

AI바라기의 인공지능
LLM / VLM : 논문리뷰 : A Survey on Hallucination in Large Vision-Language Models 본문
LLM / VLM : 논문리뷰 : A Survey on Hallucination in Large Vision-Language Models
AI바라기 2024. 8. 27. 19:19Abstract
최근 Large Vision-Language Models (LVLMs)의 발전은 실제 적용 가능성으로 인해 AI 분야에서 점점 더 많은 관심을 받고 있습니다. 하지만, "hallucination" 또는 더 구체적으로 말하면, 실제 시각적 콘텐츠와 그에 상응하는 텍스트 생성 사이의 불일치는 LVLMs 활용에 있어 상당한 어려움을 야기합니다. 이 포괄적인 조사에서는, LVLMs 관련 hallucinations를 분석하여 개요를 정립하고 향후 완화 노력을 촉진하고자 합니다.
먼저, LVLMs에서 hallucinations의 개념을 명확히 하고 다양한 hallucination 증상을 제시하며 LVLM hallucinations에 내재된 고유한 문제들을 강조합니다. 이어서 LVLMs에 특화된 hallucinations를 평가하기 위한 벤치마크 및 방법론을 설명합니다. 또한, 훈련 데이터 및 모델 구성 요소에 대한 통찰을 포함하여 이러한 hallucinations의 근본 원인을 조사합니다. hallucinations 완화를 위한 기존 방법들도 비판적으로 검토합니다. 마지막으로, LVLMs 내 hallucinations와 관련된 미해결 문제 및 향후 방향을 논의하며 본 조사를 마무리합니다.
Introduction
인공지능 분야가 급속도로 발전하는 가운데, GPT-4, LLaMA, LLaMA2와 같은 large language models (LLMs)는 natural language understanding (NLU) 및 generation (NLG) 분야에서 놀라운 발전을 이루었습니다. vision-language tasks를 위해 LLMs의 NLU 및 NLG 기능을 활용하는 일반적인 접근 방식은 시각적 특징을 LLMs에 추가 입력으로 삽입하고 텍스트 특징과 정렬하는 것입니다. 이 방법은 MiniGPT-4, LLaVA, LLaVA-1.5와 같은 여러 large vision-language models (LVLMs)에 적용되었습니다. 기존 LVLMs가 보여주는 유망한 결과에도 불구하고, 무시할 수 없는 문제, 즉 hallucination이 실제 적용을 방해하고 있습니다. LVLM에서 hallucination은 이미지의 실제 내용과 생성된 텍스트 내용 사이의 불일치를 나타내며, large language models에서 발생하는 텍스트 hallucination과 유사합니다.
기존 연구에서는 image captioning 모델의 hallucination 문제를 다루었으며, 특히 이미지에 묘사된 객체가 모델이 생성한 텍스트에 의해 정확하게 설명되는지 여부, 즉 "객체의 존재"에 초점을 맞추었습니다. 폐쇄된 도메인 내에서 훈련된 image captioning 모델과 달리 LVLMs는 LLMs의 강력한 이해력과 표현 능력을 활용하여 더욱 상세하고 유창한 설명을 생성합니다. 그러나 이러한 향상된 능력은 hallucination을 다양화하고 잠재적으로 악화시킬 수 있으며, 이는 객체의 존재에 국한되지 않고 속성 및 관계 오류와 같은 설명 오류에서도 나타납니다. 본 연구에서는 이미지가 전달하는 의미 내용과 모델이 생성한 텍스트 내용 사이의 모든 불일치를 나타내는 visual hallucinations에 중점을 둡니다.

Figure 1: LVLMs에서의 Hallucination 예시. Hallucination 증상은 판단 및 설명과 같은 다양한 vision-language tasks의 결함 또는 objects, attributes 및 relations와 같은 다양한 visual semantics에서의 사실적 오류로 나타날 수 있습니다.
LVLM에서 Hallucination 및 그 원인
LVLMs에서 hallucination 증상은 다면적입니다. 인지적 관점에서 hallucination은 true/false 판단 오류 및 시각 정보 설명의 부정확성으로 나타날 수 있습니다. 예를 들어, 그림 1의 첫 번째 예에서 볼 수 있듯이, 모델은 "이미지에 고양이가 있습니까?" 및 "이미지에 새가 네 마리 있습니까?"와 같은 질문에 잘못 응답하여 사실 판단에 결함이 있음을 보여줍니다. 또한 두 번째 예에서는 생성된 설명과 시각적 사실 사이의 불일치를 보여줍니다. 한편, 시각적 의미론 관점에서는 객체, 속성 및 관계에 대한 hallucination이라는 3가지 분류법을 제공합니다. 예를 들어, 모델은 이미지에 "노트북" 및 "작은 개"와 같은 존재하지 않는 객체를 생성하고, 남자를 "장발"이라고 설명하는 등 잘못된 속성 설명을 제공하며, 자전거가 남자 "앞에" 있다고 주장하는 등 객체 간의 관계에 대해 부정확한 주장을 합니다. 현재 방법은 모델의 인지적 성능을 기반으로 LVLMs에서 이러한 hallucination을 평가하며, 주로 hallucination이 없는 생성 및 hallucination 식별이라는 두 가지 주요 측면에 중점을 둡니다. 전자는 모델의 응답에서 hallucination 요소를 자세히 분석하고 그 비율을 정량화하는 것을 포함합니다. 반면 후자는 응답에 hallucination 콘텐츠가 포함되어 있는지 여부에 대한 이진 판단만 필요합니다. 이러한 접근 방식은 섹션 3에서 자세히 논의됩니다.
LLMs에서 hallucination의 원인에 대해서는 광범위하게 논의되었지만, LVLMs의 시각적 modality는 이러한 발생을 분석하는 데 있어 고유한 과제를 제시합니다. 본 연구에서는 훈련 데이터 및 모델 특성에 중점을 두고 LVLMs의 hallucination에 대한 철저한 분석을 수행합니다. 분석 결과 LVLMs의 hallucination은 LLMs의 생성적 특성뿐만 아니라 편향된 훈련 데이터, vision encoders가 이미지를 정확하게 grounding하지 못하는 문제, 서로 다른 modality 간의 불일치, 불충분한 context attention 및 기타 여러 요인에 의해 발생하는 것으로 나타났습니다. 이어서 기존 hallucination 완화 방법에 대한 포괄적인 개요를 제공합니다. 원인에 따라 현재 완화 접근 방식은 주로 훈련 데이터 최적화, LVLMs 내 다양한 모듈 개선 및 생성된 출력의 후처리에 중점을 둡니다. 이러한 방법은 hallucination 발생을 줄여 더욱 충실한 응답을 생성하는 데 사용됩니다. 마지막으로 LVLMs에서 hallucination 연구를 발전시키기 위한 몇 가지 중요한 방향을 제시합니다.
요약하면, 본 연구는 LVLMs 개발에 대한 통찰력을 제공하고 LVLM hallucination과 관련된 기회와 과제를 탐구하는 것을 목표로 합니다. 이러한 탐구는 현재 LVLMs의 한계를 이해하는 데 도움이 될 뿐만 아니라 향후 연구 및 보다 안정적이고 효율적인 LVLMs 개발을 위한 중요한 지침을 제공합니다.
LVLMs: VLPMs의 진화 및 아키텍처
LVLMs는 이전 Vision-Language Pretrained Models (VLPMs)에서 진화한 모델입니다. LVLM 아키텍처는 일반적으로 visual encoder, modality connection module 및 LLM이라는 세 가지 구성 요소로 이루어집니다. visual encoder는 종종 CLIP vision encoder를 변형한 것으로, 입력 이미지를 visual tokens으로 변환합니다. connection module은 visual tokens를 LLM의 word embedding space에 맞춰 LLM이 시각 정보를 처리할 수 있도록 합니다. modality alignment를 위한 다양한 방법, 즉 cross-attention, adapters, Q-Formers 및 linear layers 또는 multi-layer perceptrons (MLP)와 같은 더 간단한 구조가 있습니다. LLM은 LVLMs 내에서 중앙 처리 장치처럼 기능하며, 정렬된 시각 및 텍스트 정보를 수신한 후 이 정보를 종합하여 응답을 생성합니다.
LVLMs 훈련에는 두 가지 핵심 단계가 포함됩니다.
(1) pretraining 단계에서는 LVLMs가 정렬된 image-text 쌍으로부터 vision-language knowledge를 습득하고,
(2) instruction-tuning 단계에서는 LVLMs가 다양한 task dataset을 사용하여 인간의 지시를 따르는 방법을 학습합니다.
이러한 단계를 거친 후 LVLMs는 시각 및 텍스트 데이터를 효율적으로 처리하고 해석하여 Visual Question Answering (VQA)과 같은 복합 multimodal tasks에서 개념에 대해 추론할 수 있습니다.
Hallucination in the Era of LVLM
2.1 Large Vision-Language Models
LVLMs는 시각 및 텍스트 데이터를 처리하여 vision 및 natural language 모두와 관련된 복합적인 tasks를 해결하는 고급 multimodal 모델입니다. LLMs의 기능을 통합한 LVLMs는 이전 Vision-Language Pretrained Models (VLPMs)에서 진화했습니다.
LVLM architectures는 일반적으로 세 가지 구성 요소, 즉 visual encoder, modality connection module 및 LLM으로 구성됩니다. visual encoder는 종종 CLIP vision encoder의 변형으로, 입력 이미지를 visual tokens으로 변환합니다. connection module은 visual tokens를 LLM의 word embedding space에 정렬하여 LLM이 시각 정보를 처리할 수 있도록 설계되었습니다. modality alignment를 위한 다양한 방법, 즉 cross-attention, adapters, Q-Formers 및 linear layers 또는 multi-layer perceptrons (MLP)와 같은 더 간단한 구조가 있습니다. LLM은 LVLMs 내에서 중앙 처리 장치처럼 기능하며, 정렬된 시각 및 텍스트 정보를 수신한 후 이 정보를 종합하여 응답을 생성합니다.
LVLMs의 훈련에는 두 가지 핵심 단계가 포함됩니다. (1) pretraining 단계에서는 LVLMs가 정렬된 image-text 쌍으로부터 vision-language knowledge를 습득하고, (2) instruction-tuning 단계에서는 LVLMs가 다양한 task dataset을 사용하여 인간의 지시를 따르는 방법을 학습합니다. 이러한 단계를 거친 후 LVLMs는 시각 및 텍스트 데이터를 효율적으로 처리하고 해석하여 Visual Question Answering (VQA)과 같은 복합 multimodal tasks에서 개념에 대해 추론할 수 있습니다.
2.2 Hallucination in LVLMs
LVLMs에서 hallucination은 시각적 입력('사실'로 간주)과 LVLM의 텍스트 출력 사이의 모순을 의미합니다. vision-language tasks의 관점에서 LVLM hallucination 증상은 판단 또는 설명의 결함으로 해석될 수 있습니다.
judgement hallucination은 사용자의 질의 또는 진술에 대한 모델의 응답이 실제 시각 데이터와 일치하지 않을 때 발생합니다. 예를 들어 그림 1에서 볼 수 있듯이, 새 세 마리가 묘사된 이미지를 제시하고 그림에 고양이가 있는지 질문했을 때 모델은 "예"라고 잘못 확인합니다. 반면에 description hallucination은 시각 정보를 충실하게 묘사하지 못하는 것을 의미합니다. 그림 1의 아래 부분에서 예시된 것처럼 모델은 남자의 머리카락, 컵의 수량 및 색상, 자전거의 위치를 부정확하게 설명하고 노트북 및 개와 같은 존재하지 않는 물체를 만들어냅니다.
의미론적 관점에서 이러한 불일치는 존재하지 않는 객체를 주장하거나, 객체 속성을 잘못 설명하거나, 객체 관계를 부정확하게 설명하는 것으로 특징지을 수 있으며, 각각 다른 색상으로 강조 표시되어 있습니다.
2.3 Unique Challenges regarding Hallucination in LVLMs
LVLMs는 visual 및 language modules를 모두 통합하여 vision-language tasks를 처리합니다. 그러나 이러한 통합은 hallucination detection, causal inference 및 mitigation methods에 있어 고유한 문제를 야기합니다.
Hallucination Detection의 어려움 LVLM의 multimodal 특성은 hallucination detection을 어렵게 만듭니다. LVLM Hallucinations는 object, attribute 및 relation을 포함하되 이에 국한되지 않는 다양한 semantic dimensions에 걸쳐 나타날 수 있습니다. 이러한 hallucinations를 종합적으로 탐지하려면 모델은 natural language understanding뿐만 아니라 fine-grained visual annotations를 사용하고 생성된 텍스트와 정확하게 정렬해야 합니다.
얽혀 있는 원인 LVLMs에서 hallucination의 원인은 종종 다면적입니다. 한편으로는 misinformation, biases 및 knowledge boundary limits와 같은 LLMs 및 LVLMs 모두가 공유하는 데이터 관련 문제가 있습니다. 그러나 LVLMs는 시각 데이터 통합으로 인해 고유한 문제를 겪습니다. 예를 들어, 불분명하거나 왜곡된 이미지와 같은 visual uncertainty는 LVLMs에서 language priors 및 statistical biases를 악화시켜 더 심각한 hallucinations를 초래할 수 있습니다.
복합적인 Mitigation Methods LLM-targeted hallucination mitigation methods, 즉 data quality enhancement, encoding optimization 및 aligning with human preferences를 조정하는 것 외에도, LVLM-specific methods에는 visual representations 개선 및 multi-modal alignment 개선도 포함됩니다. 예를 들어, visual resolution을 높이면 hallucinations를 효과적으로 줄일 수 있다는 제안이 있습니다. 그럼에도 불구하고 방대한 데이터로 high-resolution visual encoders를 훈련하는 것은 리소스를 많이 요구할 수 있습니다. 따라서 visual representations를 보강하기 위한 보다 비용 효율적인 전략을 조사하는 것이 필수적입니다. 또한 visual tokens과 textual tokens 사이의 큰 차이는 vision-language token alignment를 개선하면 잠재적으로 hallucinations 발생률을 낮출 수 있음을 시사합니다.
Evaluation Methods and Benchmarks
LVLM에서 hallucination의 개념을 확립한 후, 기존 LVLM hallucination 평가 방법 및 벤치마크를 살펴보겠습니다. 그림 1에서 언급된 description 및 judgement tasks에서의 hallucination 증상에 따라 현재 평가 방법은 다음 두 가지 주요 접근 방식으로 분류할 수 있습니다.
(1) hallucination이 없는 콘텐츠 생성 능력 평가 및
(2) hallucination 식별 능력 평가 (그림 2 참조).
마찬가지로 벤치마크 또한 평가 tasks를 기반으로 discriminative 및 generative 벤치마크로 분류할 수 있습니다 (표 1 참조).
3.1 Evaluation on Non-Hallucinatory Generation
Non-hallucinatory generation 평가는 출력에서 hallucinated content의 비율을 측정하는 것입니다. 현재 주로 두 가지 유형, 즉 handcrafted pipeline 및 model-based end-to-end methods가 있습니다.
Handcrafted Pipeline Methods Handcrafted pipeline methods는 구체적이고 명확한 목표를 가진 여러 단계를 수동으로 설계하여 강력한 interpretability를 특징으로 합니다. CHAIR는 모델 생성 및 ground-truth captions 간의 객체 차이를 정량화하여 image captioning에서 object hallucinations를 평가하는 것을 목표로 합니다. 그러나 이러한 기존 방법은 LVLMs의 방대한 object categories를 처리하는 데 어려움을 겪습니다. 이를 해결하기 위해 CCEval은 CHAIR를 적용하기 전에 GPT-4 기반 object alignment module을 사용합니다. FAITHSCORE는 free-form 모델 응답의 faithfulness를 평가하기 위한 reference-free 및 fine-grained 평가 방법을 제공하며, descriptive sub-sentences 식별, atomic facts 추출 및 추출된 facts를 해당 입력 이미지와 비교하는 과정을 포함합니다.
Model-based End-to-End Methods End-to-end methods는 응답 점수 매기기 또는 응답에서 hallucinations 존재 여부 확인과 같은 LVLMs의 응답을 평가하여 LVLMs의 성능을 직접 평가합니다. 기존 end-to-end 평가 방법은 크게 두 가지 유형으로 분류할 수 있습니다.
첫 번째 유형은 LLM-based evaluation으로, 고급 LLM (예: GPT-4)을 구현하여 hallucination을 기반으로 LVLM 생성 콘텐츠를 평가합니다. 이러한 방법은 LLM의 강력한 natural language understanding 및 processing capabilities를 활용합니다. visual information (예: dense captions 및 object bounding boxes), 사용자 지시 및 모델 응답을 입력으로 통합하여 LLM이 이러한 응답을 평가하고 점수를 매기도록 합니다.
두 번째 유형은 hallucination data driven model evaluation으로, hallucinations를 탐지하기 위해 fine-tuning 모델에 레이블이 지정된 hallucination datasets를 생성합니다. [Gunjal et al., 2023]은 주석이 달린 LVLM image descriptions를 사용하여 M-HalDetect dataset을 생성하고 hallucination 식별을 위해 dataset에서 InstructBLIP 모델을 fine-tune합니다.
마찬가지로 [Wang et al., 2023c]는 ChatGPT에서 생성된 hallucinatory responses dataset을 컴파일한 다음 LoRA를 사용하여 이 dataset에서 LLaMA 모델을 fine-tune하여 hallucinatory responses와 non-hallucinatory responses를 구별합니다.
3.2 Evaluation on Hallucination Discrimination
Hallucination discrimination 평가 접근 방식은 LVLMs의 hallucination discrimination 능력을 평가하는 것을 목표로 합니다. 이 접근 방식을 따르는 방법은 일반적으로 question-answering 형식을 채택하여, 제공된 입력 이미지의 내용과 일치하거나 상충되는 설명으로 구성된 질문을 LVLMs에 제시하고 모델의 응답을 평가합니다. POPE는 "이미지에 사람이 있습니까?"와 같은 이미지 내 객체 존재에 대한 binary (Yes-or-No) 질문을 설계하여 LVLMs의 hallucination discrimination 능력을 평가합니다. 질문에서 묻는 객체는 random (무작위로 없는 객체 선택), popular (dataset에서 가장 빈번하지만 현재 이미지에는 없는 객체 선택) 및 adversarial (존재하는 객체와 자주 함께 발생하는 없는 객체 선택)이라는 세 가지 뚜렷한 sampling strategies 하에 선택됩니다. CIEM은 POPE와 유사하지만 ChatGPT를 프롬프트하여 객체 선택을 자동화합니다. NOPE는 시각적 질의에서 객체의 부재를 식별하는 LVLMs의 능력을 평가하도록 설계된 또 다른 VQA 기반 방법이며, 정답은 부정적인 진술입니다.
3.3 Evaluation Benchmarks
일반적인 LVLM 기능을 평가하는 표준 LVLM 벤치마크와 달리, LVLM hallucination 벤치마크는 특히 non-hallucinatory generation 또는 hallucination discrimination을 목표로 합니다. 많은 벤치마크가 평가 방법과 함께 제안되었습니다. 표 1은 대표적인 벤치마크를 종합적으로 보여줍니다. 이러한 벤치마크는 평가 접근 방식 유형, 즉 Discriminative (Dis) 또는 Generative (Gen)에 따라 분류됩니다.
Discriminative Benchmarks POPE, NOPE 및 CIEM은 discriminative 벤치마크이며, 해당 dataset 크기는 각각 3000, 17983 및 72941입니다. 이 세 가지 벤치마크는 모두 object hallucinations에만 초점을 맞추고 평가 metric으로 accuracy를 채택하며, 이는 이미지에 객체가 있는지 질문하고 모델 응답을 ground-truth 답변과 비교하여 얻습니다.
Generative Benchmarks 표 1에 설명된 대로 현재 연구는 discriminative 벤치마크보다 generative 벤치마크를 강조합니다. discriminative 벤치마크는 주로 object 수준에서 hallucinations를 평가하는 반면, generative 벤치마크는 attribute 및 relation hallucinations를 포함하여 더 넓은 범위의 hallucinations를 평가합니다. 특히 AMBER는 generative 및 discriminative tasks를 모두 통합하는 포괄적인 벤치마크로 두드러집니다. 또한 generative 벤치마크에 사용되는 metric은 discriminative 벤치마크에서 accuracy metric에 의존하는 것과 달리 더 복잡하고 다양한 경향이 있음을 알 수 있습니다. 이는 주로 모델 출력을 ground-truth 답변과 비교하는 discriminative methods와 달리, generative 평가 방법은 LVLMs에서 생성된 응답을 분석하기 위해 특정 hallucination 범주를 대상으로 하는 맞춤형 metric이 필요하기 때문일 것입니다.
Causes of LVLM Hallucinations
LVLMs에서 hallucinations는 다양한 요인으로 인해 발생할 수 있습니다. 그림 3에서 묘사된 것처럼 LVLM pipeline에 따라 이러한 원인은 다음과 같은 측면으로 분류할 수 있습니다.
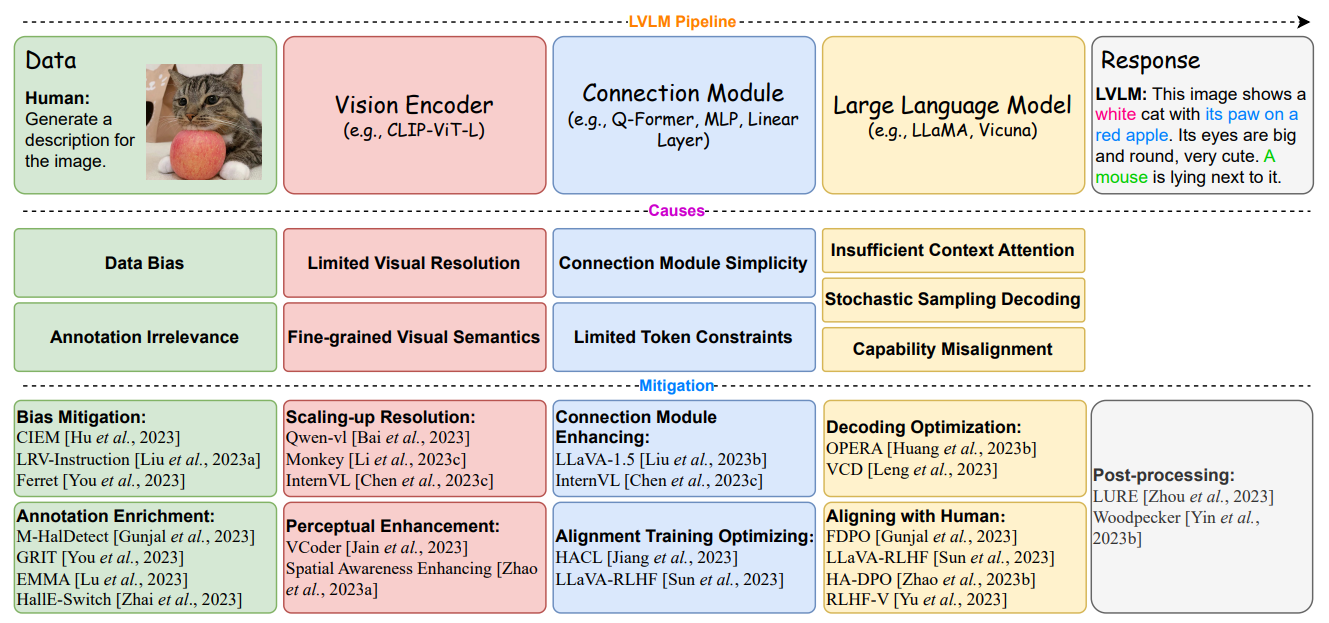
그림 3: LVLMs에서 환각 현상의 원인 및 완화 방법
4.1 Hallucinations from Data
훈련 데이터의 품질은 훈련 효율성 및 모델 성능에 큰 영향을 미칩니다. 그러나 기존 LVLM 훈련 데이터는 몇 가지 품질 문제로 인해 특정 유형의 hallucinations를 유발합니다.
Data Bias 데이터 편향의 한 가지 주목할 만한 문제는 기존 훈련 데이터에서 distribution imbalance가 존재한다는 것입니다. 특히 대부분의 답변이 "예"인 factual judgment QA 쌍에서 그렇습니다. 이러한 편향된 데이터로 훈련된 LVLMs는 잘못되거나 오해의 소지가 있는 프롬프트에도 "예"라고 일관되게 답변하고 설명을 제공하는 경향이 있습니다. 또 다른 문제는 data homogeneity로, 다양한 환경에서 시각 정보를 이해하고 지시를 실행하는 모델의 능력을 저해합니다. 예를 들어, MiniGPT-4는 다양한 instruction learning이 부족하기 때문에 사용자가 제기하는 특정 질문에 관계없이 이미지를 설명할 수만 있습니다. 마찬가지로 LLaVA는 훈련된 시각 정보의 다양성이 제한되어 있어 local visual relations를 정확하게 설명하는 데 어려움을 겪습니다.
Annotation Irrelevance 많은 양의 instruction data는 주로 LLMs를 사용하여 image-caption 및 detection data에서 합성됩니다. 그러나 이러한 generative models의 불안정성으로 인해 이 접근 방식은 annotation relevance 문제에 직면합니다. 즉, 생성된 긴 instructions에는 종종 이미지에 묘사된 fine-grained content에 해당하지 않을 수 있는 objects, attributes 및 relationships가 포함됩니다. 이러한 데이터로 훈련하는 것도 hallucinations를 촉진합니다.
4.2 Hallucinations from Vision Encoder
LVLMs에서 널리 채택되는 vision encoders는 CLIP에서 파생되었으며, contrastive learning을 통해 시각적 및 텍스트적 특징을 동일한 공간에 매핑합니다. CLIP은 다양한 visual understanding tasks에서 탁월한 성능을 달성하지만, 제한된 visual resolution 및 fine-grained visual semantics와 같이 시각 정보를 완전히 표현하는 데에는 한계가 있습니다.
Limited Visual Resolution 더 높은 이미지 해상도는 visual encoder가 객체 인식에서 더 정확하고 더 많은 시각적 세부 정보를 인지할 수 있도록 하여 hallucinations를 완화할 수 있습니다. 그러나 더 넓은 범위의 이미지 해상도를 처리하는 것은 계산적으로 까다롭기 때문에 기존 모델은 일반적으로 더 작은 이미지 해상도(예: LLaVA의 경우 224×224, LLaVA-1.5의 경우 336×336 픽셀)를 사용합니다.
Fine-grained Visual Semantics CLIP은 주로 salient objects에만 초점을 맞춘 contrastive learning을 통해 시각적 콘텐츠와 word embeddings를 정렬하며, 이미지의 fine-grained 측면을 포착하지 못하여 background description, object counting 및 object relation과 같은 hallucinations를 초래합니다.
4.3 Hallucinations from Modality Aligning
connection module은 visual features를 LLM의 word embedding space에 투영하여 visual modality와 textual modality를 정렬합니다. 따라서 misalignment는 hallucination 생성의 주요 요인이 될 수 있습니다. 또한, MiniGPT-4 및 LLaVA와 같은 고급 LVLMs에서도 visual features와 textual features 사이의 차이가 상당하며 hallucinations를 유발하는 것으로 밝혀졌습니다. connection module의 단순성 및 tokens의 제약은 두 가지 주요 원인입니다.
Connection Module Simplicity linear layers와 같은 단순한 구조는 일반적으로 visual modality와 textual modality를 정렬하기 위한 connection modules로 사용됩니다. 비용 효율적이지만, connection modules의 단순성은 포괄적인 multimodal connection을 방해하여 hallucinations의 위험을 증가시킵니다.
Limited Token Constraints Q-Former는 BLIP2, InstructBLIP 및 MiniGPT-4와 같은 LVLMs에서 널리 사용되는 multimodal alignment module입니다. 다양한 목표를 가지고 훈련되어 미리 정해진 수의 random initialized tokens (예: 32)를 텍스트와 정렬된 visual features로 인코딩합니다. 그러나 이러한 tokens의 제한된 수량으로 인해 정렬 프로세스 중에 이미지에 있는 모든 정보를 인코딩할 수 없으며, 결과적으로 발생하는 정보 손실은 hallucinations의 위험을 높입니다.
4.4 Hallucinations from LLM
LLMs는 LVLMs의 아키텍처에서 중추적인 역할을 하며, 복잡한 multimodal tasks를 처리하는 LVLMs의 능력을 크게 향상시킵니다. 그러나 이러한 통합은 LLMs의 내재적인 hallucination 문제를 LVLMs에도 도입합니다. 많은 연구 문헌에서 LLMs에서 hallucination에 기여하는 다양한 요인을 탐구했습니다. 이 섹션에서는 vision-language 범위 내에서 LLMs에서 발생하는 잠재적인 hallucination 원인을 간략하게 요약합니다.
Insufficient Context Attention 불충분한 context attention은 디코딩 과정에서 모델이 context의 일부 정보에만 집중하는 현상입니다. 이 현상에는 입력 시각 정보를 무시하면서 생성된 콘텐츠의 현재 부분에 과도하게 집중하는 것, 유창하지만 부정확한 콘텐츠를 생성하기 위해 언어 패턴을 우선시하는 것, 생성된 콘텐츠의 일부 요약 tokens에 집중하여 날조 및 환각 콘텐츠를 생성하는 것이 포함됩니다.
Stochastic Sampling Decoding Stochastic sampling은 디코딩 프로세스에 무작위성을 도입하며 LLMs에서 일반적으로 사용되는 디코딩 전략입니다. 높은 가능성을 가진 시퀀스와 관련된 저품질 텍스트 생성을 방지하고 생성된 콘텐츠를 풍부하게 하는 데 도움이 됩니다. 그러나 모델에 무작위성을 통합하면 hallucinations의 위험도 증폭됩니다.
Capability Misalignment LLMs에서 capability misalignment는 사전 훈련 단계에서 확립된 모델의 내재적 능력과 instruction tuning 중에 부과된 확장된 요구 사항 사이의 불일치입니다. 이러한 불일치는 LLMs가 확립된 지식 한계를 넘어서는 응답을 생성하여 환각 콘텐츠의 가능성을 높입니다.
Mitigation of LVLM Hallucination
LVLMs에서 hallucinations를 완화하기 위한 다양한 방법이 제안되었습니다. 그림 3에 묘사된 것처럼 이러한 방법들은 확인된 원인을 해결하도록 맞춤화되어 있습니다. 이 섹션에서는 다음 관점에서 자세히 설명합니다.
5.1 Mitigation for Data
훈련 데이터를 최적화하는 것은 hallucinations를 완화하는 직접적이고 효과적인 방법입니다. 현재 데이터셋에서 탐구된 결함과 관련하여 다음 두 가지 관점에서 문제를 해결하기 위한 몇 가지 조치가 취해지고 있습니다.
Bias Mitigation
훈련 데이터에서 positive 및 negative samples의 불균형을 고려하여, CIEM은 off-shelf LLMs를 활용하여 annotated image-text datasets에서 contrastive question-answer 쌍을 생성합니다. 그런 다음 이러한 쌍은 Contrastive Instruction Tuning (CIT)에 활용됩니다. LRV-Instruction은 400,000개의 시각적 instructions으로 구성된 크고 다양한 데이터셋을 제안합니다. 이 데이터셋에는 positive visual instructions뿐만 아니라 세 가지 다른 semantic levels에 대한 negative visual instructions도 포함됩니다. 또한 Ferret은 fine-grained 방식으로 탐구하여 원래 categories, attributes 또는 quantity information을 유사한 가짜 정보로 대체하여 95,000개의 negative samples를 마이닝할 것을 제안합니다. 이 방법은 모델의 robustness를 효과적으로 향상시킵니다.
Annotation Enrichment
풍부하게 annotated된 데이터셋을 구축하면 LVLMs가 시각적 콘텐츠를 정확하게 추출하고 modality를 포괄적으로 정렬하도록 감독하여 hallucination을 완화하는 데 도움이 됩니다. 주목할 만한 데이터셋 중 하나는 M-HalDetect입니다. COCO에서 가져온 4,000개의 image-description 쌍으로 구성되며 object existence, relative positions 및 attributes에 레이블이 지정되어 있습니다. 또 다른 가치 있는 데이터셋은 GRIT입니다. GRIT는 hierarchical spatial knowledge에 대한 refer-and-ground instructions를 통해 110만 개의 샘플을 제공합니다. 또한 RAM-system grounded objects가 있는 데이터셋과 RAM 또는 LLMs에서 생성된 objects가 있는 데이터셋이라는 두 가지 데이터셋을 개발했습니다. 마지막으로 multi-round conversations, vision-prompted recognition 및 fact-checking을 포괄하는 180,000개의 fine-grained instruction samples를 생성했습니다.
5.2 Mitigation for Vision Encoder
Scaling-up Vision Resolution 이미지 해상도를 224 × 224에서 448 × 448로 점진적으로 확대하는 것이 효과적임을 보여주었습니다. MONKEY는 high-resolution 이미지를 vision encoder와 크기가 일치하는 패치로 분할하여 처리하고, 패치에서 추출된 local features는 LLM에서 처리됩니다. InternVL은 vision encoder를 60억 개의 파라미터로 확장하여 1,664에서 6,144 픽셀 범위의 너비를 가진 이미지를 처리할 수 있습니다. 그러나 이 접근 방식은 large-scale 데이터를 사용한 pretraining에 많은 리소스가 필요합니다.
Perceptual Enhancement 대부분의 기존 LVLMs는 주로 salient objects에만 초점을 맞추고 일부 시각적 단서를 불가피하게 생략하는 CLIP의 ViT를 vision encoder로 사용합니다. object-level perceptual capability를 향상시키기 위해 VCoder는 추가 vision encoders를 통해 segmentation map, depth map 또는 둘 다와 같은 추가 perception modalities를 control inputs로 사용합니다. spatial awareness capability를 향상시키기 위해 추가적인 pre-trained 모델을 도입하여 spatial position information 및 scene graph details를 획득한 다음 이를 사용하여 LVLMs가 사용자 질의를 처리하도록 안내하는 것이 좋습니다.
5.3 Connection Module을 위한 완화 방법
Connection Module Enhancing
섹션 4.3에서 논의된 바와 같이, connection module의 제한된 용량은 완벽한 modality alignment를 방해하여 hallucination 위험을 증가시킵니다. vision modality와 language modality를 더 잘 정렬하기 위해 연구자들은 최근 더욱 강력한 connection modules를 개발했습니다. 예를 들어, LLaVA-1.5는 LLaVA의 connection module을 single linear layer에서 MLP로 업그레이드하여 향상시킵니다. 또한 LLaMA2를 활용하여 QLLaMA를 구축하며, 이는 visual features를 텍스트에 정렬하는 데 있어 Q-Former를 훨씬 능가합니다.
Alignment Training Optimizing
alignment training 프로세스를 강화하는 것은 modality alignment를 향상시키고 hallucinations 위험을 줄이는 효과적인 방법입니다. LVLMs에서 visual tokens과 textual tokens 사이에 상당한 차이가 있음을 관찰했습니다. visual tokens과 textual tokens를 더 가깝게 만들기 위한 새로운 learning objectives를 명시적으로 추가함으로써 hallucinations를 줄일 수 있습니다. 한편, Reinforcement Learning from Human Feedback (RLHF)를 사용하여 서로 다른 modalities를 정렬하여 hallucination 감소를 달성합니다.
5.4 Mitigation for LLM
Decoding Optimization
불충분한 context attention에 대응하여, 일부 최근 연구에서는 디코딩 중에 모델이 적절한 context에 집중할 수 있도록 하여 hallucinations를 완화하려고 시도합니다. LVLMs가 몇 개의 summary tokens에 과도하게 집중하고 image tokens를 무시하여 hallucinations를 생성할 수 있다는 점을 발견했습니다. hallucinations를 완화하기 위해, over-trusted candidates의 우선순위를 낮추는 가중치 scoring 시스템과 decision points를 재평가하기 위한 retrospection 메커니즘을 통해 beam search 프로세스를 수정하는 새로운 디코딩 전략인 OPERA를 개발했습니다. visual uncertainty와 statistical bias 및 language priors로 인해 발생하는 hallucinations에 미치는 영향에 중점을 두었습니다.
original 및 altered visuals의 출력을 대조하는 visual contrastive decoding 전략을 제안하여 모델이 language priors 및 statistical biases에 과도하게 의존하는 것을 수정하는 데 도움을 줍니다.
Aligning with Human Training
LVLMs를 인간의 선호도에 맞춰 훈련하면 모델 응답의 품질을 향상시킬 수 있습니다. 최근에는 non-hallucinatory responses가 선호되고 hallucinatory contents는 선호되지 않는 preference-aligned training에 초점을 맞춘 노력이 있습니다. LLaVA-RLHF는 RLHF를 사용하여 LVLMs를 훈련하여 인간의 선호도에 맞추는 선구적인 연구입니다. 먼저 reward model을 훈련하여 인간의 선호도를 반영합니다. 그런 다음 fact augmented RLHF 및 reward model을 적용하여 LVLMs를 인간의 선호도에 맞춥니다. 또 다른 범주의 방법은 RLHF와 같은 reward-model-based reinforcement learning 방법의 복잡성을 피하면서 인간의 선호도 데이터에서 직접 LLMs를 훈련하는 Direct Preference Optimization (DPO)를 기반으로 합니다. hallucinatory labelled training data를 생성한 후, 이 연구는 특히 HA-DPO 및 FDPO와 같은 DPO 변형을 제시하여 LVLMs를 훈련하여 인간과 더 잘 일치하고 non-hallucinatory responses를 생성합니다.
5.5 Mitigation via Post-processing
LVLMs의 모듈을 조작하는 것 외에도 추가 모듈 또는 작업을 통해 post-processing 또는 output editing을 통해 hallucinations를 완화할 수 있습니다. Post-processing methods는 시각 데이터, 사용자 지시 및 LVLM 응답을 입력으로 받아 hallucination이 없는 개선된 응답을 출력합니다.
최근에는 생성된 image descriptions에서 hallucinations를 줄이기 위해 두 가지 post-processing methods, 즉 LURE 및 Woodpecker가 도입되었습니다. LURE는 object hallucination의 원인에 대한 통찰력을 활용하여 MiniGPT-4를 기반으로 revisor model을 훈련시킵니다. Woodpecker는 훈련이 필요 없는 post-processing method로, 핵심 개념 추출, 질문 공식화, visual knowledge validation 적용, 구조화된 visual knowledge base 생성 및 knowledge base의 증거를 통합하고 부정확성을 수정하여 생성된 콘텐츠를 개선하는 5단계로 구성됩니다.
정리본 입니다.
1. 데이터 관련 원인과 완화 방법
- 원인: 데이터 편향 및 주석 부적합성
- 데이터 편향: 훈련 데이터의 불균형과 사실 판별 질문 쌍에서의 "예" 대답이 과다하게 포함된 경우.
- 주석 부적합성: 이미지의 세밀한 내용과 일치하지 않는 잘못된 주석이 포함된 경우.
- 완화 방법:
- 편향 완화: 부정적인 예시를 포함한 다양한 데이터셋 생성 및 대조 학습 기법 사용.
- 주석 강화: 더 풍부하고 정확한 주석이 포함된 데이터셋을 구축하여, 모델이 시각 정보를 정확하게 추출하고 정렬할 수 있도록 지도.
2. 비전 인코더 관련 원인과 완화 방법
- 원인: 제한된 시각 해상도 및 세밀한 시각 의미의 부족
- 제한된 시각 해상도: 저해상도 이미지 처리로 인해 시각 인코더가 객체 인식을 정확하게 수행하지 못하는 경우.
- 세밀한 시각 의미의 부족: 비전 인코더가 주로 두드러진 객체에만 집중하여 세밀한 시각적 요소를 놓치는 경우.
- 완화 방법:
- 해상도 확장: 이미지 해상도를 점진적으로 확대하여 비전 인코더의 객체 인식 정확도를 향상.
- 지각 향상: 객체 수준의 인식을 강화하기 위해 추가적인 지각 모달리티(예: 분할 맵, 깊이 맵)를 사용하는 방법.
3. 모달리티 정렬 관련 원인과 완화 방법
- 원인: 연결 모듈의 단순성과 제한된 토큰 제약
- 연결 모듈의 단순성: 간단한 구조의 연결 모듈이 시각적 특징과 텍스트 모달리티를 완벽하게 정렬하지 못하는 경우.
- 제한된 토큰 제약: 시각적 정보를 모두 인코딩하지 못하는 소수의 토큰 사용으로 인한 정보 손실.
- 완화 방법:
- 연결 모듈 강화: 더 복잡한 연결 모듈을 도입하여 모달리티 정렬을 개선.
- 정렬 학습 최적화: 시각적 토큰과 텍스트 토큰 간의 간극을 줄이기 위해 새로운 학습 목표를 추가하여 정렬을 강화.
4. 대형 언어 모델(LLM) 관련 원인과 완화 방법
- 원인: 불충분한 맥락 주의, 확률적 샘플링 디코딩, 능력 불일치
- 불충분한 맥락 주의: 모델이 생성 중 일부 정보에만 집중하고, 전체 맥락을 충분히 고려하지 못하는 경우.
- 확률적 샘플링 디코딩: 디코딩 과정에서 확률성을 도입하여 환각 위험을 증가시키는 경우.
- 능력 불일치: 모델의 기존 능력과 학습 후 요구 사항 간의 불일치로 인해 발생하는 환각.
- 완화 방법:
- 디코딩 최적화: OPERA와 같은 새로운 디코딩 전략을 사용하여 모델이 적절한 맥락에 집중하도록 유도.
- 사람과의 정렬 학습: 인간의 선호에 맞게 모델의 출력을 조정하는 방법으로 환각을 줄이고, 비환각적 응답을 선호하도록 모델을 훈련.
이와 같이, 각 원인에 대해 대응하는 완화 방법을 도입하여 LVLM의 환각 현상을 줄일 수 있습니다.
'논문리뷰' 카테고리의 다른 글
| Diffusion : 논문 리뷰 : Grid Diffusion Models for Text-to-Video Generation (0) | 2024.09.03 |
|---|---|
| LLM / VLM : 논문 리뷰 : Self-Taught Evaluators (7) | 2024.08.28 |
| LLM / VLM : 논문리뷰 : Building and better understanding vision-languagemodels: insights and future directions (1) | 2024.08.27 |
| LLM / VLM : 논문리뷰 : Matryoshka Multimodal Models (0) | 2024.08.26 |
| LLM / VLM : 논문리뷰 : Pixel Aligned Language Models (0) | 2024.08.26 |


