

AI바라기의 인공지능
Diffusion : 논문 리뷰 : LLM-grounded Video Diffusion Models 본문
ABSTRACT
텍스트 조건부 diffusion model은 neural video generation을 위한 유망한 도구로 부상했습니다. 그러나 현재 모델들은 여전히 복잡한 시공간적 프롬프트에 어려움을 겪고 있으며 제한적이거나 잘못된 움직임을 생성하는 경우가 많습니다. 이러한 한계를 해결하기 위해 LLM-grounded Video Diffusion (LVD)을 소개합니다. LVD는 텍스트 입력에서 직접 비디오를 생성하는 대신 먼저 large language model (LLM)을 활용하여 텍스트 입력을 기반으로 동적 scene layout을 생성하고, 이후 생성된 layout을 사용하여 video generation을 위한 diffusion model을 안내합니다.
LLM은 텍스트만으로 복잡한 시공간적 역학을 이해하고 프롬프트와 실제 세계에서 일반적으로 관찰되는 객체 모션 패턴 모두에 closely align되는 layout을 생성할 수 있음을 보여줍니다. 그런 다음 attention map을 조정하여 이러한 layout으로 video diffusion model을 안내하는 방법을 제안합니다.
우리의 접근 방식은 training-free이며 classifier guidance를 허용하는 모든 video diffusion model에 통합될 수 있습니다. 우리의 결과는 LVD가 기본 video diffusion model 및 여러 강력한 기준선 방법보다 원하는 속성과 모션 패턴을 가진 비디오를 충실하게 생성하는 데 있어 훨씬 뛰어난 성능을 보여줍니다.
주요 문제점:
- 기존 텍스트 기반 video diffusion model은 복잡한 시공간적 프롬프트를 이해하는 데 어려움을 겪고, 부정확한 움직임을 가진 비디오를 생성하는 경우가 많음.
제안하는 해결책:
- LLM-grounded Video Diffusion (LVD): LLM을 활용하여 텍스트에서 동적인 scene layout을 생성하고, 이를 video diffusion model에 guidance로 제공하여 보다 정확하고 사실적인 비디오 생성.
LVD의 핵심 아이디어:
- LLM 활용: 텍스트 입력으로부터 시공간적 정보를 이해하고, 실제 세계와 유사한 객체 움직임 패턴을 가진 scene layout을 생성.
- Attention map 조정: 생성된 layout을 attention map에 적용하여 video diffusion model을 안내하고, 원하는 움직임과 속성을 가진 비디오 생성.
- Training-free: 추가적인 학습 없이 기존 video diffusion model에 쉽게 통합 가능.
LVD의 장점:
- 복잡한 시공간적 프롬프트를 더 잘 이해하고, 원하는 움직임을 가진 비디오 생성 가능.
- 기존 video diffusion model보다 성능이 뛰어남.
- 추가 학습 없이 다양한 video diffusion model에 적용 가능.
결론:
LVD는 LLM을 활용하여 video diffusion model의 성능을 향상시키는 새로운 방법을 제시하며, 텍스트 기반 비디오 생성 분야의 발전에 기여할 수 있음.
1 INTRODUCTION
Text-to-image generation 분야는 최근 몇 년 동안 상당한 발전을 이루었습니다. 특히, diffusion model은 고품질 visual contents를 생성하는 놀라운 능력을 보여주었습니다. 그러나 Text-to-video generation은 복잡한 시공간적 역학과 관련된 어려움으로 인해 더욱 까다롭습니다.
최근 연구들은 입력 텍스트 프롬프트에서 시공간적 역학을 포착하는 것을 목표로 하는 text-to-video model을 제안했습니다. 그러나 이러한 방법들은 여전히 제공된 프롬프트에 잘 맞는 사실적인 spatial layout이나 temporal dynamics을 생성하는 데 어려움을 겪고 있습니다 (Fig. 1 참조).

왼쪽: Wang et al. (2023)과 같은 기존 text-to-video diffusion model은 복잡한 프롬프트에 맞는 고품질 비디오를 생성하는 데 어려움을 겪는 경우가 많습니다.
오른쪽: 동일한 모델에 적용했을 때, training-free 방법인 LVD는 입력 텍스트 프롬프트에 closely align되는 사실적인 비디오를 생성할 수 있습니다.
즉, Figure 1은 LVD를 적용했을 때 기존 text-to-video diffusion model의 단점을 극복하고, 복잡한 프롬프트에 더 잘 부합하는 고품질 비디오를 생성할 수 있음을 보여주는 예시입니다.
diffusion model이 텍스트 프롬프트에서 직접 복잡한 역학을 생성하는 데 대한 엄청난 어려움에도 불구하고, 한 가지 가능한 해결 방법은 먼저 프롬프트에서 명시적인 시공간적 layout을 생성한 다음, layout을 사용하여 diffusion model을 제어하는 것입니다. 실제로, 최근 text-to-image generation에 대한 연구에서는 Large Language Models (LLM)을 사용하여 spatial arrangement를 생성하고 이를 text-to-image model의 조건으로 사용하는 것을 제안합니다. 이러한 연구는 LLM이 텍스트 프롬프트를 기반으로 각 객체의 spatial bounding box에 대한 자세하고 정확한 좌표를 생성하는 놀라운 능력을 가지고 있으며, bounding box를 사용하여 diffusion model을 제어하여 일관된 spatial relationship을 가진 이미지 생성을 향상시킬 수 있음을 보여줍니다.
그러나 LLM이 spatial 및 temporal dimension 모두에서 비디오에 대한 dynamic scene layout을 생성할 수 있는지는 아직 입증되지 않았습니다. 이러한 layout의 생성은 훨씬 더 어려운 문제인데, 객체의 모션 패턴은 종종 물리적 특성 (예: 중력)과 객체의 속성 (예: 탄성 vs 강성) 모두에 의존하기 때문입니다.
본 논문에서는 LLM이 주어진 텍스트 프롬프트와 일치하는 시공간적 bounding box를 생성할 수 있는지 조사합니다. 생성된 이러한 box sequence는 Dynamic Scene Layouts (DSL)라고 하며, 텍스트 프롬프트와 비디오 사이의 차이를 연결하는 intermediate representation 역할을 할 수 있습니다. 간단하면서도 효과적인 attention-guidance 알고리즘을 사용하여 이러한 LLM에서 생성된 DSL을 활용하여 training-free 방식으로 객체 수준 spatial relation 및 temporal dynamics 생성을 제어합니다. LLM-grounded Video Diffusion (LVD)라고 하는 전체 방법은 Fig. 2에 나와 있습니다. Fig. 1에서 볼 수 있듯이 LVD는 지정된 temporal dynamics, 객체 속성 및 spatial relationship을 가진 비디오를 생성하여 입력 프롬프트와 생성된 콘텐츠 간의 alignment를 크게 향상시킵니다.
프롬프트에 맞는 spatial layout과 temporal dynamics을 생성하는 LVD의 능력을 평가하기 위해 각각 프롬프트에서 서로 다른 spatial 및 temporal properties을 이해하고 생성해야 하는 5가지 task로 구성된 벤치마크를 제안합니다. LVD가 여러 강력한 기준선 모델에 비해 text-video alignment를 크게 향상시키는 것을 보여줍니다. 또한 UCF-101 및 MSR-VTT와 같은 일반적인 데이터 세트에서 LVD를 평가하고 evaluator 기반 평가를 수행했으며, 여기서 LVD는 내부적으로 사용하는 기본 diffusion model에 비해 지속적으로 개선된 것을 보여줍니다.
기여:
1) Text-only LLM이 이전에 보지 못했던 시공간적 sequence로 일반화되는 dynamic scene layout을 생성할 수 있음을 보여줍니다.
2) 복잡한 텍스트 프롬프트에서 비디오를 생성하는 향상된 기능을 위해 LLM에서 생성된 dynamic scene layout을 활용하는 최초의 training-free 파이프라인인 LLM-grounded Video Diffusion (LVD)을 제안합니다.
3) 입력 프롬프트와 text-to-video model에서 생성된 비디오 간의 alignment를 평가하기 위한 벤치마크를 소개합니다.
현황:
- Text-to-image generation 분야는 diffusion model 등의 발전으로 고품질 이미지 생성이 가능해졌지만, text-to-video generation은 복잡한 시공간적 역학 때문에 어려움을 겪고 있음.
- 기존 text-to-video model은 텍스트 프롬프트를 제대로 이해하지 못해, 부정확하거나 현실적이지 않은 움직임 을 가진 비디오를 생성하는 경우가 많음.
문제점:
- Diffusion model이 텍스트에서 직접 복잡한 시공간적 역학을 생성하는 것은 매우 어려움.
해결 아이디어:
- LLM 활용: 텍스트에서 명시적인 시공간적 layout (Dynamic Scene Layouts, DSL) 을 먼저 생성하고, 이를 이용하여 diffusion model을 제어.
- LLM은 텍스트를 이해하여 객체의 spatial bounding box 좌표를 생성하는 능력을 이미 보여주었음.
- 본 논문에서는 LLM이 비디오의 spatial & temporal dimension 모두에서 DSL을 생성할 수 있는지 탐구.
제안하는 방법:
- LLM-grounded Video Diffusion (LVD): LLM으로 DSL을 생성하고, attention-guidance 알고리즘을 통해 diffusion model에 적용하여 비디오 생성.
- Training-free: 추가 학습 없이 기존 diffusion model에 적용 가능.
- 향상된 텍스트-비디오 alignment: LVD는 텍스트 프롬프트에 더 잘 맞는, 사실적인 움직임 과 객체 속성 을 가진 비디오를 생성 (Figure 1 참조).
실험 및 평가:
- 새로운 벤치마크: 프롬프트의 spatial & temporal properties를 평가하기 위한 5가지 task 제시.
- 다양한 데이터셋: UCF-101, MSR-VTT 등에서 LVD 성능 검증.
- Evaluator 기반 평가: 기존 diffusion model 대비 LVD의 성능 향상 확인.
기여:
- LLM의 새로운 능력: Text-only LLM이 복잡한 시공간적 sequence를 이해하고 DSL을 생성할 수 있음을 보여줌.
- LVD: LLM 기반 DSL을 활용하는 최초의 training-free video generation pipeline 제시.
- 벤치마크: Text-to-video model 평가를 위한 새로운 벤치마크 도입.
2 RELATED WORK
제어 가능한 Diffusion Model. Diffusion model은 콘텐츠 생성 (Ramesh et al., 2022; Song & Ermon, 2019; Ho et al., 2022b; Liu et al., 2022; Ruiz et al., 2023; Nichol et al., 2021; Croitoru et al., 2023; Yang et al., 2022; Wu et al., 2022)에서 큰 성공을 거두었습니다. ControlNet (Zhang et al., 2023)은 neural network를 사용하여 크고 사전 학습된 text-to-image diffusion model에 spatial conditioning control을 통합하기 위한 architecture design을 제안합니다. GLIGEN (Li et al., 2023)은 이미지 생성을 위한 추가적인 grounding 정보를 받아들이기 위해 gated attention adapter를 도입합니다. Shape-guided Diffusion (Huk Park et al., 2022)은 사용자가 제공하거나 텍스트에서 자동으로 유추된 shape input에 응답하도록 pretrained diffusion model을 조정합니다. Control-A-Video (Chen et al., 2023b)는 edge 또는 depth map과 같은 control signal sequence를 조건으로 하여 비디오를 생성하도록 모델을 학습시킵니다. 이러한 연구에서 이룬 놀라운 진전에도 불구하고 텍스트 프롬프트만을 기반으로 복잡한 역학을 가진 비디오를 생성하는 문제는 해결되지 않고 있습니다.
Text-to-Video 생성. 비디오 생성 (Brooks et al., 2022; Castrejon et al., 2019; Denton & Fergus, 2018; Ge et al., 2022; Hong et al., 2022; Tian et al., 2021; Wu et al., 2021)에 대한 풍부한 문헌이 있지만, text-to-video generation은 모델이 텍스트만을 기반으로 비디오 역학을 합성해야 하기 때문에 여전히 어렵습니다. Make-A-Video (Singer et al., 2022)는 전체 temporal U-Net (Ronneberger et al., 2015)과 attention tensor를 분해하여 spatial 및 temporal domain 모두에서 근사화하고 고해상도 비디오를 생성하기 위한 pipeline을 구축합니다. Imagen Video (Ho et al., 2022a)는 기본적인 video generation model과 spatial-temporal video super-resolution model을 통해 고화질 비디오를 만듭니다. Video LDM (Blattmann et al., 2023)은 latent space diffusion model에 temporal dimension을 추가하여 image generator를 video generator로 변환합니다. Text2Video-Zero (Khachatryan et al., 2023)는 temporal consistency를 보장하기 위한 두 가지 후처리 기술을 도입합니다. latent code에 모션 역학을 인코딩하고 cross-frame attention mechanism으로 frame-level self-attention을 재프로그래밍합니다. 그러나 이러한 모델은 다양한 모션 패턴과 객체 속성을 포함할 수 있는 대규모 paired text-video training data가 부족하고, 그러한 대규모 데이터 세트로 학습하는 데 필요한 계산 비용이 많이 들기 때문에 적절한 비디오 역학을 생성하는 데 여전히 쉽게 실패합니다.
Large Language Model (LLM)에서 Grounding 및 추론. 최근 몇몇 text-to-image model은 입력 텍스트 프롬프트를 LLM에 공급하여 적절한 spatial bounding box를 얻고, box를 조건으로 하여 고품질 이미지를 생성하는 것을 제안합니다. LMD (Lian et al., 2023)은 LLM에서 생성된 layout을 기반으로 이미지를 생성하기 위해 innovative controller를 사용하여 diffusion model을 안내하는 training-free 접근 방식을 제안합니다. LayoutGPT (Feng et al., 2023)은 다양한 domain에서 layout-oriented visual planning을 위해 LLM을 채택하는 program-guided 방법을 제안합니다. Attention refocusing (Phung et al., 2023)은 지정된 layout에 따라 attention map을 재정렬하기 위해 두 가지 innovative loss function을 도입합니다. 종합적으로 이러한 방법들은 LLM에서 생성된 bounding box가 text-to-image generation을 제어하는 데 정확하고 실용적이라는 경험적 증거를 제공합니다. 이러한 결과를 바탕으로 우리의 목표는 복잡한 역학을 수반하는 프롬프트에서 생성하는 text-to-video model의 능력을 향상시키는 것입니다. 우리는 spatial 및 temporal video dynamics을 생성하는 데 있어 LLM의 잠재력을 탐구하고 활용함으로써 이를 달성하고자 합니다. 동시 연구인 VideoDirectorGPT (Lin et al., 2023)는 multi-scene video generation에서 LLM을 사용하는 것을 제안하는데, 이는 다른 초점과 기술 경로를 추구합니다. 추가적인 conditioning을 위한 diffusion adapter를 학습하는 것을 탐구하는 반면, LVD는 inference-time guidance와 LLM의 일반화에 대한 심층적인 분석에 중점을 둡니다.
(1) Controllable Diffusion Models:
- 장점: 이미지 생성에서 큰 성공을 거두었고, ControlNet, GLIGEN 등 다양한 기술을 통해 외부 조건을 활용하여 생성 과정을 제어할 수 있음.
- 단점: 텍스트만으로 복잡한 역학을 가진 비디오를 생성하는 데는 여전히 어려움을 겪고 있음.
- 주요 연구: ControlNet, GLIGEN, Shape-guided Diffusion, Control-A-Video
(2) Text-to-Video Generation:
- 장점: Make-A-Video, Imagen Video 등 다양한 모델들이 제안되었고, 고해상도 비디오 생성이 가능해짐.
- 단점: 대규모 데이터셋 부족, 높은 계산 비용, 현실적인 비디오 역학 생성의 어려움 등으로 인해 여전히 발전의 여지가 많음.
- 주요 연구: Make-A-Video, Imagen Video, Video LDM, Text2Video-Zero
(3) LLM을 이용한 Grounding 및 Reasoning:
- 장점: LLM을 통해 텍스트에서 객체의 위치 정보 등을 추출하여 이미지 생성에 활용, LMD, LayoutGPT 등에서 효과를 입증.
- 단점: 주로 이미지 생성에 초점을 맞추었으며, 비디오 생성, 특히 복잡한 역학을 가진 비디오 생성에는 활용되지 않았음.
- 주요 연구: LMD, LayoutGPT, Attention refocusing
본 논문 (LVD)은 이러한 한계점을 극복하기 위해 LLM을 활용하여 text-to-video generation을 개선하는 새로운 방법을 제시합니다.
- LLM을 통해 시공간적인 정보를 담은 DSL을 생성하고, 이를 attention-guidance 알고리즘을 통해 diffusion model에 적용.
- 추가 학습 없이 기존 diffusion model에 적용 가능하며, 텍스트 프롬프트를 더 잘 반영하는 고품질 비디오 생성 가능.
관련 연구 VideoDirectorGPT와의 차별점:
- VideoDirectorGPT는 multi-scene video generation에 LLM을 사용하지만, LVD는 단일 장면 비디오 생성에 집중.
- VideoDirectorGPT는 diffusion adapter를 학습하는 반면, LVD는 inference-time guidance를 통해 LLM을 활용.
- LVD는 LLM의 일반화 능력에 대한 심층적인 분석을 제공.
결론적으로, LVD는 LLM을 text-to-video generation에 효과적으로 활용하는 새로운 방법을 제시하며, 기존 연구의 한계를 극복하고 더욱 발전된 비디오 생성을 가능하게 합니다.
3 CAN LLMS GENERATE SPATIOTEMPORAL DYNAMICS?
이 섹션에서는 LLM이 지정된 텍스트 프롬프트에 해당하는 시공간적 역학을 생성할 수 있는 정도를 탐구합니다. 이 조사에서는 세 가지 질문에 대한 답을 찾고자 합니다.
- LLM은 텍스트 프롬프트에 맞춰 사실적인 dynamic scene layout (DSL)을 생성하고 특정 물리적 특성을 적용해야 하는 시점을 식별할 수 있을까요?
- LLM의 이러한 특성에 대한 지식은 가중치에서 비롯된 것일까요, 아니면 추론 중에 즉석에서 이러한 개념에 대한 이해가 발전할까요?
- LLM은 제한된 주요 특성만 포함하는 주어진 예제를 기반으로 더 넓은 세계 개념과 관련 특성으로 일반화할 수 있을까요?
역학 생성을 위해 LLM에 프롬프트를 제시하는데, 이 프롬프트는 두 부분으로 구성됩니다. 텍스트 형식의 작업 지침과 원하는 출력 및 따라야 할 규칙을 설명하는 몇 가지 예시입니다. 프롬프트에 따라 LLM에 완료를 요청하여 역학을 생성합니다.
작업 지침. LLM에게 "비디오 bounding box 생성기" 역할을 하도록 요청합니다. 작업 설정에서 좌표계, 캔버스 크기, 프레임 수, 프레임 속도와 같은 작업 요구 사항을 설명합니다. 전체 프롬프트는 부록 A.3을 참조하십시오.
DSL 표현. LLM에게 프레임 간에 연결된 bounding box 세트인 Dynamic Scene Layout (DSL)을 사용하여 각 비디오의 역학을 표현하도록 요청합니다. LLM은 각 프레임에 표시되는 box를 순차적으로 생성하도록 프롬프트됩니다. 각 box는 숫자 좌표로 box의 위치와 크기를 포함하는 표현과 함께 둘러싸인 객체를 설명하는 구문을 갖습니다. 또한 각 box에는 0부터 시작하는 숫자 식별자가 할당되고, 프레임 전체의 box는 box tracker를 사용하지 않고 할당된 ID를 사용하여 일치됩니다.
컨텍스트 내 예시. LLM은 DSL 생성에서 중력과 같은 실제 역학에 대한 우리의 요구를 이해하지 못할 수 있으며, 이는 우리의 특정 목표와 일치하지 않을 수 있는 가정으로 이어질 수 있습니다. LLM을 올바르게 안내하기 위해 자연스러운 시공간적 layout을 생성하는 데 필요한 물리적 특성을 강조하는 예시를 제공합니다. 핵심 질문은 다음과 같습니다. 실제 역학을 위해 설계되지 않은 LLM이 사실적인 layout을 생성하려면 몇 개의 예시가 필요할까요? box 좌표와 실제 역학의 복잡한 수학을 파악하기 위해 수많은 프롬프트가 필요하다고 생각할 수 있습니다. 그러한 직관과는 달리, 주요 물리적 특성을 보여주는 몇 가지 예시를 LLM에 제시하고 원하는 각 특성에 대해 하나의 예시만 사용할 것을 제안합니다. 놀랍게도 이것은 종종 LLM이 물리적 특성과 카메라 움직임을 포함한 다양한 측면을 이해하기에 충분하며, 섹션 4와 같은 비디오 생성과 같은 다운스트림 애플리케이션을 가능하게 합니다. 또한 LLM은 제공된 예시에서 외삽하여 명시적으로 언급되지 않은 관련 특성을 추론할 수 있음을 발견했습니다. 즉, 원하는 모든 특성을 나열할 필요 없이 몇 가지 주요 특성만 강조하면 됩니다. 컨텍스트 내 예시는 그림 3에 시각화되어 있으며, 자세한 내용은 부록 A.3에 있습니다.

그림3 : 컨텍스트 내 예시. 우리는 LLM에 주요 desirable property 당 하나의 컨텍스트 내 예시만 프롬프트할 것을 제안합니다. 예시 (a)/(b)/(c)는 각각 중력/탄성/원근 투영을 보여줍니다. 섹션 3에서 LLM은 이러한 컨텍스트 내 예시만으로 쿼리 프롬프트에 맞춰 DSL을 생성할 수 있음을 보여주며, 비디오 생성과 같은 다운스트림 애플리케이션을 가능하게 합니다.
생성 전 추론. LLM 출력의 해석 가능성을 높이기 위해 LLM에게 각 프레임에 대한 box 생성을 시작하기 전에 추론에 대한 간략한 설명을 출력하도록 요청합니다. 또한 출력 형식과 일치하도록 각 컨텍스트 내 예시에 추론 설명을 포함합니다. LLM의 추론 설명에 대한 예시와 분석은 부록 A.1을 참조하십시오.
조사 설정. 비디오 생성의 잠재적 다운스트림을 통해 원하는 물리적 특성을 세계 특성과 카메라 특성으로 분류합니다. 특히, 중력과 객체 탄성을 세계 특성으로, 원근 투영을 카메라 특성으로 검토합니다. 그러나 놀라운 일반화 기능은 LLM이 조사되지 않은 다른 특성으로 일반화할 수 있는 유망한 기회를 나타냅니다. 그림 3에 표시된 것처럼 LLM에 세 가지 특성 각각에 대한 예시를 하나씩 제공합니다. 그런 다음 세계 특성과 카메라 특성 모두에 대해 몇 가지 텍스트 프롬프트로 LLM에 쿼리합니다(그림 4 참조). 이 섹션의 조사에는 GPT-4 (OpenAI, 2023)를 사용합니다. 섹션 5에서는 추가 모델을 살펴보고 유사한 기능을 보이는지 확인합니다.
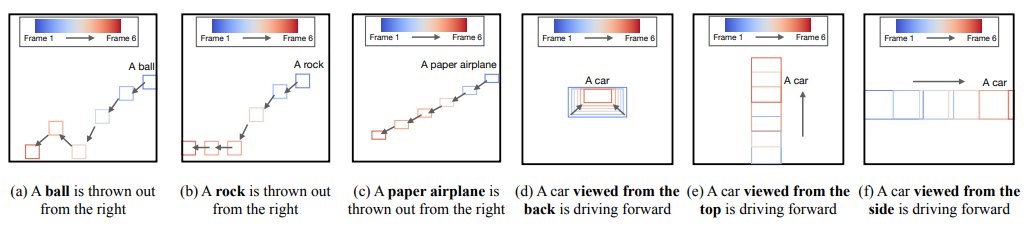
그림 3의 컨텍스트 내 예시만 사용하여 입력 텍스트 프롬프트에서 LLM이 생성한 DSL. 놀랍게도 각 물리적 특성의 적용 가능성에 대한 텍스트 설명이 없음에도 불구하고 LLM은 이를 적절하게 식별하고 적용합니다. (a,b) LLM은 예시에서 바위의 속성이 전혀 언급되지 않았음에도 불구하고 공에는 탄성 규칙을 선택적으로 적용하지만 바위에는 적용하지 않습니다. (c) LLM은 예시에서 세계 컨텍스트를 추론하고 종이 비행기의 궤적을 그릴 때 언급되지 않은 공기 마찰을 고려합니다. (d-f)는 예시에서 명시적인 지침 없이 객체 역학에 영향을 미치는 시점의 역할에 대한 LLM의 고유한 이해를 보여줍니다. 이러한 발견은 제공된 예시에만 의존하는 것이 아니라 가중치에 포함된 LLM의 타고난 지식이 이러한 적응성을 주도한다는 것을 시사합니다.
발견 사항. 보거나 보지 못했던 다양한 쿼리 시나리오에 대해 LLM이 프롬프트에 맞춰 사실적인 DSL을 생성할 수 있음을 발견했습니다. 특히, 이 기능은 제공된 예시에만 의존하는 것이 아니라 LLM의 고유한 지식에 뿌리를 두고 있습니다. 예를 들어, LLM이 시뮬레이션할 원하는 세계에 탄성이 있음을 보여주는 공 예시(그림 3(b))가 주어지면 LLM은 공을 던졌을 때 왼쪽(그림 3(b)) 또는 오른쪽에서 던졌는지 여부에 관계없이 땅에 떨어져 다시 튀어오른다는 것을 이해합니다(그림 4(a)). 또한 LLM은 탄성이 다른 객체로 일반화할 수 있습니다. 예를 들어, 컨텍스트 내 예시를 업데이트하지 않고 공을 바위로 교체하면(그림 4(b)), LLM은 바위가 탄성이 없으므로 튀지 않지만 여전히 중력을 따르고 떨어진다는 것을 인식합니다. 이러한 이해는 지침이나 예시에서 객체의 특성에 대한 명시적인 텍스트 단서 없이 도달합니다. 이 기능은 입력 프롬프트에서 파생된 것이 아니므로 LLM의 가중치에서 비롯된 것임에 틀림없습니다. 요점을 더 설명하기 위해 그림 3(c)에서 "상상의 카메라"가 원근 기하학의 원리를 따르는 것을 LLM에 보여줍니다. 카메라가 그림에서 멀어질수록 그림이 더 작게 나타납니다. 그런 다음 그림 4(e,f)에 표시된 것처럼 예시에서 직접 가르치지 않은 시나리오로 LLM을 테스트합니다. 카메라 시점과 객체 움직임에 따라 원근 기하학이 어떻게 달라지는지에 대한 명시적인 설명 없이도 LLM은 개념을 파악할 수 있습니다. 자동차의 전진 운동이 카메라가 가리키는 방향에 수직이면 원근 기하학이 적용되지 않습니다.
더욱 설득력 있게, 상상의 세계에 대한 올바른 컨텍스트를 설정함으로써 LLM은 지침이나 예시에 명시되지 않은 특성에 대한 논리적 확장을 할 수 있습니다. 그림 4(d)에 표시된 것처럼 LLM은 카메라가 정적 객체에서 멀어질 때(그림 3(c)에 소개됨)뿐만 아니라 객체가 고정된 카메라에서 멀어질 때도 원근 기하학의 원리가 적용된다는 것을 인식합니다. 이러한 이해는 주어진 예시를 넘어 확장됩니다. 그림 4(c)에서 볼 수 있듯이 공기 마찰에 대한 명시적인 언급 없이도 LLM은 종이 비행기에 대해 이를 고려하고 종이 비행기가 다른 쿼리된 객체보다 느리게 떨어지고 더 멀리 활공하는 것으로 표시되는 DSL을 생성합니다. 이는 우리의 예시가 LLM이 시뮬레이션할 상상의 세계를 구축하는 데 도움이 되어 가능한 모든 시나리오에 대한 완전한 프롬프트가 필요하지 않음을 나타냅니다. 또한 LLM은 그림 1에 대한 사실적인 DSL을 생성하기 위해 추론 설명에서 부력과 동물의 움직임 패턴에 대한 이해를 보여줍니다. 독자는 부록 A.1에서 이러한 설명을 참조할 수 있습니다.
이러한 관찰은 LLM이 그림 3의 세 가지 컨텍스트 내 예시만 주어지면 복잡한 프롬프트에 맞춰 DSL을 성공적으로 생성할 수 있음을 나타냅니다. 따라서 이러한 컨텍스트 내 예시를 사용하고 섹션 5에서 추가적인 양적 및 질적 분석을 제시합니다.

그림 4의 DSL에서 우리의 방법 LVD로 생성된 비디오. 우리의 접근 방식은 입력 텍스트 프롬프트에 올바르게 맞춰지는 비디오를 생성합니다. (a-c)는 오른쪽에서 왼쪽으로 던져지는 다양한 객체를 보여줍니다. (d-f)는 서로 다른 시점에서 본 동일한 유형의 객체를 묘사합니다.
목표:
- LLM이 텍스트 프롬프트에 맞는 시공간적 역학을 얼마나 잘 생성하는지 확인.
- LLM이 물리적 특성을 이해하고 적용하는 방식 탐구.
- LLM의 일반화 능력 분석.
핵심 질문:
- LLM은 텍스트 프롬프트에 맞는 사실적인 DSL을 생성하고, 물리 법칙을 적용해야 할 때를 알 수 있을까?
- LLM의 물리 법칙에 대한 지식은 어디서 오는 걸까? (학습된 가중치 vs 추론 중 즉석 이해)
- LLM은 제한된 예시만으로 더 넓은 세계 개념과 관련 특성을 일반화할 수 있을까?
실험 방법:
- 프롬프트 구성: 텍스트 지침 + 컨텍스트 내 예시 (원하는 출력 및 규칙 설명)
- DSL: 프레임 간에 연결된 bounding box 세트로, 객체의 위치, 크기, 설명 등을 포함.
- 컨텍스트 내 예시: 중력, 탄성, 원근 투영 등 주요 물리 특성을 보여주는 최소한의 예시 제공 (그림 3 참조).
주요 발견:
- LLM은 다양한 쿼리 시나리오에 대해 사실적인 DSL을 생성할 수 있음. (그림 4 참조)
- LLM은 제공된 예시뿐 아니라 내부 지식을 활용하여 물리 법칙을 이해하고 적용.
- 예시: 공의 탄성, 바위의 비탄성, 종이 비행기의 공기 마찰 등을 명시적인 설명 없이도 구현.
- LLM은 제한된 예시에서 관련 특성을 추론하여 일반화 가능.
- 예시: 카메라 이동 뿐 아니라 객체 이동에도 원근 투영 적용.
- LLM은 부력, 동물의 움직임 패턴 등 복잡한 개념도 이해.
결론:
- LLM은 최소한의 예시만으로도 복잡한 프롬프트에 맞는 DSL을 생성할 수 있는 능력을 보여줌.
- LVD는 이러한 LLM의 능력을 활용하여 text-to-video generation의 성능을 향상시킬 수 있음.
4 DSL-GROUNDED VIDEO GENERATION
LLM이 텍스트 프롬프트에서 DSL을 생성하는 기능을 활용하여 이러한 DSL을 기반으로 비디오 합성을 지시하는 알고리즘을 소개합니다. 우리의 DSL 기반 video generator는 기존의 text-to-video diffusion model을 지시하여 텍스트 프롬프트와 주어진 DSL 모두와 일치하는 비디오를 생성합니다. 우리의 방법은 fine-tuning이 필요하지 않으므로 instance-annotated 이미지 또는 비디오가 필요하지 않으며 학습으로 인해 발생할 수 있는 catastrophic forgetting을 방지합니다.

text-to-video diffusion model (예: Wang et al. (2023))은 N × H × W × C 형태의 random Gaussian noise를 입력으로 받아 비디오를 생성합니다. 여기서 N은 프레임 수이고 C는 채널 수입니다. 백본 네트워크 (일반적으로 U-Net (Ronneberger et al., 2015))는 이전 time step의 출력과 텍스트 프롬프트를 기반으로 입력을 반복적으로 denoise하며, 텍스트 조건화는 텍스트 정보를 latent feature에 통합하는 cross-attention layer를 사용하여 수행됩니다.
각 프레임에 대해 latent layer에서 텍스트 프롬프트의 객체 이름으로의 cross-attention map을 A ∈ R H×W 로 표시합니다. 여기서 H와 W는 latent feature map의 높이와 너비입니다. 간결하게 하기 위해 diffusion step, latent layer, 프레임 및 객체 인덱스에 대한 인덱스는 무시합니다. cross-attention map은 일반적으로 객체가 생성되는 위치를 강조 표시합니다.
그림 6에 설명된 것처럼 객체가 주어진 DSL 내에서 생성되고 이동하도록 하기 위해 cross-attention map이 해당 bounding box 내에 집중되도록 합니다. 이를 위해 DSL의 각 box를 마스크 M ∈ R H×W 로 변환합니다. 여기서 값은 bounding box 내부는 1이고 box 외부는 0입니다. 그런 다음 에너지 함수 Etopk = −Topk(A · M) + Topk(A · (1 − M))을 정의합니다. 여기서 ·는 element-wise 곱셈이고 Topk는 행렬에서 상위 k개 값의 평균을 취합니다. 직관적으로 이 에너지를 최소화하면 bounding box 내부에 k개 이상의 높은 attention 값을 장려하는 반면 box 외부에는 낮은 값만 갖게 됩니다.
그러나 연속된 프레임의 layout box가 크게 겹치는 경우 (즉, 객체가 느리게 움직이는 경우) Etopk는 부정확한 위치 제어를 초래할 수 있습니다. 겹친 영역의 고정된 객체도 에너지 함수를 최소화할 수 있기 때문이며, text-to-video diffusion model은 종종 생성하는 것을 선호합니다. 생성된 객체의 temporal dynamics이 DSL 안내와 일치하도록 추가로 보장하기 위해 Center-of-Mass (CoM) 에너지 함수 ECoM을 제안합니다. 이는 A와 M의 CoM이 유사한 위치와 속도를 갖도록 합니다. t번째 프레임의 attention map과 box 마스크의 CoM을
전반적인 에너지 E는 Etopk와 ECoM의 가중 합입니다.
에너지 E를 최소화하기 위해 각 diffusion step 전에 DSL 안내 단계를 추가합니다. 여기서 각 프레임과 각 객체에 대해 부분적으로 denoise된 비디오에 대한 에너지의 gradient를 계산하고 classifier guidance를 사용한 gradient descent로 부분적으로 denoise된 비디오를 업데이트합니다 (Dhariwal & Nichol, 2021; Xie et al., 2023; Chen et al., 2023a; Lian et al., 2023; Phung et al., 2023; Epstein et al., 2023).
이 간단하면서도 효과적인 training-free 조건화 단계를 통해 DSL로 비디오 생성을 제어하고 텍스트 프롬프트 → DSL → 비디오의 LVD 파이프라인을 완료할 수 있습니다. 또한 LVD 파이프라인의 두 단계는 구현과 무관하며 해당 구성 요소로 쉽게 교체할 수 있습니다. 즉, 더욱 기능이 뛰어난 LLM과 layout 조건부 video generator를 통해 생성 품질과 텍스트-비디오 alignment가 지속적으로 향상될 것임을 의미합니다. 그림 5에서 DSL 기반 video generator가 그림 4의 DSL로 표현되는 사실적인 비디오를 생성할 수 있음을 보여줍니다.
4. DSL-grounded Video Generation 정리노트 📝
이 섹션에서는 LLM이 생성한 DSL을 활용하여 비디오를 생성하는 방법을 설명합니다.
핵심 아이디어:
- DSL-grounded video generator: LLM에서 생성된 DSL을 기반으로 기존 text-to-video diffusion model을 안내하여 비디오를 생성.
- Training-free: 추가 학습 없이 기존 모델에 적용 가능.
방법:
- Text-to-video diffusion model: 랜덤 노이즈를 입력으로 받아 denoising 과정을 통해 비디오를 생성하는 모델 (예: Wang et al. (2023)).
- Cross-attention map: Diffusion model에서 텍스트 정보를 latent feature에 통합하는 데 사용되는 attention map.
- DSL 안내: 각 denoising step 전에 DSL 정보를 활용하여 cross-attention map을 조정.
- 마스크 생성: DSL의 각 bounding box를 마스크로 변환.
- 에너지 함수: Attention map이 bounding box 내부에 집중되도록 에너지 함수를 정의 (Etopk, ECoM).
- Gradient descent: 에너지 함수를 최소화하는 방향으로 attention map을 업데이트.
- Denoising: Attention map을 참고하여 노이즈를 제거하고 깨끗한 비디오를 생성.
장점:
- DSL 준수: 생성된 비디오가 DSL의 객체 위치 및 움직임 정보를 따름.
- Training-free: 추가 학습 없이 기존 diffusion model에 적용 가능.
- 유연성: 다양한 text-to-video diffusion model과 LLM에 적용 가능.
결과:
- 그림 5에서 DSL-grounded video generator가 그림 4의 DSL로 표현되는 사실적인 비디오를 생성할 수 있음을 보여줍니다.
1. 객체 디자인의 일관성은 어떻게 유지하는가?



