
AI바라기의 인공지능
LLM / VLM : 논문리뷰 : BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 본문
LLM / VLM : 논문리뷰 : BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
AI바라기 2024. 9. 13. 12:40Abstract
본 논문에서는 Sequence-to-Sequence 모델의 사전 훈련을 위한 denoising autoencoder인 BART를 소개합니다. BART는 (1) 텍스트를 임의의 noising function으로 손상시키고,
(2) 원본 텍스트를 복원하도록 모델을 학습시키는 방식으로 훈련됩니다.
BART는 표준 Transformer 기반 neural machine translation architecture를 사용하며, 단순함에도 불구하고 BERT(bidirectional encoder 덕분에), GPT(left-to-right decoder를 통해), 그리고 다른 최근의 pretraining scheme들을 일반화하는 것으로 볼 수 있습니다.
다양한 noising 접근 방식을 평가한 결과, 원래 문장의 순서를 무작위로 섞고 텍스트 범위를 단일 mask token으로 대체하는 새로운 in-filling scheme을 사용하여 최상의 성능을 얻을 수 있었습니다. BART는 특히 text generation에 fine tuned 되었을 때 효과적이지만 comprehension task에도 좋은 성능을 보입니다. GLUE 및 SQuAD에서 RoBERTa와 비슷한 training resources로 RoBERTa의 성능에 필적하며, abstractive dialogue, question answering 및 summarization task에서 최대 ROUGE 점수 향상을 달성하며 새로운 SOTA 결과를 달성했습니다.
또한 BART는 target language pretraining만으로 machine translation을 위한 back-translation 시스템에 비해 BLEU 점수 향상을 제공합니다. 또한 BART framework 내에서 다른 pretraining scheme들을 복제하는 ablation experiment를 통해 end-task 성능에 가장 큰 영향을 미치는 요인을 더 잘 측정합니다.
핵심 아이디어:
- BART (Bidirectional and Auto-Regressive Transformers): Sequence-to-sequence 모델을 위한 denoising autoencoder. 텍스트를 다양한 방식으로 손상시킨 후 원본 텍스트를 복원하도록 학습.
- Noising approaches: 텍스트 손상 방식은 다양하게 실험 (e.g., 문장 순서 섞기, 텍스트 일부를 mask token으로 대체).
- Architecture: Transformer-based neural machine translation architecture 사용. BERT (bidirectional encoder) 와 GPT (left-to-right decoder) 등 여러 pretraining scheme을 일반화 가능.
주요 결과:
- Text generation에 효과적: 특히 abstractive dialogue, question answering, summarization task에서 state-of-the-art 결과 달성 (최대 6 ROUGE 향상).
- Comprehension task에도 효과적: GLUE, SQuAD에서 RoBERTa와 비슷한 성능.
- Machine translation 성능 향상: Target language pretraining만으로 back-translation system 대비 1.1 BLEU 증가.
- Ablation study: 다양한 pretraining scheme을 BART framework 내에서 복제하여 end-task 성능에 영향을 미치는 요인 분석.
1 Introduction
Self-supervised methods는 다양한 NLP tasks에서 놀라운 성공을 거두었습니다 (Mikolov et al., 2013; Peters et al., 2018; Devlin et al., 2019; Joshi et al., 2019; Yang et al., 2019; Liu et al., 2019).
가장 성공적인 접근 방식은 masked language models의 변형으로, 단어의 random subset이 masked out된 텍스트를 복원하도록 훈련된 denoising autoencoders입니다.
최근 연구에서는 masked tokens의 distribution을 개선하고 (Joshi et al., 2019), masked tokens를 예측하는 순서를 변경하며 (Yang et al., 2019), masked tokens를 대체하기 위한 사용 가능한 context를 늘리는 것으로 (Dong et al., 2019) 성능 향상을 보여주었습니다. 그러나 이러한 방법들은 일반적으로 특정 유형의 end tasks (예: span prediction, generation 등)에 초점을 맞추어 적용 가능성을 제한합니다.
본 논문에서는 Bidirectional and Auto-Regressive Transformers를 결합한 모델을 사전 훈련하는 BART를 제시합니다. BART는 매우 광범위한 end tasks에 적용 가능한 sequence-to-sequence 모델로 구축된 denoising autoencoder입니다. Pretraining은 두 단계로 구성됩니다.
(1) 텍스트는 임의의 noising function으로 손상되고,
(2) sequence-to-sequence 모델은 원본 텍스트를 복원하도록 학습됩니다.
BART는 표준 Transformer 기반 neural machine translation architecture를 사용하며, 단순함에도 불구하고 BERT (bidirectional encoder 덕분에), GPT (left-to-right decoder를 통해) 및 기타 최근의 pretraining scheme들을 일반화하는 것으로 볼 수 있습니다 (그림 1 참조).

(a) BERT: Random tokens들이 masks로 대체되고, 문서는 bidirectionally하게 인코딩됩니다. 누락된 tokens들은 독립적으로 예측되므로 BERT는 generation에 쉽게 사용될 수 없습니다.
(b) GPT: Tokens들은 auto-regressively하게 예측되므로 GPT는 generation에 사용될 수 있습니다. 그러나 단어들은 왼쪽 context에만 의존할 수 있으므로 bidirectional interactions를 학습할 수 없습니다.

(c) BART: Encoder에 대한 입력은 decoder 출력과 aligned될 필요가 없으므로 임의의 noise transformations를 허용합니다. 여기서는 문서가 텍스트 범위를 mask symbols로 대체하여 손상되었습니다.
손상된 문서(왼쪽)는 bidirectional model로 인코딩된
다음 원본 문서(오른쪽)의 likelihood가 autoregressive decoder로 계산됩니다.
Fine-tuning을 위해 손상되지 않은 문서가 encoder와 decoder 모두에 입력되고 decoder의 final hidden state에서 representations를 사용합니다.
이러한 설정의 핵심 이점은 noising의 유연성입니다. 텍스트 길이 변경을 포함하여 원본 텍스트에 임의의 변형을 적용할 수 있습니다.
다양한 noising 접근 방식을 평가한 결과, 원래 문장의 순서를 무작위로 섞고 임의 길이 텍스트 범위(길이 0 포함)를 단일 mask token으로 대체하는 새로운 in-filling scheme을 사용하여 최상의 성능을 얻었습니다. 이 접근 방식은 모델이 전체 문장 길이에 대해 더 많이 추론하고 입력에 대해 더 긴 범위의 변환을 수행하도록 함으로써 BERT의 원래 word masking 및 next sentence prediction objectives를 일반화합니다.
BART는 특히 text generation에 fine tuned 되었을 때 효과적이지만 comprehension tasks에도 좋은 성능을 보입니다. GLUE 및 SQuAD에서 RoBERTa (Liu et al., 2019)와 비슷한 training resources로 RoBERTa의 성능에 필적하며, abstractive dialogue, question answering 및 summarization tasks에서 새로운 state-of-the-art 결과를 달성했습니다. 예를 들어, XSum (Narayan et al., 2018)에서 이전 연구보다 ROUGE 점수를 향상시켰습니다.
BART는 fine-tuning에 대한 새로운 접근 방식을 제시합니다. machine translation을 위한 새로운 scheme을 소개하는데, 여기서 BART 모델은 몇 개의 추가적인 transformer layers 위에 쌓입니다. 이러한 layers들은 BART를 통해 전파함으로써 외국어를 noised English로 번역하도록 훈련되며, BART를 pre-trained target-side language model로 활용합니다. 이 접근 방식은 WMT Romanian-English benchmark에서 강력한 back-translation MT baseline보다 BLEU 점수를 향상시킵니다.
이러한 효과를 더 잘 이해하기 위해 최근 제안된 다른 training objectives를 복제하는 ablation analysis도 보고합니다. 이 연구를 통해 data 및 optimization parameters를 포함한 여러 요인들을 신중하게 통제할 수 있었으며, 이러한 요인들은 training objectives 선택만큼이나 전체 성능에 중요한 것으로 나타났습니다 (Liu et al., 2019). 우리는 BART가 고려하는 모든 tasks에서 가장 일관되게 강력한 성능을 보인다는 것을 발견했습니다.
기존 연구의 한계:
- Masked language model (e.g., BERT) 기반의 denoising autoencoder는 특정 task에만 효과적.
- Masked token 예측 방식, 순서, context 등을 개선하는 연구들이 있었지만, 여전히 적용 가능성이 제한적.
BART의 핵심 아이디어:
- Bidirectional and Auto-Regressive Transformers: BERT의 양방향성 (bidirectional)과 GPT의 단방향성 (auto-regressive)을 결합.
- Denoising autoencoder: 다양한 noising function으로 텍스트를 손상시키고, 원본 텍스트를 복원하도록 학습.
- Sequence-to-sequence model: 텍스트 생성, 번역, 이해 등 다양한 task에 적용 가능한 범용적인 구조.
BART의 장점:
- Noising 유연성: 텍스트 길이 변경 등 원본 텍스트에 다양한 변환 적용 가능.
- 광범위한 task에 적용 가능: Text generation, comprehension task 모두 효과적.
- State-of-the-art 성능: 다양한 task에서 기존 모델 대비 성능 향상 (e.g., XSum에서 6 ROUGE 향상).
- Fine-tuning 유연성: Machine translation 등 새로운 fine-tuning scheme 적용 가능.
2 Model
BART는 손상된 문서를 원본 문서로 매핑하는 denoising autoencoder입니다. 손상된 텍스트에 대한 bidirectional encoder와 left-to-right autoregressive decoder를 사용하는 sequence-to-sequence model로 구현됩니다. Pre-training을 위해 원본 문서의 negative log likelihood를 최적화합니다.
2.1 Architecture
BART는 (Vaswani et al., 2017)의 표준 sequence-to-sequence Transformer architecture를 사용하지만, GPT를 따라 ReLU activation functions를 GeLUs (Hendrycks & Gimpel, 2016)로 수정하고 파라미터를 N(0, 0.02)에서 초기화합니다. Base 모델의 경우 encoder와 decoder에 각각 6개의 layer를 사용하고, large 모델의 경우 각각 12개의 layer를 사용합니다.
이 architecture는 BERT에서 사용된 것과 매우 유사하지만 다음과 같은 차이점이 있습니다:
- Decoder의 각 layer는 추가적으로 encoder의 final hidden layer에 대해 cross-attention을 수행합니다 (transformer sequence-to-sequence model에서처럼).
- BERT는 word prediction 전에 추가적인 feed-forward network를 사용하지만 BART는 사용하지 않습니다.
전체적으로 BART는 동일한 크기의 BERT 모델보다 약 10% 더 많은 parameters를 포함합니다.
2.2 Pre-training BART
BART는 문서를 손상시킨 후 reconstruction loss, 즉 decoder의 출력과 원본 문서 사이의 cross-entropy를 최적화하여 훈련됩니다. 특정 noising scheme에 맞춰진 기존 denoising autoencoders와 달리 BART는 모든 유형의 문서 손상을 적용할 수 있습니다. 극단적인 경우, source에 대한 모든 정보가 손실되면 BART는 language model과 동일합니다.
이전에 제안된 여러 가지 변형과 새로운 변형을 실험했지만, 다른 새로운 대안을 개발할 수 있는 상당한 잠재력이 있다고 생각합니다. 사용된 변형은 아래에 요약되어 있으며, 예시는 그림 2에 나와 있습니다.
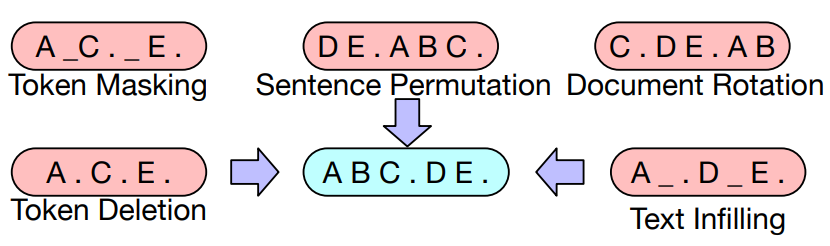
Figure 2: 실험에 사용된 입력 noising을 위한 Transformations. 이러한 transformations들은 함께 구성될 수 있습니다.
- Token Masking: BERT (Devlin et al., 2019)를 따라, 무작위로 선택된 tokens들을 [MASK] element로 대체합니다.
- Token Deletion: 입력에서 무작위 tokens들을 삭제합니다. Token masking과 달리, 모델은 어떤 위치에 입력이 누락되었는지 스스로 결정해야 합니다.
- Text Infilling: 여러 개의 text spans들을 샘플링하며, span 길이는 Poisson distribution (λ = 3)에서 추출됩니다. 각 span은 단일 [MASK] token으로 대체됩니다. 길이가 0인 span은 [MASK] tokens 삽입에 해당합니다. Text infilling은 SpanBERT (Joshi et al., 2019)에서 영감을 받았지만, SpanBERT는 span 길이를 다른 (clamped geometric) distribution에서 샘플링하고, 각 span을 정확히 동일한 길이의 [MASK] tokens sequence로 대체합니다. Text infilling은 모델에게 span에서 얼마나 많은 tokens들이 누락되었는지 예측하도록 가르칩니다.
- Sentence Permutation: 문서는 마침표를 기준으로 문장으로 나뉘고, 이 문장들은 무작위 순서로 섞입니다.
- Document Rotation: token 하나가 균일하게 무작위로 선택되고, 문서는 해당 token으로 시작하도록 회전됩니다. 이 task는 모델에게 문서의 시작 부분을 식별하도록 훈련시킵니다.
BART 모델 개요:
- Denoising autoencoder: 손상된 문서를 원본 문서로 복원하는 모델.
- Sequence-to-sequence model: Encoder-decoder 구조를 가짐.
- Bidirectional encoder: 손상된 텍스트를 양방향으로 처리.
- Left-to-right autoregressive decoder: 원본 텍스트를 왼쪽에서 오른쪽으로 순차적으로 생성.
- 학습 목표: 원본 문서의 negative log likelihood 최소화.
BART 모델 구조:
- Transformer 기반: 기존 Transformer (Vaswani et al., 2017) 활용.
- ReLU activation function → GeLU (Hendrycks & Gimpel, 2016) 로 변경.
- Parameter 초기화: N(0, 0.02).
- Encoder-decoder layer 개수:
- Base model: 각 6개 layer.
- Large model: 각 12개 layer.
- BERT와의 차이점:
- Decoder에서 encoder의 final hidden layer에 대해 cross-attention 수행.
- Word prediction 전에 추가 feed-forward network 사용 안 함.
- BERT 대비 parameter 수: 약 10% 더 많음.
BART Pre-training:
- 다양한 noising function: 텍스트 손상 방식에 제약이 없음.
- Token masking, token deletion, text infilling, sentence permutation, document rotation 등.
- Text infilling:
- Poisson 분포 (λ = 3) 기반으로 span 길이를 샘플링하여 mask token으로 대체.
- SpanBERT와 유사하지만, span 길이 샘플링 방식과 masking 방식에 차이가 있음.
- Noising function 개발 가능성: 다양한 noising function을 통해 모델 성능 향상 가능성이 열려 있음.
3 Fine-tuning BART
BART에 의해 생성된 representations는 downstream applications을 위해 여러 가지 방법으로 사용될 수 있습니다.
3.1 Sequence Classification Tasks
Sequence classification tasks의 경우, 동일한 입력이 encoder와 decoder에 입력되고, 마지막 decoder token의 final hidden state가 새로운 multi-class linear classifier에 입력됩니다. 이 접근 방식은 BERT의 CLS token과 관련이 있습니다. 그러나 decoder의 token에 대한 representation이 전체 입력으로부터 decoder states에 attend 할 수 있도록 추가 token을 끝에 추가합니다 (그림 3a 참조).
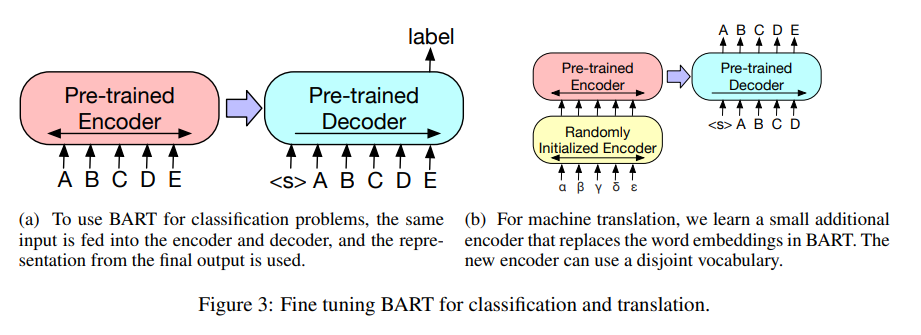
(a) BART를 classification 문제에 사용하기 위해 동일한 입력이 encoder와 decoder에 입력되고, final output에서 얻은 representation이 사용됩니다.
(b) Machine translation을 위해 BART의 word embeddings를 대체하는 작은 추가 encoder를 학습시킵니다. 새로운 encoder는 disjoint vocabulary를 사용할 수 있습니다.
Figure 3: Classification 및 translation을 위한 BART fine-tuning.
3.2 Token Classification Tasks
SQuAD의 answer endpoint classification과 같은 token classification tasks의 경우, 전체 문서를 encoder와 decoder에 입력하고, decoder의 top hidden state를 각 단어에 대한 representation으로 사용합니다. 이 representation은 token을 분류하는 데 사용됩니다.
3.3 Sequence Generation Tasks
BART는 autoregressive decoder를 가지고 있기 때문에 abstractive question answering 및 summarization과 같은 sequence generation tasks에 직접 fine-tuning될 수 있습니다. 두 task 모두 입력에서 정보를 복사하지만 조작하기도 하는데, 이는 denoising pre-training objective와 밀접하게 관련되어 있습니다. 여기서 encoder 입력은 입력 sequence이며, decoder는 출력을 autoregressively하게 생성합니다.
3.4 Machine Translation
또한 BART를 사용하여 영어로 번역하는 machine translation decoders를 개선하는 방법을 살펴봅니다. 이전 연구 Edunov et al. (2019)는 pre-trained encoders를 통합하여 모델을 개선할 수 있음을 보여주었지만, decoders에서 pre-trained language models를 사용하여 얻는 이점은 제한적이었습니다. bitext에서 학습된 새로운 encoder parameters 세트를 추가하여 전체 BART 모델(encoder 및 decoder 모두)을 machine translation을 위한 단일 pretrained decoder로 사용할 수 있음을 보여줍니다 (그림 3b 참조).
보다 정확하게는 BART의 encoder embedding layer를 새롭게 무작위로 초기화된 encoder로 대체합니다. 모델은 end-to-end로 훈련되며, 이는 새로운 encoder가 외국어 단어를 BART가 English로 de-noise할 수 있는 입력으로 매핑하도록 훈련시킵니다. 새로운 encoder는 원래 BART 모델과 별개의 vocabulary를 사용할 수 있습니다.
Source encoder는 두 단계로 훈련되며, 두 경우 모두 BART 모델의 출력에서 cross-entropy loss를 backpropagating합니다. 첫 번째 단계에서는 대부분의 BART parameters를 freeze하고 무작위로 초기화된 source encoder, BART positional embeddings 및 BART encoder 첫 번째 layer의 self-attention input projection matrix만 업데이트합니다. 두 번째 단계에서는 모든 model parameters를 약간의 iterations 동안 훈련시킵니다.
BART 활용:
- BART는 pre-trained 모델로, 다양한 downstream task에 맞게 fine-tuning하여 사용 가능.
- Fine-tuning 방식은 task의 종류에 따라 다름.
Fine-tuning 방법:
- Sequence Classification:
- Encoder와 decoder에 동일한 입력을 넣고, decoder의 마지막 token의 final hidden state를 이용하여 classification 수행.
- BERT의 CLS token과 유사하지만, BART는 마지막 token에 추가적인 token을 넣어 전체 입력에 대한 정보를 활용.
- Token Classification:
- Encoder와 decoder에 전체 문서를 입력하고, decoder의 top hidden state를 각 단어의 representation으로 사용하여 token을 분류.
- SQuAD와 같은 question answering task에 활용 가능.
- Sequence Generation:
- BART의 autoregressive decoder를 이용하여 텍스트 생성 task에 직접 fine-tuning.
- Abstractive question answering, summarization 등에 활용.
- Encoder 입력은 input sequence, decoder는 출력을 autoregressively 생성.
- Machine Translation:
- BART 전체를 pre-trained decoder로 사용하여 machine translation 성능 향상.
- 새로운 encoder parameter를 추가하여 외국어를 BART가 처리 가능한 형태로 변환.
- 새로운 encoder는 BART model과 다른 vocabulary를 사용 가능.
- Source encoder 학습은 두 단계로 진행:
- 1단계: BART parameter 대부분을 freeze하고, source encoder, positional embedding, self-attention input projection matrix만 업데이트.
- 2단계: 모든 model parameter를 적은 iteration 동안 학습.
4 Comparing Pre-training Objectives
BART는 이전 연구보다 훨씬 더 광범위한 noising scheme들을 pre-training 중에 지원합니다. base-size 모델(encoder 및 decoder 각 6 layer, hidden size 768)을 사용하여 다양한 옵션을 비교하고, 5에서 full large scale experiments를 위해 고려할 tasks의 대표적인 subset에 대해 평가합니다.
4.1 Comparison Objectives
많은 pre-training objectives가 제안되었지만, training data, training resources, 모델 간의 architecture 차이, fine-tuning procedures 등의 차이로 인해 이들 사이의 공정한 비교는 어려웠습니다. 최근 discriminative 및 generation tasks를 위해 제안된 강력한 pre-training 접근 방식들을 다시 구현했습니다. 가능한 한 pre-training objective와 관련 없는 차이점들을 통제하려고 노력했습니다. 그러나 성능 향상을 위해 learning rate 및 layer normalization 사용에 약간의 변경을 가했습니다 (각 objective에 대해 별도로 조정). 참고로, 우리의 구현을 books와 Wikipedia data 조합에 대해 1M steps 동안 훈련된 BERT의 published numbers와 비교합니다.
다음 접근 방식들을 비교합니다:
- Language Model: GPT (Radford et al., 2018)와 유사하게, left-to-right Transformer language model을 훈련합니다. 이 모델은 cross-attention 없이 BART decoder와 동일합니다.
- Permuted Language Model: XLNet (Yang et al., 2019)을 기반으로, 토큰의 1/6을 샘플링하고 autoregressively하게 무작위 순서로 생성합니다. 다른 모델과의 일관성을 위해 XLNet의 relative positional embeddings 또는 attention across segments는 구현하지 않습니다.
- Masked Language Model: BERT (Devlin et al., 2019)를 따라, 15%의 토큰을 [MASK] symbols로 대체하고 모델을 훈련하여 원본 토큰을 독립적으로 예측합니다.
- Multitask Masked Language Model: UniLM (Dong et al., 2019)과 같이 추가적인 self-attention masks를 사용하여 Masked Language Model을 훈련합니다. Self-attention masks는 다음 비율로 무작위로 선택됩니다: 1/6 left-to-right, 1/6 right-to-left, 1/3 unmasked, 1/3는 처음 50% 토큰은 unmasked이고 나머지는 left-to-right mask를 사용합니다.
- Masked Seq-to-Seq: MASS (Song et al., 2019)에서 영감을 받아, 50%의 토큰을 포함하는 span을 masking하고, masked tokens를 예측하도록 sequence-to-sequence model을 훈련합니다.
Permuted LM, Masked LM 및 Multitask Masked LM의 경우, two-stream attention (Yang et al., 2019)을 사용하여 sequence의 출력 부분의 likelihood를 효율적으로 계산합니다 (왼쪽에서 오른쪽으로 단어를 예측하기 위해 출력에 diagonal self-attention mask를 사용).
다음 두 가지 방법을 실험했습니다:
(1) task를 표준 sequence-to-sequence 문제로 처리하여 source 입력을 encoder에, target을 decoder 출력으로 사용하는 방법, 또는
(2) source를 decoder의 target에 prefix로 추가하고 sequence의 target 부분에만 loss를 적용하는 방법. BART 모델의 경우 전자가 더 잘 작동하고 다른 모델의 경우 후자가 더 잘 작동하는 것을 발견했습니다.
Fine-tuning objective(human text의 log likelihood)를 모델링하는 능력을 가장 직접적으로 비교하기 위해 표 1에 perplexity를 보고합니다.
4.2 Tasks
- SQuAD (Rajpurkar et al., 2016): Wikipedia paragraphs에 대한 extractive question answering task입니다. Answers는 주어진 document context에서 추출된 text spans입니다. BERT (Devlin et al., 2019)와 유사하게, 연결된 question과 context를 BART encoder의 입력으로 사용하고, 추가로 decoder에도 전달합니다. 모델은 각 token의 시작 및 끝 indices를 예측하는 classifiers를 포함합니다.
- MNLI (Williams et al., 2017): 한 문장이 다른 문장을 entail하는지 예측하는 bitext classification task입니다. Fine-tuned 모델은 두 문장을 연결하고 EOS token을 추가하여 BART encoder와 decoder 모두에 전달합니다. BERT와 달리 EOS token의 representation이 문장 관계를 분류하는 데 사용됩니다.
- ELI5 (Fan et al., 2019): question과 supporting documents의 연결에 conditioned된 long-form abstractive question answering dataset입니다.
- XSum (Narayan et al., 2018): highly abstractive summaries를 가진 news summarization dataset입니다.
- ConvAI2 (Dinan et al., 2019): context 및 persona에 conditioned된 dialogue response generation task입니다.
- CNN/DM (Hermann et al., 2015): news summarization dataset입니다. Summaries는 일반적으로 source sentences와 밀접하게 관련되어 있습니다.
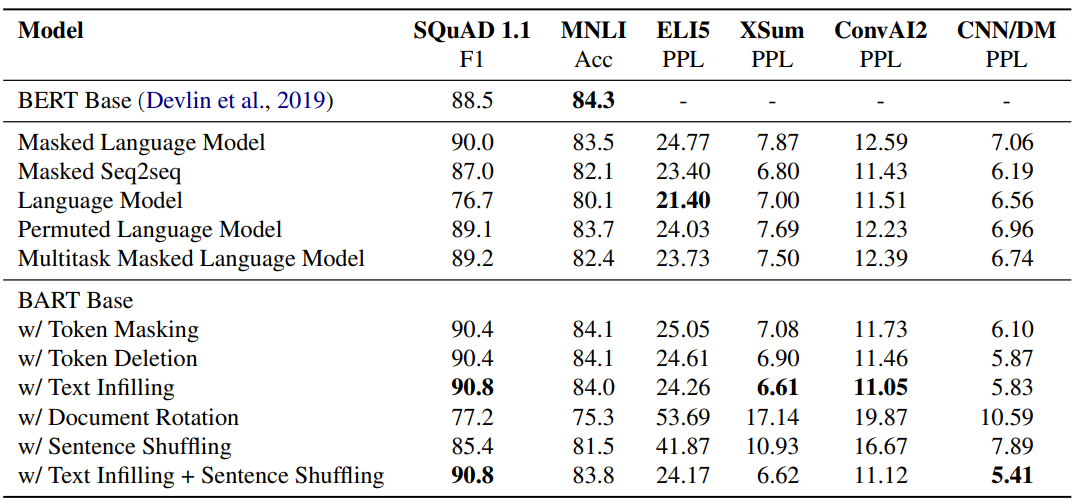
표 1: Pre-training objectives 비교. 모든 모델은 크기가 비슷하며 books와 Wikipedia data를 결합하여 1M steps 동안 학습되었습니다. 아래쪽 두 블록의 항목은 동일한 코드베이스를 사용하여 동일한 데이터로 학습되었으며 동일한 procedures로 fine-tuned되었습니다. 두 번째 블록의 항목은 이전 연구에서 제안된 pre-training objectives에서 영감을 받았지만 evaluation objectives에 중점을 두도록 단순화되었습니다 (§4.1 참조). 성능은 tasks에 따라 상당히 다르지만 text infilling을 사용하는 BART models는 가장 일관되게 강력한 성능을 보여줍니다.
4.3 Results
- Pre-training methods의 성능은 tasks에 따라 크게 다릅니다. Pre-training methods의 효과는 task에 따라 다릅니다. 예를 들어, simple language model은 최상의 ELI5 성능을 달성하지만 최악의 SQUAD 결과를 얻습니다.
- Token masking이 중요합니다. 문서를 회전하거나 문장을 permutation하는 것에 기반한 Pre-training objectives는 단독으로 수행하면 성능이 좋지 않습니다. 성공적인 방법은 token deletion 또는 masking 또는 self-attention masks를 사용합니다. Deletion은 generation tasks에서 masking보다 성능이 뛰어난 것으로 보입니다.
- Left-to-right pre-training은 generation을 개선합니다. Masked Language Model과 Permuted Language Model은 generation에서 다른 모델보다 성능이 떨어지며 pre-training 중에 left-to-right auto-regressive language modelling을 포함하지 않는 유일한 모델입니다.
- Bidirectional encoders는 SQuAD에 중요합니다. 이전 연구 (Devlin et al., 2019)에서 언급했듯이 left-to-right decoder만 사용하면 future context가 classification decisions에 중요하기 때문에 SQuAD에서 성능이 좋지 않습니다. 그러나 BART는 bidirectional layers 수의 절반만으로도 유사한 성능을 달성합니다.
- Pre-training objective만 중요한 요소는 아닙니다. Permuted Language Model은 XLNet (Yang et al., 2019)보다 성능이 떨어집니다. 이러한 차이 중 일부는 relative-position embeddings 또는 segment-level recurrence와 같은 다른 architecture 개선 사항을 포함하지 않았기 때문일 수 있습니다.
- Pure language models는 ELI5에서 최상의 성능을 발휘합니다. ELI5 dataset은 다른 tasks보다 훨씬 높은 perplexities를 가진 outlier이며 다른 모델이 BART보다 성능이 뛰어난 유일한 generation task입니다. Pure language model이 최상의 성능을 발휘하는데, 이는 출력이 입력에 의해 느슨하게 제약될 때 BART가 덜 효과적임을 시사합니다.
- BART는 가장 일관되게 강력한 성능을 달성합니다. ELI5를 제외하고 text-infilling을 사용하는 BART models는 모든 tasks에서 좋은 성능을 보입니다.
주제: 다양한 pre-training objectives를 비교 분석하여 BART의 성능 우수성 입증
실험 목표:
- 기존 pre-training objectives (e.g., Language Model, Masked Language Model) 와 BART의 성능 비교.
- 다양한 downstream tasks에서 BART의 효과 검증.
- Pre-training objective가 모델 성능에 미치는 영향 분석.
실험 설정:
- Base-size models: 6 encoder layers, 6 decoder layers, hidden size 768.
- Training data: Books + Wikipedia data (1M steps).
- Downstream tasks: SQuAD, MNLI, ELI5, XSum, ConvAI2, CNN/DM.
- Pre-training objectives:
- Language Model (GPT)
- Permuted Language Model (XLNet)
- Masked Language Model (BERT)
- Multitask Masked Language Model (UniLM)
- Masked Seq-to-Seq (MASS)
- BART (다양한 noising functions)
주요 결과:
- Pre-training objective에 따라 task별 성능 차이가 큼. (e.g., Language Model은 ELI5에서 최고, SQuAD에서 최악)
- Token masking 중요. Token deletion 또는 masking, self-attention masks를 사용하는 방법이 효과적.
- Generation tasks에서는 deletion이 masking보다 우수.
- Left-to-right pre-training은 generation 성능 향상. Masked LM, Permuted LM은 generation task에서 성능이 낮음 (left-to-right autoregressive language modeling 미포함).
- Bidirectional encoder는 SQuAD에 중요. Left-to-right decoder만 사용하면 SQuAD에서 성능이 낮음 (future context 중요).
- BART는 적은 bidirectional layers로도 유사한 성능 달성.
- Pre-training objective 외 다른 요인도 중요. (e.g., XLNet은 relative-position embeddings 등 BART에 없는 architecture 개선 사항 포함)
- Pure language model은 ELI5에서 최고 성능. ELI5는 perplexity가 높고, 출력 제약이 적어 BART가 덜 효과적.
- BART는 대부분 task에서 강력한 성능. Text infilling을 사용하는 BART는 ELI5를 제외한 모든 task에서 우수한 성능.
5 Large-scale Pre-training Experiments\
최근 연구에 따르면 pre-training이 큰 batch size 및 corpora로 확장될 때 다운스트림 성능이 크게 향상될 수 있습니다. 이러한 regime에서 BART가 얼마나 잘 수행되는지 테스트하고 다운스트림 tasks에 유용한 모델을 만들기 위해 RoBERTa 모델과 동일한 scale을 사용하여 BART를 학습했습니다.
5.1 Experimental Setup
Encoder와 decoder 각각에 12개의 layers가 있고 hidden size가 1024인 large model을 pre-train합니다. RoBERTa (Liu et al., 2019)를 따라 batch size 8000을 사용하고 500000 steps 동안 모델을 학습합니다. 문서는 GPT-2 (Radford et al., 2019)와 동일한 byte-pair encoding으로 tokenized됩니다. §4의 결과를 바탕으로 text infilling과 sentence permutation을 결합하여 사용합니다. 각 문서에서 tokens의 30%를 masking하고 모든 문장을 permutation합니다. Sentence permutation은 CNN/DM summarization dataset에서만 상당한 추가 이점을 보여주지만, 더 큰 pre-trained models가 이 task에서 더 잘 학습할 수 있을 것이라고 가정했습니다. 모델이 데이터에 더 잘 맞도록 학습 steps의 마지막 10% 동안 dropout을 비활성화했습니다. 160Gb의 뉴스, 책, 이야기 및 웹 텍스트로 구성된 Liu et al. (2019)와 동일한 pre-training data를 사용합니다.
5.2 Discriminative Tasks
표 2는 잘 연구된 SQuAD 및 GLUE tasks에서 BART의 성능을 여러 최신 접근 방식과 비교합니다. 가장 직접적으로 비교할 수 있는 baseline은 동일한 resources로 pre-trained되었지만 objective가 다른 RoBERTa입니다. 전반적으로 BART는 유사하게 수행되며 대부분의 tasks에서 모델 간의 차이가 거의 없습니다. 이는 generation tasks에서 BART의 개선이 classification 성능을 희생하지 않음을 시사합니다.
5.3 Generation Tasks
또한 여러 text generation tasks를 실험합니다. BART는 입력에서 출력 텍스트까지 standard sequence-to-sequence model로 fine-tuned됩니다. Fine-tuning하는 동안 smoothing parameter를 0.1로 설정하여 label smoothed cross entropy loss (Pereyra et al., 2017)를 사용합니다. Generation하는 동안 beam size를 5로 설정하고 beam search에서 duplicated trigrams를 제거하고 validation set에서 min-len, max-len, length penalty를 사용하여 모델을 tuned합니다 (Fan et al., 2017).
Summarization: Summarization의 state-of-the-art와 비교하기 위해 서로 다른 특성을 가진 두 개의 summarization datasets인 CNN/DailyMail 및 XSum에 대한 결과를 제시합니다.
CNN/DailyMail의 Summaries는 source sentences와 유사한 경향이 있습니다. Extractive models는 여기서 잘 수행되며 처음 세 개의 source sentences의 baseline조차도 매우 경쟁력이 있습니다. 그럼에도 불구하고 BART는 기존의 모든 연구보다 성능이 뛰어납니다.
반대로 XSum은 highly abstractive하며 extractive models는 성능이 좋지 않습니다. BART는 BERT를 활용하는 이전의 최고 연구보다 모든 ROUGE metrics에서 약 6.0점 높은 성능을 보이며 이 문제에 대한 성능이 크게 향상되었습니다. 질적으로 샘플 품질이 높습니다 (§6 참조).
Dialogue: 에이전트가 이전 context와 텍스트로 지정된 persona를 모두 조건으로 하여 응답을 생성해야 하는 CONVAI2 (Dinan et al., 2019)에서 dialogue response generation을 평가합니다. BART는 두 개의 automated metrics에서 이전 연구보다 성능이 뛰어납니다.
Abstractive QA: 최근 제안된 ELI5 dataset을 사용하여 모델이 long free-form answers를 생성하는 능력을 테스트합니다. BART는 이전의 최고 연구보다 ROUGE-L이 1.2 높은 성능을 보이지만 답변이 질문에 의해 약하게 지정되기 때문에 dataset은 여전히 어려운 과제입니다.
5.4 Translation
또한 Sennrich et al. (2016)의 back-translation data로 augmented된 WMT16 Romanian-English에 대한 성능을 평가했습니다. §3.4에서 소개된 접근 방식에 따라 6-layer transformer source encoder를 사용하여 Romanian을 BART가 영어로 de-noise할 수 있는 representation으로 매핑합니다.
실험 결과는 표 6에 나와 있습니다. 결과를 Transformer-large 설정 (baseline row)을 사용하는 baseline Transformer architecture (Vaswani et al., 2017)와 비교합니다. Fixed BART 및 tuned BART rows에서 모델의 두 단계 모두의 성능을 보여줍니다. 각 row에 대해 back-translation data로 augmented된 원래 WMT16 Romanian-English에서 실험합니다. Beam width 5와 length penalty α = 1을 사용합니다.
예비 결과는 우리의 접근 방식이 back-translation data 없이는 덜 효과적이고 overfitting되기 쉽다는 것을 시사합니다. 향후 연구에서는 추가 regularization techniques를 탐색해야 합니다.
실험 목표:
- Large batch size 및 corpora를 사용한 pre-training이 BART 성능에 미치는 영향 분석.
- RoBERTa와 동일한 scale의 pre-training을 통해 BART와 비교.
- 다양한 downstream tasks에서 BART의 성능 검증.
실험 설정:
- Large model: 12 encoder layers, 12 decoder layers, hidden size 1024.
- Large batch size: 8000 (RoBERTa와 동일).
- Training steps: 500,000 steps.
- Tokenization: GPT-2와 동일한 byte-pair encoding 사용.
- Noising function: Text infilling (30% masking) + Sentence permutation.
- Dropout: 마지막 10% training steps 동안 비활성화.
- Pre-training data: 160GB 뉴스, 책, 이야기, 웹 텍스트 (RoBERTa와 동일).
실험 결과:
- Discriminative tasks (SQuAD, GLUE):
- RoBERTa와 유사한 성능.
- BART의 generation task 성능 향상이 classification 성능을 희생시키지 않음을 보여줌.
- Generation tasks (Summarization, Dialogue, Abstractive QA):
- Summarization:
- CNN/DailyMail: Extractive model보다 우수한 성능.
- XSum: 기존 연구 대비 ROUGE score 6.0점 향상.
- Dialogue (ConvAI2): Automated metrics에서 기존 연구보다 우수한 성능.
- Abstractive QA (ELI5): 기존 연구 대비 ROUGE-L 1.2점 향상.
- Summarization:
- Machine Translation (WMT16 Romanian-English):
- Back-translation data 사용.
- 6-layer Transformer source encoder를 사용하여 Romanian을 BART가 처리 가능한 형태로 변환.
- Baseline Transformer model 대비 성능 향상.
- Back-translation data 없이는 overfitting 발생 가능성.
결론:
- Large-scale pre-training은 BART의 성능을 크게 향상시킴.
- BART는 다양한 downstream tasks에서 높은 성능을 보임.
- Text infilling과 sentence permutation을 결합한 noising function이 효과적임을 확인.
6. Qualitative Analysis
BART는 이전 state-of-the-art보다 최대 6점까지 summarization metrics에서 큰 개선을 보여줍니다. Automated metrics를 넘어 BART의 성능을 이해하기 위해 generation을 정성적으로 분석합니다. 표 7은 BART가 생성한 summaries 예를 보여줍니다. 예는 pre-training corpus를 만든 후에 게시된 WikiNews 기사에서 가져온 것으로, 설명된 이벤트가 모델의 training data에 존재할 가능성을 제거합니다. Narayan et al. (2018)을 따라 summarization하기 전에 기사의 첫 번째 문장을 제거하여 문서의 easy extractive summary가 없도록 합니다.
당연히 모델 출력은 유창하고 문법적인 영어입니다. 그러나 모델 출력은 입력에서 복사된 구문이 거의 없는 highly abstractive합니다. 또한 출력은 일반적으로 사실적으로 정확하며 입력 문서 전체의 supporting evidence를 background knowledge와 통합합니다 (예를 들어, 이름을 올바르게 완성하거나 PG&E가 캘리포니아에서 운영된다는 것을 추론). 첫 번째 예에서 물고기가 지구 온난화로부터 암초를 보호한다는 것을 추론하려면 텍스트에서 non-trivial inference가 필요합니다. 그러나 이 연구가 Science에 발표되었다는 주장은 source에서 뒷받침되지 않습니다.
이러한 샘플은 BART pre-training이 natural language understanding과 generation의 강력한 조합을 학습했음을 보여줍니다.
7. Related Work
Pre-training을 위한 초기 방법은 language models를 기반으로 했습니다. GPT (Radford et al., 2018)는 leftward context만 모델링하는데, 이는 일부 tasks에 문제가 됩니다. ELMo (Peters et al., 2018)는 left-only 및 right-only representations를 연결하지만 이러한 features 간의 interactions를 pre-train하지 않습니다. Radford et al. (2019)는 매우 큰 language models가 unsupervised multitask models 역할을 할 수 있음을 보여주었습니다.
BERT (Devlin et al., 2019)는 pre-training이 left 및 right context words 간의 interactions를 학습할 수 있도록 하는 masked language modelling을 도입했습니다. 최근 연구에서는 더 오래 학습하고 (Liu et al., 2019), layers 간에 parameters를 tying하고 (Lan et al., 2019), 단어 대신 spans를 masking하여 (Joshi et al., 2019) 매우 강력한 성능을 달성할 수 있음을 보여주었습니다. 예측은 auto-regressively 이루어지지 않아 generation tasks에 대한 BERT의 효과가 감소합니다.
UniLM (Dong et al., 2019)은 일부는 leftward context만 허용하는 masks ensemble을 사용하여 BERT를 fine-tune합니다. BART와 마찬가지로 UniLM을 generative 및 discriminative tasks 모두에 사용할 수 있습니다. UniLM predictions는 conditionally independent하지만 BART는 autoregressive하다는 점이 다릅니다. BART는 decoder가 항상 uncorrupted context에서 학습되기 때문에 pre-training과 generation tasks 간의 불일치를 줄입니다.
MASS (Song et al., 2019)는 아마도 BART와 가장 유사한 모델일 것입니다. Tokens의 연속된 span이 masked된 input sequence는 누락된 tokens으로 구성된 sequence에 매핑됩니다. MASS는 disjoint sets의 tokens가 encoder와 decoder에 제공되기 때문에 discriminative tasks에 덜 효과적입니다.
XL-Net (Yang et al., 2019)은 masked tokens을 permuted order로 auto-regressively 예측하여 BERT를 확장합니다. 이 objective를 사용하면 left 및 right context를 모두 조건으로 예측할 수 있습니다. 반대로 BART decoder는 generation 중 설정과 일치하는 pre-training 중에 left-to-right로 작동합니다.
여러 논문에서 pre-trained representations를 사용하여 machine translation을 개선하는 방법을 살펴보았습니다. 가장 큰 개선은 source 및 target languages 모두에서 pre-training하는 것에서 비롯되었지만 (Song et al., 2019; Lample & Conneau, 2019) 이를 위해서는 관심 있는 모든 languages에 대해 pre-training해야 합니다. 다른 연구에서는 pre-trained representations를 사용하여 encoders를 개선할 수 있음을 보여주었지만 (Edunov et al., 2019) decoders의 이점은 더 제한적입니다. BART를 사용하여 machine translation decoders를 개선하는 방법을 보여줍니다.
8. Conclusions
손상된 문서를 원본에 매핑하는 방법을 학습하는 pre-training approach인 BART를 소개했습니다. BART는 discriminative tasks에서 RoBERTa와 유사한 성능을 달성하는 동시에 여러 text generation tasks에서 새로운 state-of-the-art 결과를 달성합니다. 향후 연구에서는 pre-training을 위해 문서를 손상시키는 새로운 방법을 모색하고 특정 end tasks에 맞게 조정해야 합니다.
주제: BART가 생성한 요약의 질적 분석을 통해 성능 향상을 심층적으로 이해
분석 방법:
- WikiNews 기사 활용: Pre-training corpus 이후에 게시된 기사를 사용하여 training data와의 중복 방지.
- 첫 문장 제거: Extractive summarization을 방지하고, abstractive summarization 능력 평가.
- BART 생성 요약 분석: 생성된 요약의 유창성, 문법적 정확성, 추상성, 사실적 정확성, 배경 지식 활용 등을 평가.
주요 결과:
- 유창하고 문법적인 영어: BART는 자연스러운 영어 문장 생성.
- 높은 추상성: 입력 문장을 그대로 복사하지 않고, 핵심 정보를 추상적으로 요약.
- 사실적 정확성: 생성된 요약은 대체로 사실에 부합.
- 배경 지식 활용: 입력 문서와 배경 지식을 결합하여 요약 생성 (e.g., 이름 완성, PG&E가 캘리포니아에서 운영된다는 사실 추론).
- 추론 능력: 입력 텍스트에서 의미 있는 정보를 추론 (e.g., 물고기가 지구 온난화로부터 암초를 보호).
- 일부 사실 오류: 출처에서 뒷받침되지 않는 정보를 포함하는 경우도 있음 (e.g., Science 논문 게재).
결론:
- BART는 높은 수준의 natural language understanding and generation 능력을 갖춤.
- Automated metrics뿐만 아니라 질적 분석을 통해 BART의 성능 향상 확인.
참고:
- 표 7은 BART가 생성한 요약 예시를 보여줌.
- 질적 분석을 통해 BART의 강점과 약점을 파악하고, 향후 연구 방향 설정 가능.
향후 연구 방향:
- 사실 오류를 줄이고, 더욱 정확한 요약을 생성하는 방법 연구.
- 다양한 유형의 텍스트에 대한 질적 분석 수행.
BART 논문 정리노트 - Related Work (7)
주제: 기존 pre-training 방법론과 BART를 비교 분석
주요 내용:
- 초기 연구: Language model 기반 pre-training (e.g., GPT, ELMo).
- GPT: Leftward context만 고려, 일부 task에 부적합.
- ELMo: Left-only & right-only representations 결합, feature interactions 미학습.
- BERT: Masked language modeling 도입, 양방향 context 학습 가능.
- 학습 시간 증가, parameter tying, span masking 등으로 성능 향상.
- Autoregressive prediction 미지원 → generation task에 불리.
- UniLM: BERT를 masks ensemble로 fine-tuning, generative & discriminative task 모두 지원.
- BART와 달리 conditionally independent prediction.
- MASS: 연속된 token span을 masking하고 복원하는 sequence-to-sequence model.
- Disjoint sets의 token을 사용 → discriminative task에 불리.
- XL-Net: Permuted order로 masked token을 autoregressively 예측, 양방향 context 활용.
- BART는 left-to-right pre-training → generation task에 적합.
- Machine Translation: Pre-trained representations 활용 연구.
- Source & target language pre-training → 높은 성능, but 모든 언어에 pre-training 필요.
- Encoder pre-training → 효과적, decoder pre-training → 제한적.
- BART는 decoder pre-training으로 machine translation 성능 향상 가능.
결론:
- BART는 기존 방법론의 한계를 극복하고, 다양한 task에 효과적인 pre-training approach.
- Bidirectional encoder & left-to-right decoder 결합, noising function 유연성, autoregressive prediction 등이 BART의 강점.
참고:
- BART는 BERT, XL-Net 등의 장점을 결합하고, generation task에 특화된 pre-training objective를 제시.
- UniLM, MASS와의 비교를 통해 BART의 차별성 부각.
BART 논문 정리노트 - Conclusions (8)
주제: BART 연구의 핵심 내용 요약 및 향후 연구 방향 제시
주요 내용:
- BART 소개: 손상된 문서를 원본으로 복원하는 pre-training approach.
- BART 성능:
- Discriminative tasks: RoBERTa와 유사한 성능.
- Generation tasks: State-of-the-art 결과 달성.
- 향후 연구 방향:
- 새로운 noising function 개발: Task-specific noising function 탐색.
결론:
- BART는 다양한 NLP tasks에 효과적인 pre-training 모델.
- Noising function 유연성을 통해 광범위한 task에 적용 가능.
- Text infilling과 sentence permutation을 결합한 noising function이 효과적임을 확인.
참고:
- BART는 discriminative & generative tasks 모두에서 높은 성능을 보이는 범용적인 모델.
- 향후 연구를 통해 BART의 성능을 더욱 향상시킬 수 있을 것으로 기대.

