

AI바라기의 인공지능
VLM : 논문리뷰 : Scaling RL to Long Videos 본문
쉬운 설명
이 논문의 핵심 아이디어를 쉽게 비유하자면, AI에게 긴 영화 한 편을 보고 심층 분석 리포트를 쓰도록 가르치는 것과 같습니다.
기존 방식은 AI에게 영화를 통째로 계속 반복해서 보여주며(비효율적인 RL) 가르치려 하니, 시간이 너무 오래 걸리고 AI가 지쳐버리는(OOM) 문제가 있었습니다.
LongVILA-R1의 접근법은 다릅니다.
- 먼저 '족보'로 예습시키기 (CoT-SFT): AI에게 무작정 영화를 보여주기 전에, 먼저 줄거리, 인물 분석, 주요 사건의 인과관계가 잘 정리된 '핵심 요약본(족보)' (LongVideo-Reason 데이터셋)을 주고 학습시킵니다. 이걸로 AI는 기본적인 분석의 틀을 배웁니다.
- '초고효율 그룹 스터디'로 본학습하기 (MR-SP):
- 업무 분담 (Parallel Encoding): 영화(긴 비디오)를 4개의 파트로 나눠 4명의 학생(GPU)이 동시에 나눠서 봅니다.
- 노트 공유 및 재활용 (Embedding Reuse): 각자 본 파트의 내용을 요약한 노트를 공유해 합쳐서 완벽한 요약본(video embedding)을 만듭니다. 이후 토론(RL rollout)을 할 때는 매번 영화를 다시 보지 않고, 이 공유된 요약본만 계속 참고합니다.
이러한 '족보 예습'과 '초고효율 그룹 스터디' 방식을 통해 AI는 훨씬 빠르고 깊이 있게 긴 영화(비디오)를 이해하고 수준 높은 분석 리포트(reasoning)를 작성할 수 있게 된 것입니다.
LongVILA-R1: Scaling RL to Long Videos 학습 노트
용어 설명 (Glossary)
- VLM (Vision-Language Model): 이미지나 비디오와 같은 시각적 데이터와 텍스트를 함께 이해하고 처리하는 모델.
- RL (Reinforcement Learning): 강화학습. 모델이 특정 환경에서 보상(reward)을 최대화하는 행동을 학습하는 기계학습 패러다임.
- CoT-SFT (Chain-of-Thought Supervised Fine-Tuning): 모델이 정답에 도달하기까지의 사고 과정(Chain-of-Thought)을 포함한 데이터로 Supervised Fine-Tuning을 진행하는 것. 모델에게 논리적 추론 능력을 주입하는 단계.
- LongVILA-R1: 이 논문에서 제안하는 최종 모델의 이름. 긴 비디오에 대한 Reasoning 능력을 RL로 강화한 Vision-Language 모델.
- LongVideo-Reason: 이 논문에서 자체 구축한 52K 규모의 긴 비디오 reasoning QA 데이터셋.
- MR-SP (Multi-modal Reinforcement Sequence Parallelism): 이 논문의 핵심 기술. 긴 비디오 RL 학습의 병목 현상을 해결하기 위해 제안된 새로운 분산 학습 시스템.
- Rollout: RL에서 현재 policy 모델을 사용해 응답(response) 시퀀스를 생성하는 과정. 긴 비디오에서는 이 과정이 매우 비쌈.
- Prefilling: LLM에서 생성(generation)을 시작하기 전, 긴 입력 프롬프트(비디오+텍스트)를 병렬로 처리하여 key-value cache를 미리 계산하는 단계.
- GRPO (Group Relative Policy Optimization): 이 연구에서 사용한 특정 RL 알고리즘.
- vLLM engine: LLM 추론을 가속화하는 데 사용되는 고효율 오픈소스 라이브러리.
Purpose of the Paper
기존의 Vision-Language Models (VLMs)는 짧은 비디오나 이미지 인식에는 강점을 보이지만, 긴 비디오(수십 분 이상)에 담긴 복잡한 reasoning(추론)에는 한계를 보입니다. 이는 두 가지 주요 문제 때문입니다:
- 데이터 부족: 긴 비디오의 시간적, 공간적, 인과적, 서사적 관계를 추론하는 고품질의 reasoning 데이터셋이 절대적으로 부족합니다.
- 계산 비용: 긴 비디오에 Reinforcement Learning (RL)을 적용하는 것은 막대한 memory와 긴 rollout 시간으로 인해 계산적으로 거의 불가능에 가깝습니다.
이 논문은 이러한 한계를 극복하기 위해 "full-stack framework" 를 제안합니다. 즉, (1) 고품질의 대규모 Long-video reasoning 데이터셋을 직접 구축하고, (2) 이 데이터셋을 활용해 RL로 모델을 효과적으로 학습시킬 수 있는 (3) 새로운 분산 학습 시스템 (MR-SP) 을 개발하여, 긴 비디오에서도 복잡한 reasoning이 가능한 VLM을 만드는 것을 목표로 합니다.
Key Contributions & Novelty
이 논문의 핵심 기여와 독창성은 다음과 같이 요약할 수 있습니다.
- Contribution 1: LongVideo-Reason Dataset 구축
- 긴 비디오(18K개)에 대한 52K개의 고품질 Question-Reasoning-Answer 쌍을 포함하는 대규모 데이터셋을 구축했습니다.
- Novelty: 단순 QA가 아닌, Temporal, Goal/Purpose, Spatial, Plot/Narrative의 4가지 reasoning 유형으로 분류되고, Chain-of-Thought (CoT) 형식의 상세한 추론 과정까지 포함된 최초의 대규모 긴 비디오 reasoning 데이터셋이라는 점에서 독창적입니다.
- Contribution 2: 2-Stage Training Pipeline (CoT-SFT + RL)
- 1단계(Warm-up): CoT-SFT를 통해 모델에 기본적인 reasoning 능력과 instruction-following 능력을 주입합니다.
- 2단계(Scaling): RL(GRPO)을 통해 모델이 더 자유롭게 탐색하며 일반화된 reasoning 전략을 학습하도록 합니다.
- Novelty: 단순히 SFT나 RL을 개별적으로 적용한 것이 아니라, SFT로 reasoning의 기틀을 다지고 RL로 이를 확장 및 일반화하는 체계적인 2단계 접근법을 통해 학습 효율과 성능을 극대화했습니다.
- Contribution 3: MR-SP Training Infrastructure 개발
- 긴 비디오 RL의 병목을 해결하기 위한 Multi-modal Reinforcement Sequence Parallelism 시스템을 제안했습니다.
- Novelty: 이 시스템의 독창성은 두 가지 핵심 아이디어의 결합에 있습니다.
- Parallel Encoding & Embedding Reuse: 비디오 프레임을 여러 GPU에 분산시켜 병렬로 인코딩하고, 생성된 video embedding을 여러 RL rollout에 걸쳐 재사용하여 비디오 인코딩 비용을 획기적으로 줄입니다.
- Sequence Parallelism for Prefilling: RL의 policy/reference 모델 추론 시, 긴 시퀀스(비디오+텍스트)를 여러 GPU에 분산 처리(Sequence Parallelism)하여 OOM(Out-of-Memory) 문제를 해결하고 prefilling 속도를 높입니다. 이는 시스템 수준의 혁신입니다.
- Contribution 4: SOTA 성능의 LongVILA-R1 모델
- 위의 데이터셋과 학습 파이프라인, 시스템을 통해 학습된 LongVILA-R1 모델을 공개했습니다.
- Novelty: 오픈소스 모델 중 SOTA 성능을 달성했으며, 특정 reasoning 벤치마크에서는 Gemini-1.5-Pro와 대등한 성능을 보였습니다. 이는 제안된 프레임워크 전체의 효과성을 입증하는 결과입니다.
Experimental Highlights
- Training Efficiency (MR-SP 효과):
- MR-SP 시스템은 기존 RL 학습 방식 대비 최대 2.1배의 학습 속도 향상을 보였습니다 (512 프레임 기준).
- MR-SP 없이 OOM이 발생하던 1024 프레임 이상의 긴 비디오에서도 안정적으로 RL 학습을 가능하게 했습니다. (Figure 1 참고)
- Reasoning Benchmark Performance (LongVideo-Reason-eval):
- LongVILA-R1-7B는 평균 67.9%의 정확도를 기록하며, GPT-4o (60.7%), Video-R1-7B (62.7%)를 크게 앞섰고, Gemini-1.5-Pro (67.3%)와 대등한 성능을 달성했습니다.
- 특히, 복잡한 객체 추적이 요구되는 Spatial Reasoning에서 70.0% 라는 압도적인 점수를 기록해, dense frame 분석 능력의 우수성을 입증했습니다. (Table 2 참고)
- Scaling Performance (입력 프레임 증가에 따른 성능 변화):
- 입력 비디오 프레임 수가 16에서 512로 증가함에 따라, LongVILA-R1의 성능은 꾸준히 향상되었습니다. 반면, reasoning 학습을 거치지 않은 baseline 모델은 성능이 정체되거나 하락했습니다.
- 이는 LongVILA-R1이 더 긴 시각적 context를 효과적으로 활용해 reasoning 능력을 발휘함을 보여주는 강력한 증거입니다. (Figure 8 참고)
- Ablation Study:
- CoT-SFT 단계나 자체 구축한 LongVideo-Reason 데이터셋을 제외하고 학습했을 때 성능이 크게 하락함을 보여, 제안된 파이프라인의 각 구성요소가 최종 성능에 필수적임을 증명했습니다. (Table 4 참고)
Limitations and Future Work
- Limitations:
- 모호한 'Reasoning'의 정의: 'Reasoning'이라는 개념 자체가 아직 명확하게 정의되지 않아, 데이터셋 구축과 평가에 주관성이 개입될 여지가 있습니다. 이것이 중요한 이유는, 보다 객관적이고 신뢰도 높은 모델 평가를 어렵게 만들기 때문입니다.
- 여전히 존재하는 Frame 수의 한계: 제안된 시스템은 수백~수천 프레임을 처리하지만, 실제 영화나 장시간 CCTV 같은 "ultra-dense visual information"을 포함한 비디오를 처리하기에는 여전히 한계가 있습니다.
- Future Work:
- Reasoning에 대한 더 엄밀한 정의를 정립하고, 이를 기반으로 한 새로운 벤치마크를 개발하여 모델의 능력을 더 정교하게 측정해야 합니다.
- "ultra-dense" 비디오를 처리하기 위해, 시각 정보를 더 효율적으로 압축하고 학습하는 새로운 방법론을 연구하여 현재의 프레임 처리 한계를 극복해야 합니다.
Overall Summary
이 논문은 RL을 활용해 긴 비디오에 대한 VLM의 복잡한 reasoning 능력을 확장하는 **포괄적인 프레임워크 LongVILA-R1**을 제안합니다. 이를 위해, reasoning에 특화된 LongVideo-Reason 데이터셋을 구축하고, CoT-SFT와 RL을 결합한 2단계 학습 파이프라인을 적용했습니다. 특히, RL 학습의 극심한 계산 비용 문제를 해결하기 위해 핵심 기술인 MR-SP 시스템을 개발하여 학습 효율을 획기적으로 개선했습니다. 그 결과, LongVILA-R1 모델은 오픈소스 SOTA를 달성하며 긴 비디오 understanding 분야의 실질적인 진보를 이뤄냈고, 향후 Embodied AI나 Robotics 등 복잡한 시각적 이해가 필수적인 분야로의 확장 가능성을 열었습니다.
Abstract
우리는 reinforcement learning을 활용하여 vision-language models (VLMs)의 reasoning을 긴 동영상으로 확장하는 full-stack framework를 소개합니다. 우리는 긴 동영상 reasoning의 고유한 과제를 해결하기 위해 세 가지 중요한 구성 요소를 통합합니다: (1) 스포츠, 게임, 브이로그와 같은 다양한 domain에 걸쳐 고품질 reasoning annotation이 포함된 52K 개의 긴 동영상 QA 쌍으로 구성된 large-scale dataset인 LongVideo-Reason; (2) chain-of-thought supervised fine-tuning (CoT-SFT) 및 reinforcement learning (RL)으로 VLM을 확장하는 2단계 training pipeline; (3) 효율적인 rollout 및 prefilling을 위해 캐시된 video embeddings을 사용하여 long video에 맞춰진 vLLM 기반 engine과 sequence parallelism을 통합한 Multi-modal Reinforcement Sequence Parallelism (MR-SP)이라는 이름의 long video RL을 위한 training infrastructure.
실험에서 LongVILA-R1-7B는 VideoMME와 같은 long video QA benchmark에서 강력한 performance를 달성합니다. 또한 우리의 LongVideo-Reason-eval benchmark에서 temporal reasoning, goal and purpose reasoning, spatial reasoning, plot reasoning 전반에 걸쳐 Video-R1-7B를 능가하고 Gemini-1.5-Pro와 대등한 성능을 보입니다. 특히, 우리의 MR-SP system은 long video RL training에서 최대 2.1배의 속도 향상을 달성합니다. LongVILA-R1은 input video frames 수가 증가함에 따라 일관된 performance 향상을 보여줍니다. LongVILA-R1은 VLM에서 long video reasoning을 향한 확고한 발걸음을 내디뎠습니다.
또한, 우리는 다양한 modalities(video, text, audio), 다양한 models(VILA 및 Qwen 시리즈), 그리고 image 및 video generation models에 대한 RL training을 지원하는 training system을 공개합니다. 단일 A100 노드(8 GPUs)에서, 시간 길이의 동영상(예: 3,600 frames / 약 256k tokens)에 대한 RL training을 지원합니다. Code와 models은 https://github.com/NVlabs/Long-RL에서 확인할 수 있습니다.

1. Introduction
긴 동영상을 이해하려면 단순한 인식을 넘어서 temporal, spatial, goal-oriented, narrative 관점에서의 reasoning이 필요합니다. 그림 2에서 볼 수 있듯이, high-level 질문에 답하는 것은 종종 시간에 걸쳐 분포된 단서를 통합하고, 숨겨진 목표나 전략을 추론하며, 개체를 공간적으로 추적하고, 전개되는 줄거리를 이해하는 model의 능력에 달려 있습니다. 예를 들어, 축구 승부차기의 승자를 예측하는 것은 감정적 단서와 전술적 행동을 평가하는 것(temporal 및 goal reasoning)을 포함하며, 숨겨진 공의 최종 위치를 결정하는 것은 정밀한 spatial tracking을 필요로 합니다. 마찬가지로, 포커 플레이어의 결정을 평가하는 것은 표면적인 행동을 넘어서 암묵적인 전략을 해석하는 것(goal reasoning)을 요구하며, 캐릭터의 발전이나 경기 궤적을 이해하는 것은 plot reasoning의 필요성을 반영합니다. 이러한 예들은 reasoning이 단순한 인식을 넘어서는 긴 동영상 이해에 필수적임을 강조합니다.
긴 동영상 이해에서 reasoning의 명백한 중요성에도 불구하고, long-video VLM에서 이러한 기능을 활성화하는 것은 상당한 도전을 제기합니다. 첫째, 고품질의 long video reasoning datasets 수집은 본질적으로 어렵습니다. 구조화된 감독과 benchmarks가 쉽게 사용 가능한 수학이나 코드 reasoning과 같은 domain과 달리, long video reasoning은 복잡한 temporal dynamics, 목표, 공간 관계, 서사적 요소를 주석으로 다는 것을 필요로 하며, 이는 종종 몇 분 또는 몇 시간 분량의 영상에 걸쳐 이루어집니다. 이 과정은 노동 집약적이고 주관적이어서 large-scale dataset 구축을 느리고 비용이 많이 들게 만듭니다. 둘째, long videos를 위한 RL training framework는 어렵습니다. 복잡한 reasoning 목표에 models을 맞추기 위한 일반적인 전략인 Reinforcement learning은 계산 비용이 많이 들고 sample 비효율적입니다. long videos에 적용될 때, RL은 확장된 video frames로 인해 훨씬 더 부담스러워지며, 더 많은 memory와 더 긴 rollout runtime을 필요로 합니다. 이러한 도전들은 강력한 reasoning 능력을 갖춘 효과적인 long video VLM의 개발을 공동으로 방해합니다.
이 연구에서 우리는 long-video understandings를 위한 reasoning 능력을 탐구하는 포괄적인 framework인 LongVILA-R1을 소개합니다. 첫째, 우리는 LongVideo-Reason이라는 이름의 long video reasoning을 위한 CoT annotations가 포함된 고품질 dataset을 전략적으로 구축합니다. 강력한 VLM (NVILA-8B)과 선도적인 open-source reasoning LLM을 활용하여, 우리는 long videos를 위한 52K개의 고품질 Question-Reasoning-Answer pairs로 구성된 dataset을 개발합니다. 우리는 model의 reasoning 및 instruction-following 능력을 초기화하기 위해 Long-CoT-SFT에 18K개의 고품질 samples를 사용하고, reinforcement learning을 위해 추가적인 110K video data와 함께 33K개의 samples를 사용합니다. 이 2단계 training은 고품질 reasoning annotations와 reinforcement learning을 결합하여 LongVILA-R1이 우수하고 일반화된 video reasoning을 달성할 수 있도록 합니다. 우리는 또한 포괄적인 평가를 위해 Temporal, Goal and Purpose, Spatial, 그리고 Plot and Narrative의 네 가지 관점에서 performance를 평가하는 새로운 benchmark인 LongVideo-Reason-eval을 구축하기 위해 1K개의 long-video samples로 구성된 균형 잡힌 세트를 수동으로 선별합니다.
둘째, 우리는 long video reasoning을 발전시키기 위해 VLM을 위한 training framework를 제안합니다. 그림 5에서 설명한 바와 같이, 이 framework는 Stage-1: Long CoT-SFT와 Stage-2: RL for long video reasoning의 두 단계를 포함합니다. 방대한 visual embeddings, 무거운 rollouts, long-context LLM prefilling을 포함한 long video RL의 고유한 문제를 해결하기 위해, 우리는 Multi-modal Reinforcement Sequence Parallelism (MR-SP)이라고 하는 효율적이고 확장 가능한 솔루션을 개발합니다. 이는 LongVILA에 맞춰진 vLLM engine과 video embeddings를 위한 caching 체계를 통합합니다. MR-SP system은 집중적인 memory 문제를 완화하고 long video VLM의 RL training을 용이하게 합니다. 그림 1에서 볼 수 있듯이, 우리의 MR-SP system은 7B models에 대한 512-frame video RL training에서 최대 2.1배의 speedup을 달성하고 out-of-memory (OOM) 없이 더 긴 training frames를 가능하게 합니다.
LongVILA-R1-7B는 VideoMME(자막 포함)에서 68.4%와 같은 일반 video benchmark에서 강력한 performance를 보여줍니다. 우리의 LongVideo-Reason-eval benchmark에서 LongVILA-R1-7B는 네 가지 reasoning categories에 걸쳐 평균 67.9%의 accuracy를 달성하여, Video-R1-7B를 포함한 open-source models와 GPT-4o와 같은 proprietary models를 큰 차이로 능가하며, Gemini-1.5-Pro의 performance와 대등합니다. 또한, LongVILA-R1은 input frames 수가 증가함에 따라 점진적인 performance 향상을 보입니다.

- 이 이미지는 LongVILA-R1의 예시들을 보여줍니다. 왼쪽부터 순서대로 축구 경기 결과 예측, Texas Hold'em 포커에서의 의사 결정, 그리고 상자 속 공의 위치를 추적하는 spatial dynamics와 같은 task 샘플과 그에 대한 reasoning 과정을 설명합니다. 특히, spatial tracking 예시에서는 input video frames 수가 증가함에 따라 model이 정확한 reasoning에 실패하는 경우를 보여줍니다
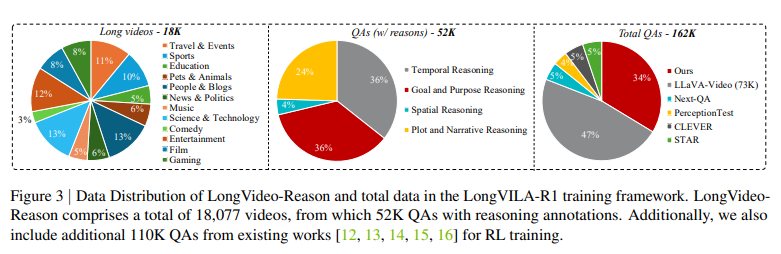
이 이미지는 LongVILA-R1 training framework에 사용된 LongVideo-Reason dataset과 전체 데이터의 분포를 보여줍니다. 왼쪽 첫 번째 파이 차트는 18,000개 긴 동영상의 장르별 분포를 나타냅니다. 가운데 차트는 reasoning이 포함된 52,000개 QA의 유형(Temporal, Goal and Purpose, Spatial, Plot and Narrative Reasoning)별 분포를 보여줍니다. 오른쪽 차트는 LongVILA-R1 학습에 사용된 전체 162,000개의 QA 데이터가 다른 기존 dataset들과 비교하여 어느 정도의 비율을 차지하는지 보여줍니다
Introduction 정리노트 (AI 연구자용) 📝
- 핵심 문제 정의 (Problem Definition)
- Long video understanding에서 단순 인식을 넘어선 temporal, spatial, goal, narrative에 대한 reasoning 능력 확보의 어려움.
- 주요 병목 현상:
- 데이터 부재: Reasoning 과정이 포함된 고품질 long video dataset이 부족. 제작이 노동 집약적이고 비용이 많이 듦.
- 학습 비효율성: Reasoning 능력 강화를 위한 Reinforcement Learning (RL)은 long video에 적용 시 memory 요구량이 막대하고 rollout 시간이 길어 비효율적이고 불안정함.
- 핵심 제안 (Core Proposal): LongVILA-R1 Framework
- Long video reasoning을 위한 데이터, 학습 방법론, 학습 시스템을 모두 포함하는 full-stack framework.
- Contribution 1: 데이터셋 (LongVideo-Reason)
- 강력한 VLM과 LLM을 활용하여 CoT (Chain-of-Thought) 스타일의 reasoning annotation이 포함된 52K 규모의 고품질 QA dataset을 구축.
- Reasoning 능력의 다각적 평가를 위한 1K 규모의 LongVideo-Reason-eval benchmark를 별도로 제작.
- Contribution 2: 학습 파이프라인 (2-Stage Training)
- Stage 1: Long CoT-SFT를 통해 model에 reasoning 및 instruction-following 능력을 명시적으로 주입.
- Stage 2: RL을 통해 reasoning 능력을 더욱 강화하고 일반화.
- Contribution 3: 학습 시스템 (MR-SP)
- Multi-modal Reinforcement Sequence Parallelism (MR-SP)라는 long video RL 전용 학습 인프라를 개발.
- vLLM engine과 video embedding caching을 도입하여 RL rollout과 prefilling 과정의 비효율을 개선. 이를 통해 학습 속도를 최대 2.1배 향상시키고 OOM (Out-of-Memory) 문제 없이 더 긴 sequence 학습을 가능하게 함.
- 주요 결과 (Key Results)
- LongVILA-R1-7B model이 자체 benchmark에서 open-source 경쟁 model 및 GPT-4o를 능가하고, Gemini-1.5-Pro와 대등한 reasoning performance를 달성.
- Input video frames 수가 증가할수록 performance가 일관되게 향상되는 scaling 특성을 보임.
쉬운 설명 💡
긴 동영상(영화 한 편, 축구 경기 전체 등)을 AI가 제대로 이해하게 만드는 것은 매우 어렵습니다. 단순히 영상에 '무엇이 있는지' 아는 것을 넘어, '시간에 따라 상황이 어떻게 변하는지', '등장인물의 숨은 의도는 무엇인지', '전체적인 줄거리가 어떻게 되는지'를 추리(reasoning)할 수 있어야 하기 때문입니다.
이 연구는 이 문제를 풀기 위해 두 가지 큰 장애물을 해결하고자 했습니다.
- 쓸만한 교재가 없다: AI에게 이런 복잡한 reasoning을 가르칠 만한 고품질의 long video dataset(학습 데이터 모음)이 거의 없습니다.
- 훈련 방식이 비효율적이다: 이런 능력을 키우는 데 효과적인 Reinforcement Learning (RL)이라는 훈련 방식은 긴 영상에 적용하면 컴퓨터 자원을 엄청나게 소모해서(특히 memory) 비효율적이고 훈련이 자주 멈춥니다.
이 논문은 위의 문제들을 해결하기 위해 다음 세 가지를 포함하는 LongVILA-R1이라는 종합 솔루션을 만들었습니다.
- 새로운 교재 제작: 똑똑한 AI를 활용해, 질문과 함께 상세한 '생각의 과정'(reasoning)까지 포함된 52,000개 분량의 고품질 long video dataset을 직접 만들었습니다.
- 체계적인 2단계 훈련법: 먼저 CoT라는 방식으로 reasoning의 기초를 가르친 후, RL 훈련으로 능력을 한 단계 더 끌어올리는 2단계 훈련법을 적용했습니다.
- 초고효율 훈련 시스템 개발: 긴 영상으로 RL 훈련을 할 때 memory 문제를 해결하고 속도를 2.1배까지 높이는 MR-SP라는 특별한 시스템을 개발했습니다.
결과적으로, 이들이 만든 LongVILA-R1이라는 AI model은 긴 영상에 대한 reasoning을 매우 잘하게 되어, 이 분야에서 GPT-4o 같은 유명 model보다 뛰어나고 Gemini-1.5-Pro와 대등한 성능을 보여주었습니다.

이 이미지는 LongVideo-Reason dataset의 data generation process를 보여주는 Figure 4입니다.
전체 과정은 다음과 같습니다.
- 동영상 분할 및 캡션 생성: 먼저 Long Videos를 10초 단위의 Short Video Clips으로 나눕니다. 그 다음 NVILA-8B라는 model을 사용해 각각의 짧은 clip에 대한 caption을 자동으로 생성합니다.
- 질의응답 및 추론 과정 생성: 이렇게 만들어진 한 영상의 모든 caption들을 종합하여, 선도적인 open-source reasoning LLM이 영상 전체 내용에 대한 reasoning을 요구하는 Question-Answer pairs를 만듭니다. 이 질문들은 Temporal, Goal and Purpose, Spatial, Plot and Narrative의 네 가지 유형으로 분류됩니다. 이어서 동일한 LLM이 Long-Cot Reasoning steps 형태로 답변에 이르는 상세한 reasoning 과정을 생성합니다.
2. Related Work
Multi-modal reasoning models. Multi-modal reasoning 분야는 특히 Vision-Language Models (VLMs)에서 상당한 발전을 이루었습니다. GPT-4o는 향상된 reasoning을 통해 visual 이해도를 높였고, Gemini-1.5-Pro는 context length를 1백만 tokens으로 확장하여 VideoMME에서 state-of-the-art performance를 달성했습니다. Open-source VLM의 architecture 및 training algorithms의 상당한 진전에 따라, multi-modal reasoning은 two-stage training strategy를 사용하는 LMM-R1, post-cold-start overthinking 문제를 다루는 Vision-R1, 그리고 16 frames에서 T-GRPO를 통해 video를 위한 RL을 강화하는 Video-R1을 포함한 연구들에서 더욱 탐구되었습니다. 그러나 이러한 접근 방식들은 주로 single images나 short videos에 초점을 맞추고 있으며, long video reasoning은 여전히 큰 도전 과제로 남아 있습니다.
Sequence parallelism. Long contexts로 training하는 것은 종종 단일 device의 memory 용량을 초과하므로 효율적인 distribution strategies가 필요합니다. Sequence parallelism (SP)은 널리 채택된 해결책이 되었습니다. 예를 들어, LightSeq나 Ring Attention과 같은 ring-based systems은 point-to-point (P2P) communication을 사용하는 반면, DeepSpeed-Ulysses는 attention computations을 최적화하기 위해 all-to-all (A2A) primitives를 사용합니다. 추가적으로, USP와 LoongTrain은 Ring-style SP와 Ulysses SP를 통합하기 위해 도입되었습니다. LongVILA는 더 나아가 multi-modal SP (MM-SP)를 제안하여, vision-language models이 long-context inputs을 처리할 수 있도록 했습니다. 그러나, multi-modal reinforcement learning은 long, mixed-token sequences로부터 광범위한 sampling을 필요로 하므로, 특히 복잡한 group optimization tasks에서 추가적인 어려움을 야기합니다.
RL frameworks for LLMs/VLMs. Reinforcement Learning (RL)은 Large Language Models (LLMs)를 향상시키는 핵심 전략이 되었으며, 특히 model outputs을 human preferences에 맞추는 Reinforcement Learning with Human Feedback (RLHF)이나 Direct Preference Optimization을 통해 이루어집니다. 최근의 발전은 RL이 LLM reasoning 능력을 크게 향상시킨다는 것을 보여줍니다. 예를 들어, DeepSeek-R1은 Group Relative Policy Optimization (GRPO) algorithm을 활용하여 group-based sampling과 rule-based rewards를 통합합니다. 다른 한편으로, RL은 특히 multi-modal settings에서 무거운 computational cost라는 고유한 문제를 제기합니다. 이 문제를 해결하기 위해, 효율적인 data flow를 위해 Ray를 활용하고 faster sampling을 위해 vLLM을 활용하는 HybridFlow가 도입되었습니다. 그럼에도 불구하고, 이는 long video sequences를 처리할 때 여전히 bottleneck으로 남아 있으며, group-based sampling은 long-context sampling과 visual encoding의 높은 computational cost에 의해 제약을 받습니다. 이 연구에서 우리는 long video RL training에 최대 2.1배의 speedup을 제공하는 MR-SP를 제안합니다.
Related Work 정리노트 (AI 연구자용) 📝
이 섹션은 본 연구가 기존 연구들과 비교하여 어떤 위치에 있으며, 어떤 차별점을 갖는지 설명합니다.
- Multi-modal reasoning models 관점
- 기존 연구: GPT-4o, Gemini-1.5-Pro 같은 closed-source model이나 Video-R1 같은 open-source model들은 single image나 short video(16 frames 수준)의 reasoning에서는 큰 성과를 보였습니다.
- 연구의 Gap: 하지만 이들의 접근법은 long video의 reasoning 문제를 해결하기엔 한계가 명확합니다. Long video reasoning은 여전히 미개척 분야입니다.
- 본 연구의 포지션: Short video의 한계를 넘어 long video 영역의 reasoning 문제를 직접적으로 해결하는 것을 목표로 합니다.
- Sequence parallelism 관점
- 기존 연구: Long context training을 위해 memory 문제를 해결하는 Sequence Parallelism (SP) 기술들(Ring Attention, DeepSpeed-Ulysses, MM-SP 등)이 개발되었습니다.
- 연구의 Gap: 기존 SP 기술들은 일반적인 지도 학습 training에 초점을 맞추고 있어, RL (Reinforcement Learning) training에서 발생하는 고유한 문제(예: 광범위한 sampling 오버헤드, 복잡한 group optimization)를 효율적으로 다루지 못합니다.
- 본 연구의 포지션: Multi-modal RL training의 특수성을 고려하여, sampling과 optimization 과정의 비효율을 개선하는 새로운 parallelism 기법(MR-SP)을 제안합니다.
- RL frameworks 관점
- 기존 연구: LLM의 reasoning 능력 강화를 위해 RLHF와 같은 RL이 핵심 전략이 되었고, HybridFlow처럼 vLLM을 사용해 sampling 속도를 개선하려는 framework도 등장했습니다.
- 연구의 Gap: 그럼에도 불구하고 long video의 RL training은 long-context sampling과 visual encoding에서 발생하는 막대한 computational cost 때문에 여전히 bottleneck 상태입니다.
- 본 연구의 포지션: long video RL training의 핵심 bottleneck을 직접 겨냥하여, MR-SP를 통해 기존 framework의 한계를 극복하고 최대 2.1배의 speedup을 달성했습니다.
쉬운 설명 💡
이 부분은 이 연구가 "기존 연구들보다 무엇이 더 새로운가?"를 설명하는 부분입니다.
- AI의 추리 능력에 대하여
- 다른 연구자들이 AI에게 사진 한 장이나 몇 초짜리 짧은 동영상을 보고 상황을 추리(reasoning)하는 법은 어느 정도 가르쳤습니다.
- 하지만 이 연구는 여기서 한 걸음 더 나아가, 한 시간짜리 영화처럼 '긴 동영상'을 보고 전체적인 맥락과 줄거리를 reasoning하는 어려운 문제에 처음으로 제대로 도전했다는 점에서 다릅니다.
- AI의 훈련 방식에 대하여
- AI를 훈련시킬 때 데이터가 너무 길고 크면 컴퓨터가 힘들어해서 데이터를 잘게 나눠서 훈련하는 기술(Sequence Parallelism)이 이미 있었습니다.
- 하지만 RL이라는 특별 훈련 방식은 기존 기술과 잘 맞지 않았습니다. 이 연구는 RL 훈련 방식에 딱 맞는 '새로운 데이터 분산 처리 기술'(MR-SP)을 개발해 long video 훈련을 가능하게 만들었습니다.
- AI 훈련 속도에 대하여
- RL 훈련은 원래 매우 느립니다. 다른 연구들이 이 속도를 높이려고 노력했지만, 특히 '긴 동영상'을 훈련시킬 땐 여전히 너무 느렸습니다.
- 이 연구는 바로 그 '긴 동영상 RL 훈련'의 속도를 2.1배나 빠르게 만드는 획기적인 방법을 개발해서, 기존의 속도 문제를 해결했다는 점이 중요합니다.
3. LongVideo-Reason Data Construction
VLMs를 위해서는 long videos에 대한 고품질의 annotated datasets가 매우 중요합니다. 기존에 공개된 long-video datasets에는 고품질의 reasoning annotations이 부족합니다. 이 섹션에서는 reasons이 포함된 52K 개의 long-video QAs의 data construction process(Figure 4)를 자세히 설명합니다.
3.1. Overview of Data Curation
우리는 먼저 Shot2Story dataset에서 18K개의 long videos를 선별합니다(Figure 3, 왼쪽). 그런 다음 Section 3.2에 자세히 설명된 대로 CoT를 위한 고품질 automated annotation pipeline을 적용하여, 총 52K개의 Question-Reasoning-Answer pairs를 만듭니다. 각 샘플은 reasoning하는 질문의 유형에 따라 Temporal Reasoning, Goal and Purpose Reasoning, Spatial Reasoning, 또는 Plot and Narrative Reasoning으로 분류될 수 있습니다(Figure 3, 가운데). 이 dataset은 다양한 유형의 long-video reasoning tasks를 포괄적으로 지원하도록 설계되었습니다.
GRPO가 batch sampling에 민감하다는 점을 감안하여, data filtering 접근 방식을 채택했습니다. 구체적으로, 우리는 LongVILA가 원본 datasets에 대해 10회 inference를 수행하는 test-scaling method를 사용합니다. 일관되게 정답 또는 오답을 맞힌 질문들은 "easy" 또는 "hard"로 레이블링되고, 다양한 predictions을 유도하는 질문들은 "medium"으로 레이블링됩니다. 우리는 Stage-1 COT-SFT에는 "easy"와 "hard" 샘플을 모두 사용하고, Stage-2 RL training에는 "medium" 샘플을 사용합니다. 그 이유는 GRPO가 의미 있는 advantages를 갖기 위해 각 샘플의 서로 다른 rollouts이 다양할 것으로 기대하며, 모든 rollouts이 정답 또는 오답을 예측하면 gradient가 사라지기 때문입니다. COT-SFT subset(18K)은 표준 구조로 형식화된 고품질의 CoT reasoning 과정을 특징으로 하며, Stage 1에서 model의 reasoning 능력에 대한 warm-up training을 위한 풍부한 리소스를 제공합니다. 한편, RL subset은 33K개의 도전적인 long-video Q&A를 포함하며, 이는 Stage 2에서 reinforcement learning을 통해 reasoning을 확장하는 데 활용됩니다. RL 확장을 더욱 강화하기 위해, 우리는 다른 datasets에서 가져온 추가적인 110K개의 고품질 open-source videos(Figure 3, 오른쪽)를 통합합니다. 이 조합은 model의 generalization을 향상시킵니다.
3.2. Long-Video Reasoning Generation
우리는 long videos에서 고품질의 Question-Reasoning-Answer pairs를 생성하는 automated annotation pipeline(Figure 4)을 소개합니다. 이 과정은 videos를 짧은 clips(각각 약 10초)으로 segmenting하는 것으로 시작하며, 각 clip은 NVILA-8B model을 사용하여 annotation되어 설명적인 captions을 제공합니다. Text-based reasoning의 획기적인 발전을 활용하여, 우리는 선도적인 open-source reasoning LLM을 배치하고, 각 video에 있는 모든 clips의 captions을 제공한 다음, 전체 video에 걸친 콘텐츠에 대한 reasoning을 포함하는 다양한 유형의 Question-Reasoning-Answer pairs를 생성하도록 prompt합니다. 구체적으로, 우리는 LLM이 네 가지 reasoning 유형 중 하나에 초점을 맞춘 Question-Reasoning-Answer pair를 생성하도록 장려하기 위해 네 가지 유형의 prompts를 설계합니다: Temporal Reasoning, Goal and Purpose Reasoning, Spatial Reasoning, 또는 Plot and Narrative Reasoning. VLMs가 visual details에 집중하도록 하기 위해, 우리는 또한 visual content의 반복적인 검사를 유도하는 "checking the video" 및 "analyzing the scene"과 같은 구문을 사용하여 prompts를 만듭니다. 마지막으로, LLM이 reasoning 단계를 다듬고 간소화하는 데 사용됩니다. 우리는 또한 네 가지 reasoning categories에 걸쳐 1,000개의 고품질 복합 reasoning 질문들을 수동으로 선별하여, VLMs의 reasoning 능력을 평가하기 위한 새로운 benchmark(LongVideo-Reason-eval)로 사용합니다. 이 전체 데이터 절차는 H100s에서 약 40,000 GPU hours를 소모합니다.
LongVideo-Reason Data Construction 정리노트 (AI 연구자용) 📝
이 섹션은 long video reasoning을 위한 새로운 dataset인 LongVideo-Reason의 구축 방법론을 설명합니다.
- 핵심 목표 (Core Goal)
- Long video에 대한 고품질 reasoning annotation이 포함된 dataset의 부재 문제를 해결.
- Shot2Story dataset의 18K videos를 기반으로, CoT (Chain-of-Thought) reasoning이 포함된 52K개의 Question-Reasoning-Answer pairs를 구축.
- 데이터 생성 파이프라인 (Data Generation Pipeline)
- Segment & Caption: Long video를 10초 단위 clips으로 분할하고, NVILA-8B model을 사용하여 각 clip의 caption을 생성.
- Generate Q&A with CoT: Open-source reasoning LLM에 한 video의 모든 captions을 입력하여, Temporal, Goal/Purpose, Spatial, Plot/Narrative 4가지 유형의 reasoning을 요구하는 Question-Reasoning-Answer pair를 생성.
- Prompt Engineering: prompt에 "checking the video"와 같은 구문을 삽입하여 model이 text가 아닌 visual 정보에 집중하도록 유도.
- 핵심 전략: RL 학습을 위한 데이터 필터링 (Key Strategy: Data Filtering for RL)
- 문제 인식: RL 알고리즘인 GRPO는 batch sampling에 민감. Batch 내 샘플들의 rollout 결과가 모두 정답이거나 모두 오답일 경우, advantage 계산이 무의미해져 gradient가 소실되는 문제가 발생.
- 해결책 (test-scaling): 각 샘플을 10회 inference하여 결과의 다양성을 기준으로 데이터를 "easy", "hard", "medium"으로 분류.
- 데이터 분리:
- COT-SFT (Stage 1) 용: "easy" & "hard" 샘플 (18K)을 사용해 model의 기본 reasoning 능력을 안정적으로 확보.
- RL training (Stage 2) 용: 다양한 rollout을 유도하는 "medium" 샘플 (33K)을 사용하여 GRPO 학습 효율을 극대화. 이는 이 논문의 RL 학습 방법론에서 매우 중요한 기여.
- 추가 구성 (Additional Components)
- Model의 generalization 성능 향상을 위해 외부 open-source video 데이터 110K를 RL dataset에 추가.
- 신뢰성 있는 평가를 위해, 4가지 reasoning categories에 걸쳐 1,000개의 고품질 복합 질문을 수동으로 제작하여 LongVideo-Reason-eval benchmark를 구축.
- 소요 비용 (Resource Cost)
- 전체 데이터 구축 과정에 H100 GPU 기준 약 40,000 시간이 소요됨.
쉬운 설명 💡
AI에게 긴 동영상을 보고 사람처럼 추리(reasoning)하는 법을 가르치고 싶은데, 마땅한 교재(dataset)가 없어서 직접 만들었다는 내용입니다.
- 교재 만드는 과정 (자동화 파이프라인)
- 긴 동영상을 10초 단위로 잘게 자릅니다.
- AI를 시켜 각 짧은 장면에 대한 요약 글(caption)을 쓰게 합니다.
- 더 똑똑한 AI에게 이 요약 글들을 전부 주고, "그래서 이 영상의 전체 줄거리는 뭐야?" 또는 "주인공의 최종 목표는 뭐였을까?" 같은 깊이 있는 질문과 그에 대한 '생각의 과정'(reasoning)이 담긴 모범 답안을 만들게 합니다.
- 핵심 비법: 학생 수준별 맞춤 문제집 만들기
- AI를 훈련시킬 때, 너무 쉬운 문제나 너무 어려운 문제만 계속 풀게 하면 학습 효과가 떨어집니다. 특히 RL이라는 훈련 방식은 AI가 '아리송해서' 맞힐 때도 있고 틀릴 때도 있는 문제를 풀 때 가장 똑똑해집니다.
- 그래서 모든 문제를 AI에게 미리 여러 번 풀게 해서 난이도를 측정했습니다.
- 기초 훈련용 문제집 (COT-SFT): 항상 맞히는 '쉬운' 문제와 항상 틀리는 '어려운' 문제를 모아서 AI에게 기본기를 가르칩니다.
- 실전 훈련용 문제집 (RL training): 맞혔다 틀렸다 하는 '아리송한' 문제들만 따로 모아서, AI의 reasoning 능력을 집중적으로 훈련시킵니다. 이게 이 연구의 핵심적인 훈련 비법입니다.
- 최종 시험 문제집 제작
- AI의 실력을 공정하게 평가하기 위해, 연구자들이 직접 1,000개의 아주 어려운 문제들을 손으로 만들어 최종 시험 문제집(benchmark)도 따로 만들었습니다.
4. LongVILA Training Pipeline
4.1. Long Video CoT Supervised Fine-Tunin
52K개의 고품질 question-reasoning-answer pairs를 활용하여, 우리는 Section 3.1에서 설명한 data filtering method를 적용하여 long CoT-SFT를 위한 18K개의 예제를 선택하고, 이를 후속 RL을 위한 warm-up phase로 사용합니다. 이 단계는 model에 long video scenarios에 대한 기본적인 reasoning abilities와 instruction-following skills을 갖추게 합니다. 수백 개의 frames에 대해 효율적으로 SFT를 수행하기 위해, 우리는 LongVILA의 MM-SP training system을 채택합니다. Section 6.2에서 입증된 바와 같이, 우리의 LongVideo-Reason dataset만으로 SFT를 수행하는 것 또한 model의 기초적인 reasoning capabilities를 효과적으로 향상시킵니다.
4.2. GRPO for Long Video
GRPO algorithm의 발전과 multi-modal reasoning training에 대한 이전의 탐구들을 바탕으로, 우리는 model을 train하기 위해 standard GRPO framework를 따릅니다. 주어진 각 질문 에 대해, policy model은 old policy $\pi_{\theta_{old}}$로부터 후보 응답 그룹 ${o_1, o_2, ..., o_G}$를 생성하며, 이와 함께 rule-based reward functions(format/accuracy)에 기반하여 계산된 해당 rewards ${r_1, r_2, ..., r_G}$가 동반됩니다. 그 후 model $\pi_{\theta}$는 다음의 objective function을 최대화함으로써 최적화됩니다:
여기서 과 는 hyper-parameters이고, 우리의 실험에서는 가 8로 설정되었으며, 위에서 샘플링된 rewards는 model을 업데이트하기 위한 advantages ()를 얻기 위해 정규화됩니다:
그러나, RL for long videos는 수백에서 수천 개의 frames를 처리하는 데 따르는 높은 computational demands 때문에 상당한 어려움을 제시합니다. 기존의 RL frameworks는 rollout 및 LLM prefilling에서 이러한 long-context training에 어려움을 겪습니다. 이를 해결하기 위해, 우리는 long-context video reasoning을 위한 reinforcement learning을 효율적으로 확장하는 MR-SP framework(Section 5)를 개발합니다. training 중 GRPO의 sampling에 대한 민감성을 고려하여, Section 3.1에서 설명한 바와 같이 reinforcement learning을 위해 33K개의 filtered data를 사용합니다. 추가적으로, RL을 scale up하기 위해 Video-R1에서 가져온 110K개의 샘플이 통합됩니다. 이 접근 방식은 model이 자유롭게 탐색하고 더 효과적이고 generalized reasoning strategies를 개발하도록 유도하는 것을 목표로 합니다.
LongVILA Training Pipeline 정리노트 (AI 연구자용) 📝
이 섹션은 LongVILA-R1 model을 학습시키기 위한 2단계 training pipeline을 설명합니다.
- 핵심 구조 (Core Architecture): 2-Stage Training Pipeline
- Long video reasoning 능력을 효과적으로 학습시키기 위해, SFT로 기본기를 다지고 RL로 심화하는 2단계 접근법을 채택했습니다.
- Stage 1: Long CoT Supervised Fine-Tuning (SFT)
- 목표 (Objective): RL 단계를 위한 warm-up phase. Model에 long video의 문맥을 이해하고, CoT 형식의 reasoning 패턴과 instruction을 따르는 기본적인 능력을 주입합니다.
- 데이터 (Data): 자체 제작한 LongVideo-Reason dataset에서 data filtering을 통해 선별한 "easy" 및 "hard" 샘플 18K개를 사용합니다.
- 시스템 (System): Long context(hundreds of frames)를 효율적으로 처리하기 위해 기존 LongVILA의 MM-SP training system을 활용합니다.
- Stage 2: GRPO for Long Video (RL)
- 목표 (Objective): SFT로 학습된 기초 reasoning 능력을 바탕으로, RL을 통해 model이 더 효과적이고 일반화된 reasoning 전략을 스스로 탐색하고 발전시키도록 유도합니다.
- 데이터 (Data): GRPO 학습에 최적화된 "medium" 난이도 샘플 33K개와, model의 generalization을 위해 Video-R1 dataset의 110K 샘플을 추가로 사용합니다.
- 방법론 (Methodology): GRPO 알고리즘을 채택합니다. old policy에서 G=8개의 후보 응답을 sampling하고, rule-based reward를 정규화하여 얻은 advantage()를 이용해 policy를 업데이트합니다.
- 핵심 도전과 해결 (Key Challenge & Solution): Long video RL에서 rollout 및 LLM prefilling 시 발생하는 막대한 computational cost가 가장 큰 bottleneck입니다. 이 논문은 이 문제를 해결하기 위해 특별히 개발한 MR-SP framework(Section 5에서 상세히 설명)를 도입하여, long-context RL training을 효율적으로 확장합니다.
쉬운 설명 💡
AI를 훈련시키는 전체 과정을 체계적인 '2단계 학습 코스'로 설계했다는 내용입니다.
- 1단계: 교과서로 기본기 다지기 (SFT 단계)
- AI에게 reasoning이 무엇인지 처음 가르치는 단계입니다.
- 연구팀이 만든 '교과서'(18K개의 데이터)를 주고, 질문과 정답, 그리고 왜 그런 정답이 나왔는지에 대한 상세한 '풀이 과정'(CoT)을 그대로 따라 배우게 합니다.
- 이건 마치 학생에게 수학 공식을 암기시키고 기본 예제를 풀게 해서 개념을 확실히 익히게 하는 것과 같습니다. 이 과정을 통해 AI는 reasoning의 기초를 다집니다.
- 2단계: 실전 응용 문제로 능력 키우기 (RL 단계)
- 기본기를 익힌 AI에게 이제는 정답과 풀이 과정이 정해져 있지 않은 '실전 응용 문제'를 줍니다.
- AI는 여러 가지 방법으로 문제를 풀어보고(rollouts), 더 나은 풀이법에 대해서는 '칭찬'(reward)을 받으며 스스로 더 효과적인 reasoning 전략을 터득해 나갑니다. RL 훈련은 바로 이런 방식입니다.
- 이 2단계 훈련은 컴퓨터에 부담이 매우 크지만, 이 논문에서 특별히 개발한 초고효율 시스템(MR-SP)을 사용해서 이 문제를 해결하고 훈련 속도를 높였습니다.
5. Multi-modal Reinforcement SP
R1-V와 EasyR1과 같은 VLMs를 위한 기존의 RL frameworks는 높은 token volume으로 인해 고유한 어려움을 제시하는 long videos를 위해 설계되지 않았습니다. 이를 해결하기 위해, 우리는 long videos에 대한 효율적인 RL training을 위한 framework인 Multi-modal Reinforcement Sequence Parallelism (MR-SP)를 소개합니다. MR-SP는 rollout 및 pre-filling 단계 모두에서 sequence parallelism을 활용하여, 감소된 overhead로 RL에서 long videos를 가능하게 합니다.
5.1. Stage 1 - Rollout with Paralleled Encoding
long-video reinforcement learning을 효율적으로 지원하기 위해, 우리는 video encoding stage에 sequence parallelism (SP)을 채택합니다. 그림 7에서 볼 수 있듯이, input video frames는 먼저 각각 자체 vision tower를 갖춘 여러 GPUs(예: GPU 1에서 GPU 3까지)에 균등하게 분할됩니다. 각 GPU는 video의 일부를 독립적으로 처리하여, frames의 subset만을 encoding합니다. 결과 video embeddings는 그림의 "All-Gather" 화살표로 표시된 것처럼 all-gather operation을 통해 text embeddings와 집계됩니다. 이 전략은 encoding 작업 부하를 분산시켜, 시스템이 더 많은 GPUs를 활용하여 훨씬 더 긴 videos를 처리할 수 있게 하면서 GPU memory overflow의 위험을 피할 수 있게 합니다. parallel encoding 방식은 vision towers의 균형 잡힌 활용을 보장하고, 단일 device에서는 불가능했을 확장 가능한 long-video processing을 가능하게 합니다.
video embeddings가 전역적으로 수집된 후, 이들은 RL pipeline 전체에 걸쳐 다운스트림 사용을 위해 재사용됩니다. 그림 7에서 설명한 바와 같이, 수집된 embeddings는 recomputation 없이 여러 rollouts 동안 재사용됩니다. 예를 들어, 각 training step에서 우리는 일반적으로 8에서 16개의 rollouts을 수행합니다. 재활용 없이는 동일한 video가 step당 수십 번 다시 encoding되어야 하므로 training 속도에 심각한 영향을 미칩니다. 수집된 embeddings를 caching하고 재사용함으로써, MR-SP는 이러한 중복을 제거하고 training을 크게 가속화합니다.
5.2. Stage 2 - Prefilling with Sequence Parallelism
각 rollout에 대해, reference 및 policy models 모두 long videos를 위한 RL에서 계산 집약적인 prefilling을 필요로 합니다. Stage 1에서 수집되어 재사용된 embedding을 가지고, 우리는 sequence parallelism을 사용하여 여러 devices에 걸쳐 inference stage를 병렬화합니다. 그림 7에서 설명한 바와 같이, 전역적으로 수집된 input embeddings는 먼저 균일한 길이로 채워지고(Padding Sequence), 그런 다음 GPUs에 균등하게 분할됩니다(Sharding to Local GPU). 이를 통해 각 GPU는 prefilling 동안 input sequence의 일부만 처리할 수 있습니다. 이 parallelism은 policy 및 reference model prefilling 모두에 적용됩니다. 그런 다음, 각 GPU는 자신의 token slice에 대한 logits를 로컬에서 병렬로 계산합니다.
Multi-modal Reinforcement SP 정리노트 (AI 연구자용) 📝
이 섹션은 long video에 대한 Reinforcement Learning (RL)의 비효율성 문제를 해결하기 위해 제안된 새로운 framework인 Multi-modal Reinforcement Sequence Parallelism (MR-SP)의 기술적 구조를 설명합니다.
- 핵심 문제 (Core Problem)
- 기존 RL frameworks는 long video의 방대한 token volume으로 인한 computational cost를 감당하도록 설계되지 않았습니다.
- 특히 RL의 rollout 단계에서 반복적인 video encoding과 계산 집약적인 prefilling이 주요 bottleneck입니다.
- 제안 시스템: Multi-modal Reinforcement Sequence Parallelism (MR-SP)
- RL의 rollout과 prefilling이라는 두 핵심 bottleneck 단계에 sequence parallelism을 적용하여 long video 학습을 효율화하는 framework입니다.
- Stage 1: Rollout 단계 최적화
- Paralleled Encoding: Long video frames를 여러 GPU에 걸쳐 분산시키고, 각 GPU의 vision tower가 할당된 frame subset을 병렬로 encoding합니다. 이후 all-gather operation으로 개별 video embeddings을 하나로 통합합니다.
- 효과: 단일 GPU의 memory overflow를 방지하고, video encoding 부하를 분산시켜 확장성을 확보합니다.
- Embedding Caching: 한번 encoding되어 통합된 video embedding은 cache에 저장됩니다. 해당 training step의 모든 rollouts(예: 8~16회)에서 recomputation 없이 이 embedding을 재사용합니다.
- 효과: step마다 수십 번씩 발생하던 반복적인 video encoding 연산을 완전히 제거하여 training 속도를 크게 향상시킵니다.
- Paralleled Encoding: Long video frames를 여러 GPU에 걸쳐 분산시키고, 각 GPU의 vision tower가 할당된 frame subset을 병렬로 encoding합니다. 이후 all-gather operation으로 개별 video embeddings을 하나로 통합합니다.
- Stage 2: Prefilling 단계 최적화
- Sequence Parallelism 적용: Stage 1에서 caching된 input embedding을 sequence 차원에서 분할(sharding)하여 여러 GPU에 분산시킵니다.
- Parallel Prefilling: 각 GPU는 input sequence의 일부에 대해서만 policy 및 reference model의 prefilling을 병렬로 수행하고, 로컬 token slice에 대한 logits를 계산합니다.
- 효과: RL rollout 과정 내부의 계산 집약적인 prefilling 단계를 병렬화하여, 전체 rollout 생성 시간을 단축시킵니다.
쉬운 설명 💡
AI에게 긴 동영상을 보여주면서 RL 방식으로 훈련시키는 것은 컴퓨터에게 너무 힘든 작업입니다. 특히 (1) 맨 처음에 긴 영상을 '이해'하는 과정과 (2) AI가 여러 가지 답을 '생각'해내는 과정이 너무 느린데, 이 문제를 해결하기 위해 MR-SP라는 '초고효율 AI 훈련 공장'을 설계했다는 내용입니다.
- 1단계: 영상 이해 작업을 효율적으로 나눠서 하기
- 나눠서 처리하기 (Paralleled Encoding): 한 명의 일꾼(GPU)에게 1시간짜리 영상을 통째로 보여주면 과부하가 걸립니다. 그래서 영상을 10분짜리 6조각으로 잘라서, 6명의 일꾼(GPU)에게 동시에 나눠주고 각자 맡은 부분만 '이해'(encoding)하게 합니다. 나중에 그 결과물들을 합치면 훨씬 빠르고 컴퓨터가 멈출 위험도 없습니다.
- 한번 본 건 저장해두기 (Embedding Caching): AI는 한 문제에 대해 여러 가지 답을 떠올려보는데(rollouts), 그때마다 1시간짜리 영상을 처음부터 다시 볼 필요는 없습니다. 그래서 한번 '이해'한 영상 내용은 따로 저장(caching)해두고, 계속 재사용해서 반복 작업을 없애 속도를 더 높입니다.
- 2단계: 답을 생각하는 과정도 나눠서 하기
- AI가 답을 '생각'해내는 과정(prefilling)도 매우 복잡하고 계산이 많습니다.
- 이 과정 역시 여러 명의 일꾼(GPU)에게 작업을 잘게 나눠서 동시에 처리하게 만들어, 생각하는 속도 자체를 빠르게 만듭니다.
결론적으로, MR-SP는 AI 훈련 과정에서 가장 시간이 오래 걸리는 두 가지 작업을 병렬로 처리하고, 불필요한 반복을 없애는 방식으로 long video 훈련을 빠르고 효율적으로 만든 새로운 시스템입니다.
주인장 이해
1. 비디오를 인풋으로 받으면 여러 gpu에 부분 적으로 임베딩 시킴.
2. 각 gpu에서 임베딩된 임베딩들을 모아서 합침. (한번에 임베딩 시키면 어려우니까 이렇게 한것 같음)
3. 그 퀘스쳔을 보고 원본 비디오를 보지 않고 임베딩만 봄.
4. 답변.

