

AI바라기의 인공지능
VLM : 논문리뷰 : 논문 정리 노트: Diving into Self-Evolving Training for Multimodal Reasoning 본문
VLM : 논문리뷰 : 논문 정리 노트: Diving into Self-Evolving Training for Multimodal Reasoning
AI바라기 2025. 1. 28. 15:28논문 정리 노트: DIVING INTO SELF-EVOLVING TRAINING FOR MULTIMODAL REASONING
Purpose of the Paper (논문의 목적):
기존 연구들은 multimodal reasoning (다중 모드 추론) 능력을 향상시키기 위한 self-evolving training (자체 진화 학습)에 대한 포괄적인 이해가 부족했습니다. 특히, multimodal 영역에서 self-evolving training의 효과를 체계적으로 분석하고 최적화하는 연구가 미흡했습니다. 이 논문은 multimodal reasoning에서 self-evolving training의 핵심 요소들을 심층적으로 분석하고, 실험적 검증을 통해 효과적인 학습 전략과 디자인 선택을 제시하는 것을 목표로 합니다. 단순한 성능 향상을 넘어, self-evolving training의 근본적인 작동 방식과 최적화 방향을 탐구하여 향후 연구를 위한 견고한 기반을 제공하고자 합니다.
Key Contributions (핵심 기여):
- Multimodal Self-Evolving Training 핵심 요소 분석: Self-evolving training을 RL (Reinforcement Learning, 강화 학습) 관점에서 재조명하여, multimodal reasoning에 특화된 3가지 핵심 요소 (Training Method, Reward Model, Prompt Variation) 를 식별하고 체계적으로 분석했습니다.
- 최적 Training Method 제시: Iterative training과 online RL 간의 간극을 줄이는 Continuous Self-Evolving Training 방식을 제안하고, 다양한 iteration interval 실험을 통해 최적의 학습 효율성을 보이는 설정을 제시했습니다. 이는 기존 iterative 방식의 단점을 보완하고 online 학습에 더 가까운 continuous optimization을 가능하게 합니다.
- Multimodal Process Reward Model (PRM) 개발 및 효과 검증: Multimodal reasoning에 특화된 최초의 process-based reward model (PRM) 을 개발하여 self-evolving training에 통합했습니다. PRM은 intermediate reasoning steps (중간 추론 단계)의 품질을 평가하여 sparse binary reward의 한계를 극복하고 학습 성능을 향상시키는 데 기여합니다. 특히, Top-K reranking 전략과 PRM의 조합이 효과적임을 입증했습니다.
- Prompt Variation 전략 탐구: Labeled prompts (레이블링된 프롬프트)와 unlabeled prompts (비레이블링된 프롬프트)를 self-evolving training에 효과적으로 통합하는 전략을 탐구했습니다. 특히, oracle reward signal (정답 기반 보상 신호)의 유무에 따른 unlabeled prompts 활용법을 분석하고, PRM과 결합하여 unlabeled data의 noise 문제를 완화하는 방법을 제시했습니다.
- Self-Evolution Dynamics 분석 및 Adaptive Exploration 전략: Training dynamics (학습 역학)을 모니터링하여 exploration (탐험) 능력 감소 문제를 발견하고, validation Reward-Pass@2 점수를 기반으로 sampling temperature (샘플링 온도)를 자동 조절하는 Adaptive Exploration 전략을 개발했습니다. 이는 exploration과 exploitation (활용)의 균형을 맞춰 학습 효율성을 극대화합니다.
- M-STAR Framework 제시 및 성능 입증: 위에서 제시된 최적 디자인 선택들을 통합하여 multimodal reasoning을 위한 self-evolving training framework인 M-STAR (Multimodal Self-evolving Training for Reasoning) 를 제안했습니다. M-STAR는 다양한 크기의 모델 (MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B), InternVL2 (2B))과 benchmark (MathVista, M3COT, MMStar, MMBench, AI2D)에서 human annotation 없이 pre-evolved model을 유의미하게 능가하는 state-of-the-art 성능을 달성했습니다.
- Policy/Reward Model 및 Data 공개: 연구 결과의 재현성과 향후 연구 발전을 위해 policy model, reward model, collected data를 공개했습니다.
Novelty (독창성):
- Multimodal Reasoning 특화 Self-Evolving Training 연구: 기존 self-evolving training 연구는 주로 text-only setting에 집중되었으나, 본 연구는 multimodal reasoning 영역에 특화하여 체계적인 분석과 최적화 전략을 제시합니다.
- Multimodal PRM의 최초 개발 및 적용: Multimodal reasoning에서 intermediate reasoning steps의 품질을 평가하는 process-based reward model을 최초로 개발하고 self-evolving training에 성공적으로 통합했습니다.
- Self-Evolution Dynamics 분석 및 Adaptive Exploration 전략: Self-evolving training 과정에서 발생하는 exploration 능력 감소 문제를 dynamics 분석을 통해 밝혀내고, 이를 해결하기 위한 adaptive temperature 조절 전략을 제시했습니다. 이는 self-evolving training의 작동 원리에 대한 깊이 있는 이해를 제공합니다.
- M-STAR Framework의 효과적인 성능: 다양한 모델과 benchmark에서 human annotation 없이 state-of-the-art 성능을 달성하며 M-STAR framework의 범용성과 효과성을 입증했습니다.
Experimental Highlights (실험 주요 결과):
- Continuous Self-Evolving Training: Iterative RFT, ReSTEM 대비 MathVista benchmark에서 최고 성능 (57.2%) 달성.
- PRM (Process Reward Model): PRM 기반 Top-2 reranking 적용 시, PRM 미적용 대비 MathVista benchmark에서 성능 향상 (59.2%) 확인. 특히 OOD (Out-of-Domain) test에서 효과적.
- Adaptive Exploration (온도 자동 조절): Validation set Reward-Pass@2 기반 temperature 조절 전략 적용 시, static temperature (고정 온도) 대비 Pass@K 감소 현상 완화 및 Reward-Pass@2 점수 향상.
- M-STAR Framework: MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B), InternVL2 (2B) 모델에 M-STAR 적용 시, MathVista, M3COT, MMStar-R, MMBench-R, AI2D benchmark에서 pre-evolved model (+warmup) 대비 유의미한 성능 향상 달성. 특히 MiniCPM-V-2.5 + M-STAR는 MathVista에서 59.5% 달성.
Limitations (한계점):
- PRM의 Verifier 능력 부족: PRM은 high-quality response를 reranking하는 데 효과적이지만, ground-truth answer 없이 response를 verification하는 능력은 부족함.
- Unlabeled Data 활용의 어려움: Oracle reward signal 없이는 unlabeled prompts를 효과적으로 활용하기 어려움. PRM이 noise sample 문제를 완화하지만, 완벽하게 해결하지 못함.
- 모델 Generalization 한계 (InternVL2-2B): 작은 모델 (InternVL2-2B)은 MMBench-R, AI2D benchmark에서 성능 향상이 제한적이며, generalization 능력에 한계가 있을 수 있음.
- Reward Model 개선 여지: Reward-Pass@2 지표 개선을 위해 reward model 자체의 성능 향상 가능성 존재.
Future Work (향후 연구 방향):
- 더 강력한 Verifier 개발: Ground-truth answer 없이도 response 품질을 정확하게 verification할 수 있는 reward model 개발 (PRM 개선 또는 새로운 reward model 연구).
- Unlabeled Data 활용 극대화: Oracle reward signal 없이 unlabeled data를 효과적으로 활용하는 self-evolving training 전략 연구 (pseudo-labeling, contrastive learning 등).
- 더 다양한 Benchmark 및 Task 확장: M-STAR framework를 더 다양한 multimodal reasoning benchmark 및 task에 적용하여 범용성 및 확장성 검증.
- Self-Evolution Dynamics 심층 분석: Exploration과 exploitation 간의 trade-off 관계 및 학습 dynamics에 대한 더 깊이 있는 분석 연구.
- Reward Model 개선 및 Adaptive Exploration 전략 고도화: Reward model 자체 성능 향상 및 adaptive temperature 조절 전략 개선을 통한 M-STAR framework 성능 극대화.
총평:
본 논문은 multimodal reasoning을 위한 self-evolving training에 대한 체계적이고 심층적인 연구를 수행하여, 핵심 요소 분석, 최적 학습 전략 제시, 새로운 PRM 개발, dynamics 분석 및 adaptive exploration 전략 개발 등 다양한 측면에서 중요한 기여를 했습니다. 특히, M-STAR framework는 실제 benchmark에서 state-of-the-art 성능을 입증하며 self-evolving training의 실질적인 효과와 잠재력을 보여주었습니다. 향후 연구는 본 논문의 한계점을 보완하고 제시된 방향을 발전시켜 multimodal reasoning 분야 발전에 더욱 기여할 것으로 기대됩니다.
ABSTRACT
Reasoning 능력은 Large Multimodal Models (LMMs)에 필수적입니다.
multimodal chain-of-thought annotation된 데이터가 없는 상황에서, model이 자체 출력으로부터 학습하는 self-evolving training은 reasoning 능력을 향상시키기 위한 효과적이고 확장 가능한 접근 방식으로 떠올랐습니다.
사용이 증가하고 있음에도 불구하고, self-evolving training, 특히 multimodal reasoning의 맥락에서, 포괄적인 이해는 여전히 제한적입니다.
본 논문에서는 multimodal reasoning을 위한 self-evolving training의 복잡성을 탐구하며, Training Method, Reward Model, 그리고 Prompt Variation이라는 세 가지 핵심 요인을 지적합니다.
우리는 각 요인을 체계적으로 조사하고 다양한 구성이 training의 효과에 어떻게 영향을 미치는지 탐구합니다.
우리의 분석은 multimodal reasoning을 최적화하는 것을 목표로 각 요인에 대한 일련의 best practices로 이어집니다.
더욱이, 우리는 training 중 Self-Evolution Dynamics와 성능 향상에 있어서 자동 균형 메커니즘의 영향을 탐구합니다.
모든 조사를 거친 후, 우리는 multimodal reasoning에서의 self-evolving training을 위한 최종 레시피를 제시하며, 이러한 설계 선택들을 M-STAR (Multimodal Self-evolving Training for Reasoning)이라는 프레임워크 안에 담습니다. M-STAR은 다양한 benchmarks에서 다양한 크기의 models에 보편적으로 효과적이며, 예를 들어 MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B) 및 InternVL2 (2B)에서 입증되었듯이 추가적인 human annotation 없이 5개의 multimodal reasoning benchmarks에서 pre-evolved model을 크게 능가합니다.
우리는 이 연구가 multimodal reasoning을 위한 self-evolving training에 대한 이해에 있어서 중요한 격차를 메우고 미래 연구를 위한 강력한 프레임워크를 제공한다고 믿습니다.
우리의 policy 및 reward models, 그리고 수집된 데이터는 multimodal reasoning에 대한 추가 조사를 용이하게 하기 위해 공개됩니다.
1 INTRODUCTION
Large Language Models의 빠른 발전과 함께, 그들의 reasoning abilities는 크게 향상되었습니다. 이러한 발전은 더욱 현실적이고 일반적인 reasoning capabilities에 대한 증가하는 수요와 동반되었습니다. intelligent agents, robotics, 그리고 autonomous driving과 같은 많은 실제 응용 분야에서 기본적인 기술로 여겨지는 Multimodal reasoning은 이러한 추세를 예시합니다. Multimodal reasoning은 Large Multimodal Models (LMMs)이 텍스트를 넘어서 다양한 modalities를 이해하도록 요구합니다. 예를 들어, visual mathematical reasoning은 models에게 복잡한 figures, diagrams, 그리고 charts를 분석하고, 제공된 정보를 활용하여 reasoning tasks를 수행하도록 도전합니다.
이러한 발전에도 불구하고, multimodal 시나리오에서 human-annotated thought processes의 가용성은 여전히 제한적이며, multimodal reasoning 학습에 어려움을 줍니다. 결과적으로, 외부 annotation된 데이터 없이 model의 자체 generation ability를 활용하여 반복적으로 스스로를 tuning하고 개선하는 self-evolving training은 reasoning abilities를 용이하게 하는 매력적인 후보로 떠올랐습니다. self-evolving training에 대한 연구는 주로 text-only settings에 초점을 맞추었지만, multimodal domain, 특히 reasoning tasks에 대한 적용은 몇 가지 산발적인 예시만 있을 뿐이며, 통합된 프레임워크는 아직 확립되지 않았습니다.
self-evolving training이 실제로 일반적인 reinforcement learning (RL) 프레임워크로 공식화될 수 있다는 사실에 영감을 받아, 우리는 먼저 RL의 관점을 통해 multimodal reasoning에서의 self-evolving training의 세 가지 핵심 구성 요소, 즉 training method, reward model의 사용, 그리고 prompt variation을 식별하여 최적의 전략을 검색하기 위한 명확하고 통합된 design space를 구축합니다.
대규모 통제 실험을 통해, 우리는 (1) 완전한 online learning으로의 격차를 줄이고 다른 iterative baselines보다 성능이 뛰어난 마지막 iteration에서 optimizer states를 상속하는 continuous self-evolving training scheme을 제안합니다 (§3.2); (2) multimodal reasoning을 위한 최초의 multimodal, process-based reward model을 training하고 성능을 더욱 향상시키는 데 유용함을 입증합니다 (§3.3); 그리고 (3) 더 많은 unlabeled queries를 추가하는 것은 완벽한 reward signals (예: oracle groundtruth answers)를 가질 때만 도움이 되며, reward model이 unseen data에 대해 잘 generalize되지 않으면 성능을 저해한다는 것을 발견합니다 (§3.4).
위의 static factors와 직교적으로, 우리는 또한 model의 dynamic evolving process, 즉 training 중에 model의 behavior가 어떻게 변하는지 보기 위해 self-evolution의 dynamics를 자세히 살펴봅니다. 우리는 greedy decoding의 model performance는 증가하지만, exploration potential은 training을 통해 계속 감소한다는 것을 발견합니다 (§4.1). 그런 다음 Figure 1에서 볼 수 있듯이 exploration과 exploitation의 균형을 맞추기 위해 training 중에 sampling temperature를 dynamically 조정하는 메커니즘을 도입합니다 (§4.2).
개별적인 통제 연구를 통해 결론지은 모든 레시피를 결합하여, 우리는 M-STAR (Multimodal Self-evolving Training for Reasoning)라는 self-evolving training algorithm을 제안합니다. MathVista, M3CoT, MMStar, MMBench 및 AI2D를 포함한 5개의 다른 multimodal reasoning benchmarks에 대한 우리의 실험 결과는 최적화된 static design choices와 dynamic adjustments를 모두 통합한 이 전략이 training 중 exploration loss를 효과적으로 완화하고 MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B) 및 InternVL2 (2B)와 같은 다양한 크기의 models에 대해 보편적으로 성능을 더욱 향상시킨다는 것을 보여줍니다.
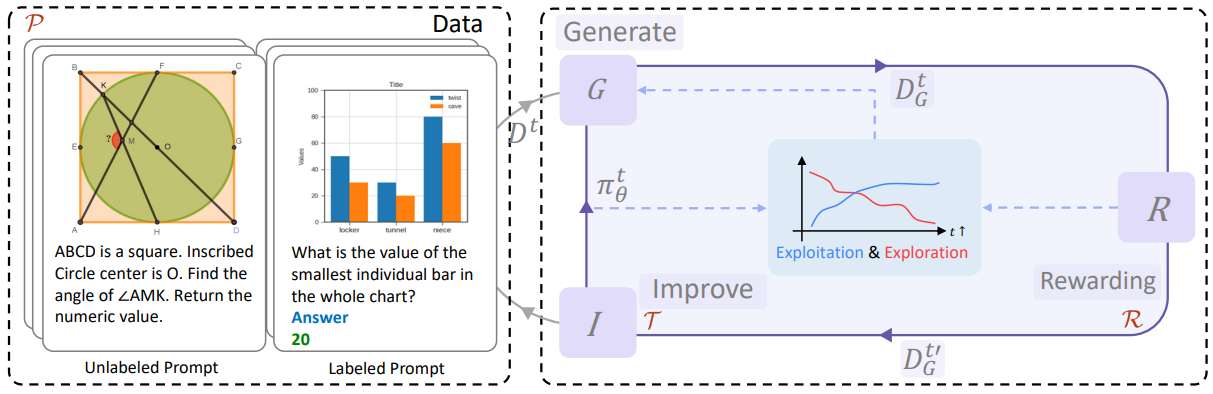
Figure 1: 우리의 multimodal reasoning을 위한 self-evolving training framework의 개요. 우리는 Training method (T), Reward model (R), 그리고 Prompt variation (P)라는 세 가지 필수적인 설계 구성 요소를 조사합니다. static factors와 직교적으로, self-evoloution의 Dynamics 또한 monitered되며, training process에 control signals를 제공합니다.
1 INTRODUCTION 섹션 정리노트 (AI 연구자용)
🔑 핵심 아이디어: Multimodal reasoning 능력 향상을 위한 Self-evolving Training 프레임워크 M-STAR 제시
🔥 배경 및 문제점:
- LLM 발전 → Reasoning 능력 향상: Large Language Models (LLMs)의 reasoning 능력은 괄목할 만한 성장을 이루었지만, 현실 세계 적용을 위한 multimodal reasoning 능력은 여전히 중요.
- Multimodal Reasoning의 중요성: Intelligent agents, robotics, autonomous driving 등 실제 응용 분야에서 핵심 기술. Visual mathematical reasoning과 같이 복잡한 시각 정보 이해 및 reasoning 요구 증가.
- Multimodal CoT 데이터 부족: Multimodal reasoning 학습을 위한 human-annotated chain-of-thought (CoT) 데이터 부족 심각 → 지도 학습 기반 접근의 한계.
- Self-evolving Training의 대안적 부상: 외부 annotation 없이 모델 스스로 생성한 데이터로 반복 학습하는 self-evolving training이 multimodal reasoning 능력 향상의 효과적인 대안으로 주목.
- Multimodal Self-evolving Training 연구 부족: 기존 self-evolving training 연구는 주로 text-only 영역에 집중. Multimodal, 특히 reasoning task에 대한 연구는 초기 단계이며, 통합된 프레임워크 부재.
💡 논문의 접근 방식 및 핵심 기여:
- RL 프레임워크로 Self-evolving Training 재정의: Self-evolving training을 Reinforcement Learning (RL) 관점에서 분석, Training Method, Reward Model, Prompt Variation 3가지 핵심 구성 요소 식별. → 최적 전략 탐색을 위한 명확한 Design Space 구축.
- 3가지 핵심 요소에 대한 심층 분석 및 Best Practices 제시:
- Training Method: Continuous Self-evolving Training Scheme 제안 (optimizer state 상속) → Online learning과의 격차 감소 및 성능 향상.
- Reward Model: Multimodal Reasoning 최초의 Process-based Reward Model 개발 및 효과 입증 → 성능 향상 기여.
- Prompt Variation: Unlabeled queries 추가 전략 분석. 완벽한 Reward Signal (Oracle) 환경에서는 효과적이나, 일반적인 Reward Model에서는 성능 저하 가능성 확인.
- Self-Evolution Dynamics 분석 및 Dynamic Temperature 조절:
- Training 과정 중 모델의 Self-Evolution Dynamics (탐색 능력 변화) 분석 → Greedy decoding 성능 증가에도 탐색 능력 감소 확인.
- Exploration-Exploitation 균형을 위한 Dynamic Temperature 조절 메커니즘 도입 및 효과 입증.
- M-STAR (Multimodal Self-evolving Training for Reasoning) 프레임워크 제안: 위 분석 및 실험 결과를 통합하여 Self-evolving Training 알고리즘 M-STAR 제시. → Static design choices + Dynamic adjustments 결합.
- M-STAR의 보편적 효과 및 성능 입증: MathVista, M3CoT, MMStar, MMBench, AI2D 등 5개 Multimodal Reasoning Benchmark에서 다양한 모델 크기 (MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B), InternVL2 (2B)) 에 대해 M-STAR의 효과 및 Pre-evolved 모델 대비 성능 향상 입증.
🚀 연구의 의의 및 기대 효과:
- Multimodal Reasoning Self-evolving Training에 대한 체계적인 이해 및 Robust Framework (M-STAR) 제공.
- 향후 Multimodal Reasoning 연구 방향 제시 및 발전 기여.
- Policy 및 Reward Model, 수집 데이터 공개 → Multimodal Reasoning 연구 활성화 기대.
📝 결론:
본 논문은 Multimodal Reasoning 능력 향상을 위한 Self-evolving Training의 핵심 요소 분석 및 최적화 전략을 제시하고, M-STAR 프레임워크를 통해 다양한 모델과 Benchmark에서 효과적인 성능 향상을 입증했습니다. Multimodal AI 연구 분야에 실질적인 기여를 할 것으로 기대됩니다.
2 OVERVIEW OF SELF-EVOLVING TRAINING FOR MULTIMODAL REASONING
Self-evolving training은 reinforcement learning의 일반적인 프레임워크로 모델링될 수 있으며, 여기서 다양한 algorithms은 PPO, STaR, ReST 및 ReSTEM과 같은 RL의 특정 instantiation으로 공식화될 수 있습니다.
특히, reward function R이 주어졌을 때, self-evolving training의 목표는 reward R의 기댓값을 최대화하도록 policy model πθ를 training하는 것입니다:
πθ = arg max
πθ
[ ∑_(i)^(L) E_(x,o∼D,ŷ_i∼πθ[·|x,o]) [R(ŷ_i)] ] (1)
여기서 x, o는 주어진 training data D의 query와 image를 나타내고, ŷ_i는 현재 policy model πθ에서 sampling된 response입니다. 그러나 이 표준 RL objective는 최적화하기에 불안정하고 확장하기 어려울 수 있습니다. 따라서 최근 연구에서 채택된 인기 있는 algorithm은 response rollout ŷ_i ∼ πθ[·|x, o]와 policy improvement를 별도의 offline stages로 분리하는 것입니다: (1) Generate: 현재 policy model이 새로운 responses ŷ_i ∼ πθ[·|x, o]를 generation합니다; 그리고 (2) Improve: reward를 사용하여 Generate 단계에서 특정 responses를 선택하고, 이는 표준 supervised fine-tuning (SFT) loss로 policy model을 training하는 데 사용됩니다. 이러한 방식으로, algorithm은 negative responses를 hard manner로 필터링하기 때문에 Rejection Fine-Tuning (RFT)과 유사합니다. Offline과 online training 사이의 tradeoff를 맞추기 위해 두 단계 모두 반복적으로 수행됩니다. mathematical problem-solving과 같은 많은 tasks에서, reward function에 활용되는 고유한 ground-truth answer a∗가 존재합니다. 예를 들어, Singh et al. (2023)은 ŷ와 a∗를 비교하여 binary reward를 계산하기 위해 exact match를 직접 채택합니다. 이러한 iterative training procedure에서, iteration t에서의 objective는 개선된 policy model π^(t+1)_θ를 얻는 것입니다:
π^(t+1)θ = arg max
π^(t)θ
[ ∑(i)^(L) E(x,o,a∗∼D,ŷ_i∼π^(t)_θ[·|x,o]) [R(a∗, ŷ_i)] ] (2)
여기서 reward function R에 대한 ground-truth answer input a∗는 비어 있을 수 있습니다. 예를 들어, unlabeled inputs를 처리할 때, ŷ_i를 scoring하기 위해 reward model이 필요합니다.
The Design Spaces
Eq. 2를 모델링하고 구현하기 위한 다양한 design choices가 있습니다. 예를 들어, reward function R의 design과 a∗가 없는 추가적인 unlabeled inputs를 training에 통합할지 여부입니다. 또한, 이 iterative process를 수행하는 training algorithms도 다양합니다. 예를 들어, Gulcehre et al. (2023); Xu et al. (2024b)는 각 iteration에서 마지막 checkpoint에서 model을 initialize하는 반면, Zelikman et al. (2022); Singh et al. (2023)는 시작 checkpoint에서 initialize하는 것이 overfitting을 줄이고 경험적으로 더 나은 performance를 제공한다고 주장합니다. 다음으로, 우리는 multimodal reasoning learning을 용이하게 하기 위해 각 요인에 대한 best practices를 요약하는 것을 목표로 training method, reward model, 그리고 prompt variation이라는 세 가지 design spaces를 조사합니다.
2 OVERVIEW OF SELF-EVOLVING TRAINING FOR MULTIMODAL REASONING 섹션 정리노트 (AI 연구자용)
🔑 핵심 아이디어: Self-evolving training을 Reinforcement Learning (RL) 프레임워크로 재정의하고, Multimodal Reasoning에 특화된 Design Space 탐색을 위한 기반 마련.
🔥 핵심 내용 및 논문만의 관점:
- Self-evolving Training = RL 프레임워크: Self-evolving training을 단순히 모델 자체 학습 방식이 아닌, 명시적인 RL 문제로 공식화. PPO, STaR, ReST, ReSTEM 등 기존 RL 알고리즘과의 연결점을 제시하며, RL 이론을 self-evolving training 분석에 활용할 수 있는 기반 마련.
- ➡️ 단순 경험적 접근을 넘어, RL 이론적 렌즈를 통해 self-evolving training을 체계적으로 분석하려는 시도.
- 불안정성 극복을 위한 Offline Iterative 방식: 표준 RL objective 직접 최적화의 불안정성 및 확장성 문제 지적. Generate-Improve 방식의 Offline Iterative training 소개 (Rejection Fine-Tuning (RFT) 유사).
- ➡️ Self-evolving training의 실질적인 구현 방식에 대한 논의. Online RL의 어려움을 인지하고, Offline 방식을 통해 안정성과 효율성 확보 전략 제시.
- Iterative Objective 및 Reward Function: 각 iteration에서의 학습 목표 (Objective Function Equation 2) 명확화. Reward Function의 역할 강조 (ground-truth answer 활용 또는 reward model 필요).
- ➡️ Self-evolving training의 각 반복 단계별 목표를 명확히 정의. Reward 설계의 중요성 강조하며, 이어지는 Reward Model 연구의 필요성 암시.
- Multimodal Reasoning Design Spaces 식별: RL 프레임워크 기반 하에, Multimodal Reasoning self-evolving training의 핵심 Design Spaces 3가지 제시:
- Reward Function (R): Reward 설계 및 ground-truth answer/reward model 활용 전략.
- Unlabeled Inputs 활용: Unlabeled 데이터 추가 활용 여부 및 방법. (Prompt Variation과 간접적으로 연결될 수 있음)
- Training Algorithm (Iteration 간 Initialization): Iteration 간 모델 Initialization 전략 (Last Checkpoint vs. Beginning Checkpoint).
- ➡️ Multimodal Reasoning self-evolving training의 성능에 결정적인 영향을 미치는 설계 요소들을 체계적으로 분류. 향후 연구 방향 설정을 위한 명확한 가이드라인 제시.
🚀 연구의 의의 및 시사점:
- Self-evolving training을 RL 관점에서 재해석하여, 보다 깊이 있는 이해 및 체계적인 분석 가능성 제시.
- Multimodal Reasoning self-evolving training의 핵심 Design Space를 명확히 정의하여, 향후 연구 방향 및 최적화 전략 탐색을 위한 프레임워크 제공.
- 단순 성능 향상을 넘어, Self-evolving Training의 근본적인 작동 원리를 이해하고, 실질적인 Design Best Practices를 도출하기 위한 연구의 첫 단계 제시.
📝 결론:
2 섹션은 Self-evolving training을 RL 프레임워크로 재정의하고, Multimodal Reasoning에 특화된 Design Space를 식별함으로써, 향후 효과적인 Self-evolving Training 방법론 연구를 위한 탄탄한 이론적 토대를 구축하는 데 집중합니다. 단순히 기존 연구들을 나열하는 것이 아니라, RL이라는 새로운 렌즈를 통해 Self-evolving training을 분석하고, 핵심 구성 요소를 명확히 정의했다는 점에서 중요한 의의를 가집니다.
3 DIVING INTO SELF-EVOLVING DESIGN COMPONENTS
이 섹션에서는 self-evolving training의 세 가지 핵심 구성 요소를 탐구하며, 각 요소 내에서 다양한 전략을 조사합니다. 먼저 일반적인 설정을 간략하게 설명한 다음(§3.1), multimodal self-evolution을 위한 best practices를 식별하기 위해 각 구성 요소에 대한 포괄적인 분석을 수행합니다(§3.2-§3.4).
3.1 GENERAL SETUP
Model
우리는 MiniCPM-V-2.5 (8B)를 기반으로 주요 탐구를 진행하고, 각 구성 요소에 대한 최종 design choice를 다양한 크기의 두 가지 추가 models인 Phi-3.5-Vision (4B) 및 InternVL-2 (2B)에서 검증합니다. 이러한 models에 대한 자세한 내용은 Appendix A에서 확인할 수 있습니다. 분석 과정을 더 쉽게 이해할 수 있도록, 이 섹션에서는 주로 MiniCPM-V-2.5의 결과를 제시하고, 다른 models의 결과는 §4.2에 포함합니다.
Datasets
우리는 high-quality하고 다양한 multimodal reasoning dataset인 MathV360K를 seed training dataset으로 활용합니다. 구체적으로, labeled training set으로 사용하기 위해 예시의 절반(180K)을 downsample하고, 나머지 절반은 답변을 사용하지 않고 unlabeled training set으로 설정합니다. 평가를 위해 MathV360K의 unlabeled 부분에서 750개의 샘플을 in-domain (ID) testset으로 분리합니다. out-of-domain (OOD) testset으로는 visual question answering, figure-based question answering, science question answering 등을 포함한 광범위한 multimodal reasoning tasks를 포괄하는 널리 인정받는 포괄적인 benchmark인 MathVista의 testmini split을 사용합니다. 또한 training에서 global validation set으로 MathV360K에서 겹치지 않는 250개의 샘플을 유지합니다.
Warm-Up Phase to Unlock the Chain-of-Thought (CoT) Capability of LMMs
예비 실험에서 open-source LMMs는 query가 주어지면 답변을 직접 output하는 반면, detailed chain-of-thought (CoT) reasoning process를 generation하는 데 어려움을 겪는다는 것을 발견했습니다. 이는 대부분의 기존 multimodal SFT training datasets에서 high quality rationales의 부족에서 기인할 수 있으며, 이는 detailed하고 step-by-step reasoning을 generation하는 open-source LMMs의 능력을 제한합니다. 그러나 self-evolving training은 models이 on-policy data로부터 효과적으로 학습할 수 있도록 다양한 intermediate steps를 가진 responses를 필요로 합니다. 이 문제를 해결하기 위해 self-evolving training 전에 첫 번째 단계로 warm-up phase를 시작합니다. model에게 질문에 직접 답변하도록 prompting하는 대신, 주어진 triplet (question, image, answer)에 대한 intermediate reasoning steps를 generation하도록 prompt합니다. 각 triplet에 대해 temperature = 1.0으로 16개의 samples를 rollout하도록 models에게 요청합니다. 그런 다음 final answers가 ground truth와 일치하지 않는 결과를 필터링하고 generation된 dataset에서 100K를 sample하여 correct answers가 있는 warm-up CoT dataset Dw를 생성합니다. 마지막으로, 이 dataset에서 models을 fine-tuning하여 표준 RFT process로 취급합니다. 우리의 iterative self-evolving training process는 warm-up training 후 이 model checkpoint에서 시작됩니다. warm-up phase 동안의 prompt에 대한 자세한 내용은 Appendix B를 참조하십시오.
Main Training Settings
우리는 Yao et al. (2024)의 대부분의 training settings를 채택하고 (Appendix C 참조), 1e−6의 constant learning rate를 사용하고 모든 실험에서 10K steps 동안 training합니다. training의 모든 rollout phases 동안 query당 16개의 responses를 sample하고 sampling temperature를 1.0으로 설정합니다. 명시적으로 달리 명시되지 않는 한, 기존 practices (Singh et al., 2023; Zelikman et al., 2022)를 따르고 labeled training data만 사용합니다.
3.2 TRAINING METHODS
§2에서 설명한 바와 같이, policy model을 update하기 위해 training하는 방법에 대한 여러 variants가 있습니다. 이전 연구에서는 주로 model initialization factor를 다양하게 변경했습니다. 여기서 "Improve" 단계에서 model은 마지막 checkpoint 또는 첫 번째 iteration 이전의 beginning checkpoint에서 initialize될 수 있습니다. model initialization 외에도, 본 연구에서는 iterative training과 online RL 사이의 gap을 자세히 조사하여 iterative self-evolving의 새로운 variants를 도입합니다. 구체적으로, iteration interval이 작을 때, 각 iteration에서의 checkpoint는 마지막 iteration의 checkpoint에서 initialize되고, optimizer와 learning rate scheduler도 iterations 간에 상속되면, iterative training은 online RL algorithm이 됩니다. 따라서 우리는 iterative training과 online training 사이의 더 부드러운 interpolation을 나타내는 새로운 iterative self-evolving training variant인 Continuous Self-Evolving을 제안합니다.
continuous self-evolving training에서는 model checkpoint를 상속하는 것 외에도 optimizer와 learning rate schedulers를 마지막 iteration에서 상속하여 optimization이 continuous하고 순수하게 online learning algorithms에 더 가깝도록 합니다. 이러한 방식으로, 우리는 기본적으로 전체 iterative training process에 걸쳐 global optimizer와 learning rate scheduler만 갖습니다. 또한 continuous self-evolving에서 iteration interval 효과를 분석합니다. iteration interval 효과는 한 iteration에 대해 전달된 training queries로 정의됩니다. 특히, 한 iteration에 대해 모든 data queries를 처리하기 위해 긴 iteration interval을 채택하는 일반적인 practice와 대조적으로 더 짧은 iteration interval을 갖는 효과를 연구합니다.
Setup
우리는 다양한 training methods의 효과를 연구하기 위해 controlled experiments를 수행합니다. 따라서 이 실험에서는 labeled dataset만 사용하고 ground-truth answer a∗와 generation된 answer 사이의 binary exact-match reward를 간단히 채택합니다. 우리는 가장 일반적인 iterative self-evolving algorithms인 ReSTEM과 iterative RFT와 비교합니다. ReSTEM과 iterative RFT는 training methods design space의 특정 instantiations입니다. 제안된 continuous self-evolving에서 iteration interval의 효과를 연구하기 위해, iteration당 모든 queries의 다양한 percentage [6.25%, 12.5%, 25%, 50%, 100%]를 사용하여 실험합니다.
Results
Table 1은 다양한 training methods의 실험 결과를 제시합니다. 전반적으로, 마지막 policy model checkpoint π^(t)_θ에서 training을 initialize하고 continuous optimization process를 유지하는 것이 self-evolving training의 효과, 특히 MathVista에서 가장 크게 기여합니다. Continuous self-evolving은 in-domain MathV360K test set에서 43.1%, OOD test set인 MathVista에서 57.2%로 최고의 performance를 달성합니다. 또한 data queries를 traverse하기 위해 적절한 interval을 유지하는 것의 중요성도 알 수 있습니다. interval이 크면 training method가 offline에 더 가까워지고, model은 현재 output distribution과 일치하는 data에 대한 timely updates를 받을 수 없습니다. 반면에 Improve 및 Generate 단계를 너무 자주 전환하면 learning process가 불안정해져 특히 in-domain test set에서 더 낮은 score로 이어집니다. 적절한 intervals를 가진 continuous self-evolving 전략은 Table 4에서 대표적인 baselines와 비교했을 때 볼 수 있듯이 다른 더 작은 models에서도 작동하며, 이는 다양한 model sizes에 걸쳐 effectiveness와 generalizability를 나타냅니다.
3.3 REWARD MODELS
self-evolving training에서 reward function design에 대한 가장 일반적인 접근 방식은 binary reward R(ŷ_i) = 1(â_i = a∗)를 사용하는 것입니다. 여기서 â_i는 ŷ_i 내부의 predicted answer이고 incorrect responses는 rewards를 최대화하기 위해 필터링됩니다. 효과적이지만, 이 sparse binary reward에는 limitations가 있습니다. response 내의 intermediate reasoning steps의 quality를 간과합니다. 또한 policy model보다 capacity가 같거나 더 높은 models에서 training된 reward models는 policy model의 learning을 개선하기 위해 더 풍부한 signals를 제공할 수 있습니다.
이 섹션에서는 multimodal reasoning을 위한 Process Reward Model (PRM)을 소개하고 (우리가 아는 한 최초), PRM 통합이 reward design을 어떻게 향상시킬 수 있는지, 그리고 multimodal reasoning을 위한 self-evolving training에서 policy model learning을 개선할 수 있는지 여부를 탐구합니다. self-evolving training의 objective에 reward scores를 통합하기 위해, reward function은 다음과 같이 재구성됩니다:
R(ŷ_i) = H(1(a∗ = â_i) × R_p(ŷ_i)) (3)
R_p(ŷ_i) = min(f(s^(0)_i), f(s^(1)_i), ..., f(s^(m)_i)) (4)
여기서 H는 final reward scores를 기반으로 responses를 processing하는 operation입니다. 여기서 우리는 ground truths와 matching하여 모든 responses가 correct하도록 보장하고, R_p(ŷ_i)는 각 sampled response에 대한 process reward score를 나타냅니다. function f(s^(k)_i)는 각 intermediate step에서의 reward score를 나타냅니다. Lightman et al. (2023)에 따라, stepwise rewards를 aggregate하기 위해 min operation을 사용합니다.
Setup
우리는 Process Reward Model (PRM)을 self-evolving training에 통합하는 것의 impact를 평가하고 PRM에서 제공하는 reward signals를 가장 잘 활용하는 방법을 탐구하기 위해 controlled experiments를 수행합니다. 특히, PRM을 적용하기 전에 responses는 training 중 consistency와 quality를 보장하기 위해 final answers를 기반으로 pre-filter됩니다. PRM을 training하기 위해 partial reasoning steps가 있는 prefixes에서 시작하는 Monte Carlo rollouts를 사용하여 training data를 generation합니다. 구체적으로, 질문당 16개의 responses를 sample하고 step-level annotations를 얻기 위해 각 step을 8번 complete합니다. PRM의 training process에 대한 추가적인 자세한 내용은 Appendix D를 참조하십시오.
우리는 두 가지 다른 H operations를 평가합니다: (1) Top-K: reward scores에 따라 top-K correct responses를 선택하고, (2) Threshold α로 Filtering: aggregated rewards가 α보다 낮은 sampled responses를 filtering합니다. α의 optimal value는 validation set에서 0.1의 interval로 enumerate하여 결정된 0.2입니다. 또한 Top-K에서 K 값을 다양하게 변경하는 것이 training에 어떤 영향을 미치는지 조사합니다. 이는 samples의 quality와 diversity 사이의 tradeoff를 나타내기 때문입니다. §3.2에 따라 training methods를 45k interval의 continuous self-evolving으로 고정하고, continuous self-evolving을 baselines로 설정합니다. continuous self-evolving은 randomly selected correct responses를 사용하거나 사용하지 않습니다.
Results
Table 2는 다양한 H choices의 impact와 함께 PRM을 self-evolving training에 통합한 결과를 제시합니다. Top-2를 사용하는 PRM을 사용한 Continuous Self-Evolving은 ID 및 OOD tests 모두에서 각각 45.3%와 59.2%의 score로 최고의 performance를 달성합니다. PRM 없이 training하는 것과 비교했을 때, PRM을 사용한 self-evolving training의 대부분의 instances는 특히 OOD test에서 향상된 performance를 보여줍니다. 흥미롭게도, correct responses의 subset을 randomly selecting하는 것은 실제로 continuous self-evolving보다 더 나쁜 performance로 이어집니다. 이는 correct answers조차 noisy할 수 있음을 시사합니다. Random selection은 이러한 noisy samples의 비율을 증가시켜 self-evolving training의 effectiveness를 저해할 수 있습니다.
PRM 활용 측면에서, 우리는 적당한 수의 responses와 함께 Top-K를 사용하는 것 (high-quality intermediate steps를 가진 K correct responses를 선택하기 위한 re-ranking operation)이 threshold로 filtering하는 것보다 성능이 뛰어나다는 것을 발견했습니다. 결과는 또한 self-evolving training에서 sampled responses의 quality와 diversity의 균형을 맞추는 것의 중요성을 강조합니다. K = 2를 선택하는 것은 이러한 균형을 잘 맞추어 각 질문에 대한 response diversity와 high-quality reasoning steps를 모두 보장합니다. §3.2의 결과와 유사하게, Table 4에서 더 작은 models에서 PRM을 포함할 때 improvement도 확인할 수 있습니다.
What makes PRM work for self-evolving training?
self-evolving training에서 PRM이 작동하는 이유에 대한 더 깊은 insights를 얻기 위해 Figure 2에 제시된 분석을 수행합니다. §3.3의 실험 결과를 바탕으로, PRM의 impact를 두 가지 key perspectives에서 탐구합니다: (1) PRM은 model이 다양한 수의 rollouts 중에서 correct responses를 select하는 데 도움이 될 수 있을까요? (2) reward scores로 re-ranked된 Top 2와 나머지 correct solutions는 얼마나 다를까요? Warmup π^(0)_θ 후 첫 번째 checkpoint를 policy model로 사용하여 validation set의 각 질문에 대해 temperature=1.0으로 16개의 responses를 sample하고, 이러한 samples에서 PRM의 behaviors를 밝힙니다.
우리는 reward models의 performance를 평가하는 데 일반적으로 사용되는 두 가지 metrics인 Best-of-N (BoN)과 weighted voting을 사용하여 PRM의 verification ability를 평가합니다. 놀랍게도 Figure 2a에서 볼 수 있듯이 PRM은 두 metrics 모두에서 underperform합니다. 특히, BoN과 weighted voting은 N < 16일 때 vanilla majority voting보다 더 나쁜 결과를 산출합니다. 이는 text-only reasoning tasks에 비해 high-quality step-level annotations의 부족 때문이라고 추측합니다. 이러한 findings는 PRM이 effective verifier가 아님을 시사합니다.
PRM이 weaker verification abilities에도 불구하고 self-evolving training에 여전히 크게 기여할 수 있는 이유를 이해하기 위해, top-2 selected responses와 다른 correct responses에 대한 다른 metrics의 distribution을 분석했습니다. 우리는 두 가지 perspectives에서 접근했습니다: reasoning steps의 average number와 GPT-4o에 의해 annotated된 질문과 response가 얼마나 directly relevant한지 (Appendix E 참조). randomly checking한 결과 incorrect steps는 찾지 못했지만 일부 irrelevant steps를 발견했기 때문입니다. Figures 2b와 2c에서 볼 수 있듯이, PRM에 의해 re-ranked된 responses는 일반적으로 더 적은 reasoning steps를 가지고 query와 더 relevant합니다. 이는 genuinely high-quality responses를 recognizing하는 PRM의 precision을 강조합니다. 따라서 PRM은 top-quality responses를 precisely identifying하는 effective reranker 역할을 합니다. 이러한 precision은 self-evolving training에서 특히 critical합니다. 여기서 responses는 이미 ground-truth answers로 필터링되었으며, reasoning steps의 quality를 accurately assess하는 능력이 vital해집니다.
앞서 언급한 분석 외에도, reward scores가 낮은 responses를 filtering하기 위해 α를 활용하는 것이 Top-K보다 성능이 낮은 이유도 조사합니다. 결과는 validation set에서 결정된 optimal threshold value를 사용하더라도 각 query에 대한 모든 responses를 retain하거나 filter out하는 경향이 있어 diversity를 줄이고 learning process를 더 challenging하게 만든다는 것을 나타냅니다. 이는 PRM이 Verifier보다 Reranker로서 더 나은 performance를 보인다는 결론을 더욱 뒷받침합니다.
3.4 PROMPT VARIATION
이 섹션에서는 prompt variation이 self-evolving training에 어떤 영향을 미치는지 탐구합니다. prompts에는 labeled prompts와 unlabeled prompts라는 두 가지 primary types가 있습니다. Labeled prompts는 annotation된 ground truth answers와 함께 제공되며, 이는 training 중에 incorrect responses를 필터링하는 데 사용할 수 있습니다. 대조적으로, self-evolving training에서 unlabeled prompts를 활용하는 것은 ground truth annotations의 부재로 인해 더 challenging합니다. training에서 unlabeled prompts의 quality를 유지하려면 reward scores 또는 pseudo labels와 같은 surrogates를 사용해야 합니다. 한편, labeled prompts와 달리 unlabeled prompts는 SFT period에서 training되지 않으므로 policy models의 learning 난이도를 높입니다.
Skylines: Unlabeled Prompts with Oracle Reward Signals
이러한 추가적인 factors의 coupling은 complexity를 도입하여 unlabeled prompts의 effective use를 덜 predictable하게 만듭니다. 이러한 factors를 dissect하기 위해 "skyline" experiments로 baseline을 설정하는 것으로 시작합니다. 여기서 unlabeled prompts와 ground truth answers를 모두 사용할 수 있지만 SFT phase에서는 사용되지 않습니다. oracle reward signals가 있는 이러한 unlabeled prompts는 fully unlabeled prompts와 labeled prompts 사이의 intermediate difficulty 역할을 하여 unlabeled data로 training하는 것의 challenges에 대한 insight를 제공합니다.
Unlabeled Prompts
우리는 unlabeled prompts를 self-evolving training에 통합합니다. 이러한 prompts에 대해 sampled responses의 quality를 보장하기 위해, weighted voting을 사용하여 다른 responses의 predictions를 앙상블하고, 앙상블된 prediction을 pseudo label a˜로 취급합니다. 그런 다음 이 pseudo label을 사용하여 conflicting predictions가 있는 responses를 필터링하여 consistency를 보장합니다. §3.3에 요약된 best practices에 따라 PRM을 reranker로 적용하여 predicted answer a˜가 있는 responses 중에서 top-2 responses를 선택합니다. 그런 다음 이러한 unlabeled prompts를 self-evolving training을 위해 labeled prompts와 혼합합니다. 또한, unlabeled prompts로부터 learning하는 것이 policy models에게 더 challenging하므로, model performance에 대한 impact를 더 잘 이해하기 위해 training에 unlabeled prompts를 도입하는 optimal stage를 조사합니다. 우리는 45k prompts의 training interval을 유지하고 unlabeled prompts가 self-evolving training process에 도입되는 시점을 조정합니다. 구체적으로, total training process의 [0%, 25%, 50%, 75%] 후에 unlabeled prompts를 도입합니다.
A Glimpse at Unlabeled Prompts: Potential Efforts to Make Them Effective
Table 3은 oracle reward signals의 유무에 따른 unlabeled prompts 통합 결과를 제시합니다. PRM을 통합하지 않고 oracle reward signals에만 의존하는 training에서, unlabeled prompts를 사용한 continuous self-evolving은 out-of-domain test에서는 labeled prompts에서만 training된 standard continuous self-evolving보다 성능이 뛰어나지만, in-domain test에서는 underperform합니다. 이는 추가적인 prompts가 model이 underrepresented questions에 대해 더 잘 generalize하는 데 도움이 되지만, 이전에 학습한 정보를 잊어버릴 위험도 증가시킨다는 것을 나타냅니다.
그러나 PRM과 결합한 후에는 oracle reward signals가 제공되더라도 모든 policy models가 두 benchmarks 모두에서 labeled prompts에서만 training된 best model보다 성능이 더 나쁩니다. §3.3의 분석에 따르면, 이는 PRM이 ground-truth answers 없이 responses를 verify할 수 없기 때문에 발생하며, generalization은 여전히 concern으로 남아 있습니다.
unlabeled prompts를 도입하는 timing을 examining할 때, process 중간에 도입하는 것보다 처음부터 추가하는 것이 model performance에 대한 negative impact를 mitigate하는 데 도움이 된다는 것을 발견했습니다. 그러나 unlabeled prompts가 training process 후반에 도입되면 전체 training에 덜 participate하여 limited involvement로 인해 단순히 더 나은 결과를 얻습니다. 이는 충분한 surrogate supervision (예: reward signals)이 없으면 self-evolving training의 middle stages 동안 unlabeled prompts를 도입하는 것이 process에 harm를 줄 수 있으며, policy model의 distribution에서 deviation을 유발할 수 있음을 시사합니다.
3 DIVING INTO SELF-EVOLVING DESIGN COMPONENTS 섹션 정리노트 (AI 연구자용)
🔑 핵심 아이디어: Multimodal Self-evolving Training의 3가지 핵심 Design Component (Training Method, Reward Model, Prompt Variation) 에 대한 심층 분석 및 Best Practices 도출. M-STAR 프레임워크의 핵심 설계 요소 탐색.
🔥 3.1 GENERAL SETUP - 실험 환경 및 기본 설정:
- Model: MiniCPM-V-2.5 (8B) 메인 실험, Phi-3.5-Vision (4B), InternVL-2 (2B) 로 Generalization 검증. 다양한 Model Size에 대한 실험 고려.
- Datasets: MathV360K (High-quality Multimodal Reasoning Dataset) 활용.
- Labeled/Unlabeled split 전략: Labeled Set (180K, CoT Warm-up), Unlabeled Set (180K, Prompt Variation 실험), ID Test (MathV360K 일부), OOD Test (MathVista), Validation (MathV360K 일부). 명확한 데이터 분할 및 활용 전략 제시.
- Warm-up Phase (CoT Capability Unlock): Open-source LMMs의 CoT 능력 부족 문제 지적, Novel Warm-up Phase 도입:
- (Question, Image, Answer) triplet 기반 Intermediate Reasoning Step Generation Prompting.
- RFT 방식으로 CoT Dataset (Dw, 100K) 구축 및 Fine-tuning. Self-evolving training 전 CoT 능력 확보 중요성 강조.
- Training Settings: Constant LR (1e-6), 10K Steps, Sampling Temperature 1.0, Labeled Data Default. 재현 가능한 실험 환경 설정.
🔥 3.2 TRAINING METHODS - Iterative 방식의 한계 극복 및 Continuous Self-Evolving 제안:
- 문제점: 기존 Iterative Self-evolving (ReSTEM, RFT) 의 Model Initialization 방식 (Last vs. Beginning Checkpoint) 에 집중. Online RL과의 Gap 존재.
- 핵심 제안: Continuous Self-Evolving: Iterative Training과 Online RL 사이의 Interpolation 시도.
- Optimizer & LR Scheduler 상속: 각 Iteration 마다 Optimizer State, LR Scheduler 유지. Optimization Continuousity 확보.
- Iteration Interval 중요성 분석: Interval 크기 변화 ([6.25%, 100%]) 실험. 너무 길면 Offline, 너무 짧으면 Unstable. 적절한 Interval 필요.
- 결론: Continuous Self-Evolving (적절 Interval) ReSTEM, RFT 대비 ID/OOD 성능 최고. 특히 MathVista OOD 성능 향상 두드러짐. Smaller Models에도 Generalize.
- ➡️ Iterative Self-evolving의 최적 Training Method로 Continuous Self-Evolving 제시.
🔥 3.3 REWARD MODELS - Sparse Binary Reward의 한계 극복, Multimodal PRM 도입:
- 문제점: Binary Exact-match Reward (Sparse) 는 Intermediate Reasoning Step Quality 간과.
- 핵심 제안: Process Reward Model (PRM) for Multimodal Reasoning (최초 시도):
- Intermediate Reasoning Step Quality 반영 Reward Model (Equation 3, 4). Step-wise Reward, Min Aggregation 활용.
- PRM Training: Monte Carlo Rollouts (Partial Reasoning Prefixes), Step-level Annotations 활용. (Appendix D 상세 설명).
- H Operations (Response Selection): Top-K (Top-K Correct Responses), Threshold Filtering (α 이하 Filtering). Top-K 방식 효과적 확인.
- PRM 효과 분석:
- Verifier 능력은 부족: BoN, Weighted Voting Metric Underperform. Step-level Annotation Quality 한계 추정.
- Reranker 역할 효과적: PRM Re-ranked Responses는 Reasoning Steps 적고, Query Relevance 높음. High-Quality Responses Precision 높음.
- Top-K (K=2) Best: Quality & Diversity 균형 중요. Threshold Filtering 방식은 Diversity 부족으로 성능 저하.
- 결론: PRM (특히 Top-K=2 와 Continuous Self-Evolving 결합) Binary Reward 대비 ID/OOD 성능 향상. OOD 성능 향상 폭 더 큼. PRM은 Verifier보다 Reranker로서 효과적.
- ➡️ Self-evolving training Reward Design에 Process Reward Model (PRM) 효과 입증.
🔥 3.4 PROMPT VARIATION - Labeled vs. Unlabeled Prompts, Oracle Reward Signal 실험:
- Prompt 종류: Labeled Prompts (Ground Truth Answer O), Unlabeled Prompts (Ground Truth Answer X).
- Unlabeled Prompts Challenges: Ground Truth 부재 → Reward Score/Pseudo Label Surrogate 필요. SFT Training 부재 → Learning Difficulty 증가.
- Skyline Experiments (Oracle Reward Signals): Unlabeled Prompts + Ground Truth Answer (SFT 미사용). Unlabeled Prompts 잠재력 & 한계 분석.
- Unlabeled Prompts 통합 전략: Weighted Voting Pseudo Labeling, PRM Reranking (Top-2). Labeled + Unlabeled Prompts 혼합 Training.
- Unlabeled Prompts 도입 시점 실험: [0%, 25%, 50%, 75%] Training 진행 후 Unlabeled Prompts 도입 시점 변화 실험.
- 결론:
- Oracle Reward Signal Unlabeled Prompts: OOD 성능 향상, ID 성능 저하 (Generalization vs. Forgetting Trade-off).
- PRM + Unlabeled Prompts: 오히려 Labeled Prompts Only 모델보다 성능 저하. PRM의 Unlabeled Response Verification Generalization 한계.
- Unlabeled Prompts 도입 시점: Training 초반 도입이 후반 도입보다 성능 유리. 후반 도입은 오히려 Harm 유발 가능성 (Policy Distribution Deviation).
- ➡️ Unlabeled Prompts 활용 신중해야 함. 현재 PRM으로는 효과적 Surrogate Supervision 어려움. 향후 Unlabeled Prompt 효과적 활용 위한 연구 필요.
📝 섹션 3 전체 요약:
섹션 3은 Multimodal Self-evolving Training의 핵심 Design Component들을 체계적으로 분석하고, 실험적으로 검증하여 Best Practices를 도출합니다. Continuous Self-Evolving Training Method, Process Reward Model (PRM), Prompt Variation 전략 각각에 대한 심층적인 분석과 실험 결과를 제시하며, M-STAR 프레임워크 구축의 핵심적인 기반을 마련합니다. 특히, Continuous Self-Evolving, PRM Reranking 효과, Unlabeled Prompts 활용의 어려움 등은 주목할 만한 발견이며, 향후 Multimodal Self-evolving Training 연구 방향에 중요한 시사점을 제공합니다.



