challenges를 체계적으로 분석함.
쉬운 설명 : 1. INTRODUCTION
이 섹션은 왜 요즘 AI(생성형 AI)가 계속해서 새로운 것을 배우는 게 어려운지, 그리고 이 논문이 왜 중요한지를 설명하고 있습니다.
- AI의 변화: 예전 AI는 사진을 보고 "이건 고양이다/아니다"를 맞추는 문제 풀이 위주였다면, 요즘 AI(ChatGPT 등)는 글을 쓰거나 그림을 그리는 창작을 합니다.
- 문제점 (건망증): AI에게 새로운 지식(예: 최신 뉴스)을 가르치면, 예전에 배운 지식(예: 역사)을 까먹는 현상(Catastrophic forgetting)이 발생합니다. 그렇다고 매번 모든 데이터를 다 모아서 처음부터 다시 가르치기에는 비용과 시간, 개인정보 문제가 너무 큽니다.
- 생성형 AI가 더 어려운 이유:
- 문제 풀이 AI는 정답을 고르는 '경계선'만 기억하면 되지만, 생성형 AI는 '맥락'과 '지식의 깊이'를 통째로 유지해야 하기 때문입니다.
- 예를 들어, 작문 실력을 유지하면서 새로운 단어를 배워야 하는데, 자칫하면 새로운 단어만 배우고 문장 만드는 법을 잊거나 엉뚱한 소리(Hallucinations)를 하게 됩니다.
- 이 논문의 목표: 기존 논문들은 특정 AI 모델 하나만 파고들었다면, 이 논문은 글(LLM), 그림(Diffusion), 로봇 행동(VLA) 등 다양한 생성형 AI들이 겪는 '학습 건망증' 문제를 한 번에 모아서 비교하고 해결책을 정리한 최초의 '통합 가이드북'입니다.

Figure 1: 인간과 기계의 연속 학습 비교 및 모델 유형별 차이
이 그림은 왜 AI에게 연속 학습이 필요한지, 그리고 기존 모델(Discriminative)과 생성형 모델(Generative)의 목표가 어떻게 다른지를 설명합니다.
- (a) Human and Machine Continual Learning (좌측)
- 인간 (Human): 어린이가 성장하며 새로운 코스, 기술, 경험을 차례로 배우듯이, 인간은 평생 동안 이전 기억을 잃지 않고 새로운 것을 학습합니다.
- 기계 (Machine): AI 모델도 인간처럼 새로운 지시(Instructions), 모달리티(Modalities), 지식(Knowledge)을 순차적으로 학습하면서도, 이전 지식을 잊지 않는(Catastrophic Forgetting 방지) 것을 목표로 합니다.
- (b) Discriminative and Generative Continual Learning (우측)
- 나무 비유: AI가 배워야 할 방대한 영역을 나무로 표현했습니다. (새로운 능력, 클래스, 도메인, 태스크, 모달리티 등)
- Discriminative Models (왼쪽 잎): 분류(Classification), 탐지(Detection)와 같은 '인식(Perception)' 관련 태스크에 집중합니다.
- Generative Models (오른쪽 잎): 인식 능력을 바탕으로 새로운 콘텐츠를 만들어내는 '창조(Creation)' 관련 태스크까지 요구됨을 보여줍니다. 즉, 생성형 모델의 연속 학습이 더 포괄적이고 어렵다는 것을 암시합니다.
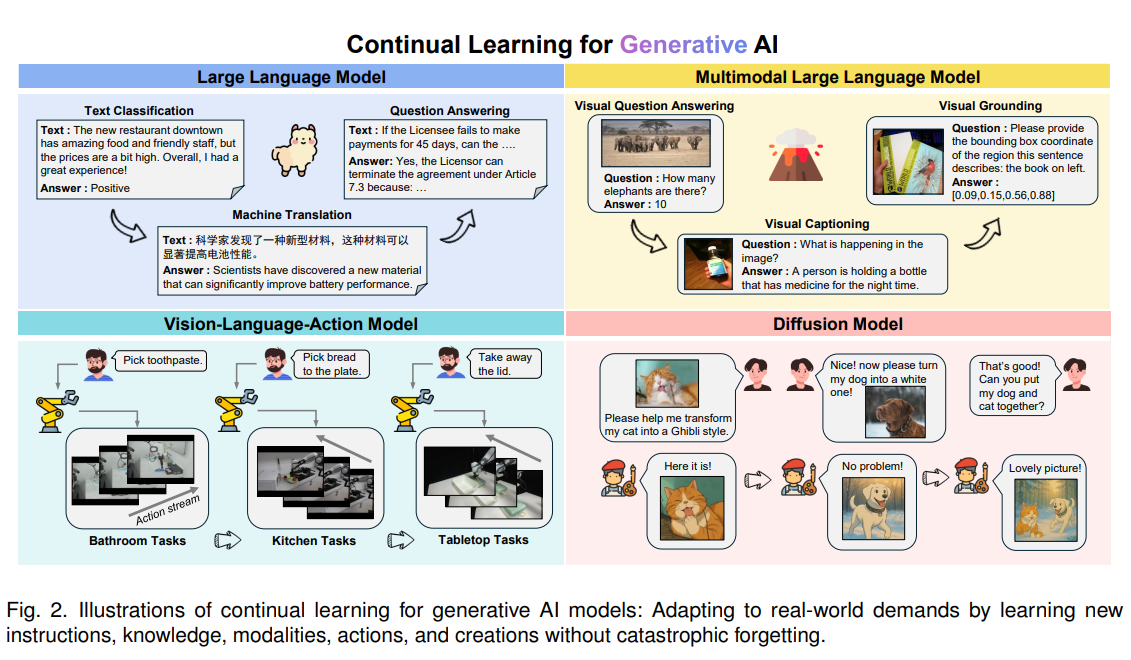
Figure 2: 생성형 AI 모델별 연속 학습 시나리오 예시
이 그림은 이 논문이 다루는 4가지 주요 생성형 모델 카테고리에서, 실제로 연속 학습이 어떻게 적용되는지를 구체적인 태스크 흐름으로 보여줍니다.
- Large Language Model (LLM - 좌측 상단)
- 텍스트 기반의 태스크들이 연속적으로 주어지는 상황입니다.
- 순서: 텍스트 감정 분석(Text Classification) $\rightarrow$ 질문 답변(QA) $\rightarrow$ 기계 번역(Machine Translation) 순으로 새로운 태스크를 학습하더라도 이전 능력을 유지해야 합니다.
- Multimodal Large Language Model (MLLM - 우측 상단)
- 이미지와 텍스트를 함께 이해하는 태스크들입니다.
- 순서: 이미지 보고 코끼리 수 세기(VQA) $\rightarrow$ 물체의 위치 찾기(Visual Grounding) $\rightarrow$ 상황 설명하기(Visual Captioning)와 같이 시각적 이해가 필요한 다양한 태스크를 연속으로 학습합니다.
- Vision-Language-Action Model (VLA - 좌측 하단)
- 로봇이 시각 정보를 통해 행동(Action)을 수행하는 모델입니다.
- 순서: 욕실 정리(치약 집기) $\rightarrow$ 주방 일(접시에 빵 놓기) $\rightarrow$ 탁자 정리(뚜껑 치우기)처럼 환경이 바뀌어도 로봇이 새로운 행동을 계속 배워나가는 과정을 보여줍니다.
- Diffusion Model (우측 하단)
- 이미지를 생성하거나 편집하는 모델입니다.
- 순서: 고양이를 지브리 스타일로 변환 $\rightarrow$ 강아지를 흰색으로 변환 $\rightarrow$ 강아지와 고양이를 함께 있는 그림으로 생성. 사용자의 새로운 요구(New instructions)에 맞춰 생성 능력을 계속 확장해 나가는 모습입니다.
요약하자면: Figure 2는 "새로운 지시, 지식, 모달리티, 행동, 창작물"을 학습할 때 건망증(Catastrophic Forgetting) 없이 현실 세계의 요구에 적응하는 것이 Generative AI 연속 학습의 핵심 목표임을 4가지 분야로 나누어 예시로 보여주고 있습니다.
2 OVERVIEW OF CONTINUAL LEARNING
2.1 Basic Formulation
Continual learning은 서로 다른 tasks의 training samples가 순차적으로 도착하는, dynamically evolving data distributions로부터 knowledge를 습득하는 challenge를 다룹니다. Continual learning model은 모든 tasks에 대해 강력한 performance를 유지하면서, 일반적으로 과거 data에 대한 접근을 제한하거나 방지하는 constraints 하에서, 이전에 학습된 information을 보존하는 동시에 new knowledge를 동화해야 합니다. 공식적으로, 총 $T$개의 continual learning tasks가 있다고 가정해 봅시다. Task $t$에 대한 training samples는 $\mathcal{D}_t = {(x, y)}$로 표현될 수 있으며, 여기서 $x$는 input data이고 $y$는 그에 상응하는 label입니다.
주목할 점은, 필요한 training data의 유형은 다양한 generative models에 따라 다르다는 것입니다. 예를 들어, MLLM에서 $(x, y)$는 일반적으로 input images, user instructions, 그리고 target answers $(X_v, X_{ins}, X_a)$로 구성된 triplet으로 이루어집니다. VLA models에서는 state-action pairs $(S, A)$의 형태를 취할 수 있으며, 여기서 state $S$는 image observation과 text instruction을 포함합니다. Task $t$의 training 동안에는 현재 task의 data에만 접근할 수 있습니다. 각 continual learning task의 training objective는 다음과 같이 공식화할 수 있습니다:
여기서 $f_{\theta}$는 generative model을 나타내며, $\ell(\cdot, \cdot)$은 task-specific loss function입니다. 각 generative model에 대한 구체적인 formulation은 해당 섹션의 시작 부분에 자세히 설명되어 있습니다.
$t$번째 task에 대한 training이 완료되면, model은 현재 input에 대한 어떠한 task identity information에도 접근하지 못한 채, 이전에 보았던 모든 tasks의 test sets에 대해 evaluated 됩니다. Generative models를 위한 이상적인 continual learning framework는 현재 task에 대한 포괄적인 learning을 가능하게 하고, 이전에 습득한 knowledge를 보존하며, 미래의 unseen tasks에 대해 강력한 generalization을 보여주어야 합니다.
2.2 Evaluation Metrics
Model의 continual learning ability에 대한 evaluation은 일반적으로 세 가지 측면을 포함합니다: 학습된 모든 tasks에 대한 overall performance, 이전에 학습된 tasks에 대한 forgetting 정도, 그리고 unseen tasks에 대한 generalization capability입니다. 명확성을 위해, model이 task 1부터 task $t$까지 순차적으로 trained된 후 $k$번째 task에 대한 performance를 $a_{t,k}$로 표기합니다.
Overall performance는 일반적으로 Last Accuracy (Last)와 Average Accuracy (Avg)를 포함합니다. 이 두 metrics는 $t$번째 task에 대해 training한 후 다음과 같이 계산됩니다:
여기서 Last는 현재 task에 대한 model의 average performance를 반영하며, Avg는 이전 tasks 전반에 걸친 performance를 추가적으로 종합합니다. 두 metrics 모두 값이 높을수록 우수한 continual learning performance에 해당합니다.
Forgetting evaluation은 일반적으로 두 가지 핵심 metrics인 forgetting measure (FM)와 backward transfer (BWT)를 포함합니다. 전자는 먼저 각 seen task에 대한 forgetting 정도를 계산하는데, 이는 역사적으로 가장 높았던 accuracy와 현재 accuracy의 차이에서 도출됩니다:
FM은 task $t$ 시점에서 모든 previous tasks에 걸친 average forgetting degree로 계산됩니다:
BWT는 $t$번째 task를 learning하는 것이 이전에 학습된 모든 tasks의 performance에 미치는 평균적인 영향을 정량화합니다:
FM은 catastrophic forgetting을 정량화하며, 값이 낮을수록 previous knowledge의 보존이 더 잘 되었음을 나타냅니다. BWT는 tasks 간의 knowledge transfer를 평가하며, 양수 값(즉, BWT > 0)은 prior tasks에 유익한 forward transfer를 반영하고 음수 값(즉, BWT < 0)은 간섭을 나타냅니다.
Generalization capability는 zero-shot transfer (ZT)로 평가할 수 있으며, 이는 training process 전반에 걸쳐 zero-shot transferability가 얼마나 잘 유지되는지 정량화하기 위해 설계되었습니다. 공식적으로, task $k$에 대해, 이는 선행 tasks에 대해 trained된 models가 task $k$에서 평가된 average accuracy $A_k$를 계산합니다:
ZT는 final task에 대해 training한 후 $A_k$의 평균입니다:
ZT의 높은 값은 continual learning process 전반에 걸쳐 unseen tasks에 대한 zero-shot generalization capability가 우수하게 보존되었음을 입증합니다.
$a_{t,k}$의 계산은 구체적인 task type에 의존한다는 점을 언급할 가치가 있습니다. 예를 들어, text generation task를 위한 Bilingual Evaluation Understudy (BLEU), visual grounding task를 위한 Intersection-over-Union (IoU), text-to-image generation task를 위한 Fréchet Inception Distance (FID) 등입니다. 이 외에도 여러 다른 evaluation criteria가 있으며, 상세한 사양에 대해서는 독자들이 원본 논문들을 참조하기를 권합니다.
2.3 Taxonomy
Hippocampus에서의 rapid learning과 neocortex에서의 long-term integration의 협력적 메커니즘에서 영감을 받아, continual learning methods는 체계적으로 다음 세 가지 approaches로 분류될 수 있습니다.
Architecture-based methods는 dynamic network expansion 또는 task-specific knowledge를 격리하기 위한 modular design을 통해 brain의 modular organization을 모방합니다. 이러한 methods는 일반적으로 별도의 network modules 내에 그러한 knowledge를 캡슐화합니다. Model sizes가 커짐에 따라, 기존 approaches는 knowledge를 저장하고 적응시키기 위해 점점 더 Parameter-Efficient Fine-Tuning (PEFT) techniques (예: LoRA 및 Prompts)를 채택하고 있습니다. 공식적으로, $\theta_{old}$를 현재 task에 대한 training 동안 frozen 상태로 유지되는 model parameters라고 합시다. 여기에는 일반적으로 backbone network와 previous tasks와 연관된 extended sub-network가 포함됩니다. 현재 task에 특화된 parameters는 $\theta_{new}$로 표기되며, 이는 일반적으로 유일한 trainable components입니다. 이 시점에서 식 (1)은 다음과 같이 다시 쓰여집니다:
Generative model은 본질적으로 강력한 generalization capabilities를 가지고 있기 때문에, 상대적으로 적은 parameters를 가진 이러한 submodules는 task-specific knowledge를 효과적으로 유지할 수 있습니다. Inference 동안, 이 부류의 methods에 대한 핵심 challenges 중 하나는 input sample에 기반하여 적절한 sub-module을 효과적으로 선택하는 것입니다.
Regularization-based methods는 learned representations를 보존하기 위해 중요한 parameters를 제약함으로써 neocortical synaptic stability와 metaplasticity를 모방하며, 이는 생물학적 selective consolidation을 반영합니다. 이 목표를 달성하기 위해, generative models는 종종 parameter space 또는 feature space에서 regularization을 사용하며, 전자는 다음과 같이 공식화됩니다:
여기서 $\lambda$는 사전에 정의된 hyperparameter이고, $\Omega(\cdot, \cdot)$는 현재 parameter $\theta$와 old task parameter $\theta_{old}$ 사이의 제약을 강제하는 regularization term (예: L2 norm)입니다.
여기서 $\phi = f_{\theta}(x)$는 model에 의해 추출된 output features 또는 logits를 나타내며, $\mathcal{R}(\cdot, \cdot)$은 previous tasks로부터 학습된 representations를 보존하기 위해 사용되는 feature regularization term (예: knowledge distillation)입니다. 이러한 methods의 중심적인 challenge는 new knowledge의 습득에 미치는 영향을 최소화하면서 prior tasks의 knowledge를 효과적으로 유지하는 regularization terms를 고안하는 것입니다.
Replay-based methods는 new task training 동안 past experiences를 다시 방문하기 위해 raw data를 저장하거나 synthetic samples를 generating함으로써 hippocampal memory replay mechanisms를 복제하여, catastrophic forgetting을 효과적으로 완화합니다. 실제로, 이 approach는 일반적으로 previous tasks의 data 중 subset을 저장하는 auxiliary memory buffer $\mathcal{M}$을 유지하는 것을 포함하며, 이는 현재 task data와의 joint training에 사용됩니다:
Generative models의 경우, replay-based continual learning methods의 핵심 challenge는 memory buffers의 제한된 용량에서 기인합니다. 이러한 constraint를 고려할 때, rehearsal을 위해 작지만 대표성 있는 past samples의 subset을 선택하는 것이 중요한 문제가 됩니다. 또한, data privacy 및 storage overhead와 같은 실용적인 우려를 고려하여, 여러 approaches는 raw samples를 저장하는 대신 previous tasks의 intermediate representations (예: features 또는 hidden states)를 유지하는 것을 선택함으로써 직접적인 data retention과 관련된 위험과 비용을 완화합니다.
이에 따라, 우리는 Figure 3에 묘사된 바와 같이 위에 개요 된 taxonomy에 따라 기존의 generative model-based continual learning approaches를 분류합니다. 특히, 상호 연결된 neural units를 통한 brain의 복잡한 정보 분산 처리를 반영하여, 이러한 methods는 종종 여러 상호 의존적인 modules로 구성됩니다. 분석적 명확성을 위해, 각 method는 주로 주요 functional component에 기반하여 분류되며, 추가적인 design dimensions는 해당 설명 섹션 내에서 자세히 소개됩니다.
2. OVERVIEW OF CONTINUAL LEARNING 정리노트 (AI 연구자용)
본 섹션은 Generative Models를 위한 Continual Learning (CL)의 수학적 정식화, 평가 지표, 그리고 방법론적 분류 체계(Taxonomy)를 정의합니다.
1. Basic Formulation & Objective
- Goal: 순차적으로 도착하는 $T$개의 Tasks ($D_t$)에 대해, 과거 Data 접근이 제한된 상황에서 Catastrophic Forgetting 없이 New Knowledge를 학습하고 Future Unseen Tasks에 대한 Generalization 성능을 확보.
- Data Structure per Model: Generative Models의 종류에 따라 Training data $(x, y)$의 구성이 상이함.
- MLLM: Triplet 구조 $(X_v, X_{ins}, X_a)$ (Image, Instruction, Answer).
- VLA: State-Action pairs $(S, A)$ (Image observation + Text instruction, Action).
- Optimization Objective:
- $$\arg \min_{\theta} \mathbb{E}_{(x,y)\sim \mathcal{D}_t} [\ell(f_{\theta}(x), y))]$$
2. Evaluation Metrics
모델의 성능은 크게 Overall Performance, Forgetting, Generalization 세 가지 축으로 평가됨.
- Overall Performance:
- Average Accuracy ($Avg_t$): 현재 시점까지 학습한 모든 Task의 평균 성능.
- Last Accuracy ($Last_t$): 현재 Task에 대한 학습 직후의 성능 평균.
- Forgetting & Transfer:
- Forgetting Measure ($FM_t$): 과거 Task들의 최고 성능 대비 현재 성능의 하락폭 평균. (낮을수록 좋음)
- $$f_{k,t} = \max_{i \in \{1,\dots,t-1\}} (a_{i,k} - a_{t,k})$$
- Backward Transfer ($BWT_t$): 새로운 학습이 과거 Task 성능에 미치는 영향. ($BWT > 0$: 긍정적 전이, $BWT < 0$: 간섭)
- Generalization (Generative AI 특화):
- Zero-shot Transfer ($ZT$): 학습 과정 중 Unseen Future Tasks에 대한 Zero-shot 성능 유지력 평가. Open-world 시나리오에서 중요함.
- $$ZT = \frac{1}{T - 1} \sum_{k=2}^{T} A_k$$
3. Taxonomy of Approaches
뇌과학적 기전(Hippocampus의 Rapid learning vs Neocortex의 Consolidation)에 영감을 받아 3가지로 분류.
- Architecture-based Methods (Modular Organization):
- Concept: Task별로 Network Modules를 격리하거나 동적으로 확장하여 간섭 방지.
- Recent Trend: 모델이 거대해짐에 따라 **PEFT (LoRA, Prompts)**를 활용해 $\theta_{new}$만 학습하고 $\theta_{old}$는 Frozen하는 방식이 주류.
- Objective:
- $$\arg \min_{\theta_{new}} \mathbb{E}_{(x,y)\sim \mathcal{D}_t} [\ell(f_{\theta_{old} \cup \theta_{new}}(x), y))]$$
- Challenge: Inference 시 Input에 맞는 적절한 Sub-module을 선택하는 것(Routing).
- Regularization-based Methods (Synaptic Stability):
- Concept: 중요한 Parameter가 변하지 않도록 제약(Constraint)을 검.
- Parameter Regularization: Weight 변화에 Penalty 부여 (예: L2 norm).
-
$$\arg \min_{\theta} \mathbb{E}_{(x,y)\sim \mathcal{D}_t} [\ell(f_{\theta}(x), y)) + \lambda \cdot \Omega(\theta, \theta_{old})]$$
- Feature Regularization: Output Logits나 Feature map 보존 (예: Knowledge Distillation).
-
$$\arg \min_{\theta} \mathbb{E}_{(x,y)\sim \mathcal{D}_t} [\ell(f_{\theta}(x), y)) + \lambda \cdot \mathcal{R}(\phi, \phi_{old})]$$
- Challenge: New Knowledge 습득(Plasticity)과 기존 지식 보존(Stability) 사이의 Balance 조절.
- Replay-based Methods (Memory Replay):
- Concept: 과거 Data의 일부(Buffer)를 저장하거나 생성하여 현재 Data와 Joint Training.
- Objective:
-
$$\arg \min_{\theta} \mathbb{E}_{(x,y)\sim (\mathcal{D}_t \cup \mathcal{M})} [\ell(f_{\theta}(x), y))]$$
- Challenge & Trend: Generative Models에서는 Buffer Size 한계가 큼. 최근에는 Raw Data 저장 대신 Intermediate Representations를 저장하여 Privacy 및 Storage 문제를 해결하는 추세.
쉬운 설명 : 2. OVERVIEW OF CONTINUAL LEARNING
이 섹션은 AI가 연속으로 공부할 때(Continual Learning) **"어떻게 가르칠 것인가?"**와 **"성적표를 어떻게 낼 것인가?"**에 대한 규칙을 설명합니다.
- 기본 규칙 (Formulation):
- AI는 수학($Task 1$)을 배우고, 그 다음에 영어($Task 2$)를 배웁니다.
- 이때 중요한 건, "옛날 교과서(과거 데이터)를 다시 펼쳐보지 않고도" 수학 공식을 까먹지 않아야 한다는 점입니다.
- 모델 종류(글, 그림, 로봇)에 따라 공부하는 자료의 형태는 다릅니다.
- 성적표 (Evaluation Metrics): AI가 공부를 잘했는지 3가지 기준으로 평가합니다.
- 종합 성적 (Overall): 지금 시험 보면 평균 몇 점인가?
- 기억력 (Forgetting): 예전에 100점 맞았던 과목이 지금은 몇 점으로 떨어졌는가? (점수가 덜 떨어져야 좋음)
- 응용력 (Generalization - ZT): 아직 안 배운 과목(예: 과학) 문제를 던져줬을 때, 엉뚱한 답을 안 하고 얼마나 잘 찍는가? (생성형 AI에서는 이 '센스'가 중요합니다)
- 공부 방법 3가지 (Taxonomy): 뇌가 기억을 저장하는 방식을 본따서 3가지 전략을 씁니다.
- Architecture-based (노트 나누기): 수학 노트와 영어 노트를 따로 씁니다. 뇌의 구획을 나누는 것과 같습니다. 요즘은 책 전체를 다시 쓰는 게 힘드니까, 포스트잇(PEFT/LoRA)만 붙여서 공부하는 방식이 유행입니다.
- Regularization-based (중요한 것 표시하기): 기존 지식 중에 중요한 부분은 "절대 지우지 마!"라고 락을 걸어두는 겁니다. 뇌세포 연결을 단단하게 유지하는 것과 비슷합니다.
- Replay-based (오답 노트 복습): 새로운 걸 배울 때, 예전에 배운 내용 중 아주 일부만(핵심 요약) 가져와서 같이 훑어보는 방식입니다. 뇌가 잘 때 기억을 되감기(Replay) 하는 것과 같습니다.
3 CONTINUAL LEARNING FOR LARGE LANGUAGE MODELS
최근 몇 년간, Large Language Models (LLMs)는 massive general-domain text corpora에 대한 pre-training을 통해 뛰어난 natural language understanding 및 generation capabilities를 입증했습니다. Real-world applications에서 높은 성능을 유지하기 위해, LLMs는 data, tasks, user preferences가 진화함에 따라 새로운 information을 통합하고 prior knowledge를 유지할 수 있는 능력이 필요합니다. 전통적인 language models와 달리, LLMs는 모든 task를 autoregressive next-token prediction을 통한 generative sequence prediction 문제로 취급합니다. 이들의 massive parameterization은 few-shot learning 및 복잡한 multi-step reasoning을 포함한 emergent capabilities를 가능하게 합니다. 결과적으로, 더 작은 models를 위해 설계된 많은 conventional continual learning methods는 LLMs에 효과적으로 적응하는 데 어려움을 겪습니다.
다음 섹션에서는 먼저 training objectives, 일반적으로 사용되는 model backbones, 널리 채택된 benchmarks를 포함한 LLM continual learning task의 setup을 개괄합니다(Section 3.1). 다음으로, 기존 연구를 architecture-based(Section 3.2), regularization-based(Section 3.3), replay-based(Section 3.4) approaches의 세 가지 strategies로 분류