

AI바라기의 인공지능
VLM : 논문 리뷰 : Reasoning via Video: The First Evaluation of Video Models’ Reasoning Abilities through Maze-Solving Tasks 본문
VLM : 논문 리뷰 : Reasoning via Video: The First Evaluation of Video Models’ Reasoning Abilities through Maze-Solving Tasks
AI바라기 2025. 11. 27. 20:42
Terminology
- Reasoning via Video: 텍스트(Text)로 추론 과정을 서술하는 것이 아니라, 비디오의 Next-frame generation 과정을 통해 시각적, 물리적 인과관계를 연속적으로 시뮬레이션하며 문제를 해결하는 패러다임.
- Reasoning via Text: 기존 VLM들이 사용하는 방식으로, 시각 정보를 텍스트 토큰으로 변환한 뒤 언어 모델의 연산 능력에 의존해 추론하는 방식.
- VR-Bench (Visual Reasoning Benchmark): 이 논문에서 제안한 벤치마크로, 5가지 유형(Regular, Irregular, Trapfield, Sokoban, 3D Maze)의 미로 찾기 문제로 구성된 7,920개의 비디오 데이터셋.
- Chain-of-Frame (CoF): LLM의 Chain-of-Thought(CoT)에 대응하는 개념으로, 정답 경로를 프레임 단위로 연속적으로 생성하여 시각적 추론 궤적을 형성하는 것.
- Test-Time Scaling: 학습 단계가 아닌, 추론(Inference) 단계에서 샘플링 횟수(budget)를 늘려 다양한 경로를 탐색하고 정답 확률을 높이는 기법. (LLM의 Self-Consistency와 유사)
- SFT (Supervised Fine-Tuning): 사전 학습된 비디오 모델을 VR-Bench 데이터로 미세 조정하여 추론 능력을 극대화하는 과정.
- VLM-as-Judge: 생성된 비디오가 물리적 규칙(벽 통과 금지 등)을 잘 따랐는지 사람이 아닌 VLM(예: GPT-4o)을 사용하여 평가하는 방식.
Purpose of the Paper
- Existing Gap: 기존 비디오 생성 모델 평가는 주로 시각적 품질(Fidelity)이나 모션의 자연스러움에 치중되어 있었으며, 모델의 **논리적 문제 해결 능력(Reasoning)**을 평가하는 체계적인 벤치마크가 부재했음.
- Problem Definition: 기존 VLM들의 Reasoning via Text 방식은 공간적 정보를 1차원 텍스트 토큰으로 압축하는 과정에서 정보 손실이 발생하고, 긴 호흡(Long-horizon)의 공간 추론에 취약함.
- Goal: "비디오 모델이 텍스트 없이 비디오 생성만으로 복잡한 공간 추론을 수행할 수 있는가?"라는 질문에 답하기 위해, Reasoning via Video 패러다임을 제안하고 이를 검증할 수 있는 엄격한 테스트베드(VR-Bench)를 구축함.
Key Contributions
- Paradigm Shift to Reasoning via Video:
- 추론을 'Next-token prediction'이 아닌 **'Next-frame prediction'**으로 재정의함.
- 비디오의 시공간적 연속성(Spatiotemporal continuity)이 복잡한 공간 추론 문제(미로 등)에 더 적합한 기질(Substrate)임을 입증함.
- VR-Bench Construction:
- 단순 비디오 생성이 아닌 Visual Trace Reasoning (VTR) 과제를 수행하도록 설계됨.
- Novelty: 2D/3D 미로, Sokoban(상자 밀기), Trapfield(함정 피하기) 등 다양한 물리/공간 규칙을 포함하며, 정답 경로(Ground Truth)와 비교하여 픽셀 단위의 궤적 정확도를 평가할 수 있음.
- Empirical Analysis & SFT Efficiency:
- Open-source 비디오 모델(Wan2.1)을 SFT하여 Wan-R1을 개발, SFT가 비디오 모델의 잠재된 추론 능력을 효과적으로 이끌어냄을 증명.
- 난이도(Difficulty), 질감(Texture), 미로 유형(Maze Type)에 대한 강력한 Generalization 능력을 확인.
Experimental Highlights
- Baselines: Wan-R1(Ours) vs. Closed-source Models (Sora-2, Veo-3, Gemini-2.5-pro, GPT-5 high) vs. Open-source VLMs.
- Key Findings:
- Video Models Outperform VLMs: 복잡한 미로(Irregular, Trapfield)나 난이도가 높은(Hard) 설정에서 Reasoning via Video 방식이 Reasoning via Text (VLM) 방식보다 압도적인 성능을 보임. VLM은 미로가 커질수록(Context length 증가) 성능이 급격히 하락함.
- Wan-R1 Performance: SFT된 Wan-R1 모델은 학습하지 않은 Hard 난이도나 새로운 Maze Type에서도 높은 Success Rate(SR)를 달성 (예: 3D Maze에서 SR 100.0 달성).
- Test-Time Scaling Effect (Novel Discovery):
- 추론 시 샘플링 횟수()를 늘릴수록 성능이 비약적으로 향상됨 (10~20% gain).
- K
- 이는 비디오 모델이 다양한 해결 경로를 탐색할 수 있으며, 더 많은 연산 자원(Inference Budget)을 투입하면 추론 신뢰도가 높아짐을 시사 (LLM의 Scaling law와 유사).
- Metrics: Exact Match (EM), Success Rate (SR), Step Deviation (SD, 경로 효율성).
Limitations and Future Work
- Limitations:
- Task Specificity: 현재 VR-Bench는 미로(Maze) 및 경로 탐색 문제에 집중되어 있어, 더 일반적인 물리 상식이나 인과관계 추론까지 포괄하지는 않음.
- Evaluator Reliability: VLM-as-Judge가 사람의 평가와 높은 상관관계를 보이지만, 완벽하지는 않음.
- Future Work:
- Task Expansion: 올림피아드 수준의 물리/수학 문제를 비디오 시각화를 통해 해결하는 과제로 확장 예정.
- Embodied Reasoning: 단순히 영상을 생성하는 것을 넘어, 상호작용 가능한 환경에서 일련의 행동(Action)을 예측하고 시뮬레이션하는 연구로 발전시킬 계획.
Overall Summary
이 논문은 비디오 생성 모델을 단순한 크리에이티브 도구가 아닌 **시각적 시뮬레이션을 통한 추론 엔진(Reasoning Engine)**으로 재조명합니다. 연구팀은 7,920개의 미로 해결 과제로 구성된 VR-Bench를 구축하고, 이를 통해 비디오 모델이 텍스트 기반 모델(VLM)보다 복잡한 공간 추론에 더 효과적임을 입증했습니다. 특히, Test-Time Scaling을 통해 비디오 생성 모델도 추론 시 연산량을 늘리면 성능이 향상된다는 점을 발견하여, 향후 Visual OpenAI o1과 같은 '생각하는 비디오 모델'의 발전 가능성을 시사했습니다.
쉬운 설명
이 논문의 핵심 아이디어는 **"말로 설명하는 것(Text)보다 직접 그려보는 것(Video)이 문제 해결에 더 낫다"**는 것입니다.
- 기존 방식 (VLM): 복잡한 미로를 보고 "위로 3칸, 오른쪽으로 2칸..."이라며 말로 풀려고 하니, 미로가 커지면 헷갈려서 길을 잃습니다.
- 이 논문의 방식 (Video Model): 말로 설명하는 대신, 직접 펜으로 길을 따라 그리는 영상을 만들어냅니다. 이렇게 하니 벽에 부딪히는지, 함정이 있는지를 시각적으로 계속 확인하면서 길을 찾을 수 있어 훨씬 더 똑똑하게 문제를 풉니다.
- 발견: 심지어 한 번에 그리는 것보다, 여러 번 그려보고 그중 가장 좋은 것을 고르게 했더니(Test-Time Scaling), 정답률이 훨씬 올라갔습니다. 즉, 비디오 모델도 "생각할 시간(연산량)"을 더 주면 더 똑똑해진다는 것을 밝혀냈습니다.
Abstract
Video Models는 coherent motion dynamics를 갖춘 high-fidelity video generation에서 놀라운 성공을 거두었습니다.
Language modeling에서 text generation으로부터 text-based reasoning으로 발전한 것과 유사하게, video models의 발전은 우리에게 다음과 같은 질문을 던지게 합니다. Video models가 video generation을 통해 reason할 수 있을까요? Discrete text corpus와 비교할 때, video는 explicit spatial layouts와 temporal continuity에 reasoning의 기반을 두며, 이는 spatial reasoning을 위한 이상적인 토대가 됩니다.
본 연구에서 우리는 reasoning via video paradigm을 탐구하고, video models의 reasoning capabilities를 체계적으로 평가하기 위해 설계된 comprehensive benchmark인 VR-Bench를 소개합니다. 본질적으로 spatial planning과 multi-step reasoning을 필요로 하는 maze-solving tasks에 기반을 둔 VR-Bench는, 5가지 maze types와 다양한 visual styles에 걸쳐 7,920개의 procedurally generated videos를 포함하고 있습니다.
우리의 empirical analysis는 SFT가 video model의 reasoning ability를 효율적으로 이끌어낼 수 있음을 보여줍니다. Video models는 reasoning 과정에서 더 강력한 spatial perception을 보여주며, 선도적인 VLMs를 능가하고 다양한 scenarios, tasks, 그리고 complexity levels 전반에 걸쳐 훌륭하게 generalizing합니다.
더 나아가 우리는 inference 중에 diverse sampling이 reasoning reliability를 10–20% 향상시키는 test-time scaling effect를 발견했습니다. 이러한 발견들은 spatial reasoning tasks를 위한 reasoning via video의 고유한 잠재력과 scalability를 강조합니다.
1. Introduction
Diffusion-based 및 autoregressive-based generative architectures의 급속한 발전으로, video models는 high-fidelity video generation에서 엄청난 성공을 목격했습니다. Stable Video Diffusion 및 Imagen Video와 같은 이전 연구들은 input instructions를 조건으로 physically realistic하고 temporally consistent videos를 생성하는 video models의 능력을 보여줍니다. 최근 연구들은 더 나아가 advanced video models가 generation 그 자체를 넘어 perception, understanding, 심지어 reasoning을 포함한 다양한 visual tasks를 수행할 수 있음을 밝혀냈습니다. 이러한 발견들은 video models가 순수한 generative models에서 general-purpose visual intelligence models로 진화하고 있음을 시사합니다. Language models가 text generation에서 text-based reasoning으로 진화한 것과 유사하게, video models의 발전은 다음과 같은 질문으로 이어집니다: "Video models가 video generation을 통해 reason할 수 있을까요?"
결정적으로, video modality의 spatiotemporal nature는 reasoning에 대한 새로운 관점을 제공합니다. 우리가 reasoning via text라고 부르는 전통적인 paradigm은 intermediate reasoning steps를 표현하기 위한 매체로 language를 사용합니다. Chain-of-Thought prompting과 같은 대표적인 연구는 large language models (LLMs)를 이끌어내어 일관된 textual reasoning chain을 생성함으로써 이를 달성합니다. 최근, 이 reasoning via text paradigm은 multimodal question answering 및 video understanding을 포함한 visual domains에 도입되었습니다. 그러나 이러한 multimodal settings에서도, 현재의 paradigms는 여전히 visual 또는 physical dynamics 대신 textual continuation을 통해 reasoning을 표현합니다. 대조적으로, video는 reasoning을 시간의 흐름에 따른 visual continuation의 과정으로 표현합니다. Video의 각 frame은 이전 frames를 기반으로 구축되며, 2D 및 3D space 내에서 dynamics of motion, spatial consistency, 그리고 temporal causality를 포착합니다. Frames의 continuous하고 structured nature는 video를 multimodal reasoning을 위한 이상적인 기질(substrate)로 만듭니다. 이러한 통찰을 바탕으로, 우리는 next-token prediction이 아닌 next-frame generation을 통해 reasoning이 나타나는 reasoning via video를 제안합니다.
그러나 reasoning via video를 위한 포괄적인 testbed가 부족합니다. 이를 위해, 우리는 video generation models의 reasoning capabilities를 체계적으로 평가하도록 설계된 전용 benchmark인 VR-Bench를 소개합니다. Figure 1에서 볼 수 있듯이, 우리는 benchmark를 maze-solving task에 기반을 두었는데, 이는 open-ended solution space와 풍부한 trajectory-based supervision으로 인해 visual reasoning에 자연스럽게 적합하기 때문입니다. 각 instance는 본질적으로 spatial planning, dynamic tracking, 그리고 multi-step reasoning을 요구하므로, 시간 경과에 따른 model inference quality를 평가하기 위한 이상적인 testbed가 됩니다. 우리의 dataset은 7,920개의 procedurally generated maze-centric videos로 구성되며, 각 비디오는 models가 optimal path를 추론해야 하는 Trace Reasoning Task와 짝을 이룹니다. 광범위한 generalizability를 보장하고 model robustness를 시험하기 위해, VR-Bench는 Regular Maze, Irregular Maze, 3D Maze, Sokoban, Trapfield의 5가지 뚜렷한 maze types에 걸쳐 있으며, 광범위한 spatial structures와 decision patterns를 포괄합니다. 또한, 각 maze는 12개 이상의 themes에 걸쳐 다양한 visual styles로 렌더링되어, models가 다양한 visual domains 전반에서 얼마나 잘 generalize하는지에 대한 fine-grained analysis를 가능하게 하고 reasoning tasks의 realism과 complexity를 높입니다.
제안된 VR-Bench를 바탕으로, 우리는 reasoning via video paradigm에 대한 systematic study를 수행합니다. 우리는 open-source video models의 reasoning capability를 이끌어내기 위해 VR-Bench에서 파생된 instruction-following datasets를 구축합니다. Supervised fine-tuning (SFT) 후, 이 models는 VR-Bench의 모든 reasoning tasks에서 상당한 performance gain을 보여줍니다. 게다가 SFT는 video models에게 task difficulty, background style, task type을 포함한 다양한 distribution shifts 하에서 강력한 out-of-domain generalization을 부여합니다. Reason via text 방식을 사용하는 vision–language models (VLMs)와 비교할 때, video models는 high-complexity reasoning tasks에서 지속적으로 대응 모델들을 능가하며, 다양한 scenarios와 tasks에 걸쳐 task difficulty가 증가함에 따라 더 큰 stability와 심지어 우월한 performance를 보여줍니다. 이 결과는 video가 spatial reasoning을 위한 더 expressive substrate 역할을 하며, 이는 video models가 temporal continuity와 dynamic visual context를 활용하도록 촉진함을 확인시켜 줍니다. 흥미롭게도, 우리는 video models가 LLMs의 것과 유사한 test-time scaling effect를 보인다는 것을 추가로 관찰했습니다. Inference budget이 증가함에 따라 performance가 상당히 향상됩니다. Test time에 diverse sampling strategies를 채택함으로써, video models는 여러 reasoning trajectories를 효과적으로 탐색하여 uncertainty를 줄이고 10–20%의 평균 performance gain을 달성합니다. 이러한 경험적 결과들은 reasoning via video paradigm의 고유한 잠재력과 scalability를 강조합니다.
우리의 contributions는 다음과 같이 요약됩니다:
- 우리는 token prediction이 아닌 sequential frame generation에서 reasoning이 나타나는 reasoning via video paradigm에 대한 초기적이고 체계적인 탐구를 수행합니다. Text-based approaches와 비교할 때, 이 paradigm은 temporal continuity와 spatial causality를 자연스럽게 포착하여, spatial reasoning tasks를 해결하기 위한 더 expressive하고 scalable substrate를 제공합니다.
- 우리는 다양한 spatial structures, difficulty levels, texture styles를 갖춘 maze-solving tasks에 기반을 둔 comprehensive benchmark인 VR-Bench를 구축합니다. 이는 fine-grained trajectory-level supervision을 제공하며 path accuracy, rule compliance, generalization에 대한 평가를 지원합니다.
- 광범위한 실험을 통해, 우리는 video-based reasoning이 특히 maze type, visual style, difficulty의 distribution shifts 하에서 complex tasks에 대해 text-based reasoning (예: VLMs)을 능가함을 입증합니다. Fine-tuned video models는 더 강력한 performance, 더 낮은 path redundancy, 그리고 더 높은 structural fidelity를 보여줍니다.
- 우리는 더 큰 inference budgets에서 performance가 지속적으로 향상되는 video models를 위한 test-time scaling effect를 밝혀냅니다. LLMs에서의 경우와 유사하게, diverse sampling은 multi-path exploration을 가능하게 하며 metrics 및 difficulty levels 전반에 걸쳐 최대 20%의 performance gains를 산출합니다.
1. Introduction 핵심 정리 노트 (for AI Researchers)
1. Paradigm Shift: Reasoning via Text $\rightarrow$ Reasoning via Video
- Motivation: Language models가 text generation에서 text-based reasoning (CoT 등)으로 진화한 것처럼, Video models도 pure generative models에서 general-purpose visual intelligence로 진화 중.
- Problem: 기존의 multimodal approaches (VLMs)는 여전히 reasoning process를 textual continuation으로 표현함. 이는 physical dynamics나 spatial consistency를 직접적으로 담아내기엔 한계가 있음.
- Proposal: Reasoning via Video paradigm 제안.
- Reasoning은 next-token prediction이 아닌 next-frame generation을 통해 발현됨.
- Video의 frames는 본질적으로 structured nature를 가지며, dynamics of motion, spatial consistency, temporal causality를 포착하는 이상적인 substrate임.
2. VR-Bench: A Comprehensive Testbed
- Task Selection: Maze-solving task를 채택.
- 이유: Open-ended solution space, rich trajectory-based supervision, spatial planning 및 multi-step reasoning 능력 평가에 적합.
- Dataset Specs:
- 7,920 procedurally generated videos.
- Trace Reasoning Task: Optimal path를 추론(생성)하는 과제.
- Diversity: 5가지 Maze Types (Regular, Irregular, 3D, Sokoban, Trapfield) 및 12개 이상의 Visual styles로 구성하여 Generalizability와 Robustness 평가.
3. Key Empirical Findings (vs. VLMs)
- SFT Effect: VR-Bench 기반 Instruction-following datasets로 SFT 수행 시, Video models의 reasoning capability가 크게 향상됨.
- Superiority: High-complexity reasoning tasks에서 Video models가 Reason via text 방식의 VLMs를 능가.
- Task difficulty가 증가할수록 더 높은 stability와 performance를 보임.
- Spatial reasoning에서 video가 text보다 더 expressive substrate임을 입증.
- Generalization: Task difficulty, background style, task type의 distribution shifts 환경에서도 강력한 out-of-domain generalization 성능 확보.
4. Novel Insight: Test-Time Scaling Effect
- Observation: Video models에서도 LLMs와 유사한 Test-time scaling effect가 관찰됨.
- Mechanism: Inference budget을 늘리고 Diverse sampling strategies를 적용하여 multiple reasoning trajectories를 탐색.
- Result: Uncertainty가 감소하며 평균 **$10-20\%$**의 Performance gain 달성. 이는 Video generation 기반 reasoning의 scalability를 시사함.
쉬운 설명 : 비디오 모델이 "생각"하는 새로운 방법
1. 텍스트로 생각하기 vs 비디오로 생각하기
- 지금까지의 AI(챗GPT 등)는 어려운 문제를 풀 때 **글(Text)**을 써내려가며 추론했습니다. (예: "A는 B니까, 정답은 C야.")
- 하지만 이 논문은 **비디오(Video)**를 생성하며 추론하는 방식을 제안합니다. 다음 단어를 예측하는 게 아니라, **다음 장면(Frame)**을 그려내며 문제를 푸는 것이죠. 공간이나 움직임과 관련된 문제는 말로 하는 것보다 직접 그려보는 게 훨씬 정확하기 때문입니다.
2. 미로 찾기로 시험하기 (VR-Bench)
- 이 방식이 통하는지 확인하기 위해 연구진은 AI에게 미로 찾기(Maze-solving) 시험을 봅니다.
- 단순히 "오른쪽으로 가"라고 말하는 게 아니라, AI가 직접 미로를 탈출하는 경로가 그려진 비디오를 생성해야 합니다. 다양한 종류(3D 미로, 장애물 피하기 등)의 미로 7,920개를 준비해 철저히 테스트했습니다.
3. 결과 : 말보다 행동이 낫다
- 실험 결과, 복잡한 공간 추론 문제에서는 글로 답하는 모델(VLM)보다 비디오를 생성하는 모델이 훨씬 더 똑똑했습니다. 문제가 어려울수록 격차는 더 벌어졌습니다.
4. 핵심 발견 : 많이 상상할수록 똑똑해진다
- LLM(거대언어모델)이 생각할 시간을 많이 주면 더 똑똑해지는 것처럼, 비디오 모델도 여러 번 다양하게 시뮬레이션(Sampling) 해보게 하면 정답률이 $10-20%$나 올라간다는 사실을 발견했습니다.
2. Related Works
2.1. Video Generation
Video models는 understanding과 generation 모두에서 급속히 발전했습니다. MViT, Video Swin Transformer, VideoMAE와 같은 초기 understanding methods는 downstream tasks를 위한 robust video representations를 학습하는 데 초점을 맞추었습니다. LLMs와 함께, 최근의 approaches는 videos를 tokenize하고 captioning, event localization, reasoning을 위해 language backbones를 활용합니다. Generation 측면에서는, Sora-2가 synchronized dialogue 및 sound와 함께 controllable하고 physically consistent outputs를 달성했습니다. Runway의 Gen-3, Pika Labs, Luma AI, Google DeepMind의 Veo series와 같은 Proprietary systems는 video quality와 realism을 더욱 향상시키지만 closed-source로 남아 있습니다. 대조적으로 Stable Video Diffusion, OpenSora, HunyanVideo, Wan series와 같은 open-source frameworks는 접근을 민주화하여, state-of-the-art video synthesis를 위한 efficient architectures와 scalable training을 제공합니다.
2.2. Evolution of Reasoning Paradigms
Chain-of-Thought (CoT) prompting은 language models의 reasoning abilities를 크게 향상시켰습니다. Reinforcement learning은 CoT-style reasoning을 model training에 더욱 통합하여, models가 multi-step thought processes를 내면화할 수 있게 합니다. 최근에는 이러한 paradigms가 vision-language models (VLMs)로 확장되었습니다. o3 및 o4-mini와 같은 systems는 "Think with Image" framework를 도입하여, reasoning이 zooming 및 cropping과 같은 visual operations에 기반을 두도록 합니다. 이를 통해 model은 CoT process의 일부로서 image regions와 동적으로 상호 작용할 수 있으며, 그 결과 multimodal reasoning을 향상시킵니다. 이와 동시에, generation과 understanding을 위한 unified models의 부상은 interleaved vision-language outputs를 중심으로 한 새로운 reasoning paradigm을 탄생시켰습니다. 순수하게 textual reasoning traces 대신, 이러한 models는 textual elements와 visual elements 사이를 교차하는 coherent sequences를 생성하여, complex multimodal reasoning을 위한 보다 grounded하고 expressive format을 제공합니다.
2.3. Evaluation of Video Generation Reasoning
Video generation models를 위한 이전의 benchmarks는 주로 visual quality, temporal coherence, 그리고 human preferences와의 alignment를 평가하는 데 중점을 두었습니다. 그러나 이러한 evaluations는 video models의 reasoning capabilities를 대체로 무시했습니다. 최근 연구들은 reasoning via video generation—즉, generation process 자체를 통해 reasoning tasks를 해결하는 models의 능력—을 탐구하기 시작했습니다. 예를 들어, Veo 3와 같은 models는 maze navigation 및 symmetry recognition과 같은 tasks에서 zero-shot competence를 보여줍니다. 이러한 tasks는 visual world를 지각(perceiving), 모델링(modeling), 조작(manipulating)하는 것을 필요로 하며, 이는 video generation이 본질적으로 spatial-temporal reasoning을 지원할 수 있음을 나타냅니다.
이러한 유망한 방향에도 불구하고, 현재의 video reasoning을 위한 benchmarks는 여전히 몇 가지 한계점을 가지고 있습니다: (1) Fine-grained 및 objective evaluation의 부족: 현재의 evaluations는 video에 내재된 reasoning trajectory를 포착하지 못한 채, manual inspection이나 coarse metrics에 크게 의존합니다. (2) Modality comparisons의 부재: Think with text 또는 think with image paradigms와의 체계적인 비교가 부족하여, video generation이 진정으로 reasoning에 대해 고유한 이점을 제공하는지 불분명합니다. (3) Tuning 및 scaling analysis의 무시: Language 또는 multimodal models와 달리, video reasoning benchmarks는 supervised fine-tuning (SFT)이나 test-time scaling이 performance를 향상시킬 수 있는지 거의 탐구하지 않습니다.
이러한 공백들은 generation quality뿐만 아니라 rigorous metrics, multimodal comparisons, 그리고 extensible settings를 사용하여 videos 내의 reasoning process를 평가하는 새로운 benchmark를 요구합니다.
2. Related Works 핵심 정리 노트 (for AI Researchers)
1. Video Generation Landscape: From Quality to Accessibility
- Evolution: Video models는 understanding (MViT, VideoMAE)에서 generation으로 급격히 발전함.
- Current State:
- Proprietary: Sora-2, Gen-3, Veo 등은 physically consistent outputs와 controllable features를 제공하지만 Closed-source.
- Open-source: Stable Video Diffusion, OpenSora, HunyanVideo 등은 efficient architectures와 scalable training을 통해 접근성을 민주화함. $\rightarrow$ 본 연구는 이러한 Open-source models를 기반으로 reasoning capability를 탐구.
2. Reasoning Paradigms: Text $\rightarrow$ Image $\rightarrow$ Video (Target)
- Text-based: CoT prompting과 RL을 통해 multi-step thought processes를 내면화.
- VLM Integration:
- "Think with Image": o3, o4-mini 등은 zooming/cropping과 같은 visual operations를 CoT에 통합하여 multimodal reasoning 수행.
- Interleaved Outputs: Textual elements와 Visual elements가 교차하는 sequence를 생성하여 더 grounded된 reasoning format 제공.
- Implication: 기존 연구들은 text나 static image 기반의 reasoning에 집중되어 있으며, temporal dynamics를 활용한 reasoning은 상대적으로 덜 탐구됨.
3. Evaluation Gaps in Video Reasoning (Critical Motivation)
기존 Benchmarks는 주로 visual quality나 temporal coherence 평가에 편중됨. 최근 Veo 3 등이 maze navigation과 같은 tasks에서 Reasoning via Video Generation의 가능성을 보였으나, 여전히 세 가지 치명적인 한계가 존재함:
- Lack of Fine-grained Evaluation: Reasoning trajectory를 정밀하게 추적하지 못하고 manual inspection이나 coarse metrics에 의존.
- Absence of Modality Comparisons: "Think with Text"나 "Think with Image" paradigm 대비 Video generation이 갖는 고유한 이점에 대한 체계적 비교 부재.
- Neglect of Tuning & Scaling: Video reasoning 성능 향상을 위한 **Supervised Fine-tuning (SFT)**이나 Test-time scaling 효과에 대한 분석 전무.
- $\therefore$ 본 논문은 이러한 한계를 극복하기 위해 generation quality뿐만 아니라 reasoning process 자체를 정량적으로 평가하는 VR-Bench를 제안.
쉬운 설명 : 비디오 AI, '화질' 경쟁에서 '지능' 경쟁으로
1. 비디오 생성 AI의 현재 주소
- 요즘 비디오 AI(Sora 등)는 영상을 정말 진짜처럼 잘 만듭니다. 하지만 지금까지의 연구는 "얼마나 그럴듯하고 예쁜 영상을 만드는가?"에만 집중해 왔습니다.
2. AI가 생각하는 방식의 변화
- 글로 생각하기: 챗GPT는 "논리적인 글"을 쓰면서 문제를 풉니다.
- 이미지로 생각하기: 최신 모델들은 이미지를 확대하거나 잘라보며 "시각적"으로 생각하기 시작했습니다.
- 비디오로 생각하기 (이 논문의 목표): 이제는 시간이 흐르는 "영상"을 통해 인과관계를 따지며 생각하는 단계로 넘어가려 합니다.
3. 왜 새로운 테스트가 필요한가?
- 기존의 테스트 방법들은 비디오의 **때깔(화질, 자연스러움)**만 점수를 매겼습니다.
- AI가 비디오를 만들면서 문제(예: 미로 탈출)를 제대로 풀었는지 채점하는 기준이 없었습니다.
- 또한, 글이나 그림으로 푸는 것보다 비디오로 푸는 게 진짜 더 유리한지, 공부(Fine-tuning)시키면 더 잘하는지 확인해본 적이 없었습니다. 이 논문은 바로 그 빈틈을 파고든 것입니다.

3. VR-Bench
3.1. Dataset Construction
VR-Bench dataset은 다양한 Maze Puzzles를 visual reasoning tasks로 구성하는 Visual Trace Reasoning (VTR) dataset입니다. 그 construction process는 Maze Generation과 Video Generation의 두 단계로 구성됩니다.
Maze Generation. 본 연구의 maze generation process는 5가지 distinct types를 포함하며, dataset 내 7,920개의 모든 maze instances는 custom code를 통해 programmatically generated 되었습니다. 각 type은 아래에 설명된 바와 같이 specific visual reasoning capabilities를 평가하도록 맞춤 설계되었습니다:
- Regular Maze. 우리는 model의 basic maze structures를 perceive하는 능력과 path-finding 및 problem-solving competence에 초점을 맞추기 위해 grid-based layout을 가진 mazes를 생성하며, 이는 maze reasoning tasks를 위한 fundamental testbed 역할을 합니다.
- Trapfield. 이 type은 traditional mazes의 "walls"를 grid-shaped trap regions로 변형하여, "finding feasible paths"에서 "avoiding traps"로 logic을 뒤집습니다. Problem-solving logic을 변경하는 것 외에도, 더 유연한 movement space는 optimal paths를 plan하고 find하는 model의 능력에 도전합니다.
- Irregular Maze. Regular block-shaped paths에서 벗어나, 우리는 curve-based path designs를 채택합니다. 이 design은 model이 coordinate-based position encoding에 의존하는 것을 방지하여, maze layouts에 대한 pure visual perception을 엄격하게 평가합니다. 또한 visual reasoning을 text-based reasoning과 명시적으로 분리하여, video model이 video 자체를 통해 reason하는 capability에 집중합니다.
- Sokoban. 우리는 "Sokoban" task mechanism을 도입하여 traditional mazes의 기본 규칙을 수정합니다. Models는 path finding 위에 Sokoban logic을 이해하고 적용해야 하므로, task complexity가 증가하고 logic을 내면화하고 적용하는 model의 능력이 강조됩니다.
- 3D Maze. Maze를 3D space로 확장함으로써, 우리는 stereoscopic structural design을 사용하여 3D environments에서의 model의 spatial perception ability와 cross-dimensional path reasoning capability를 테스트합니다.
Maze Variations. VTR task에 대한 generalization ability를 평가하고 diverse maze scenarios에 적응하는 robustness를 향상시키기 위해, 우리는 두 가지 주요 차원에서 variations를 도입합니다: (1) Difficulty Level: 우리는 maze size를 조정하고(예: $5 \times 5$에서 $7 \times 7$로 확장), maze branches의 수를 수정하고, obstacles를 추가하여 세 가지 difficulty grades (Easy, Medium, Hard)를 정의합니다; (2) Maze Texture: Figure 6에서 볼 수 있듯이 procedural methods와 generative models를 통해 생성된 textures를 사용하여 maze obstacles, paths, 및 기타 components의 textures를 변화시킵니다. 이는 policies를 광범위한 visual distribution에 노출시키고 clean, synthetic environments에 대한 overfitting을 완화합니다.
Video Generation. Maze images로부터 solution videos를 생성하기 위해, 우리는 Breadth-First Search solver를 사용하여 각 maze에 대한 optimal path를 계산합니다. 이 paths는 24 fps의 videos로 렌더링되고 playback speed를 조정하여 192 frames (8초)로 표준화되어, training과 evaluation을 위한 일관된 image–video pairs를 생성합니다.
3.2. Metric Design
우리는 아래에 상세히 설명된 바와 같이 task를 포괄적으로 평가하기 위해 두 가지 다른 evaluation paradigms를 선택했습니다.
Path Matching. VTR task를 객관적이고 포괄적으로 평가하기 위해, 우리는 model-generated videos의 각 frame에 걸쳐 target tracking을 수행하여 target의 motion trajectory를 기록합니다. 이 trajectories를 각 task에 대한 optimal path와 비교하고 분석하여, 우리는 다음 4가지 evaluation metrics를 제안합니다.
- Exact Match (EM)
- $EM_i = \prod_{j=1}^{n_i} I(\hat{v}{ij} = v{ij})$로 정의됩니다. 이 metric은 model이 shortest optimal valid path와 일치하는 완전하고 올바른 trajectory를 성공적으로 생성했는지 측정합니다. Optimal solution에서 한 단계라도 벗어나면 오답으로 간주됩니다.
- Success Rate (SR)
- $SR_i = I(p^{(gen)}{end} \in B{goal})$로 정의됩니다. SR은 generated trajectory가 지정된 goal region에 성공적으로 도달했는지 측정합니다. 이는 target position에 도착하여 task를 완료하는 model의 capability를 반영하며, 값 1은 성공적인 goal 도달을, 0은 goal 도달 실패를 나타냅니다.
- Precision Rate (PR)
- $PR_i = \frac{1}{n_i} \sum_{j=1}^{n_i} [\prod_{k=1}^{j} I(\hat{v}{ik} = v{ik})]$로 정의됩니다. PR은 optimal path를 따라 연속적으로 올바른 steps의 비율을 정량화합니다. 이는 EM보다 더 부드러운 metric을 제공하며, 완전한 올바른 trajectory를 향해 꾸준하고 의미 있는 진전을 이루는 model의 능력을 반영합니다.
- Step Deviation (SD)
- $SD_i = \frac{L^{(gen)}_i}{L^{(gt)}_i} - 1$로 정의됩니다. SD는 generated trajectory의 상대적인 path-length redundancy를 정량화하여, model의 path가 optimal path에 비해 얼마나 더 긴지를 나타냅니다. 더 작은 SD는 더 높은 efficiency와 optimal solution에 대한 더 가까운 준수를 나타냅니다.
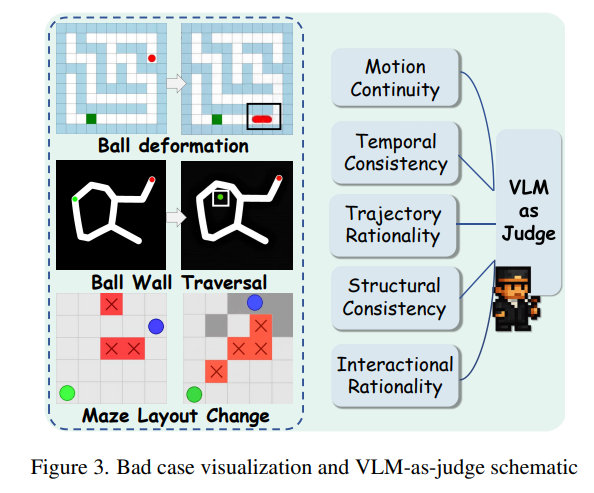
Rule Compliance. 모든 generated videos가 maze path를 따라 task를 완료하는 공을 충실하게 묘사하는 것은 아닙니다. Figure 6에서 볼 수 있듯이, 우리는 testing 중에 공이 "maze walls를 뚫고 지나가거나", "사라졌다 다시 나타나거나", "frames 전반에 걸쳐 maze layouts가 일치하지 않는" 등 수많은 failure cases를 관찰했습니다. Spatial 및 physical rules에 대한 model의 준수를 일관되게 평가하기 위해, 우리는 5가지 주요 차원을 검사하는 prompt-based assessment protocol을 설계했습니다: (1) Main subject의 Motion Continuity, (2) Subject의 Temporal Consistency, (3) Main subject의 Trajectory Rationality, (4) Maze의 Structural Consistency, 그리고 (5) Subject–maze interactions의 Interactional Rationality. 각 generated video는 VLM에 의해 해석되며, VLM은 이러한 rules의 잠재적인 위반을 식별하고 점수를 매깁니다. 구체적으로, 각 차원에는 binary score가 할당됩니다—행동이 비합리적인 경우 0, 합리적인 경우 1입니다. 5가지 차원의 점수는 합산되어 0에서 5까지의 unified VLM-score를 계산하며, 이는 generated videos의 전반적인 rule compliance에 대한 quantitative measure를 제공합니다.
Structural Consistency는 maze layout이 변경되었는지 여부에 대한 binary judgment만을 제공하므로, 우리는 frames 전반에 걸친 structural consistency의 정도를 정량적으로 측정하기 위해 Maze Fidelity (MF)를 도입하며, 이는 다음과 같이 정의됩니다:
여기서 $M$은 sampled frames의 수; $I_0$와 $I_i$는 첫 번째 및 $i$번째 frames의 background regions를 나타내며; $\tau$는 pixel-difference threshold; 그리고 $N_i$는 유효한 overlapping pixels의 수입니다. MF는 frames 전반에 걸친 background stability를 정량화하며, 값이 높을수록 static maze layout의 보존이 더 잘 이루어짐을 나타냅니다.
3. VR-Bench 핵심 정리 노트 (for AI Researchers)
1. Dataset Construction: Visual Trace Reasoning (VTR)
- Concept: Maze Puzzle을 통한 Visual Reasoning 평가 데이터셋. (총 7,920개, Programmatically generated).
- Maze Types (5 Distinct Types): 단순 경로 찾기를 넘어 다양한 능력을 평가하도록 설계.
- Regular: Grid-based. 기본적인 Path-finding & Problem-solving testbed.
- Trapfield: "벽" 대신 "함정" 회피. Logic 반전 (Finding feasible $\rightarrow$ Avoiding traps) 및 Flexible movement space 평가.
- Irregular: Grid를 벗어난 Curve-based paths. Coordinate-based position encoding 의존성을 차단하고 Pure Visual Perception을 평가 (Text-based reasoning과 Decoupling).
- Sokoban: 물체 이동 로직 추가. 단순 경로 탐색을 넘어 Internalize & Apply Logic 능력 요구.
- 3D Maze: Stereoscopic design을 통한 Spatial Perception 및 Cross-dimensional reasoning 평가.
- Robustness Strategy:
- Difficulty: Size ($5 \times 5 \sim 7 \times 7$), Branch 수, Obstacle 조정.
- Texture: Procedural/Generative texture를 적용하여 Visual distribution을 넓히고 Synthetic environment에 대한 Overfitting 방지.
- Data Format: BFS로 계산된 Optimal Path를 24fps, 192 frames (8초) 비디오로 렌더링.
2. Evaluation Paradigm 1: Path Matching (Quantitative)
- Method: 생성된 비디오 내 Target을 Tracking하여 Ground Truth (Optimal Path)와 비교.
- Metrics:
- Exact Match (EM): Optimal path와 완벽히 일치하는지 평가 (Binary, $I(\hat{v}_{ij} = v_{ij})$). 단 한 스텝이라도 빗나가면 Fail.
- Success Rate (SR): Goal region에 도달했는지 여부 ($I(p^{(gen)}_{end} \in B_{goal})$).
- Precision Rate (PR): 첫 에러 발생 전까지 얼마나 많은 step이 정확했는지 비율. EM보다 Soft한 척도.
- Step Deviation (SD): Path-length redundancy 측정 ($\frac{L^{(gen)}_i}{L^{(gt)}_i} - 1$). 값이 작을수록 Optimal path에 근접한 효율적인 경로임.
3. Evaluation Paradigm 2: Rule Compliance (Qualitative/Physics)
- Motivation: 비디오 생성 모델 특유의 Hallucination (벽 뚫기, 객체 소멸, 맵 구조 변경 등) 감지.
- VLM-as-Judge Score: VLM을 사용하여 5가지 차원을 Binary(0/1)로 평가 후 합산(0~5점).
- Motion Continuity: 주체의 움직임이 끊기지 않는가?
- Temporal Consistency: 주체(공)가 시간적으로 일관된가?
- Trajectory Rationality: 이동 경로가 합리적인가?
- Structural Consistency: 미로 구조가 변하지 않는가?
- Interactional Rationality: 벽/함정과의 상호작용이 물리적으로 타당한가?
- Maze Fidelity (MF):
- 배경(Maze Layout)의 일관성을 Pixel-level에서 정량화.
- Frame $0$과 Frame $i$ 간의 Pixel 차이($|I_0(p)-I_i(p)| > \tau$)를 계산하여 구조적 안정성 측정.
쉬운 설명 : AI 비디오 운전면허 시험
1. 시험 코스 (데이터셋)
연구진은 AI에게 5가지 종류의 "운전 코스"를 준비했습니다.
- 일반 도로 (Regular): 평범한 바둑판 미로.
- 지뢰밭 (Trapfield): 벽이 없는 대신 밟으면 안 되는 함정이 있는 곳.
- 비포장 곡선 도로 (Irregular): 네모 반듯하지 않고 구불구불한 길. (좌표로 찍어서 못 풀고 진짜 눈으로 보고 운전해야 함).
- 창고 정리 (Sokoban): 짐을 밀어서 길을 만드는 논리력이 필요한 코스.
- 입체 고가도로 (3D): 3차원 공간지각 능력이 필요한 코스.
2. 채점 기준 (평가 지표)
AI가 만든 비디오를 보고 깐깐하게 채점합니다.
- 목적지 도착했니? (SR): 일단 골인 지점에 갔는지 확인.
- 내비게이션이랑 똑같이 갔니? (EM): 최단 경로랑 토씨 하나 안 틀리고 똑같이 갔는지.
- 얼마나 돌아갔니? (SD): 바로 가면 될 길을 뱅뱅 돌아서 가진 않았는지.
- 물리 법칙은 지켰니? (Rule Compliance):
- 갑자기 벽을 뚫고 지나가진 않았나?
- 자동차가 갑자기 사라졌다 나타나진 않았나?
- 운전 중에 도로 모양이 갑자기 바뀌진 않았나? (이건 Maze Fidelity라는 픽셀 단위 검사로 확인)
- 이 부분은 사람 눈 대신 똑똑한 AI(VLM)가 심판을 봐서 점수를 매깁니다.