

AI바라기의 인공지능
VLM : 논문리뷰 : DoraemonGPT : Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent) 본문
VLM : 논문리뷰 : DoraemonGPT : Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent)
AI바라기 2025. 5. 6. 13:54DoraemonGPT 학습 노트
용어 설명 (Glossary)
- LLM-driven visual agents: Large Language Model을 기반으로 시각적 정보를 이해하고 작업을 수행하는 에이전트.
- Dynamic Scenes: 정적인 이미지와 달리 시간의 흐름에 따라 변화하는 장면 (주로 비디오).
- Task-related Symbolic Memory (TSM): 주어진 질문/작업과 관련된 정보만을 비디오에서 추출하여 구조화된 형태로 저장하는 메모리. 공간(space) 정보와 시간(time) 정보로 분리됨.
- Space-dominant Memory: 객체의 trajectory, description 등 공간적 속성에 중점을 둔 메모리. Multi-object tracking, segmentation 모델 등으로 추출.
- Time-dominant Memory: 비디오 전체의 시간적 흐름, 이벤트, 오디오 정보 (ASR), 캡션 등에 중점을 둔 메모리. ASR, OCR, captioning 모델 등으로 추출.
- Sub-task Tools: TSM에서 정보를 효율적으로 검색하고 특정 유형의 추론(When, Why, What, How, Count 등)을 수행하기 위해 설계된 특수 도구들. 각 도구는 개별 LLM sub-agent로 구현됨.
- Knowledge Tools: LLM 내부 지식의 한계를 보완하기 위해 외부 지식 소스(텍스트 파일, 웹 검색 등)에 접근하는 도구.
- Monte Carlo Tree Search (MCTS) Planner: 게임 AI 등에서 사용되는 탐색 알고리즘. DoraemonGPT에서는 다양한 도구 조합의 방대한 planning space를 효율적으로 탐색하고, 여러 가능한 해결책을 찾아내기 위해 사용됨. 보상(reward) 기반의 backpropagation을 통해 최적의 tool sequence를 탐색.
- Spatial-temporal Reasoning: 비디오 내에서 시간과 공간에 걸쳐 발생하는 객체, 행동, 이벤트 간의 관계를 추론하는 능력.
- Referring Video Object Segmentation: 자연어 설명(referring expression)에 해당하는 비디오 내 객체를 시간 흐름에 따라 segmentation하는 작업.
- Foundation Models: 대규모 데이터로 사전 학습되어 다양한 downstream task에 활용될 수 있는 기반 모델 (e.g., BLIP, YOLOv8, Whisper).
- Zero-shot: 특정 작업에 대해 별도의 fine-tuning 없이 pre-trained 모델을 그대로 사용하여 문제를 해결하는 방식.
- In-context Learning (ICL): LLM의 prompt 내에 몇 가지 예시(demonstration)를 제공하여 모델이 별도의 학습 없이 새로운 작업을 수행하도록 유도하는 방식.
- ReAct: Reasoning과 Acting을 결합하여 LLM이 중간 추론 과정을 생성하고 이를 바탕으로 외부 도구를 사용하거나 행동을 결정하는 프레임워크. MCTS planner의 노드 구성 방식에 영향을 줌.
- Backpropagation (in MCTS): MCTS에서 탐색 결과(leaf node)의 성공/실패 보상을 상위 노드로 전파하여 다음 탐색 방향 결정에 활용하는 과정.
Purpose of the Paper
- 기존 한계 극복: 기존 LLM 기반 visual agent들은 주로 정적 이미지(static image) 처리에 집중하여, 동적 장면(dynamic scene) 이해 능력이 부족하고 실제 애플리케이션(실험 보조, 실수 분석 등) 적용에 한계가 있음.
- 새로운 도전 과제 제시: 비디오 데이터는 (1) Spatial-temporal Reasoning의 복잡성 증가, (2) Action 및 Intention 추론으로 인한 더 큰 Planning Space, (3) 특정 도메인(과학 실험 등)에 대한 LLM의 제한된 내부 지식(Limited Internal Knowledge) 이라는 새로운 도전 과제를 야기함.
- 연구 목표: 이러한 한계를 극복하고 도전 과제를 해결하기 위해, 동적 장면(비디오)을 효과적으로 이해하고 복잡한 작업을 수행할 수 있는 포괄적이고 개념적으로 우아한 LLM 기반 시스템, DoraemonGPT를 제안함. 이는 비디오 데이터를 기반으로 추론하고 행동하는 video agent 형태로 구체화됨.
Key Contributions & Novelty
- Task-related Symbolic Memory (TSM) (§2.1):
- Contribution: 비디오 정보를 질문/작업 관련성에 따라 필터링하고, 공간(space-dominant) 정보와 시간(time-dominant) 정보로 분리하여 SQL 형태로 구조화된 메모리를 구축함.
- Novelty: 단순히 비디오 정보를 나열하는 것이 아니라, **작업 관련성(task relevance)**을 먼저 판단하고 **공간-시간 정보를 명시적으로 분리(decoupling)**하여 동적 장면에 특화된 구조화된 메모리를 생성함. 이는 LLM의 효율적인 정보 접근 및 추론을 지원함.
- Specialized Sub-task Tools & Pluggable Knowledge Tools (§2.1, §2.2):
- Contribution: 다양한 Spatial-temporal Reasoning 유형(When, Why, What 등)에 맞춰 설계된 Sub-task Tool들을 통해 TSM 쿼리를 간결화하고, 외부 지식 소스 연동을 위한 Knowledge Tool을 플러그 앤 플레이 방식으로 통합함.
- Novelty: LLM에게 직접 SQL을 생성하게 하거나 범용 도구를 사용하는 대신, 추론 유형별로 특화된 symbolic sub-task tool을 사용하여 LLM의 context 길이를 줄이고 추론 효율성을 높임. 외부 지식 통합 방식을 체계화함.
- MCTS-based Planner (§2.3):
- Contribution: 복잡한 비디오 작업의 넓은 planning space를 탐색하기 위해 Monte Carlo Tree Search (MCTS) 기반의 planner를 도입함. 이를 통해 여러 잠재적 해결책(multiple feasible solutions)을 탐색하고, 그 결과를 종합하여 최종 답변의 질을 향상시킴.
- Novelty: LLM 기반 비디오 작업 planning에 MCTS를 적용하여, 기존의 greedy search나 단순 tree search 방식보다 효과적으로 최적의 tool 사용 순서를 찾고, 단일 실패에 강하며 다양한 해결 경로를 고려할 수 있게 함.
Experimental Highlights
- Datasets: NEXT-QA, TVQA+ (Video Question Answering), Ref-YouTube-VOS (Referring Video Object Segmentation), 및 다양한 in-the-wild 시나리오.
- Metrics: VQA Task - Accuracy (Accc, Acct, Accd, Avg, Acca), Segmentation Task - J&F.
- Baselines: ViperGPT, VideoChat (LLM-driven agents), SOTA supervised 모델들.
- Key Results:
- VQA 성능: NEXT-QA, TVQA+ 데이터셋에서 경쟁 LLM agent (ViperGPT, VideoChat) 대비 월등한 성능 달성 (e.g., TVQA+에서 ViperGPT 대비 +10.2% Acc). 특히 Descriptive 질문에서 강점 (Table 2a, Fig. 5).
- Referring Video Object Segmentation 성능: Zero-shot 설정임에도 불구하고 SOTA supervised 모델(OnlineRefer)을 능가하는 성능 달성 (65.9% vs 64.8% J&F, Table 2b). 이는 TSM의 효과적인 정보 구성 및 grounding 능력을 입증.
- Ablation Study: TSM (space & time 모두 중요), MCTS planner (N>1 exploration 유리), MCTS 탐색 전략의 우수성 검증 (Table 3).
- Qualitative Results: 복잡한 실험 과정 검증, 비디오 내용 이해, 비디오 편집(inpainting) 등 다양한 in-the-wild task 처리 능력 시연 (Fig. 4, 7, 8).
Limitations and Future Work
- TSM 설계: 현재 TSM 타입 설계가 수동적이고 heuristic함. 자동화된 TSM 설계 방법 및 더 세분화된 메모리 타입 (e.g., human-centric) 연구 필요.
- Foundation Model 의존성: TSM 구축 및 도구 실행 성능이 사용된 foundation model(detection, captioning 등)의 성능에 직접적으로 의존함. 모델 예측 오류가 메모리/추론 정확도에 영향. 저조도, 블러 등 어려운 환경 데이터 처리 능력 한계.
- LLM 능력 한계: MCTS planner의 계획 및 추론 정확도는 사용하는 LLM의 능력에 제약받음. 작은 규모나 성능이 낮은 LLM 사용 시 합리적인 해결책 탐색 가능성 저하.
- 계산 비용: MCTS planner 도입으로 추가적인 계산 비용 발생. 실시간성(real-time)이 중요하거나 자원이 제한된(resource-constrained) 환경에서는 사용 제약. High-end 시스템 또는 온라인 LLM 서비스(OpenAI) 필요.
- Future Work: TSM 설계 자동화, foundation model 오류 강건성 향상, 실시간 시나리오를 위한 효율성 개선 연구.
Overall Summary
DoraemonGPT는 LLM 기반 에이전트의 적용 범위를 정적 이미지에서 동적 비디오 장면으로 확장하기 위한 포괄적인 시스템이다. 핵심 아이디어는 작업 관련 정보를 공간/시간으로 분리하여 저장하는 Task-related Symbolic Memory (TSM), 특화된 Sub-task/Knowledge Tools, 그리고 넓은 탐색 공간에서 다수의 해결책을 찾는 MCTS Planner이다. 실험 결과, 기존 LLM 에이전트 및 supervised 모델 대비 우수한 성능을 보이며 비디오 이해 및 추론 능력의 발전을 보여주었다. 이는 LLM을 활용한 동적 환경 이해 및 상호작용 연구에 중요한 기여를 할 수 있다.
쉬운 설명 (Easy Explanation)
DoraemonGPT는 비디오를 보고 질문에 답하거나 작업을 수행하는 똑똑한 비디오 에이전트입니다. 기존 에이전트들이 비디오를 정지 화면 여러 개처럼 보는 경향이 있었다면, DoraemonGPT는 비디오의 '움직임'과 '시간 흐름' 자체를 더 잘 이해하려고 합니다.
핵심 아이디어는 마치 우리가 공부할 때 노트를 정리하는 것과 비슷합니다.
- 필요한 정보만 골라 정리 (TSM): 질문을 받으면, 비디오 전체 내용 중 질문과 관련된 정보만 쏙쏙 골라냅니다. 그리고 이 정보들을 '어디서 일어났는지 (공간)'와 '언제 일어났는지 (시간)'로 주제를 나눠 깔끔하게 정리(TSM)해 둡니다.
- 특화된 검색 도구 사용 (Sub-task Tools): 정리된 노트(TSM)에서 답을 찾을 때, 그냥 막 뒤지는 게 아니라 '언제?'를 묻는 질문엔 '시간' 노트를 뒤지고, '왜?'를 묻는 질문엔 '원인/결과'를 찾는 등 질문 유형에 맞는 특화된 검색 도구(Sub-task Tools)를 사용해 효율적으로 답을 찾습니다. 모르는 내용은 외부 책(Knowledge Tools)을 찾아보기도 합니다.
- 여러 계획 시도 및 종합 (MCTS Planner): 복잡한 질문에는 한 가지 방법만 고집하지 않고, 여러 가지 가능한 계획(도구 사용 순서)들을 탐색(MCTS)해 봅니다. 마치 여러 아이디어를 브레인스토밍하고 가장 좋은 아이디어들을 모아 최종 답을 만드는 것처럼, 여러 시도 결과를 종합하여 더 정확하고 풍부한 답을 만들어냅니다.
이런 방식으로 DoraemonGPT는 복잡한 비디오 내용을 더 깊이 이해하고 다양한 질문에 더 똑똑하게 답할 수 있게 됩니다.
Abstract
최근의 LLM-driven visual agents는 주로 image-based tasks 해결에 초점을 맞추고 있으며, 이는 dynamic scenes 이해 능력을 제한하여, 실험실 실험에서 학생들을 지도하고 그들의 실수를 식별하는 것과 같은 실제 응용과는 거리가 멀게 만듭니다.
따라서, 본 논문은 dynamic scenes 이해를 위해 LLMs로 구동되는 포괄적이고 개념적으로 우아한 시스템인 DoraemonGPT를 탐구합니다. video modality가 실제 시나리오의 끊임없이 변화하는 특성을 더 잘 반영한다는 점을 고려하여, 우리는 DoraemonGPT를 video agent로 예시합니다.
question/task가 포함된 video가 주어지면, DoraemonGPT는 input video를 task-related attributes를 저장하는 symbolic memory로 변환하는 것으로 시작합니다. 이 structured representation은 잘 설계된 sub-task tools에 의한 spatial-temporal querying 및 reasoning을 가능하게 하여 간결한 intermediate results를 도출합니다.
LLMs가 specialized domains(예: 실험의 기초가 되는 과학적 원리 분석)에 관해서는 limited internal knowledge를 가지고 있다는 점을 인식하여, 우리는 external knowledge를 평가하고 다양한 domains에 걸친 tasks를 처리하기 위해 plug-and-play tools를 통합합니다.
또한, 다양한 tools의 scheduling을 위한 대규모 planning space를 탐색하기 위해 Monte Carlo Tree Search 기반의 새로운 LLM-driven planner가 도입됩니다. planner는 결과의 reward를 backpropagating하여 반복적으로 실행 가능한 솔루션을 찾으며, 여러 솔루션은 개선된 final answer로 요약될 수 있습니다.
우리는 세 가지 benchmarks와 여러 in-the-wild scenarios에서 DoraemonGPT의 효과를 광범위하게 평가합니다.
1. Introduction
large language models (LLMs)의 발전에 기반하여, 최근의 LLM-driven agents는 복잡한 image task를 관리 가능한 subtasks로 분해하고 단계별로 해결하는 가능성을 보여주었습니다. static images는 광범위하게 연구되었지만, 실제 환경은 본질적으로 dynamic하며 끊임없이 변화합니다. 일반적으로 dynamic scenes를 캡처하는 것은 data-intensive 절차이며, 대개 static images를 videos로 스트리밍하여 처리됩니다. 결과적으로, videos의 spatial-temporal reasoning은 실제 생활에서의 recognition, semantic description, causal reasoning 등에서 중요합니다.
dynamic scenes 이해를 위해, videos를 처리하는 LLM-driven agents 개발은 매우 중요하지만 큰 도전 과제들을 수반합니다: i) Spatial-temporal Reasoning. instances 간의 관계에 대한 Reasoning은 task decomposing 및 decision-making에 중요합니다. 이러한 관계는 space, time 또는 이들의 spatial-temporal combination과 관련될 수 있습니다. ii) 더 큰 Planning Space. image modality와 비교할 때, actions 및 그 intentions에 대한 high-level semantics는 일반적으로 temporal visual observations에서만 추론될 수 있습니다. 즉, temporal semantics의 inference는 필요하며 dynamic video tasks 분해의 search space를 확장할 것입니다. iii) Limited Internal Knowledge. LLMs는 실제 세계의 끊임없이 변화하는 특성 및/또는 proprietary datasets 학습 부족으로 인해 모든 video 이해에 필요한 모든 knowledge를 encode할 수 없습니다.
앞선 논의에 비추어, 우리는 다양한 foundation models 및 applications와 호환되는 직관적이면서도 다재다능한 LLM-driven system인 DoraemonGPT를 제시합니다. video agent로 예시되는 DoraemonGPT는 세 가지 바람직한 능력을 갖추고 있습니다: 첫째, reasoning 전에 주어진 task에 관한 정보 수집. DoraemonGPT에서 주어진 dynamic task의 분해는 instance locations, actions, scene changes 등과 같은 informative attributes로부터 추론되는 spatial-temporal relations의 agent-based reasoning에 의해 결정됩니다. 그러나 과도한 context 수집은 LLMs의 capability를 저해하는 경향이 있으므로, task-solving 관련 정보만이 중요하다는 점에 유의해야 합니다. 둘째, decisions을 내리기 전에 더 나은 solutions 탐색. LLM-driven planning은 high-level tasks를 sub-tasks 또는 action sequences로 분해합니다. action sequence를 가능한 모든 sequences를 포함하는 tree 내의 root-to-leaf path로 간주할 때, planning은 tree-like search space에서 optimal decisions을 찾는 것으로 볼 수 있습니다. dynamic scenes에서 tasks를 해결하기 위한 큰 planning space와 관련하여, tree-like search methods로 LLMs를 prompting하는 것은 더 나은 solutions의 기회를 제공하며 심지어 다른 관점에서 tasks를 고려할 가능성까지 열어줍니다. 셋째, knowledge extension 지원. 인간이 domain-specific issues를 해결하기 위해 참고 서적을 참조하는 것처럼, DoraemonGPT는 주어진 일련의 external knowledge sources(예: search engines, textbooks, databases 등) 중에서 가장 관련성이 높은 knowledge source를 선택한 다음 planning 중에 해당 소스로부터 정보를 query하도록 설계되었습니다.
더 구체적으로, DoraemonGPT는 ⟨memory, tool, planner⟩ 구조를 가집니다 (Fig. 1c): i) Task-related Symbolic Memory (§2.1). 주어진 video 및 task와 관련된 정보를 수집하기 위해, 우리는 spatial-temporal attributes를 space-dominant와 time-dominant라는 두 개의 memories로 decoupling하는 것을 고려합니다. 이 memories를 구축하기 전에, LLMs를 사용하여 주어진 task와의 relevance를 결정하고 유용한 것만 유지합니다. 그런 다음 Foundation models를 사용하여 space-dominant attributes(예: instance trajectory, description 등) 또는 time-dominant attributes(예: video descriptions, audio speech 등)를 추출하고 이를 query table로 통합합니다. 이는 LLMs가 symbolic language(예: SQL language)를 사용하여 정보에 access하는 것을 용이하게 합니다. ii) Sub-task (§2.1) 및 Knowledge (§2.2) Tools. planner의 context/text length를 압축하고 effectiveness를 향상시키기 위해, 우리는 일련의 sub-task tools를 설계하여 memory information querying을 단순화합니다. 각 tool은 task-specific prompts 및 examples를 사용하는 개별 LLM-driven sub-agents를 통해 다양한 종류의 spatial-temporal reasoning(예: “How...”, “Why...” 등)에 초점을 맞춥니다. 또한, 전용 knowledge tools는 domain-specific knowledge가 필요한 tasks를 위해 external sources를 통합할 수 있습니다. iii) Monte Carlo Tree Search (MCTS) Planner (§2.3). 큰 planning space를 효율적으로 탐색하기 위해, 우리는 새로운 tree-search-like planner를 제안합니다. planner는 답의 reward를 backpropagating하고 확장성이 높은 node를 선택하여 새로운 solution을 확장함으로써 반복적으로 feasible solutions를 찾습니다. 모든 결과를 요약한 후, planner는 유익한 final answer를 도출합니다. tree search planner를 설계하기 위해, 우리는 DoraemonGPT에 MCTS를 장착했습니다. MCTS는 특히 game AI 커뮤니티에서 large search space로부터 optimal decisions을 찾는 데 effectiveness를 보여주었습니다.
위의 설계를 결합하여, DoraemonGPT는 dynamic spatial-temporal tasks를 효과적으로 처리하고, 여러 potential solutions의 포괄적인 exploration을 지원하며, multi-source knowledge를 활용하여 전문성을 확장할 수 있습니다. 세 가지 benchmarks에 대한 광범위한 실험은 우리의 DoraemonGPT가 causal/temporal/descriptive reasoning 및 referring video object recognition에서 최근 LLM-driven competitors(예: ViperGPT)를 상당히 능가함을 보여줍니다. 또한, 우리의 MCTS planner는 단순 searching method 및 다른 baselines를 능가합니다. 더욱이, DoraemonGPT는 이전 approaches에서는 적용할 수 없거나 무시되었던 더 복잡한 in-the-wild tasks를 처리할 수 있습니다.
DoraemonGPT Introduction: 정리 노트 (AI 연구자용)
핵심 문제:
- 기존 LLM-driven visual agents는 주로 static images에 초점. Real-world dynamic scenes (e.g., 실험 지도) 이해 능력 부족.
- Video는 dynamic scene 이해에 필수적이나, LLM agent가 처리하기엔 큰 도전 과제 존재.
주요 도전 과제 (Challenges for Video Agents):
- Spatial-temporal Reasoning: 시간과 공간에 걸친 instance/action 관계 reasoning의 복잡성 (Task 분해 및 decision-making에 필수).
- Larger Planning Space: Image 대비 video는 temporal semantics (actions, intentions) 추론이 필요하며, 이는 task 분해 시 search space를 크게 확장시킴.
- Limited Internal Knowledge: LLM은 real-world의 모든 변화나 proprietary datasets에 대한 학습 부족으로 모든 video 이해에 필요한 domain-specific knowledge를 갖추기 어려움.
제안 시스템: DoraemonGPT
- Dynamic scene 이해를 위한 LLM-driven system (video agent로 예시).
- 핵심 구조: ⟨memory, tool, planner⟩
DoraemonGPT의 주요 특징 및 기여:
- Task-Relevant 정보 수집 및 Symbolic Memory:
- Reasoning 전, 주어진 task와 관련된 정보만 선별적 수집 (LLM capability 저하 방지).
- Spatial-temporal attributes를 space-dominant/time-dominant memory로 분리 (decoupling).
- LLM으로 task relevance 판단 후 유용한 정보만 저장.
- Foundation models로 attributes 추출 후 queryable table (symbolic memory, e.g., SQL) 형태로 저장하여 LLM의 효율적 access 지원.
- MCTS 기반 Planner:
- Video task의 large planning space를 효과적으로 탐색하기 위해 Monte Carlo Tree Search (MCTS) 기반 planner 도입.
- Iterative하게 feasible solutions 탐색 (reward backpropagation, node expansion).
- 다양한 solution 경로 탐색 및 최종 요약을 통해 개선된 final answer 도출. Tree-search 방식으로 다양한 관점에서의 task 고려 가능성 제시.
- Knowledge Extension & Modular Tools:
- Plug-and-play 방식의 knowledge tools를 통해 external knowledge sources (search engines, textbooks 등) 활용. Domain-specific knowledge 부족 문제 해결.
- Sub-task tools: 특정 유형의 spatial-temporal reasoning("How", "Why" 등)을 전담하는 LLM-driven sub-agents 활용. Memory querying 단순화 및 planner의 context 길이 축소, effectiveness 향상.
주요 성과 (Claimed):
- Dynamic spatial-temporal tasks 효과적 처리.
- Multiple potential solutions의 포괄적 exploration 지원.
- Multi-source knowledge 활용 가능.
- 기존 LLM-driven competitors (e.g., ViperGPT) 대비 benchmarks (causal/temporal/descriptive reasoning, referring video object recognition)에서 우수한 성능.
- MCTS planner가 naïve search 등 baselines 대비 우월.
- 기존 approaches로 처리 어려웠던 복잡한 in-the-wild tasks 처리 가능.
쉬운 설명: Introduction 섹션
AI가 사진뿐만 아니라 동영상까지 이해하도록 만드는 연구예요. 우리가 실생활에서 겪는 일들은 대부분 정지된 사진보다는 움직이는 동영상에 가깝잖아요? 예를 들어 실험 과정을 보거나 스포츠 경기를 분석하는 것처럼요.
그런데 동영상을 이해하는 건 사진보다 훨씬 어려워요. 왜냐하면:
- 시간과 공간: 동영상 속에서는 물건들이 움직이고 상황이 계속 변해요. 언제 어디서 무슨 일이 일어나는지 파악하는 게 복잡해요.
- 더 많은 경우의 수: 동영상 속 행동의 의도나 이유를 알아내려면 고려해야 할 것들이 훨씬 많아져요. 마치 복잡한 미로 찾기처럼요.
- 전문 지식 부족: AI가 세상의 모든 지식, 특히 특정 분야(예: 과학 실험 원리)의 전문 지식을 다 알 수는 없어요.
그래서 이 논문에서는 "DoraemonGPT"라는 새로운 AI 시스템을 제안해요. 이 시스템은 동영상 이해의 어려움을 해결하기 위해 다음과 같은 똑똑한 방법을 사용해요:
- 핵심 정보만 쏙쏙: 동영상과 질문이 주어지면, 질문에 답하는 데 꼭 필요한 정보(누가, 무엇을, 어디서, 어떻게 등)만 골라서 기억해요. 쓸데없는 정보까지 다 보지 않아서 AI가 헷갈리지 않아요.
- 최적의 경로 탐색 (MCTS 계획): 동영상 속 복잡한 상황을 분석하고 질문에 답하기 위해, 마치 여러 갈래 길을 탐색하듯 다양한 방법(solution)을 찾아봐요. 그중에서 가장 좋은 답을 찾아내거나 여러 답을 종합해서 더 나은 최종 답을 만들어요.
- 외부 전문가 찬스: AI가 스스로 모르는 내용(예: 특정 과학 지식)이 나오면, 마치 우리가 책이나 인터넷을 찾아보듯 외부 정보(검색 엔진, 데이터베이스 등)를 활용해서 답을 찾아요.
결론적으로 DoraemonGPT는 동영상 속 복잡한 상황을 더 잘 이해하고, 다양한 해결책을 탐색하며, 필요할 땐 외부 지식까지 활용할 수 있도록 설계된 AI 시스템이라고 할 수 있습니다.
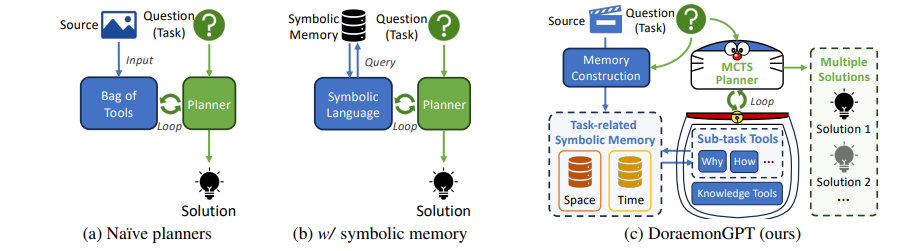
Figure 1. (a) 단순한(Naïve) LLM-driven planners는 static image task를 일련의(sequence) tool executions로 분해하지만, real-world 환경은 본질적으로 dynamic합니다. (b) symbolic memory를 사용하는 Planners는 external knowledge를 검색하기 위해 symbolic languages를 생성합니다. (c) task가 주어진 dynamic video에 대해, 우리의 DoraemonGPT (§2)는 spatial-temporal attributes를 task-related memories로 분리(decouples)합니다. symbolic languages를 직접 생성하는 대신, 다양한 spatial-temporal reasoning을 위한 여러 sub-task (symbolic) tools와 다른 tools(예: external knowledge 검색용)가 task 해결을 위해 planned됩니다. MCTS planner를 통해 DoraemonGPT는 큰 planning spaces를 탐색하고, potential solutions를 찾으며, 개선된 final answer를 제공할 수 있습니다.

Figure 2. Overview. question/task가 주어진 video에 대해, DoraemonGPT는 먼저 Task-related Symbolic Memory (§2.1)를 추출합니다. 이는 두 가지 types를 가집니다: instances 기반의 space-dominant memory와 time frames/clips 기반의 time-dominant memory. 이 memory는 다양한 reasoning을 위해 LLM-driven sub-task tools에 의해 queried될 수 있습니다. 또한, external knowledge (§2.2)를 querying하기 위한 다른 tools나 utility tools도 지원됩니다. planning을 위해, 우리의 MCTS Planner (§2.3)는 N개의 feasible solutions를 exploring하여 question을 action sequence로 decomposes하며, 이는 추가적으로 informative answer로 summarized될 수 있습니다.
2. DoraemonGPT
Overview. Fig. 2에서 볼 수 있듯이, DoraemonGPT는 다양한 tools를 활용하여 복잡한 dynamic video task를 sub-tasks로 decompose하고 해결할 수 있는 LLM-driven agent입니다. textual task/question ()가 주어진 video ()에 대해, DoraemonGPT는 먼저 의 task analysis를 기반으로 에서 Task-related Symbolic Memory (§2.1)를 추출합니다. 다음으로, Monte Carlo Tree Search (MCTS) Planner (§2.3)를 사용하여 DoraemonGPT는 symbolic memory querying, external knowledge (§2.2) accessing, 그리고 다른 utility tools (video inpainting 등) 호출을 위한 tool sets를 자동으로 schedules하여 question 를 해결합니다. 궁극적으로, planner는 큰 planning space를 탐색하고, 여러 가능한 answers를 반환하며, 개선된 answer를 summarize합니다.
2.1. Task-related Symbolic Memory (TSM) Videos는 spatial-temporal relations를 포함하는 복잡한 dynamic data입니다. video 에 대한 question 가 주어졌을 때, 관련 없는 정보가 방대함에도 불구하고 solution에는 관련된 attributes의 일부만이 중요합니다. 따라서 우리는 를 해결하기 전에 와 관련하여 잠재적으로 관련된 video information을 TSM으로 extract하고 store할 것을 제안합니다.
TSM Construction. TSM을 construct하기 위해, 우리는 question 를 기반으로 TSM의 task type을 선택하는 간단한 in-context learning 방법을 사용합니다. 우리는 각 TSK type의 task description을 우리의 LLM-driven planner의 context에 배치하며, 이는 “Action: ⟨TSM type⟩ construction...”과 같은 format으로 적합한 TSM을 predict하도록 prompted될 것입니다. 그런 다음, 해당 TSM constructing을 위한 API가 호출되어 task-related attributes를 extract하고 이를 SQL table에 store합니다. 이 테이블은 symbolic languages, 즉 SQL로 accessed될 수 있습니다.
video tasks를 categorizing하는 표준화된 criterion은 없습니다. DoraemonGPT에서는 video representation learning에서 널리 적용되어 온 spatial-temporal decoupling의 perspective를 선택하여 두 가지 memory types를 design합니다:
- Space-dominant memory는 주로 특정 targets (예: persons 또는 animals) 또는 그들의 spatial relations과 관련된 questions를 address하는 데 사용됩니다. 우리는 multi-object tracking methods를 사용하여 instances를 detect하고 track합니다. 각 instance는 unique ID, semantic category, localization을 위한 trajectory & segmentation, text-based grounding을 위해 extracted되고 사용되는 appearance description, 그리고 action classification을 포함하는 attributes를 갖습니다.
- Time-dominant memory는 video의 temporal-related information을 constructing하는 데 중점을 둡니다. 이는 video 전체의 content를 comprehending해야 합니다. 이 memory에 stored된 attributes는 timestamp, ASR에 의한 audio content, OCR에 의한 optical content, BLIPs에 의한 frame-level captioning, 유사하고 연속적인 frame-level results를 dedupicating하여 얻은 clip-level captioning 등을 포함합니다.
Table 1은 우리의 TSMs의 해당 extraction models과 함께 attribute types를 제공합니다.
Sub-task Tools. 비록 LLM-driven agents가 전체 memory의 in-context learning이나 memory access를 위한 symbolic sentences generating을 통해 external information을 assess할 수 있지만, 이러한 methods는 context의 길이를 상당히 increase시켜 reasoning process에서 crucial information의 omission을 초래하거나 redundant context에 의해 influenced될 가능성이 있습니다. 따라서 우리는 sub-task questions에 answering함으로써 우리의 TSMs에서 information을 querying하는 역할을 담당하는 일련의 sub-task tools를 제공합니다. LLM-driven planner는 sub-task description, tool name, 및 tool inputs를 기술하는 그것의 in-context description을 통해 각 sub-task tool의 function을 learns합니다.
sub-task tool의 API를 call하기 위해, DoraemonGPT는 LLMs에 의해 generated된 command, 예를 들어 “Action: ⟨tool name⟩. Input: ⟨video name⟩#⟨sub question⟩...”를 parses합니다.
위의 두 종류의 TSMs와 collaborate하기 위해, 우리는 다른 sub-task description을 가지며 다른 sub-questions를 solving하기 위한 sub-task tools를 design합니다. 여기에는 다음이 포함됩니다:
- When: temporal understanding과 관련된 것, 예: “개가 소파 옆을 지나갈 때가 언제인가?”
- Why: causal reasoning과 관련된 것, 예: “왜 그 여자는 장난감을 흔들었는가?”
- What: required information을 describing하는 것, 예: “실험의 이름은 무엇인가?”
- How: 어떤 방식, 수단 또는 특성, 예: “아기는 어떻게 자신을 안전하게 지키는가?”
- Count: 무언가를 counting하는 것, 예: “방 안에 몇 명의 사람이 있는가?”
- Other: 위의 tools에 해당하지 않는 questions, 예: “누가 마지막에 더 멀리 미끄러졌는가?”
이 tools의 API functions 또한 LLMs를 기반으로 built됩니다. 각 sub-task tool function은 개별적인 LLM-driven agent이며, 이는 우리의 TSMs를 query하기 위해 SQL을 generate하고 주어진 sub-task question에 answer할 수 있습니다. 다른 sub-task agents는 그들의 purposes에 맞는 다른 in-context examples를 가집니다. sub-question이 두 개 이상의 sub-tools에 suitable할 수 있으며 (예: "아기가 장난감을 가지고 놀기 전에 무엇을 하고 있었나?", what과 when 관련), 우리의 MCTS planner (§2.3)는 다른 selections를 exploring할 수 있습니다.
2.2. Knowledge Tools and Others complex problems를 다룰 때, LLM-driven agents는 때때로 video understanding과 training 중 LLMs에 의해 learned된 implicit knowledge에만 solely based하여 accurate decisions를 make하는 데 fail합니다. 따라서 DoraemonGPT는 LLM이 input video/question 내의 specialized content를 comprehending하는 것을 assist할 수 있는 external knowledge sources의 integration을 supports합니다. DoraemonGPT에서, knowledge source는 개별 knowledge tool을 사용하여 plug-and-play manner로 integrated될 수 있습니다. sub-task tools (§2.1)와 Similar하게, knowledge tool은 두 parts로 consists됩니다: i) 주어진 knowledge source를 describe하는 in-context knowledge description과 ii) question answering을 통해 source로부터 information을 query하는 API function.
우리는 다른 knowledge를 covering하기 위해 세 가지 types의 API function을 consider합니다: i) symbolic knowledge는 Excel 또는 SQL tables와 같은 structured format으로 presented된 information을 말합니다. API function은 우리의 sub-task tools (§2.1)와 같은 symbolic question-answering sub-agent입니다. ii) textual knowledge는 research publications, reference books 등과 같이 natural language text를 통해 expressed된 knowledge를 encompasses합니다. API function은 text embedding 및 searching을 기반으로 built됩니다. iii) web knowledge는 internet에서 searched된 knowledge를 denotes합니다. API function은 Google, Bing 등과 같은 search engine API입니다. knowledge tools 외에도, DoraemonGPT는 video editing 및 inpainting과 같은 specialized vision tasks를 complete하는 데 help하기 위해 recent LLM-driven agents에서 commonly used되는 general utility tools의 integrating 또한 supports합니다.
2.3. Monte Carlo Tree Search (MCTS) Planner Previous LLM-driven planners는 주어진 를 action/sub-task sequence로 decompose하고 step by step으로 solve합니다. 이러한 strategy는 final answer까지 action nodes의 chain을 generates하는 greedy search method로 볼 수 있습니다. 일부 works와 Similar하게, 우리는 LLM-driven planning의 large planning space를 tree로 consider합니다. 더욱이, 우리는 single attempt가 correct result를 yield하지 못하거나 better solutions가 exist할 수 있다고 consider합니다. planning space를 efficiently explore하기 위해, 우리는 large trees searching에 practical한 MCTS를 equipped한 novel tree-search-like planner를 propose합니다.
우리는 question input 를 root node 로 define하고, action 또는 tool call은 non-root node이며, action sequence는 root node에서 leaf node까지의 path로 viewed될 수 있습니다. 우리의 MCTS planner에서, non-root node는 ⟨thought, action, action input, observation⟩ 형태의 ReAct-style step이며, leaf node는 추가적으로 final answer를 가집니다.
planner는 다음 네 phases를 times 동안 iteratively executes하고 개의 solutions를 produces합니다:
Node Selection. 각 iteration은 new solution을 planning하기 위한 expandable node를 selecting하는 것으로 starts합니다. 첫 iteration에서는 root 만이 selectable합니다. 후속 iterations에서는, sampling probability 에 based하여 non-leaf node를 randomly select합니다. 여기서 는 node 의 reward value이며, 0으로 initialized되고 Reward Back-propagation phase에서 updated됩니다. higher reward를 가진 node는 selected될 probability가 더 큽니다.
Branch Expansion. new branch를 create하기 위해 selected expandable node에 child가 added될 것입니다. previous child nodes와 different한 new tool call을 generating하기 위해 LLM을 leverage하기 위해, 우리는 historical tool actions를 LLM의 prompt에 add하고 different choice를 make하도록 instruct합니다. 이러한 in-context prompt는 new final answer를 향한 후속 chain execution에서 removed될 것입니다.
Chain Execution. new branch를 expanding한 후, 우리는 step-wise LLM-driven planner를 사용하여 new solution을 generate합니다. execution process는 tool calls의 steps/nodes chain으로 consists되며, final answer를 obtaining하거나 execution error를 encountering하면 terminate됩니다.
Reward Back-propagation. leaf/outcome node 를 obtaining한 후, 우리는 그것의 reward를 까지 ancestor nodes로 gradually propagate할 것입니다. 여기서 우리는 두 kinds의 reward를 consider합니다:
- Failure: planner가 failed tool call 또는 incorrect result format과 같은 unexpected result를 produces합니다. 이 경우 reward 은 negative value (예: -1)로 set됩니다.
- Non-failure: planner가 successfully result를 produces하지만, 그 result가 ground truth로서 correct한지는 not sure합니다. 여기서 은 positive value (예: 1)로 set됩니다.
simplicity를 위해, 를 positive base reward라고 할 때, 우리는 Failure와 Non-failure에 대해 각각 로 set합니다. LLMs에 의해 produced된 outcome은 beginning의 context (the initial prompts)와 end (the final nodes)에 더 related되어 있습니다. 우리는 에 close한 nodes에 more rewards가 applied되어야 한다고 believe합니다. 따라서, backpropagation function은 로 formulated됩니다. 여기서 은 와 사이의 node distance를 denotes하고, 는 reward의 decay rate를 controlling하는 hyperparameter입니다. node distance가 further할수록, reward decay ratio 는 greater해집니다. Commonly, higher 를 setting하면 expanded node가 (non-failure answer의) leaf node에 approaching할 probability가 increase합니다.
모든 MCTS iterations 후에, planner는 최대 개의 non-failure answers를 produce할 것이며, 우리는 LLMs를 사용하여 모든 answers를 summarize하여 informative answer를 generate할 수 있습니다. Alternatively, single-/multiple-choice questions의 경우, 우리는 voting process를 통해 final answer를 determine할 수 있습니다.
DoraemonGPT Section 2: 정리 노트 (AI 연구자용)
Overall Architecture (전체 구조):
- DoraemonGPT: dynamic video task 분해(decomposition) 및 해결을 위한 LLM-driven agent.
- Workflow (작동 흐름): 입력 + -> Task Analysis -> TSM (§2.1) 추출(Extraction) -> MCTS Planner (§2.3) -> Tool Scheduling (TSM Querying, External Knowledge (§2.2), Utility Tools) -> 다중 Solutions -> 요약된(Summarized) Final Answer.
2.1 Task-related Symbolic Memory (TSM)
- 핵심 아이디어 (Core Idea): Planning 전에 에서 task 관련(-relevant) attributes만 사전 추출(Pre-extract)하여 구조화되고 query 가능한 memory (SQL table)에 저장(store). Video data 복잡성 및 관련 없는 context 문제 해결.
- 구축 (Construction):
- LLM planner가 기반의 in-context learning을 통해 TSM type (Space-dominant/Time-dominant) 선택. ("Action: ⟨TSM type⟩ construction..." format 예측)
- 전용 APIs가 특정 extraction models (Table 1 참조)를 사용하여 선택된 TSM type을 구축(construct).
- Memory Types (Spatial-Temporal Decoupling 관점):
- Space-dominant: Instances/objects 및 spatial relations에 초점. Multi-Object Tracking (MOT) 사용. Attributes: Instance ID, semantic category, trajectory/segmentation (localization용), appearance description (text-based grounding용), action classification.
- Time-dominant: Temporal information 및 video 전체 content에 초점. Attributes: Timestamp, ASR content, OCR content, frame/clip captions (BLIPs, deduplication).
- Sub-task Tools:
- 목적 (Purpose): Planner context 과부하 또는 planner의 직접적인 symbolic language 생성 요구 없이 TSMs를 효율적으로 query. 특정 reasoning 중심의 sub-questions 답변에 특화 설계.
- 메커니즘 (Mechanism): 미리 정의된 tools 세트 (When, Why, What, How, Count, Other). Planner는 in-context description (sub-task 설명, tool 이름, input 명시)에서 학습한 function에 따라 tool API ("Action: ⟨tool name⟩. Input: ...") 호출.
- 구현 (Implementation): 각 tool은 관련 TSM (Space/Time-dominant)을 query하기 위해 SQL을 generate하고 특정 sub-question type에 answer하는 독립적인(independent) LLM-driven agent. (각 tool은 목적에 맞는 다른 in-context examples 사용). MCTS planner는 sub-question이 여러 tools에 해당할 경우 모호성(ambiguity) 처리.
2.2 Knowledge Tools and Others
- 목적 (Purpose): 또는 에 필요한 domain-specific 정보나 누락된 정보를 위해 LLM의 internal knowledge를 external sources로 보강(Augment).
- 메커니즘 (Mechanism): 개별 tools를 통한 Plug-and-play 방식 integration. 각 tool은 in-context description (knowledge source 설명)과 query API 보유.
- Knowledge/API Types:
- Symbolic: 구조화된(Structured) data (Excel/SQL). API: Symbolic question-answering sub-agent (sub-task tool과 유사).
- Textual: 비구조화된(Unstructured) text (논문, 책). API: Text embedding & search 기반.
- Web: 인터넷 knowledge. API: Search engine API (Google, Bing).
- Utility Tools: 표준 vision tools (예: video inpainting, editing) 통합 지원.
2.3 Monte Carlo Tree Search (MCTS) Planner
- 핵심 아이디어 (Core Idea): LLM planning space를 tree로 간주하고 MCTS를 사용하여 이 large space를 효율적으로 explore. Greedy sequential planners의 한계 (잠재적 failure, suboptimal solutions) 극복.
- Tree 구조 (Structure): Root = . Non-root node = Tool call (ReAct-style: ⟨thought, action, input, observation⟩). Path = Action sequence. Leaf node = Final answer를 포함하는 노드.
- MCTS 반복 프로세스 (Iterative Process) ( iterations -> solutions):
- Node Selection: 누적된 reward 기반의 sampling probability 에 따라 확장 가능한(expandable) node 선택. 높은 reward는 높은 선택 확률 의미.
- Branch Expansion: 선택된 node에 새로운 child node (tool call) 추가. 형제 노드(siblings)와 다른 tool 선택을 장려하기 위해 history 포함하여 LLM에 prompt. (해당 prompt는 이후 chain execution에서 제거)
- Chain Execution: 새로운 branch에서 step-wise LLM planner (ReAct)를 사용하여 final answer 또는 error 발생 시까지 plan (tool calls의 chain) 실행.
- Reward Back-propagation: Leaf node 의 reward 을 조상(ancestors) 노드 (까지)로 전파.
- (Failure: tool error, 잘못된 format).
- (Non-failure: 성공적 실행, 정답 여부는 불확실).
- Update 규칙: . Reward는 거리 에 따라 지수적(exponentially) 감쇠 (로 조절). 성공적인 경로(leaf node) 근처 탐색(exploration) 집중. (높은 는 성공적인 leaf node 근처 확장 확률 증가)
- 최종 결과 (Final Output): 최대 개의 non-failure answers를 LLM으로 summarize하여 informative answer 생성. 또는 multiple-choice tasks의 경우 voting 사용.
쉬운 설명: Section 2 (DoraemonGPT 작동 방식)
이 섹션은 DoraemonGPT가 비디오를 보고 질문에 답하기 위해 내부적으로 어떻게 작동하는지 자세히 설명해요. 크게 세 부분으로 나눌 수 있어요.
1. 비디오 내용 똑똑하게 노트 정리하기 (TSM: Task-related Symbolic Memory)
- 핵심: 비디오에는 정보가 너무 많으니까, AI는 질문과 관련된 중요한 내용만 쏙쏙 뽑아서 미리 노트를 만들어요. 마치 시험공부할 때 요점 정리하는 것과 같아요.
- 정리 방식: 노트는 두 종류로 만들어요.
- '누가/무엇이/어디서' 노트 (Space-dominant): 비디오에 나오는 사람이나 사물, 위치, 움직임 등을 정리해요.
- '언제/무슨 일이' 노트 (Time-dominant): 시간 순서대로 어떤 장면이 나오고, 어떤 소리가 들리고, 어떤 자막이 나오는지 등을 정리해요.
- 노트 활용법 (Sub-task Tools): 이렇게 정리된 노트를 바로 AI에게 다 보여주는 게 아니라, '언제?', '왜?', '몇 개?' 같은 특정 질문에 답하는 **'미니 전문가(Sub-task Tools)'**들을 이용해요. 이 전문가들이 노트를 보고 필요한 정보만 찾아서 알려주는 거죠. 이렇게 하면 AI가 덜 헷갈리고 효율적으로 정보를 찾을 수 있어요.
2. 필요할 때 외부 도움 받기 (Knowledge Tools)
- 핵심: AI가 비디오나 자체 지식만으로는 답을 모를 때가 있어요 (예: 전문 과학 지식). 그럴 때는 외부 전문가나 자료를 찾아봐야 해요.
- 도움 종류: DoraemonGPT는 여러 종류의 **'외부 도움 도구(Knowledge Tools)'**를 가지고 있어요.
- 표나 데이터베이스 같은 정형 데이터 전문가.
- 논문이나 책 같은 텍스트 문서 전문가.
- 구글 같은 인터넷 검색 전문가.
- 기타 도구: 필요하다면 비디오 편집 같은 **다른 유용한 도구(Utility Tools)**도 사용할 수 있어요.
3. 최고의 계획 세우기 (MCTS Planner)
- 핵심: 이게 DoraemonGPT의 진짜 '두뇌'예요. 어떤 순서로 '미니 전문가'나 '외부 도움 도구'를 사용해야 질문에 가장 잘 답할 수 있을지 최고의 계획을 세우는 역할을 해요.
- 계획 방식 (MCTS): 단순히 한 가지 계획만 세우는 게 아니라, 마치 게임에서 여러 가지 수를 미리 내다보듯이 **다양한 계획(경로)**을 탐색해요.
- 탐색: 여러 번(N번) 다른 방식으로 도구들을 조합해서 실행해 봐요.
- 학습: 각 방법이 성공적으로 끝났는지(실패했는지) 보고 '보상(Reward)'을 줘요. 성공적인 경로에 가까울수록 더 많은 보상을 줘서, 그쪽 경로를 더 탐색하도록 유도해요.
- 결정: 이렇게 여러 계획을 시도하고 학습한 결과를 바탕으로, 가장 좋아 보이는 계획들을 종합해서 최종 답변을 만들어요. 객관식 문제라면 가장 많이 나온 답을 고를 수도 있고요(voting).
요약: DoraemonGPT는 비디오를 보고 질문을 받으면, (1) 필요한 정보만 뽑아 노트를 만들고 (TSM), (2) 이 노트를 바탕으로 '미니 전문가(Sub-task Tools)'들이 답을 찾거나 (3) 필요하면 '외부 도움(Knowledge Tools)'을 받으며, (4) 이 모든 과정을 'MCTS'라는 똑똑한 계획 전문가가 여러 가능성을 탐색하고 조율하여 최종 답을 찾아내는 방식으로 작동합니다.
- 비디오 + 질문 입력받기
- 질문에 답하는 데 필요한 정보만 쏙쏙 뽑아서 '요약 노트'(TSM) 만들기
- 그 '요약 노트'와 여러 '전문 도구'(Sub-task tool, Knowledge tool 등)를 활용해서
- '똑똑한 계획 전문가'(MCTS Planner)가 최적의 답을 찾기 위해 여러 방법을 탐색하고 실행해 보고
- 그 과정을 거쳐 최종 답변을 딱! 내놓는 것
MCTS과정중에 노드의 보상이 업데이트 되는데 그게 정답 여부와는 다르게, 툴의 성공 여부로만 보상이 업데이트가 되고, 그러면서 안정적인 path를 찾아 갈 수 있도록 가이드하는 mcts이다.
하지만 적절성이 안맞는다는 문제가 있지만 그것은 llm 플래너가 해야할 일이다.
"하나의 거대 VLM이 모든 것을 다 하는 것이 아니라, 중심적인 LLM이 여러 시각/음성 전문 모듈(팀원)들과 협력하여 얻은 정보(TSM)를 바탕으로, 주어진 질문에 맞춰 비디오를 이해하고 답을 찾아가는 방식"
이것이 DoraemonGPT의 핵심 접근 방식이라고 볼 수 있습니다. LLM이 '지휘자' 또는 '프로젝트 매니저' 역할을 하고, 다른 전문 모델들이 각자의 역할을 수행하여 비디오 이해라는 공동 목표를 달성하는 구조인 것이죠.

