

AI바라기의 인공지능
VLM : 논문리뷰 : LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL 본문
VLM : 논문리뷰 : LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
AI바라기 2025. 3. 21. 14:19Overall Summary:
LMM-R1 논문은 3B LMMs의 reasoning 능력을 강화하기 위한 novel two-stage rule-based RL framework를 제안하고, text-only data 기반 FRE stage와 multimodal data 기반 MGT stage를 통해 효과적인 multimodal generalization 달성 가능성을 입증했습니다. Text-based reasoning enhancement를 통한 data-efficient multimodal learning paradigm 제시를 통해, costly high-quality multimodal training data에 대한 의존성을 낮추고, LMMs의 reasoning 능력 향상 및 real-world application 확장에 기여할 것으로 기대됩니다. 향후 larger 모델 및 다양한 task로 확장, reward function 개선 등 future work 통해 framework 발전 potential 높음.
쉬운 설명:
LMM-R1은 "튼튼한 기초 공사 후, 맞춤형 훈련" 전략과 같습니다. 작은 모델 (3B LMMs) 이지만, 먼저 텍스트 문제만 풀면서 reasoning 기초 체력을 키우고 (FRE stage), 이후 multimodal 문제 (이미지+텍스트) 를 풀면서 실전 감각을 익히는 방식 (MGT stage) 입니다. 마치 글쓰기 기초 연습 후, 그림 보고 글쓰기 훈련하는 것과 유사합니다. 이 방법을 통해 작은 모델도 reasoning 능력이 크게 향상될 수 있고, multimodal 세상에서도 똑똑하게 활약할 수 있음을 보여줍니다. 비싼 multimodal 데이터 없이, text 데이터만으로도 효과를 볼 수 있다는 점이 핵심입니다.
LMM-R1 논문 분석 노트
Purpose of the Paper:
- 기존 Large Multimodal Models (LMMs)의 reasoning 능력 한계 극복 (특히, 3B parameter 이하의 compact architecture 모델).
- Multimodal domain에서 rule-based Reinforcement Learning (RL)의 두 가지 주요 문제점 (data limitations, weak foundational reasoning) 해결하고자 함.
- Costly high-quality multimodal training data에 대한 의존성을 낮추고, data-efficient paradigm 제시 목표.
Key Contributions:
- Novel Two-Stage Rule-Based RL Framework: LMM-R1
- Foundational Reasoning Enhancement (FRE): Text-only data와 rule-based RL 활용, 모델의 foundational reasoning abilities 강화 (novelty: multimodal data 없이 text-only data만으로 reasoning 능력 향상).
- Multimodal Generalization Training (MGT): 제한적인 multimodal data 환경에서 rule-based RL 추가 학습, 다양한 multimodal domain으로 reasoning 능력 generalization (novelty: FRE stage에서 확보된 reasoning 능력을 multimodal domain으로 효과적으로 transfer).
- Experimental Validation: Qwen2.5-VL-Instruct-3B 모델에 LMM-R1 framework 적용, multimodal 및 text-only benchmarks에서 baseline 대비 significant performance improvement 입증 (novelty: 3B LMMs에서도 strategic two-stage training 통해 architectural constraints 극복 가능성 제시).
- Multimodal benchmarks 평균 4.83%, text-only benchmarks 평균 4.5% 성능 향상.
- Complex Football Game task에서 3.63% 성능 향상.
- Text-based reasoning enhancement가 effective multimodal generalization 가능하게 함을 실험적으로 검증.
Experimental Highlights:
- Datasets:
- FRE stage: DeepScaler-Preview-Dataset (text-only), Verifiable Multimodal-65K (multimodal).
- MGT stage: VerMulti-Geo (geometry), VerMulti (perception-reasoning balanced), MageBench Sokoban (agent-related).
- Benchmarks:
- Multimodal: OlympiadBench, MathVision, MathVerse, MM-Star, MathVista.
- Text-only: MATH500, GPQA.
- Agent-related: Sokoban, Football Game.
- Metrics: Accuracy, reward (format reward, accuracy reward).
- Key Result: LMM-R1 (FRE-Text + MGT-Geo/PerceReason/Sokoban) 모델이 다양한 benchmarks에서 baseline (Qwen2.5-VL-CoT) 및 direct RL 모델 (FRE-Multi, Direct-RL-Geo/Sokoban) 대비 consistently superior performance 달성. 특히, FRE-Text stage의 text-only RL이 multimodal reasoning generalization에 효과적임을 입증.
Limitations and Future Work:
- Limitations:
- Rule-based RL reward function 설계의 복잡성 (특히, multimodal task).
- Text-only FRE stage가 visual perception 능력 향상에 limited benefit 제공 가능성.
- 3B LMMs architecture 자체의 inherent reasoning capacity 한계 존재 가능성.
- Future Work:
- LMM-R1 framework를 larger LMMs 및 다양한 downstream task로 확장.
- High-quality multimodal reasoning data를 synthesize하는 방법 연구 (data augmentation strategy).
- Visual perception 능력 향상을 위한 FRE stage 개선 (e.g., visual pre-training integration).
- More sophisticated reward function 개발 (e.g., PRM-based reward).
Abstract
Large Multimodal Models (LMMs)에서 reasoning을 향상하는 것은 visual perception과 logical reasoning 사이의 복잡한 상호 작용, 특히 architectural 제약으로 인해 reasoning capacity와 modality alignment가 제한되는 compact 3B-parameter architectures에서 고유한 문제에 직면합니다. rule-based reinforcement learning (RL)은 텍스트 전용 도메인에서는 뛰어나지만, multimodal extension은 두 가지 critical barriers에 직면합니다. (1) ambiguous answers와 scarce complex reasoning examples로 인한 data limitations, (2) multimodal pretraining으로 인한 degraded foundational reasoning.
이러한 문제를 해결하기 위해, 우리는 Foundational Reasoning Enhancement (FRE)와 Multimodal Generalization Training (MGT)를 통해 rule-based RL을 multimodal reasoning에 적용하는 2단계 framework인 LMM-R1을 제안합니다.
FRE 단계에서는 먼저 rule-based RL을 사용하여 텍스트 전용 data로 reasoning abilities를 강화한 다음,
MGT 단계에서 이러한 reasoning capabilities를 multimodal domains으로 일반화합니다.
Qwen2.5-VL-Instruct-3B에 대한 실험에서 LMM-R1은 multimodal 및 text-only benchmarks에서 baselines 대비 각각 평균 4.83% 및 4.5%의 improvements를 달성했으며, 복잡한 Football Game tasks에서는 3.63%의 gain을 달성했습니다.
이러한 결과는 text-based reasoning enhancement가 효과적인 multimodal generalization을 가능하게 하여, costly high-quality multimodal training data를 우회하는 data-efficient paradigm을 제공함을 입증합니다.

Figure 1. Comparison of reasoning approaches on a geometric problem.
기하 문제에 대한 reasoning approaches 비교. baseline LMM (위)은 slant height를 잘못 식별하여 erroneous solution으로 이어집니다. 반면, LMMR1 (아래)는 Pythagorean theorem을 올바르게 적용하여 actual slant height를 결정함으로써 superior reasoning을 보여주며, 이는 our rule-based RL approach가 model’s ability to apply proper mathematical principles를 어떻게 향상시키는지를 보여줍니다.
1. Introduction
최근 몇 년 동안 Large Language Reasoning Models (LLRMs)에서 remarkable progress가 있었습니다. 연구자들은 Monte Carlo Tree Search (MCTS) 및 Process Reward Models (PRM)과 같은 approaches를 탐구해 왔으며, 이러한 approach는 extensive human annotation 또는 expensive computational resources가 필요합니다. DeepSeek-R1은 Rule-based Reinforcement Learning (RL)을 사용한 more efficient approach를 도입했는데, 이는 prompt-answer pairs만 필요로 하여 models가 reward hacking을 피하면서 exploration을 통해 autonomously improve reasoning을 할 수 있게 합니다.
multimodal domain으로 눈을 돌리면, enhancing reasoning capabilities의 challenges는 considerably more complex해집니다. Large Multimodal Models (LMMs)는 visual information이 visual perception과 logical reasoning 모두의 integration을 요구함으로써 reasoning complexity를 증가시키기 때문에 더 큰 challenges에 직면합니다. 이러한 challenge는 3B LMMs에서 particularly severe한데, 이는 limited parameter capacity가 capabilities를 constrains하기 때문입니다. 더욱이, 이러한 requirement는 high-quality multimodal reasoning data를 extremely difficult to collect하게 만들고, reasoning processes와 함께 multimodal data를 training에 사용하는 것을 더욱 복잡하게 만듭니다.
rule-based RL의 text-only domain에서의 potential을 고려하여, 우리는 이를 multimodal reasoning으로 확장하는 것을 목표로 합니다. 그러나 direct application은 두 가지 specific issues에 직면합니다.
(1) Data limitations: Rule-based RL은 accurate rewards를 위해 uniquely verifiable answers를 필요로 하지만, multimodal tasks는 종종 answer ambiguity (예: image description, visual QA)를 포함하는 반면, perception-focused data는 풍부하지만 limited complex reasoning examples로 어려움을 겪고 있어 RL에서 insufficient reasoning으로 이어질 수 있습니다.
(2) Weak foundational reasoning: multimodal data로 trained된 models는 종종 text-only tasks에서 weakened capabilities를 보여주며, Chain-of-Thought (CoT)를 사용하는 일부 LMMs는 실제로 multimodal benchmarks에서 performance degradation을 경험하는데, 이는 smaller 3B-parameter architectures에서 limited capacity로 인해 증폭되는 현상입니다.
이러한 challenges를 해결하기 위해, 우리는 LMMs의 general reasoning capabilities를 향상시키는 것을 목표로 하는 simple yet effective two-stage rule-based RL training framework인 LMM-R1을 제안합니다. 이전 studies에서는 smaller 3B LMM이 본질적으로 complex multimodal reasoning을 위한 capacity가 부족하다고 제안하지만, 우리는 strategic two-stage training이 이러한 architectural constraints를 극복할 수 있음을 보여줍니다.
Fig. 1에서 볼 수 있듯이, LMM-R1은 Pythagorean theorem을 correctly apply하여 cone의 slant height를 determine하는 반면, baseline LMM은 이를 incorrectly identifies하여, our approach가 mathematical reasoning capabilities를 어떻게 향상시키는지를 보여줍니다.
Our framework는 두 가지 key stages로 구성됩니다.
첫 번째 단계는 Foundational Reasoning Enhancement (FRE) 로, abundant high-quality text-only data와 함께 rule-based RL을 사용하여 model’s basic reasoning abilities를 strengthen합니다. 이 단계는 expensive multimodal data에 대한 need를 avoiding하면서, subsequent multimodal generalization을 위한 crucial stepping stone 역할을 하는 solid reasoning foundation을 확립합니다.
두 번째 단계는 Multimodal Generalization Training (MGT) 이며, limited complex multimodal reasoning tasks에서 rule-based RL training을 continue합니다. 이 continuing training은 reasoning abilities를 various multimodal domains으로 generalizes합니다.
MGT 단계에서, 우리는 두 가지 key multimodal reasoning domains에 focus합니다. general multimodal reasoning domain과 agent-related reasoning domain입니다.
general multimodal reasoning domain의 경우, model’s reasoning abilities를 GeoQA, ScienceQA, ChartVQA 등을 포함한 various multimodal scenarios로 further extend합니다.
agent-related domain의 경우(이는 LMMs의 significant real-world use cases를 represent합니다), Sokoban 및 football tasks와 같은 tasks에서 our approach를 evaluate합니다. 이러한 tasks는 goal identification, path planning, multi-image processing을 포함한 sophisticated reasoning skills를 require하므로, real-world applications에 대한 meaningful assessments를 provide합니다. 또한, rule-based RL을 사용하여 Sokoban에서 model을 continuing training하면 agent-related benchmark에서 its performance가 further improves되어, agent domains에서 LMM-R1의 effectiveness를 further validating합니다.
experiments에서, 우리는 Qwen2.5-VL-Instruct-3B를 baseline model로 사용하고 LMM-R1을 적용했으며, 그 results는 several important findings를 reveal합니다.
첫째, enhancing foundational reasoning capabilities는 multimodal reasoning에 crucial합니다. RL training에 text-only data를 사용하면 general domain과 agent-related domain 모두에서 multimodal reasoning capabilities를 significantly improve할 수 있는 반면, multimodal data를 rule-based RL에 directly 사용하면 reasoning abilities에서 limited improvement가 발생합니다.
Fig. 2에서 볼 수 있듯이, our experiments는 model이 verifiable multimodal data로 rule-base RL을 사용하여 directly trained된 후 high-quality long reasoning processes를 generate하지 못한다는 것을 reveal합니다.
또한, LMM-R1은 model’s reasoning capabilities를 enhances할 뿐만 아니라 its visual abilities도 further improves합니다.
Specifically, LMM-R1은 multiple multimodal benchmarks에서 significant performance improvements를 achieves하며, text-only/five multimodal/ Football Game benchmarks에서 baseline model 대비 4.5%/4.83%/3.63%의 performance increase를 달성했습니다.
Our main contributions include:
- 우리는 extensive human annotation 없이 multimodal reasoning을 enhance하기 위해 two-stage training strategy (FRE 및 MGT)와 함께 rule-based RL을 사용하는 first framework인 LMM-R1을 introduce합니다.
- 우리는 rule-based RL을 통해 text-only reasoning data를 사용하면 foundational reasoning ability를 largely improve할 수 있으며, more importantly, 이러한 ability가 multimodal domains으로 generalized될 수 있음을 show합니다.
- 우리는 initially possess very limited reasoning capabilities를 가진 3B LMMs에서도 LMM-R1이 reasoning ability를 significant enhance할 수 있음을 demonstrate하여, broader applications을 위한 LMM-R1의 vast potential을 suggesting합니다.
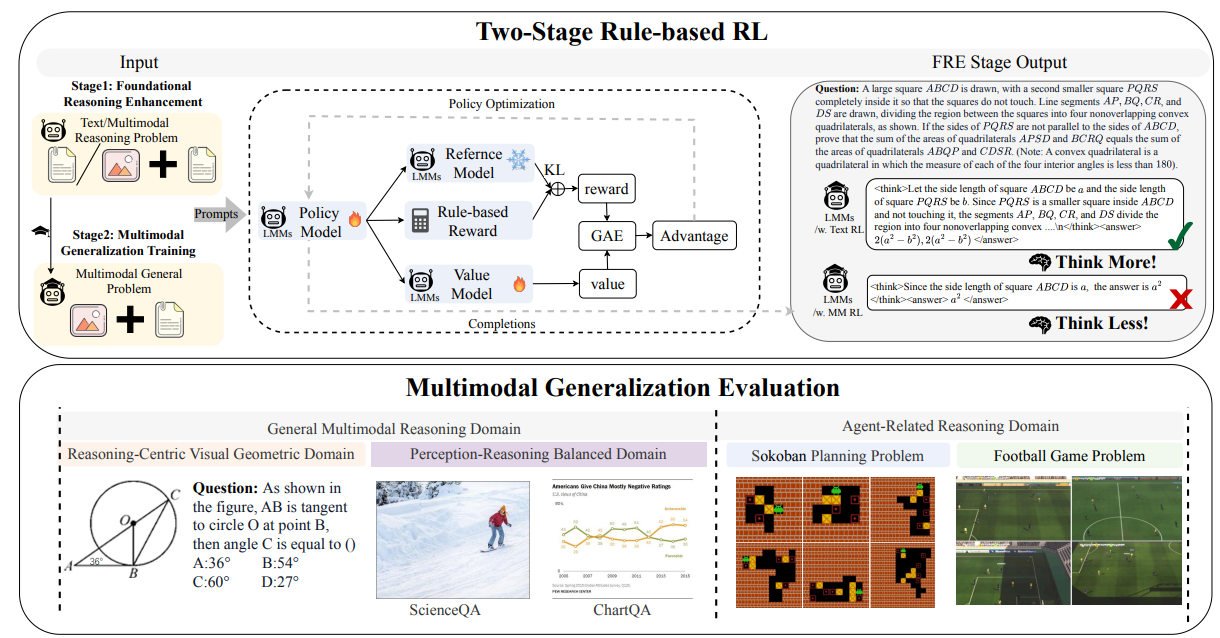
위쪽 그림은 LMM-R1이 two-stage, rule-based RL strategy를 사용하여 reasoning capabilities를 enhance한다는 것을 보여줍니다. 첫 번째 Foundational Reasoning Enhancement (FRE) 단계에서는 text-only reasoning data를 사용하여 LMM을 trains하여 foundational reasoning skills를 improve합니다. Subsequently, 두 번째 Multimodal Generalization Training (MGT) 단계에서는 이러한 capabilities를 diverse multimodal domains으로 extends하며, evaluation benchmarks는 아래쪽 패널에 illustrated되어 있습니다.
1. Introduction 정리 노트 (AI 연구자 대상)
핵심 문제 제기:
- Compact LMMs (특히 3B)의 한계: architectural constraints로 인해 reasoning capacity 및 modality alignment (visual perception + logical reasoning)에 어려움을 겪음.
- Multimodal reasoning data 부족: high-quality multimodal reasoning data는 수집하기 어렵고, ambiguous answers 및 scarce complex reasoning examples 문제가 있음.
- Multimodal pretraining의 부작용: multimodal data로 trained된 models는 text-only tasks에서 weakened capabilities를 보이며, CoT를 사용해도 multimodal benchmarks에서 performance degradation이 발생 (특히 3B models에서 심화).
LMM-R1 제안 (해결책):
- Two-Stage Rule-based RL Framework:
- FRE (Foundational Reasoning Enhancement): text-only data와 rule-based RL을 사용하여 foundational reasoning abilities를 강화. (expensive multimodal data 필요 X)
- MGT (Multimodal Generalization Training): 강화된 reasoning capabilities를 multimodal domains으로 generalize (limited complex multimodal reasoning tasks 사용).
- Focus: General multimodal reasoning (GeoQA, ScienceQA, ChartVQA 등) & Agent-related reasoning (Sokoban, football tasks).
주장 & 차별점:
- 3B LMM의 한계 극복: strategic two-stage training (FRE + MGT)을 통해 architectural constraints를 overcome.
- Text-only data의 중요성: text-only data를 활용한 rule-based RL이 foundational reasoning을 크게 향상시키고, multimodal domains으로의 generalization을 가능하게 함. (multimodal data에 직접 rule-based RL 적용은 효과 제한적)
- Reasoning & Visual Abilities 동시 향상: LMM-R1은 reasoning capabilities뿐만 아니라 visual abilities도 향상.
실험 결과 (Qwen2.5-VL-Instruct-3B):
- Multimodal & text-only benchmarks에서 significant performance improvements (각각 4.83%, 4.5%).
- Complex Football Game tasks에서 3.63% gain.
쉬운 설명 :
- Introduction 섹션에서는 Large Multimodal Models (LMMs), 특히 작은 크기(3B parameter)의 모델들이 가진 문제점을 이야기하고 있어요.
- 쉽게 말해: 작은 LMM들은 이미지랑 텍스트를 একসাথে 이해하고 추론하는 능력이 좀 부족하다는 거에요. 이미지도 보고, 글도 읽고, 그 둘을 연결해서 뭔가 똑똑한 답을 내놓는 게 어렵다는 거죠.
- 왜 어렵냐? 🤖 모델 크기가 작아서 정보 처리 능력이 딸리고, 🖼️ 이미지랑 📝 텍스트를 융합하는 게 쉽지 않기 때문이에요. 게다가, 이런 능력을 키우려면 아주 좋은 학습 데이터가 많이 필요한데, 그런 데이터를 구하기가 하늘의 별따기처럼 어렵대요.
- 그래서 이 논문에서는 LMM-R1이라는 새로운 방법을 제안합니다. 이 방법은 두 단계로 이루어져 있어요.
- 1단계 (FRE): 먼저 텍스트만 가지고 추론 능력을 빡세게 훈련시켜요. 마치 덧셈, 뺄셈, 곱셈, 나눗셈을 먼저 배우는 것처럼 기본적인 추론 능력을 탄탄하게 만드는 거죠.
- 핵심: 이미지 없이 텍스트만으로도 충분히 똑똑해질 수 있다는 거!
- 2단계 (MGT): 그 다음에 이미지랑 텍스트를 같이 사용하는 좀 더 어려운 문제들을 풀면서 배운 능력을 응용하는 연습을 해요.
- 핵심: 1단계에서 배운 텍스트 추론 능력이 이미지랑 텍스트를 같이 이해하는 데에도 큰 도움이 된다는 거!
- 1단계 (FRE): 먼저 텍스트만 가지고 추론 능력을 빡세게 훈련시켜요. 마치 덧셈, 뺄셈, 곱셈, 나눗셈을 먼저 배우는 것처럼 기본적인 추론 능력을 탄탄하게 만드는 거죠.
- 이 방법을 쓰면 좋은 점은?
- 작은 LMM도 똑똑하게 만들 수 있다!
- 비싼 학습 데이터 없이도 좋은 성능을 낼 수 있다! (텍스트 데이터는 상대적으로 구하기 쉬우니까)
- 추론 능력뿐만 아니라 이미지 인식 능력도 좋아진다!
마치 어린 아이에게 처음에는 글자만 가르치다가(FRE), 나중에 그림책을 읽어주면서(MGT) 이해력을 높이는 것과 비슷한 원리라고 생각하면 쉬울 것 같아요.
2. Related Work
Large Multimodal Model (LMM)
LMMs는 Large Language Models (LLMs)에 additional modalities, 특히 vision을 integrate하여 general vision capabilities를 enhance합니다. 초기에는 Flamingo 및 BLIP2와 같은 models가 visual question answering을 위해 frozen vision encoders를 LLMs와 aligned했습니다. Subsequently, LLaVA series, MiniGPT-4, mPLUG-Owl series는 instruction-following을 improve하기 위해 visual instruction tuning을 introduced했습니다. VisionLLM, KOSMOS 2, Shikra, Qwen-VL series와 같은 models는 region description 및 localization과 같은 tasks를 위해 visual grounding을 통해 LMMs를 enhanced했습니다. InternVL은 vision foundation models를 scaling up하여 LLMs와의 alignment를 수행했습니다. Additionally, GPT-4V 및 Gemini는 strong general visual understanding을 demonstrated했습니다. Mixture-of-Experts (MoE) approaches는 DeepSeek-VL2, Uni-MoE, MoVA, MoME에서 understanding을 improved했습니다. SEED-X, Chameleon, Show-o, Transfusion, Janus를 포함한 일부 models는 vision understanding과 generation을 unified했습니다. However, most existing LMMs는 여전히 reasoning capabilities가 lack합니다.
Reinforcement Learning in LLMs and LMMs.
Reinforcement Learning (RL)은 LLMs 및 LMMs의 capabilities를 enhancing하는 key methodology가 되었습니다. Early research는 primarily Reinforcement Learning from Human Feedback (RLHF)에 focused했는데, 이는 model outputs를 human preferences와 align하는 것을 aimed했습니다. Recent advancements는 RL이 이러한 models의 reasoning capabilities를 significantly enhance할 수 있음을 demonstrated했습니다. For instance, DeepSeek-R1 및 Kimi-1.5와 같은 models는 rule-based reward를 통해 LLMs의 reasoning abilities를 improving하는 데 있어 RL의 effectiveness를 highlight합니다.
multimodal domain에서, RL을 leveraging하여 LMMs의 reasoning capacities를 enhance하는 research는 remains in its early stages입니다. 일부 researchers는 Process Reward Models (PRM)을 사용하여 LMMs의 reasoning capabilities를 enhance하는 것을 explore합니다. However, 이러한 PRM-based approaches는 typically powerful closed-source models를 사용하여 large amounts of training data를 generate해야 하므로, high computational and financial costs가 발생합니다. Concurrent work R1-V는 geometry problems 및 object counting tasks와 같은 specific subdomains에서 rule-based RL을 explores하지만, general domains 및 agent-related applications에서의 exploration은 lacks합니다.
2. Related Work 정리 노트 (AI 연구자 대상)
LMM 연구 동향 (이 논문 이전):
- 초점: 대부분 visual capabilities 향상에 집중 (e.g., visual question answering, visual grounding, instruction-following).
- 대표 모델: Flamingo, BLIP2, LLaVA series, MiniGPT-4, mPLUG-Owl series, VisionLLM, KOSMOS 2, Shikra, Qwen-VL series, InternVL, GPT-4V, Gemini.
- 최근 트렌드: Mixture-of-Experts (MoE) approaches (DeepSeek-VL2, Uni-MoE, MoVA, MoME), vision understanding & generation 통합 (SEED-X, Chameleon, Show-o, Transfusion, Janus).
- 한계: 대부분의 LMMs는 여전히 reasoning capabilities 부족.
LLMs & LMMs에서의 Reinforcement Learning (RL):
- LLMs: RL, 특히 RLHF가 capabilities 향상 (특히 reasoning)에 key methodology로 자리 잡음.
- 성공 사례: DeepSeek-R1, Kimi-1.5 (rule-based reward를 통해 reasoning abilities 향상).
- LMMs: RL을 활용한 reasoning capabilities 향상 연구는 초기 단계.
- 기존 연구: Process Reward Models (PRM) 사용 (high computational & financial costs 발생).
- Concurrent work (R1-V): specific subdomains (geometry problems, object counting)에서 rule-based RL 탐구, but general domains & agent-related applications에서는 부족.
이 논문의 Contribution (LMM-R1) 암시:
- 기존 LMM 연구들이 간과했던 "reasoning capabilities 부족" 문제를 해결하고자 함.
- LMMs에서 rule-based RL을 효과적으로 활용하는 새로운 방법을 제시 (특히, general domains & agent-related applications에서).
- (이전 섹션 1. Introduction과 연결) Two-stage training (FRE & MGT)을 통해 data efficiency & reasoning generalization 달성.
쉬운 설명:
- LMM 연구 동향:
- 지금까지: 대부분의 LMM 연구는 "이미지를 얼마나 잘 이해하고 설명하는가"에 집중했어요. 예를 들어, 이미지 속 물체가 뭔지 맞추거나, 이미지를 보고 질문에 답하거나, 이미지를 설명하는 글을 쓰는 거죠.
- 최근에는: 여러 개의 작은 모델들을 합쳐서 더 똑똑하게 만들거나(MoE), 이미지 이해와 생성을 한 번에 하는 모델들도 나오고 있어요.
- 문제점: 그런데! 정작 중요한 "추론 능력" (이미지와 텍스트를 종합해서 논리적으로 생각하는 능력)은 아직 부족하다는 거예요.
- Reinforcement Learning (RL)의 활용:
- LLM에서는: RL, 특히 사람이 피드백을 주는 방식(RLHF)이 모델을 똑똑하게 만드는 데 큰 역할을 했어요. 특히, 규칙에 따라 보상을 주는 방식(rule-based reward)이 추론 능력을 키우는 데 효과적이라는 게 밝혀졌죠.
- LMM에서는: RL을 써서 추론 능력을 키우려는 연구는 아직 걸음마 단계예요.
- 기존 연구: 복잡한 방법(PRM)을 쓰긴 하는데, 돈도 많이 들고 계산도 많이 필요해요.
- 비슷한 시기 연구: 특정 분야(도형 문제, 물체 개수 세기)에서는 rule-based RL을 시도해봤지만, 더 넓은 범위나 실제 활용에는 적용해보지 않았어요.
- 그래서 이 논문은:
- 기존 LMM 연구들이 놓치고 있던 "추론 능력" 문제를 해결하려고 해요.
- LMM에 rule-based RL을 효과적으로 적용하는 새로운 방법을 제시해서, 더 다양한 분야에서 활용할 수 있게 하고, 실제 문제 해결에도 도움이 되게 하려는 거죠.
- (1. Introduction에서 설명한) 두 단계 학습 방법(FRE & MGT)을 통해 적은 데이터로도 좋은 성능을 내고, 배운 추론 능력을 여러 분야에 적용할 수 있게 하려는 거예요.
3. Preliminaries
3.1. Reinforcement Learning for LMMs
우리는 LMMs를 train하기 위해 Proximal Policy Optimization (PPO) algorithm을 사용하며, 이는 다음 objective function을 maximize하는 것을 목표로 합니다.
L(θ) = Ey∼πθ [r(y) - β * KL(πθ(y|I, x) || πθ0 (y|I, x))]
- y: generated answer
- I: image input (있는 경우)
- x: text prompt
- πθ: policy model
- πθ0: fixed initial policy
- β: Kullback-Leibler divergence (KL) penalty coefficient
3.2. Reward Function
우리는 rule-based RL을 위해 two-part reward function을 designing하는 데 있어 다음을 따릅니다.
Format Reward. 우리는 먼저 responses가 required structured format을 따르는지 evaluate합니다. 즉, reasoning을 <reasoning> 태그로 wrapping하고, final answer를 <final_answer> 태그로 wrapping합니다. 이 format은 model이 final answer를 providing하기 전에 its reasoning process를 explicitly demonstrate하도록 encourages하며, 이는 readability 및 reasoning quality를 evaluating하는 데 crucial합니다.
Accuracy Reward. 두 번째 metric은 solution의 correctness를 evaluates합니다. 우리는 model’s answer와 ground-truth solution을 모두 comparable representations로 parses하는 symbolic verification approach를 employ합니다. 그런 다음 이러한 representations는 exact string matching이 아닌 equivalence를 checked하여, different but equivalent expressions가 correct로 recognized될 수 있도록 합니다.
final reward function r(y)는 다음과 같이 간단하게 described될 수 있습니다.
r(y) = α * rf(y) + ra(y)
- rf(y): format reward
- ra(y): accuracy reward
- α: accuracy와 비교하여 format이 얼마나 important한지를 adjusts하는 parameter
이 reward function은 model이 correct solutions를 produce할 뿐만 아니라, its reasoning process를 structured manner로 articulate하도록 effectively guide할 수 있습니다.
4. LMM-R1: Two-Stage Rule-based RL
DeepSeek-R1을 DeepSeek-R1-Zero에서 develop하는 데 사용된 approach에서 inspired되어, 우리는 multimodal reasoning model training을 두 단계로 나눕니다. (1) high-quality text-only를 사용하는 rule-based RL로 model’s foundational reasoning ability를 Increase합니다. (2) three distinct and complex multimodal reasoning tasks에서 reasoning ability를 independently Generalize합니다.
4.1. Foundational Reasoning Enhancement (FRE)
base model의 foundational reasoning ability를 enhance하기 위해, 우리는 두 가지 complementary approaches를 explore합니다.
Text-Only Reasoning Enhancement: 우리는 rule-based RL을 위해 large-scale 및 high-quality verifiable text-only data를 utilize합니다. 이 approach는 existing multimodal reasoning tasks에 비해 inherently more challenging하고 more complex reasoning processes를 demand하는 a wide variety of text-based reasoning problems를 leverages합니다. 이러한 rich textual reasoning tasks에 대한 training을 통해, 우리는 model에 대한 strong foundational reasoning capabilities를 develop하는 것을 aim하며, 이는 potentially multimodal contexts로 transferred될 수 있습니다.
Multimodal Reasoning Enhancement: As a comparison, 우리는 또한 rule-based RL training을 위해 available multimodal verifiable data를 utilize합니다. 이 data는 quality가 more limited하지만, 이 approach는 model에게 multimodal domain에 대한 direct exposure를 provides합니다. As a result, 이는 multimodal reasoning tasks에 대한 more immediate benefits를 offers하고 model’s ability to understand visual contexts를 enhances합니다.
4.2. Multimodal Generalization Training (MGT)
model의 foundational reasoning capabilities를 enhancing한 후, 우리는 이러한 capabilities가 diverse multimodal domains으로 얼마나 잘 generalize되는지 evaluating하는 데 focus합니다. 우리는 multimodal intelligence의 different aspects를 test하는 두 가지 distinct domains에 걸쳐 evaluate합니다: General Multimodal Reasoning Domain과 Agent-Related Reasoning Domain. 이러한 domains에 대한 continuing RL training을 통해, 우리는 model의 multimodal reasoning ability를 improve하는 것을 aim합니다.
4.2.1. General Multimodal Reasoning Domain
이 domain은 image contents와 texts 모두를 based on reasoning을 perform하는 visual perception ability에 focuses합니다.
Visual Reasoning-Centric Geometric Domain (Geo): 우리는 initial reasoning enhancement stage와 multimodal applications 사이의 natural bridge 때문에 geometric reasoning을 continued RL training을 위한 our first domain으로 select합니다. 이 domain은 FRE stage에서 사용된 mathematical reasoning과 structural similarities를 shares하면서 visual perception challenges를 introduces합니다. geometric problems에 대한 continuing RL training을 통해, model은 visual information을 extract하고 mathematical reasoning을 apply하는 것을 learns합니다. 이 domain은 model이 이미 geometric concepts에 대한 rich pretrained knowledge를 possesses하고 data distribution이 FRE stage와 similar하기 때문에 relatively simple합니다.
Perception-Reasoning Balanced Domain (PerceReason): For our second continued RL training domain, 우리는 visual question answering, document understanding, mathematical reasoning, scientific reasoning을 포함하여 20개 이상의 distinct datasets에서 a broad spectrum of multimodal tasks를 employ합니다. 이 diverse training domain은 model을 various visual contexts와 reasoning problems에 simultaneously exposes합니다. 이 comprehensive collection에 대한 continuing RL training을 통해, model은 its reasoning capabilities를 adapt하여 heterogeneous inputs and tasks를 handle해야 하며, 이는 real-world application scenarios를 mirroring합니다. 이 domain은 model이 rich pretrained multimodal knowledge를 가지고 있지만 data distribution이 FRE stage와 significantly 다르기 때문에 moderate challenge를 presents합니다. 이 stage는 FRE stage training을 통해 reasoning ability를 enhancing하는 것이 strong foundation model을 builds하는지 evaluates합니다. The foundation model은 continued reinforcement learning을 통해 various challenging multimodal domain으로 efficiently transferred될 것으로 expected됩니다.
4.2.2. Agent-Related Reasoning Domain
complex visual environments에서 agent로서 act하는 model’s ability를 evaluate and enhance하기 위해, 우리는 enhanced reasoning capabilities가 visual contexts에서 sequential decision-making과 planning을 requiring하는 tasks로 얼마나 잘 transfer되는지 evaluate하기 위해 MageBench를 follow합니다. 우리는 다음에 나오는 MageBench에서 two domains을 select합니다.
Sokoban Planning Domain: Sokoban은 agent가 boxes를 designated target locations로 push해야 하는 classic puzzle game입니다. 이 domain은 model’s spatial reasoning과 planning capabilities를 evaluates하며, model은 potential moves를 visualize하고, deadlocks를 anticipate하고, optimal sequence of actions를 generate해야 합니다.
Football Game Domain: 이 domain은 model을 multi-agent football environment에 places하며, model은 game objectives를 achieve하기 위해 a player를 control해야 합니다. The model은 teammates와 opponents의 positions을 based on strategic decisions를 make해야 하며, competitive setting에서 cooperation과 interaction skills를 demonstrating합니다.
In addition, 우리는 또한 model’s agent capabilities를 enhance하기 위해 rule-based RL을 통해 Sokoban에서 model을 continually train하여, agent domains에서 our approach’s effectiveness를 further validating합니다. Notably, 이러한 domains은 model이 pretraining 동안 encountered하지 않은 scenarios를 represent하며, data distributions가 our first-stage rule-based RL training과 significantly 다르기 때문에 generalization의 challenging test 역할을 합니다.
4. LMM-R1: Two-Stage Rule-based RL 정리 노트 (AI 연구자 대상)
핵심 아이디어: LMM-R1 = Two-Stage Training (FRE + MGT)
- DeepSeek-R1에서 영감: DeepSeek-R1-Zero에서 DeepSeek-R1을 개발한 방식처럼, multimodal reasoning model training을 두 단계로 나눔.
1단계: Foundational Reasoning Enhancement (FRE)
- 목표: base model의 foundational reasoning ability 강화.
- 두 가지 접근 방식 (비교):
- Text-Only Reasoning Enhancement (핵심): large-scale, high-quality, verifiable text-only data를 사용한 rule-based RL.
- 장점: Multimodal data보다 challenging & complex reasoning problems를 다룸 → strong foundation.
- 가정: Text-only reasoning skills → Multimodal contexts로 transfer 가능.
- Multimodal Reasoning Enhancement (비교군): available multimodal verifiable data를 사용한 rule-based RL.
- 장점: Multimodal domain에 대한 direct exposure → Multimodal reasoning tasks에 immediate benefits.
- 단점: Data quality가 상대적으로 낮음.
- Text-Only Reasoning Enhancement (핵심): large-scale, high-quality, verifiable text-only data를 사용한 rule-based RL.
2단계: Multimodal Generalization Training (MGT)
- 목표: FRE에서 강화된 reasoning capabilities를 diverse multimodal domains으로 generalize.
- 두 가지 Domain:
- 4.2.1 General Multimodal Reasoning Domain:
- Visual Reasoning-Centric Geometric Domain (Geo): FRE stage와 structural similarities, visual perception challenges 도입 (상대적으로 쉬움).
- Perception-Reasoning Balanced Domain (PerceReason): 다양한 multimodal tasks (visual QA, document understanding, mathematical/scientific reasoning) 포함 (난이도 중간). FRE로 얻은 foundation이 효과적인지 검증.
- 4.2.2 Agent-Related Reasoning Domain:
- Sokoban Planning Domain: spatial reasoning & planning capabilities 평가.
- Football Game Domain: multi-agent environment, strategic decision-making, cooperation & interaction skills 평가.
- 추가 Training: Sokoban에서 rule-based RL로 continual training → agent capabilities 강화.
- 핵심: Pretraining에서 접하지 못한 scenarios → generalization 능력 평가 (data distribution이 FRE와 significantly different).
- 4.2.1 General Multimodal Reasoning Domain:
이 논문만의 차별점/강조점:
- Text-only data의 중요성 재확인: FRE 단계에서 text-only data를 활용한 rule-based RL이 foundational reasoning 강화에 효과적임을 강조.
- Two-stage training의 체계화: FRE (text-only) → MGT (multimodal)로 이어지는 체계적인 training framework 제시.
- Generalization 능력 검증: 다양한 multimodal domains (general & agent-related)에서의 실험을 통해 generalization 능력 검증.
쉬운 설명:
LMM-R1 훈련 방법 (두 단계):
- 1단계: 기초 체력 훈련 (FRE)
- 목표: 이미지 없이, 텍스트만 가지고 추론하는 능력을 빡세게 키우는 단계입니다. (마치 수학 문제만 잔뜩 풀면서 기본기를 다지는 것과 비슷)
- 방법:
- 주로: 엄청나게 많은 양의 텍스트 문제들을 풀게 합니다. (정답이 확실한 문제들만!)
- 비교: 이미지랑 텍스트가 같이 있는 문제들도 풀어보게 합니다. (하지만 양이 적고, 난이도가 텍스트 문제만큼 높지 않음)
- 핵심: 텍스트만으로도 추론 능력을 충분히 키울 수 있고, 이게 나중에 이미지랑 같이 추론할 때도 도움이 된다!
- 2단계: 실전 응용 훈련 (MGT)
- 목표: 1단계에서 키운 추론 능력을 바탕으로, 이미지랑 텍스트가 섞여 있는 다양한 문제들을 풀어보는 단계입니다.
- 두 가지 종류의 문제:
- 일반적인 문제 (General Multimodal Reasoning):
- 도형 문제: 그림 보고 도형 넓이 계산하기 (1단계에서 배운 수학 지식 + 이미지 정보 활용)
- 종합 문제: 이미지 보고 질문에 답하기, 문서 이해하기, 과학 문제 풀기 등등 (다양한 종류의 문제)
- 에이전트 관련 문제 (Agent-Related Reasoning):
- 소코반 게임: 상자 밀어서 목표 지점에 옮기기 (공간 추론 능력 + 계획 능력 필요)
- 축구 게임: 축구 경기에서 선수 조작하기 (상황 판단 능력 + 협동 능력 필요)
- 추가 훈련: 소코반 게임만 따로 더 훈련시켜서 에이전트 능력 향상
- 일반적인 문제 (General Multimodal Reasoning):
- 핵심: 1단계에서 텍스트로만 훈련했는데도, 2단계에서 이미지랑 텍스트 섞인 문제들을 잘 풀 수 있다! → 훈련 방법이 효과적이다!
이 논문이 강조하는 것:
- "텍스트만으로 추론 능력 키우는 게 진짜 중요해!"
- "기초 체력(텍스트 추론) → 실전 응용(이미지+텍스트)" 순서로 훈련하는 게 효과적이야!"
- "이렇게 훈련하면 다양한 문제들에 다 잘 적응할 수 있어!"
