

AI바라기의 인공지능
VLM : 논문리뷰 : Visual Position Prompt for MLLM based Visual Grounding 본문
MLLM 기반 Visual Grounding을 위한 Visual Position Prompt 학습 노트
연구 목적 (Purpose of the Paper)
- 문제점: Multimodal Large Language Models (MLLMs)는 다양한 이미지 관련 task에서 뛰어난 성능을 보이지만, 정밀한 공간 추론 및 visual grounding에는 어려움을 겪음. 이는 명시적인 공간 참조가 부족하고, 미세한 공간 정보보다 전역적인 context를 우선시하기 때문.
- 목표: 명시적인 위치 참조를 제공하여 MLLMs의 visual grounding 능력을 향상시키고, 텍스트 설명과 이미지 위치 간의 정확한 연관성을 가능하게 함.
- 기존 연구와의 차별성: 더 큰 datasets이나 추가적인 decoders를 사용하는 기존 방법과 달리, Visual Position Prompt (VPP)를 도입하여 학습 데이터나 모델 복잡성을 크게 늘리지 않고도 공간 인식을 향상시킴.
핵심 기여 (Key Contributions)
- VPP-LLaVA: Visual Position Prompt (VPP)를 갖춘 MLLM으로, grounding 능력을 향상시킴.
- 두 가지 상호 보완적인 메커니즘:
- Global VPP: 입력 이미지에 학습 가능한 축과 유사한 embedding을 오버레이하여 구조화된 공간 단서를 제공.
- Local VPP: DETR 기반 generator로부터 position-aware queries를 통합하여 미세한 localization에 초점을 맞추고, 가능한 객체 위치를 제안.
- VPP-SFT Dataset: 효율적인 모델 학습을 위해 고품질 visual grounding 데이터를 통합한 compact (0.6M samples) dataset. 다른 모델들이 훨씬 더 큰 datasets (~21M samples)을 필요로 하는 것과 대조적.
- Novelty: 다른 MLLM들과 다르게, 추가적인 특별한 decoder 없이 Global 및 Local VPP를 사용하는 pure MLLM.
실험 결과 (Experimental Highlights)
- State-of-the-Art 성능: 훨씬 적은 학습 샘플 (0.6M vs. MiniGPT-v2의 21M)을 사용했음에도 불구하고 표준 grounding benchmarks (RefCOCO, RefCOCO+, RefCOCOg)에서 state-of-the-art 성능 달성.
- 뛰어난 효율성: 다른 MLLMs에 비해 강력한 성능을 유지하면서도 뛰어난 효율성을 입증.
- 주요 Datasets: RefCOCO, RefCOCO+, RefCOCOg, ReferIt.
- Metrics: IoU threshold 0.5를 사용한 정확도.
- Baselines: OFA-L, TransCP, MDETR, UNINEXT-L, KOSMOS-2, Shikra, Ferret, GroundingGPT, MiniGPT-v2, Qwen-VL, PINK, Groma, Lion.
- 정량적으로, 훨씬 더 큰 datasets과 visual encoders를 사용하는 specialist 및 generalist 모델을 능가.
한계점 및 향후 연구 방향 (Limitations and Future Work)
- 한계점:
- 복잡한 관계 추론 및 모호한 queries에 어려움을 겪음.
- 부정 (negation)을 포함하는 queries에서 성능 저하가 관찰됨.
- Datasets 크기 및 유형으로 인해 일반적인 언어 능력이 저하될 수 있으며, 이는 MLLMs의 일반적인 과제.
- 향후 연구 방향:
- global VPP에 대한 더 많은 initialization forms 탐색.
- 더 강력한 DETR variant가 visual grounding 성능을 향상시킬 수 있는지 여부 조사.
- 부정 및 모호한 queries와 관련된 의미론적 이해의 문제 해결.
- (METEOR score로 표시된) caption 정확도 향상.
Overall Summary (전반적인 요약)
본 논문은 visual grounding을 위해 global 및 local Visual Position Prompts (VPP)를 효과적으로 통합하는 MLLM인 VPP-LLaVA를 제안. 훨씬 적은 training dataset을 사용하여 놀랍도록 높은 효율성으로 state-of-the-art 성능을 달성. 이 연구는 MLLMs에서 명시적인 위치 참조의 중요성을 보여주며, visual grounding 및 관련 vision-language tasks의 추가 개선을 위한 길을 열어줌.
쉬운 설명: 이 논문은 이미지 속에서 "갈색 물체" 와 같이 말로 표현된 물건을 정확하게 찾는 능력을 향상시키기 위해, 이미지에 좌표축과 같은 "위치 정보 (Visual Position Prompt)" 를 추가하는 방법을 사용했습니다. 마치 지도에 격자를 그려 넣어 위치를 더 쉽게 찾도록 돕는 것과 비슷합니다. 이 방법을 통해, 학습 데이터가 훨씬 적음에도 불구하고, 기존 방법들보다 더 뛰어난 성능을 달성했습니다.
Abstract
Multimodal Large Language Models (MLLMs)는 다양한 image 관련 task에서 뛰어나지만, image 내의 spatial information과 coordinate를 정확하게 align하는 데 어려움을 겪습니다. 특히 visual grounding과 같은 position-aware task에서 그러합니다. 이러한 제한은 두 가지 주요 요인에서 비롯됩니다.
첫째, MLLMs는 명시적인 spatial reference가 부족하여 textual description을 image의 정확한 location과 연결하기 어렵습니다.
둘째, feature extraction process가 fine-grained spatial detail보다 global context를 우선시하여 localization capability가 약화됩니다.
이 문제를 해결하기 위해, 우리는 grounding capability를 향상시키기 위해 Visual Position Prompt (VPP)를 갖춘 MLLM인 VPP-LLaVA를 소개합니다.
VPP-LLaVA는 두 가지 보완적인 mechanism을 통합합니다.
- Global VPP는 learnable하고 axis와 유사한 embedding을 input image에 overlay하여 structured spatial cue를 제공합니다.
- Local VPP는 position-aware query를 통합하여 fine-grained localization에 focus하며, 이는 probable object location을 제안합니다.
또한 0.6M sample의 VPP-SFT dataset을 도입하여 high-quality visual grounding data를 compact format으로 통합하여 efficient model training을 가능하게 합니다.
이 dataset에서 VPP를 사용하여 training하면 model의 performance가 향상되어, 훨씬 더 큰 dataset(~21M samples)에 의존하는 MiniGPT-v2와 같은 다른 MLLMs에 비해 더 적은 training sample을 사용함에도 불구하고 standard grounding benchmark에서 state-of-the-art result를 달성합니다.
Index Terms
Multimodal large language model, Visual grounding, Visual prompt, Prompt learning.
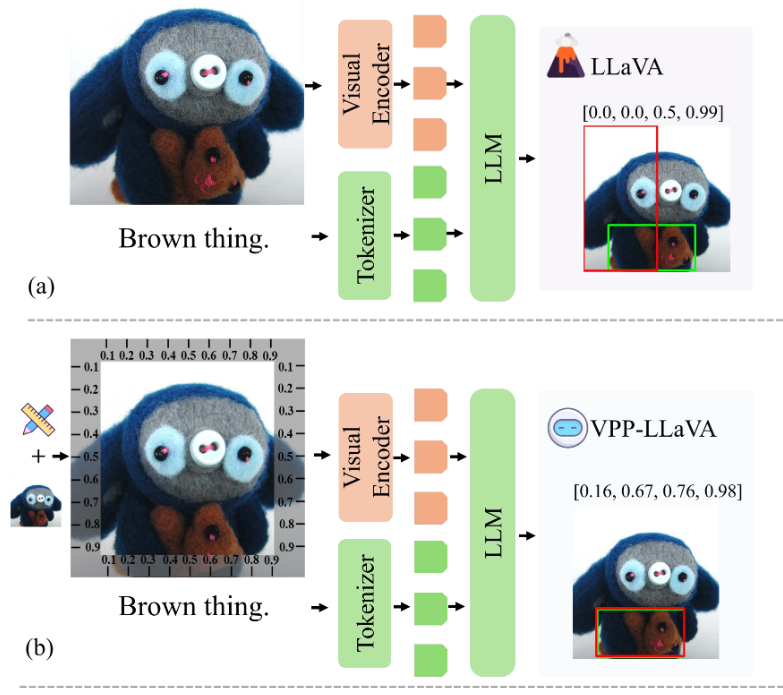
Fig. 1. MLLMs의 visual grounding case study:
(a) LLaVA-v1.5는 given query expression을 based on inaccurate bounding box를 output합니다.
(b) Position reference가 provided될 때, VPP-LLaVA는 suitable result를 produce합니다. Brevity를 위해, some text instruction은 omitted됩니다.

Fig. 2. Visual Position Prompt (VPP)를 갖춘 MLLM-based visual grounding framework인 VPP-LLaVA의 illustration.
우리는 foundational spatial cue를 사용하여 MLLMs에 대한 global position reference를 provide하기 위해 global VPP를 utilize합니다. Additionally, local position reference로 serving하는 local VPP는 object spatial information을 further enhance하고 incorporate하기 위해 introduced됩니다. Brevity를 위해, some text instruction은 omitted됩니다.
I. INTRODUCTION
Multimodal Large Language Models (MLLMs)는 다양한 image 관련 task에서 인상적인 result를 달성하며 research community로부터 상당한 주목을 받고 있습니다.
이러한 task 중에서 visual grounding, 특히 Referring Expression Comprehension (REC)는 critical challenge로 꼽힙니다.
Pure detection task와 달리, visual grounding은 free-form language expression을 기반으로 image 내의 location을 정확하게 identifying하는 것을 포함합니다. 이는 image segmentation, remote sensing, human-robot interaction과 같은 application에서 human과 machine 간의 cognitive interaction에 fundamental합니다.
MLLMs가 spatial understanding에 대한 reasonable ability를 가지고 있음을 나타내는 research가 있지만, 이러한 models, 특히 visual grounding과 같은 precise spatial reasoning을 포함하는 task에 대해서는 further enhancement가 필요하다는 consensus가 increasingly 커지고 있습니다.
Fig. 1 (a)에서 illustrated된 바와 같이, 예를 들어 LLaVA-v1.5의 grounding result는 notable inaccuracy를 reveal합니다 (red box는 predicted bounding box를 indicate하고, green box는 ground truth를 represent합니다). Predicted bounding box가 target object(즉, brown toy)를 partially cover하지만, size와 shape inaccuracy를 모두 겪으며 object의 true boundary와 잘 align되지 않습니다. 이러한 limitation은 MLLMs에서 spatial alignment와 object localization을 improve하기 위한 more effective strategy의 need를 highlight합니다.
이러한 challenge를 address하기 위해, 일부 study에서는 advanced region-level enhancement module과 larger, more comprehensive visual grounding dataset을 MLLMs에 integration하는 것을 investigating하고 있습니다. 다른 approach에서는 localization accuracy를 improve하기 위해 additional decoder를 사용하여 special token을 directly bounding box로 converting하는 것과 같은 task-specific expertise를 incorporation하는 것을 exploring하고 있습니다.
그러나 grounding task에서 MLLM performance를 enhance하기 위해 aforementioned method를 사용함에도 불구하고, study에서는 MLLMs가 여전히 image의 spatial information과 coordinate를 precisely align하는 데 significant challenge에 face하고 있음을 suggest합니다. 한 가지 key issue는 model이 spatial cue를 effectively interpret하고 utilize하는 ability에 있으며, 이는 많은 case에서 underutilized된 remain입니다.
Fig. 1 (b)에서 shown된 바와 같이, coordinate axis 형태의 positional reference를 introduce하여 explicit spatial guide를 providing하면 model의 spatial relationship에 대한 understanding이 significantly improve됩니다. 이 reference는 model이 image에 있는 object의 spatial information을 better interpret하여 more accurate localization으로 leading할 수 있게 합니다. Specifically, predicted bounding box는 brown toy와 more aligned하게 되어, positional reference가 incorporated될 때 improved spatial reasoning과 localization accuracy를 reflecting합니다.
이러한 observation을 based on, 우리는 visual grounding capability를 improve하기 위해 MLLMs 내에 positional reference를 prompt로 integrating하는 것을 propose합니다. Fig. 1 (b)에 shown된 coordinate axis가 global spatial guide를 provide하는 반면, 우리는 또한 object location과 semantic context를 capturing하여 local spatial cue를 offer하는 detection model에서 derived된 object position embedding의 potential을 leveraging하는 것을 explore합니다. 이러한 two type의 Visual Position Prompt (VPP) (global 및 local)는 complementary하며, global guide는 overall spatial structure를 establishing하는 데 helping하고, local cue는 object-specific localization을 refining합니다.
Specifically, global VPP는 axis와 유사한 form으로 initialized되고 input image에 overlaid되어 global spatial reference를 providing합니다. 이를 통해 MLLMs는 image 전체에서 coordinate information을 spatial detail과 more effectively align할 수 있습니다.
Object-specific spatial 및 semantic information을 capture하기 위해, 우리는 image 내의 potential object를 identify하는 local VPP를 introduce합니다. 이 local reference는 decoder가 object-level detail을 other feature와 integrate하는 데 help합니다. Global 및 local prompt를 both combining함으로써, 우리 model은 spatial alignment를 improve하고 visual grounding task에서 performance를 boost합니다.
Notably, 우리는 high-quality visual grounding data를 compact form으로 consolidating하는 새로운 VPP-SFT dataset에서 about 0.6M sample의 relatively small training set으로 state-of-the-art result를 achieve합니다. Around ~21M grounding sample을 require하는 MiniGPT-v2와 같은 other MLLMs에 compared하여, 우리의 approach는 strong performance를 maintaining하면서 superior efficiency를 demonstrates합니다.
In summary, our contributions are shown as follows:
- We propose VPP-LLaVA, an MLLM-based method for visual grounding with a Visual Position Prompt, along with a high-quality grounding instruction tuning dataset, VPP-SFT, which contains approximately 0.6M samples.
- We introduce novel global and local Visual Position Prompts that enable MLLMs to more effectively link spatial information within images to coordinate details, thereby enhancing their visual grounding capabilities.
- Extensive experiments demonstrate that our method not only achieves state-of-the-art performance but also does so with a substantially smaller training dataset compared to other MLLMs, highlighting its efficiency.
🚀 I. INTRODUCTION 핵심 정리 노트 (AI 연구자 대상)
문제 제기:
- MLLMs가 visual grounding (특히 Referring Expression Comprehension) task에서 어려움을 겪고 있음.
- Why? MLLMs는 명시적 spatial reference 부족, global context에 치중한 feature extraction으로 인해 spatial information과 coordinate alignment가 부정확함.
- LLaVA-v1.5를 예시로 들어 부정확한 bounding box prediction을 보여줌 (Fig. 1 (a)).
기존 연구의 한계:
- Region-level enhancement module, large visual grounding dataset, task-specific expertise (e.g., special token을 bounding box로 변환) 등 MLLM 성능 향상을 위한 노력에도 불구, spatial cue 활용은 여전히 미흡함.
본 논문의 핵심 아이디어 (Fig. 1 (b), Fig. 2):
- Visual Position Prompt (VPP) 도입: MLLM에 positional reference를 prompt로 제공하여 visual grounding capability 향상.
- Global VPP: Axis-like embedding을 input image에 overlay하여 global spatial guide 제공.
- Local VPP: Detection model에서 derived된 object position embedding을 활용하여 object-specific spatial cue 제공 (local spatial guide).
- Global & Local VPP는 상호 보완적: Global VPP는 전반적인 spatial structure 확립, Local VPP는 object-specific localization 정교화.
데이터셋 및 효율성:
- VPP-SFT dataset: 0.6M sample의 compact visual grounding dataset.
- MiniGPT-v2 (~21M grounding sample) 등 다른 MLLMs보다 훨씬 적은 training data로 state-of-the-art performance 달성 → 높은 효율성
Contribution 요약:
- VPP-LLaVA (VPP를 활용한 MLLM-based visual grounding method) 및 VPP-SFT dataset 제안.
- Novel global & local VPP 도입: Image 내 spatial information과 coordinate detail을 효과적으로 연결하여 visual grounding capability 향상.
- Extensive experiment를 통해 state-of-the-art performance 달성 및 타 MLLM 대비 높은 효율성 입증.
👶 쉬운 설명:
MLLM (Multi-modal Large Language Model)이 뭐에요?
- 이미지랑 텍스트를 모두 이해할 수 있는 똑똑한 AI 모델이에요. 예를 들어, "갈색 장난감을 찾아줘"라는 말을 하면 이미지에서 갈색 장난감을 찾을 수 있죠.
Visual Grounding은 또 뭐에요?
- 이미지 속에서 특정 물건을 찾는 기술이에요. "갈색 장난감"이라고 하면, AI가 이미지에서 갈색 장난감이 어디 있는지 정확하게 네모 박스(bounding box)로 표시해주는 거죠.
근데 왜 어렵대요?
- AI 모델은 이미지에서 물건의 정확한 위치를 파악하는 게 어려워요. 사람처럼 "왼쪽 위에" 같은 공간 감각이 부족하기 때문이죠. 그래서 엉뚱한 곳에 네모 박스를 치거나, 크기를 잘못 맞추는 경우가 많아요.
그래서 이 논문에서는 뭘 했대요?
- AI 모델에게 "좌표"라는 힌트를 줘서 물건 위치를 더 잘 찾게 만들었어요!
- Global VPP: 이미지 전체에 좌표축 (x축, y축)을 그려 넣어서, AI가 "아, 저 물건은 x축으로 이만큼, y축으로 이만큼 떨어진 곳에 있구나!" 하고 알 수 있게 해줘요.
- Local VPP: 각 물건 주변에 작은 좌표를 붙여서, "이 물건은 요기 쯤에 있어요!" 하고 더 자세하게 알려주는 거죠.
- 이렇게 힌트를 줬더니, AI가 물건 위치를 훨씬 정확하게 찾게 되었대요! 게다가, 다른 AI 모델보다 훨씬 적은 데이터로도 더 좋은 결과를 냈다고 하네요. (훨씬 효율적!)
II. RELATED WORK
A. Visual Grounding
Visual grounding은 주어진 free-formed linguistic expression을 based on image 내의 object를 locate하는 fundamental vision-language task입니다.
Conventional methods. Conventional visual grounding method는 typically three category로 divided됩니다:
- Two-stage methods: Standard detection network가 region proposal을 generate하고, cross-modal matching을 통해 language query와 best matches하는 proposal이 selected됩니다. EARN, MattNet 등이 이 방식에 해당됩니다.
- One-stage methods: Pre-trained detector의 limitation 때문에 increasingly adopted되고 있는 alternative solution입니다. 예를 들어, YOLOv3를 based on 하는 FAOA는 visual 및 linguistic modality에서 fused된 feature를 based on YOLO-like network를 사용하여 bounding box를 generate합니다.
- Transformer-based methods: Vision-Language Pre-trained (VLP) model의 advancement와 함께, strong performance와 pre-defined anchor로부터의 independence (one-stage method의 typical) 덕분에 increasingly popular해지고 있습니다. TransVG, VLTVG, TransCP, MDETR, CLIP-VG, OFA, UNINEXT-L 등이 representative method에 among됩니다. 이러한 method는 transformer를 사용하여 visual 및 linguistic feature를 directly fuse하고 visual grounding을 regression task로 model합니다.
Conventional method가 visual grounding 분야에서 significant progress를 made했음에도 불구하고, 이러한 approach는 often specifically individual task를 위해 designed되었습니다. Recently, researcher들은 their focus를 Multimodal Large Language Models (MLLMs)로 shifted하고 있으며, MLLMs의 ability를 leveraging하여 visual grounding을 other vision-related task와 unify하고 있습니다. 이러한 integration은 single, versatile model 내에서 task handling을 streamline합니다.
MLLM-based methods. Natural language processing 분야에서 LLMs의 tremendous success와 함께, researcher들은 their application을 multimodal domain으로 expanding하는 것을 considering하고 있습니다. LLaVA, MiniGPT-4 등이 typical example입니다. However, they는 visual grounding 분야에서 still have room for improvement입니다.
MLLMs의 grounding capability를 enhance하기 위해, researcher들은 more visual grounding data와 advanced position-aware module의 incorporation을 proposing하고 있습니다. 예를 들어, Shikra, Kosmos, MiniGPT-v2는 coordinate를 specialized token으로 discrete하여 MLLMs의 input format과 better align합니다. Ferret은 Spatial-Aware Visual Sampler를 introduce하고, PINK는 self-consistent bootstrapping approach를 employ하여 region sensitivity를 enhance합니다. 이러한 method는 여전히 standard MLLM framework를 adhere하며, 여기서 MLLM의 decoder는 coordinate를 directly output합니다.
LLMs는 inherently dense prediction task에 well-suited되지 않기 때문에, another type의 MLLM-based grounding method가 exists하며, 이는 task-specific decoder를 introducing하는 데 focus합니다. 예를 들어, LISA, GLaMM은 pixel-level referring image segmentation을 위해 SAM decoder를 leverage하는 반면, LLaVA-grounding은 bounding box를 predict하기 위해 additional grounding module을 introduce합니다.
Although they는 visual grounding에서 great progress를 achieved했지만, 여전히 image의 spatial information과 coordinate를 precisely align하는 데 challenge에 face합니다. Besides, almost all these model은 large-scale dataset에서 trained됩니다. 예를 들어, MiniGPT-v2는 approximately 21M grounding data sample에서 trains됩니다.
In contrast, our approach는 clear positional reference를 providing함으로써 MLLMs가 이러한 correspondence를 learning하는 것을 explicitly aids하여, state-of-the-art performance를 achieving하면서 only a much smaller dataset에서의 training을 requiring합니다.
B. Visual Prompt
Visual prompt는 text prompt보다 more direct하기 때문에 specific task에서 model을 guide하기 위해 researcher들에 의해 used됩니다.
Vision-and-Language Pre-training (VLP) model에서, VPT, MaPLe, CMPA는 CLIP visual embedding 전에 several learnable token을 add하여 CLIP을 few-shot classification task로 transferring합니다. PEVL, CPT는 visual grounding과 같은 position-sensitive vision-language task를 mask token prediction에 adapt합니다.
Recently, visual prompt는 SAM 및 its variant와 같은 large vision model에 introduced되어 image segmentation을 guide합니다.
MLLMs 분야에서, many work는 specific downstream task를 위해 visual prompt approach를 consider합니다. position-guided visual prompt for GPT-4V를 present하며, 이는 highly model 자체의 Chain-of-Thought ability에 rely합니다. Ferret, ViP-LLaVA는 scribble, arrow와 같은 hand-drawn free-form visual prompt를 introduce하여 user-friendly MLLMs를 building합니다. transferable visual prompt method를 propose하며, 이는 single model에서의 training 후에 downstream task에서 different model에 applied될 수 있습니다. segmentation mask와 같은 external knowledge를 visual prompt for MLLMs로 incorporating하여 visual understanding performance를 enhance할 것을 suggest합니다.
🔍 II. RELATED WORK 핵심 정리 노트 (AI 연구자 대상)
A. Visual Grounding
- 기존 연구 동향:
- Conventional methods: Two-stage, One-stage, Transformer-based methods 등으로 발전.
- 한계: 개별 task에 특화되어 설계, MLLM의 versatility 활용에 부족.
- MLLM-based methods: MLLM을 visual grounding에 적용하려는 시도 증가 (LLaVA, MiniGPT-4 등).
- 개선 노력: More visual grounding data, advanced position-aware module 통합 (Shikra, Kosmos, MiniGPT-v2, Ferret, PINK 등).
- 여전히 MLLM framework를 따르며, decoder가 직접 coordinate를 output (LLM은 dense prediction에 부적합).
- Task-specific decoder 도입: LISA, GLaMM, LLaVA-grounding 등 (pixel-level prediction, bounding box prediction).
- 한계: 여전히 spatial information과 coordinate alignment에 어려움, 대규모 dataset에 의존 (MiniGPT-v2: ~21M samples).
- 개선 노력: More visual grounding data, advanced position-aware module 통합 (Shikra, Kosmos, MiniGPT-v2, Ferret, PINK 등).
- Conventional methods: Two-stage, One-stage, Transformer-based methods 등으로 발전.
- 본 논문의 차별점: Clear positional reference (VPP)를 제공하여 MLLM이 spatial correspondence를 명시적으로 학습하도록 지원, 더 작은 dataset으로 state-of-the-art performance 달성.
B. Visual Prompt
- 기존 연구 동향:
- VLP model에서 visual prompt 활용 (VPT, MaPLe, CMPA): CLIP visual embedding 앞에 learnable token 추가.
- Position-sensitive task를 mask token prediction에 adapt (PEVL, CPT).
- Large vision model (SAM 등)에서 image segmentation guide를 위해 visual prompt 도입.
- MLLM에서 downstream task를 위해 visual prompt 고려 (GPT-4V, Ferret, ViP-LLaVA 등).
- Transferable visual prompt, external knowledge (segmentation mask)를 visual prompt로 활용하는 연구.
- 본 논문과의 연관성: Visual Prompt 개념을 활용하여 VPP (global & local)를 제안, MLLM의 visual grounding capability 향상. 기존 연구와 달리, 명시적인 spatial reference 제공에 초점.
👶 쉬운 설명:
A. Visual Grounding (물건 위치 찾기)
- 옛날 방식:
- 이미지에서 물건 후보들을 찾고, 그 중에서 질문에 맞는 물건을 고르는 방식 (Two-stage).
- 이미지랑 질문을 합쳐서 한 번에 물건 위치를 찾는 방식 (One-stage).
- Transformer라는 똑똑한 AI 모델을 사용하는 방식.
- 문제점: 특정 문제(task)에만 잘 동작하고, 여러 문제를 한 번에 처리하는 데는 약함.
- 요즘 방식 (MLLM):
- 이미지랑 텍스트를 둘 다 이해하는 똑똑한 AI 모델 (MLLM)을 사용해서 물건 찾기.
- 개선 노력:
- 더 많은 데이터, 위치 정보를 더 잘 처리하는 모듈 추가.
- MLLM은 원래 위치를 정확하게 찾는 데 약해서, 특별한 "도우미" 모듈을 추가하기도 함.
- 문제점: 여전히 위치를 정확하게 찾는 게 어렵고, 엄청나게 많은 데이터가 필요함.
- 이 논문에서는: AI 모델에게 "좌표"라는 확실한 힌트를 줘서, 적은 데이터로도 물건을 더 잘 찾게 함!
B. Visual Prompt (그림 힌트)
- 원래는: AI 모델에게 그림으로 힌트를 줘서 특정 작업을 더 잘하게 만드는 기술.
- 예: 이미지 분류, 이미지 분할 등.
- 이 논문에서는: Visual Prompt 아이디어를 활용해서, "좌표"라는 그림 힌트(VPP)를 만들고, MLLM에게 줘서 물건 위치를 더 잘 찾게 함!
III. METHODS
A. Overview
이 섹션에서는 visual grounding을 위한 Visual Position Prompt를 갖춘 MLLM 기반 method인 VPP-LLaVA를 present합니다. Fig. 2에 depicted된 바와 같이, 우리의 overall framework는 LLaVA-v1.5의 framework를 따릅니다. 여기에는 image feature를 extracting하기 위한 CLIP-L/336 visual encoder, 이러한 feature를 LLM의 feature space로 mapping하기 위한 2-layer MLP, 그리고 tokenized text prompt를 process하기 위한 LLM backbone으로서의 Vicuna-v1.5 model이 include됩니다. MLLMs가 image 내에서 coordinate와 spatial information을 precisely align하도록 돕기 위해, 우리는 global 및 local Visual Position Prompt를 both introduce합니다.
B. Global Visual Position Prompt
, , 에서 inspired되어, 우리는 MLLM에 대한 global position reference를 provide하기 위해 learnable global Visual Position Prompt (VPP) 를 introduce하고, 이를 axis와 유사한 form으로 initializing합니다.
[ \delta^{i}{g} \leftarrow X{\text{axis}} \in \mathbb{R}^{3 \times H \times W}, ]
여기서 는 initialized global VPP이고, 는 0.1의 unit scale을 사용하여 가장자리를 따라 coordinate axis가 있는 axes image를 denotes합니다. Fig. 2에 shown된 바와 같이, 이 design은 LLaVA의 training dataset에 있는 coordinate data format과 align되어 MLLM에 global reference를 providing합니다. In contrast, 우리는 image 외부에 coordinate axis를 adding하는 것을 avoided했는데, 이는 image coordinate가 annotated data와 misalign되어 confusion과 poor performance를 leading하기 때문입니다.
Global VPP는 resizing 및 padding과 같은 standard transformation을 사용하여 input image에 overlaid됩니다. Mathematically, global VPP의 process는 다음과 같이 described될 수 있습니다:
[ X^{gp} = \alpha \cdot T_{v}(X) + (1 - \alpha) \cdot T_{ipt}(\delta_{g}^{i} \odot M_{w}), ]
여기서 는 overlaid global VPP의 strength를 control하는 trade-off parameter입니다. 는 CLIP에서 resize 및 padding과 같은 visual encoder의 preprocessing transformation을 represents합니다. 는 global prompt를 processed input의 size에 fit하도록 scaling하는 interpolation operation을 denotes합니다. 는 가장자리 주변의 width가 인 binary mask이며, global VPP의 visible range를 control하는 데 use합니다. Global VPP를 가장자리를 따라 coordinate가 있는 axis와 유사한 image로 initialize하기 때문에, 이 masking은 essential합니다. 왜냐하면 그 안의 모든 pixel이 visible할 필요는 없기 때문입니다.
Added global VPP 가 있는 input image를 obtain한 후, image feature를 get하기 위해 LLaVA의 visual encoder, 즉 CLIP-L/336에 send합니다.
[ F_{gp} = \text{CLIP}(X^{gp}), ]
그런 다음 LLaVA에서 used된 것과 similar한 two-layer MLP가 image feature를 LLM의 language space로 project하는 데 used됩니다.
[ F'{gp} = MLP(F{gp}), ]
C. Local Visual Position Prompt
Object spatial information을 further enhance하고 incorporate하기 위해, 우리는 local position reference로 serving하는 local VPP를 introduce합니다.
Specifically, in our implementation, 우리는 entire local prompt generation process를 handle하기 위해 DETR을 local VPP generator로 use합니다. 를 object query의 set으로 denote합니다. Overlaid global prompt와 object query가 있는 image를 DETR의 transformer encoder 및 decoder에 feeding함으로써, image당 100개의 object query embedding을 obtain하여 potential object location과 semantic information을 both capturing합니다.
[ F_{lp} = \text{DETR}(X_{gp}, \mathcal{O}), ]
여기서 는 generated local Visual Position Prompt를 denotes하고, 은 ResNet-101 backbone, 6-layer transformer encoder, 6-layer transformer decoder를 includes하는 DETR model을 denotes합니다. LLaVA에 following하여, local prompt의 feature를 LLM의 space로 map하기 위해 2-layer MLP를 also use합니다.
[ F'{lp} = MLP(F{lp}), ]
Proposed local VPP는 other DETR-based method와 two key aspect에서 itself를 distinguishes합니다: First, bounding box proposal을 extract하기 위해 pre-trained detector에 heavily rely하는 existing two-stage visual grounding MLLMs와 unlike, 우리는 spatial 및 semantic information을 both capture하는 object position embedding을 dynamically generate합니다. 이를 통해 LLM decoder는 object-level detail을 more effectively integrate할 수 있습니다. Second, DETR을 incorporate하고 LLM을 solely fusion에 using하면서 extra box decoder를 add하는 ContextDET와 같은 method와 unlike, our method는 pure MLLM입니다. 이 design은 architecture를 simplify할 뿐만 아니라 visual 및 language modality의 more seamless integration을 enabling함으로써 performance를 enhances합니다.
D. Instruction Tuning and Data Construction
Both prompt에서 image feature가 obtained되면, 우리는 directly them을 concatenate하고 combined feature를 query text instruction과 along with LLM에 feed하여 processing합니다. 우리는 LLaVA-v1.5의 pre-trained Vicuna-v1.5를 LLM으로 utilize합니다. Response는 autoregressive language modeling, 즉 next token prediction의 likelihood를 maximizing함으로써 LLM에 의해 generated되며, 이는 다음과 같이 formulated될 수 있습니다:
[ P(X_a \mid F', X_q) = \prod_{i=1}^{L} P_{\theta}(x_i \mid F', X_q, X_{a,<i}), ]
[ F' = \text{concatenate}([F'{gp}, F'{lp}]), ]
여기서 는 global 및 local VPP를 both applying하여 obtained된 concatenated visual feature를 represents합니다. Symbol 는 LLM의 parameter를 denotes하고, 는 query text instruction을 stands for하고, 은 answer 의 sequence length를 refers하고, 는 current prediction token 를 precede하는 all answer token을 encompasses하며, 여기서 는 next word token prediction process의 step을 indicates합니다.
Model의 instruction tuning을 위해, 우리는 approximately 0.6M sample을 containing하는 dataset인 VPP-SFT를 construct하며, 이는 many MLLMs에서 grounding에 commonly used되는 other dataset보다 significantly smaller합니다. 예를 들어, MiniGPT-v2는 21M grounding sample을 uses하고, KOSMOS-2는 20M을 uses하고, even the relatively smaller Shikra는 4M sample을 utilizes합니다.
Table 3에 shown된 바와 같이, our constructed dataset은 primarily four main source에서 derives됩니다: LLaVA-665K, CB-GRD, CB-REF, Genixer의 subset으로, original data의 high quality로 인해 respectively 134,864, 264,516, 87,091, 130,000 conversation을 containing합니다. Our model은 pre-trained LLaVA model에 built되어 있기 때문에, all bounding box와 instruction을 LLaVA에서 used되는 format을 follow하도록 convert합니다. Specifically, 우리는 bounding box coordinate를 LLaVA format에 adapt하고, image를 longer edge를 따라 pad하고, coordinate를 form으로 normalize합니다. LLaVA의 original language capability를 retain하기 위해, 우리는 Please provide a short description for this region: xxx와 같은 instruction으로 formatted된 small amount의 region-captioning data (e.g., CB-REF subset)를 incorporate합니다. 우리는 tuned MLLM이 response로 coordinate를 provide할 뿐만 아니라 language query의 part로 coordinate를 recognize하고 interpret하는 것을 aim합니다. 이 two type의 data의 combination은 image에서 object location의 model의 spatial awareness를 enhances하여 spatial information을 perceive하는 ability를 improving합니다. Our dataset의 sample은 Table I에 shown되어 있습니다.
VPP-SFT는 other dataset의 simple fusion이 아니라는 점에 note하는 것이 important합니다. Many MLLM paper는 reuse하기 hard한 fragmented dataset을 introduce합니다. VPP-SFT는 MLLMs를 위해 이러한 scattered visual grounding dataset을 together bring하려고 tries합니다. Often complex format with lots of special position token을 갖는 grounding을 위한 other instruction-tuning dataset과 unlike, our data format은 refreshingly straightforward합니다. 이러한 simplicity는 our based on new dataset을 create하는 것을 easier하게 만들고 model의 more direct fine-tuning을 allows하여 MLLM spatial awareness를 boost합니다. As a result, our dataset은 highly reusable하고 adaptable합니다.
🧠 III. METHODS 핵심 정리 노트 (AI 연구자 대상)
Overall Framework (Fig. 2):
- LLaVA-v1.5 기반:
- CLIP-L/336 visual encoder (image feature extraction)
- 2-layer MLP (feature를 LLM space로 mapping)
- Vicuna-v1.5 (LLM backbone)
핵심 아이디어: Visual Position Prompt (VPP) 도입
- Global VPP:
- Learnable parameter (): Axis-like 형태로 초기화, global spatial reference 제공.
- Input image에 overlay (수식 2):
- : Global VPP 강도 조절.
- : CLIP의 preprocessing (resize, padding).
- : Global prompt 크기를 input에 맞게 조절.
- : Global VPP 가시 범위 조절 (binary mask).
- CLIP visual encoder 통과 (수식 3), MLP로 LLM space에 projection (수식 4).
- Local VPP:
- DETR을 local VPP generator로 활용:
- Object query () 입력, DETR encoder-decoder 통과 (수식 5).
- 100개의 object query embedding 생성 (potential object location + semantic information).
- MLP로 LLM space에 projection (수식 6).
- 차별점:
- Pre-trained detector에 의존하는 기존 two-stage MLLM과 달리, dynamic object position embedding 생성 (spatial + semantic).
- LLM decoder가 object-level detail을 효과적으로 통합.
- ContextDET와 달리, pure MLLM (architecture 단순화, visual & language modality seamless 통합).
- DETR을 local VPP generator로 활용:
Instruction Tuning & Data Construction:
- Global & Local VPP feature concatenation (수식 8), query text instruction과 함께 LLM에 입력.
- Autoregressive language modeling으로 response 생성 (수식 7).
- VPP-SFT dataset:
- ~0.6M samples (MiniGPT-v2: 21M, KOSMOS-2: 20M, Shikra: 4M).
- LLaVA-665K, CB-GRD, CB-REF, Genixer subset 기반 (high-quality data).
- Bounding box, instruction을 LLaVA format으로 변환.
- Region-captioning data 일부 포함 (LLaVA original language capability 유지).
- 장점:
- 단순하고 straightforward한 format (special position token X).
- 새로운 dataset 생성, model fine-tuning 용이 (MLLM spatial awareness 향상).
- 높은 재사용성 및 적응성 (reusable & adaptable).
👶 쉬운 설명:
VPP-LLaVA 모델 구조:
- LLaVA-v1.5라는 기존 모델을 기본으로 사용해요.
- 이미지 이해: CLIP (이미지 특징 추출)
- 이미지-텍스트 연결: MLP (이미지 특징을 텍스트 특징 공간으로 변환)
- 텍스트 이해 및 생성: Vicuna (똑똑한 언어 모델)
핵심 기술: Visual Position Prompt (VPP)
- Global VPP (전역 좌표 힌트):
- 이미지 전체에 좌표축 (x축, y축)을 그려 넣어서, AI가 이미지의 전체적인 공간 구조를 파악하도록 도와줘요.
- 좌표축은 학습 가능해서, AI가 스스로 최적의 좌표축 형태를 찾을 수 있어요.
- Local VPP (지역 좌표 힌트):
- DETR이라는 물체 감지 모델을 사용해서, 이미지 속 각 물체의 위치 정보를 담은 "좌표 힌트"를 만들어요.
- AI는 이 힌트를 보고, "아, 이 물건은 여기쯤에 있구나!" 하고 더 정확하게 알 수 있죠.
- 다른 모델들과 달리, 미리 만들어진 물체 후보 영역 (bounding box proposal)을 사용하는 게 아니라, 실시간으로 물체 위치 정보를 생성해서 더 유연하고 정확해요.
학습 방법:
- Global VPP, Local VPP에서 얻은 정보와 질문 텍스트를 합쳐서 LLM에 입력해요.
- LLM은 다음에 나올 단어를 예측하는 방식으로 답변을 생성해요.
- VPP-SFT 데이터셋:
- 다른 모델들보다 훨씬 적은 양의 데이터 (~0.6M)로 학습했어요 (효율성 👍).
- 기존 데이터들을 잘 조합하고, 형식을 통일해서 재사용성을 높였어요.
- 데이터 형식이 단순해서, 새로운 데이터를 만들거나 모델을 추가 학습시키기 쉬워요.
원본이미지 -> 클립 -> 이미지 피쳐
이미지 피쳐 + 학습가능한 테두리 좌표축 -> MLP -> F'_{gp} (이미지에 좌표축 정보가 담겨 있고 LLM이 이해할 수 있는 형태)
이미지 피쳐 -> 100개의 질문 (DETR 사용) -> F_{lp} -> MLP -> F'_{lp} (100가지 오브젝트 별로 있거나 없거나에 대한 정보와 함께 각 물체의 좌표 정보도 있음.)
F'_{gp} + F'_{lp} 를 사용하여 인퍼런스 진행


