LLM : 논문리뷰 : Reverse Thinking Makes LLMs Stronger Reasoners
Abstract
Reverse thinking은 인간 추론에서 중요한 역할을 합니다. 인간은 문제에서 해결책으로 추론할 수 있을 뿐만 아니라 그 반대로, 즉 해결책에서 시작하여 문제를 향해 추론할 수도 있습니다. 이를 통해 사고의 앞뒤를 일관성 있게 확인할 수 있으므로 전반적인 추론 성능이 향상되는 경우가 많습니다. Large Language Models (LLM)이 Reverse thinking을 수행할 수 있도록 하기 위해 데이터 augmentation 및 학습 목표로 구성된 프레임워크인 Reverse-Enhanced Thinking (REVTHINK)을 소개합니다. REVTHINK에서 (1) 원래 질문, (2) 순방향 추론, (3) 역방향 질문, (4) 역방향 추론으로 구성된 teacher model에서 구조화된 순방향-역방향 추론을 수집하여 데이터셋을 보강합니다. 그런 다음 세 가지 목표를 사용하여 multi-task 학습 방식으로 더 작은 student model을 훈련합니다. (a) 질문에서 순방향 추론을 생성하고, (b) 질문에서 역방향 질문을 생성하고, (c) 역방향 질문에서 역방향 추론을 생성합니다. 상식, 수학 및 논리적 추론을 다루는 12개 데이터셋에 대한 실험은 student model의 zero-shot 성능에 비해 평균 13.53% 향상되었으며 가장 강력한 knowledge distillation baseline에 비해 6.84% 향상되었음을 보여줍니다. 또한 이 방법은 샘플 효율성을 보여줍니다. 훈련 데이터에서 정확한 순방향 추론의 10%만 사용하여 10배 더 많은 순방향 추론으로 훈련된 표준 fine-tuning 방법보다 성능이 뛰어납니다. REVTHINK은 또한 분포 외 보류 데이터셋에 대한 강력한 일반화를 보여줍니다.
Abstract 정리 노트
주제: Large Language Model (LLM) 의 추론 능력 향상
핵심 아이디어: 인간의 '역방향 사고' (Reverse Thinking) 를 LLM에 적용하여 추론 능력을 향상시키는 방법
Reverse Thinking 이란?
- 문제에서 답을 찾는 '순방향 사고' 뿐 아니라, 답에서 문제를 유추하는 '역방향 사고' 를 통해 사고의 일관성을 확인하고 추론 능력을 높이는 것
REVTHINK (Reverse-Enhanced Thinking) 프레임워크:
- LLM에 역방향 사고를 적용하기 위한 프레임워크
- 데이터 augmentation과 학습 목표를 통해 LLM을 훈련
데이터 augmentation:
- Teacher model을 사용하여 구조화된 순방향-역방향 추론 데이터를 수집
- 원래 질문, 순방향 추론, 역방향 질문, 역방향 추론으로 구성
학습 목표:
- Student model을 multi-task learning 방식으로 훈련
- 질문에서 순방향 추론 생성
- 질문에서 역방향 질문 생성
- 역방향 질문에서 역방향 추론 생성
실험 결과:
- 12개 데이터셋 (상식, 수학, 논리적 추론) 에서 평균 13.53% 성능 향상 (zero-shot 대비)
- Knowledge distillation baseline 대비 6.84% 성능 향상
- 샘플 효율성: 적은 양의 데이터로도 높은 성능 달성
- Out-of-distribution 데이터셋에서도 강력한 일반화 능력 보임
결론:
REVTHINK 프레임워크를 통해 LLM의 추론 능력을 효과적으로 향상시킬 수 있음
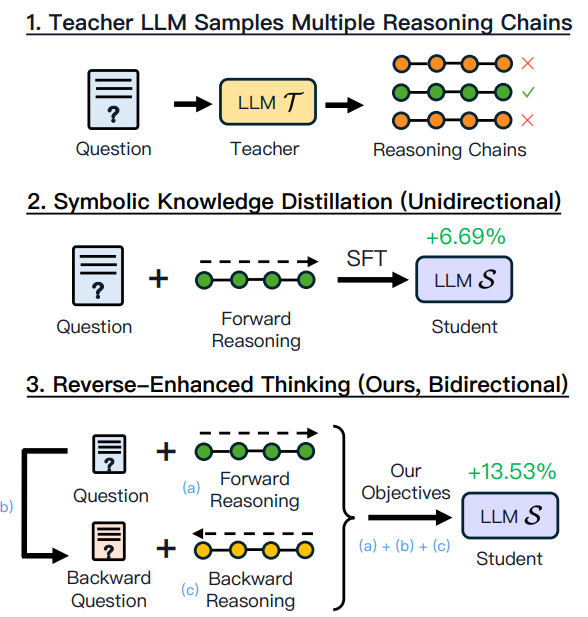
그림 1: Symbolic Knowledge Distillation (SKD)과 본 연구 방법의 비교.
(1) teacher model은 주어진 질문에 대해 여러 개의 추론 체인을 생성합니다. (2) SKD는 정확한 추론 체인에서 supervised fine-tuning을 수행합니다. (3) 본 연구 방법은 양방향 추론을 통합하여 multi-task 목표를 사용하여 Q에서 A와 A에서 Q 모두에서 학습합니다.
1 Introduction
"항상 뒤집어라." - Carl Jacobi
Reverse thinking은 인간의 추론 과정에서 중요한 역할을 합니다. 예를 들어 수학 시험을 생각해 보세요. 시험 점수를 높이는 효과적인 방법은 순방향과 역방향 모두 추론하는 것입니다. 순방향 추론에서는 질문으로 시작하여 단계별로 답을 구합니다. 반면에 Reverse thinking은 예상 답변에서 시작하여 원래 질문으로 거슬러 올라갑니다. 이러한 양방향 접근 방식을 통해 솔루션의 정확성을 확인하고 잠재적인 오류를 식별할 수 있습니다. Emma에게 사과가 두 개 있고 Jack에게 사과가 세 개 있는 간단한 수학 문제를 생각해 보세요. 그들은 함께 몇 개를 가지고 있을까요? 순방향 추론은 2 + 3 = 5라는 계산으로 이어집니다. Reverse thinking을 사용하면 그들이 사과 5개를 가지고 있다는 결론부터 시작합니다. Emma에게 두 개가 있는 경우 Jack에게는 몇 개가 있을까요? 결과는 3개이며 원래 문제와 일치하고 솔루션이 정확함을 확인합니다. 그러나 순방향 추론에서 실수로 답을 6으로 예측하면 Reverse thinking에서 충돌이 발생합니다. 그들에게는 사과가 6개 있고 Emma에게는 2개가 있으므로 Jack에게는 4개가 있어야 하는데 이는 원래 문제와 모순됩니다. 이러한 불일치는 솔루션을 재평가하고 개선해야 함을 나타냅니다.
이전 연구에서는 Large Language Models (LLM)이 수학에서 순방향-역방향 추론의 이점을 얻는다는 것을 보여주었습니다. 이는 주로 두 가지 요인 때문입니다. (1) 순방향 및 역방향 추론 간의 명확한 역 관계를 촉진하는 수학의 고도로 구조화된 특성과 (2) 이름이나 숫자와 같은 변수를 간단히 바꾸어 새로운 수학 문제를 만들 수 있는 기능입니다. 이러한 요인은 첫 번째 연구 질문으로 이어집니다. Reverse thinking을 더 광범위하고 덜 구조화된 도메인에 적용할 수 있을까요? 또한 이러한 방법은 테스트 시에 검증 목적으로 작동합니다. 솔루션이 주어지면 LLM에 역방향으로 생각하고 순방향 추론이 맞는지 여부를 확인하도록 요청할 수 있습니다. Self-Consistency와 같은 다른 테스트 시간 방법에 비해 적당한 개선을 보여주지만 두 번째 질문을 제기합니다. 테스트 시 검증을 위해 역방향 추론을 사용하는 대신 모델을 훈련하여 본질적으로 역방향으로 생각하도록 하여 순방향 추론을 개선할 수 있을까요?
이러한 연구 질문에 답하기 위해 언어 모델에 Reverse thinking을 주입하도록 설계된 데이터 augmentation 및 새로운 학습 목표로 구성된 프레임워크인 REVTHINK을 제안합니다. 더 크고 더 유능한 teacher model을 사용하여 데이터셋을 보강하는 것으로 시작합니다. 추론 벤치마크 데이터는 일반적으로 질문과 답변으로 구성됩니다. teacher model에서 few-shot 프롬프트를 통해 (1) 순방향 추론, (2) 역방향 질문, (3) 역방향 추론을 생성하여 이를 확장합니다. 순방향 및 역방향 추론은 모두 Chain-of-Thought입니다. 순방향 추론이 정확하고 (ground truth에 대해 확인됨) 역방향 추론이 원래 질문과 일치하는 데이터 포인트만 유지합니다 (teacher model을 프롬프트하여 검증됨). 데이터셋을 보강한 후 더 작은 student model을 훈련하기 위한 세 가지 주요 목표를 제안합니다. 특히 학생은 (1) 질문에서 올바른 순방향 추론을 생성하고, (2) 원래 질문에서 역방향 질문을 생성하고, (3) 역방향 질문에서 역방향 추론을 생성하는 방법을 배웁니다. 이러한 목표의 근거는 세 가지입니다. 첫째, 질문에서 올바른 추론을 생성하는 것은 knowledge distillation의 표준 방법입니다. 둘째, 역방향 질문을 생성하면 student model이 문제를 뒤집는 방법을 "생각"하고 질문할 올바른 질문을 결정하도록 권장합니다. 마지막으로 역방향 질문을 해결하면 학생의 역방향 추론 능력이 강화됩니다. 테스트 시 student model에 질문이 표시되고 표준 zero-shot 추론과 유사하게 순방향 추론만 생성합니다. 본질적으로 파이프라인은 훈련 중에 역방향으로 추론하는 기능을 내재화하는 동시에 테스트 시간 계산을 zero-shot 접근 방식만큼 효율적으로 유지합니다. 그림 1에 표시된 것처럼 기존의 supervised fine-tuning은 질문에서 답변까지 단방향 추론에 중점을 둡니다. 이와 대조적으로 REVTHINK는 데이터 augmentation 방법과 제안된 목표를 통해 양방향으로 추론하는 방법을 학습하여 양방향 사고를 도입하여 더 큰 개선을 가져옵니다.
Mistral-7B-Instruct 및 Gemma-7B-Instruct의 두 가지 모델을 사용하여 상식 추론, 수학적 추론, 논리적 추론 및 자연어 추론에서 12개의 다양한 데이터셋에 대해 REVTHINK을 평가합니다. 결과는 파이프라인을 통해 역방향으로 생각하는 법을 배우면 성능이 지속적으로 향상되어 학생의 zero-shot 성능에 비해 평균 13.53%, 널리 사용되는 Symbolic Knowledge Distillation (SKD) 방법에 비해 6.84% 향상되었음을 보여줍니다. REVTHINK은 또한 다른 데이터 augmentation baseline과 비교하여 4.52% − 7.99%의 유사한 이득을 보여줍니다. 분석에서는 또한 REVTHINK가 샘플 효율성을 보여준다는 점을 강조합니다. 여기서 리소스가 부족한 체제에서는 훈련 인스턴스의 10%만 사용하면 (방법으로 보강됨) 전체 훈련 세트에 적용된 SKD의 성능을 능가합니다 (순방향 추론 사용). 또한 REVTHINK는 student model 크기가 2B에서 176B로 확장됨에 따라 긍정적으로 확장되어 후자가 25배 더 많은 매개변수를 가지고 있음에도 불구하고 7B 모델에서 176B 모델의 zero-shot 성능보다 더 나은 결과를 얻습니다. 또한 REVTHINK은 보이지 않는 데이터셋으로 잘 일반화되고 기존 데이터 augmentation 기술을 보완합니다.
1 Introduction 정리 노트
주제: Large Language Model (LLM)의 추론 능력 향상
핵심 아이디어: 인간의 '역방향 사고'(Reverse Thinking)를 LLM에 적용하여 추론 능력을 향상시키는 방법
Reverse Thinking 이란?
- 문제에서 답을 찾는 '순방향 사고' 뿐 아니라, 답에서 문제를 유추하는 '역방향 사고'를 통해 사고의 일관성을 확인하고 추론 능력을 높이는 것
- 예시: 엠마와 잭의 사과 개수 문제를 통해 순방향/역방향 추론 과정과 오류 검증 방식 설명
기존 연구의 한계:
- 수학 문제처럼 구조화된 영역에만 적용 가능
- 테스트 시점에서 검증 용도로만 사용 (모델 자체의 추론 능력 향상에는 기여 X)
본 연구의 목표:
- Reverse Thinking을 덜 구조화된 영역에도 적용 가능하도록 확장
- 모델 학습 단계에서 역방향 사고를 적용하여 모델 자체의 추론 능력 향상
REVTHINK (Reverse-Enhanced Thinking) 프레임워크:
- LLM에 역방향 사고를 적용하기 위한 프레임워크
- 데이터 augmentation과 새로운 학습 목표를 통해 LLM을 훈련
데이터 augmentation:
- Teacher model을 사용하여 구조화된 순방향-역방향 추론 데이터를 수집
- 원래 질문, 순방향 추론, 역방향 질문, 역방향 추론으로 구성
- Teacher model의 판단을 통해 정확한 데이터만 선별
학습 목표:
- Student model을 multi-task learning 방식으로 훈련
- 질문에서 순방향 추론 생성 (기존 knowledge distillation)
- 질문에서 역방향 질문 생성 (문제 뒤집기 능력 향상)
- 역방향 질문에서 역방향 추론 생성 (역방향 추론 능력 강화)
REVTHINK의 장점:
- 훈련 과정에서 역방향 추론 능력을 내재화하여 모델 자체의 추론 능력 향상
- 테스트 시에는 순방향 추론만 사용하여 효율적인 계산 유지
- 기존 방법 (단방향 추론) 과 달리 양방향 추론을 통해 더 큰 성능 향상 가능
실험 결과:
- 다양한 데이터셋에서 성능 향상, 샘플 효율성, 모델 크기 확장성, 일반화 능력 등을 입증
참고: 전문성을 위해 AI 관련 용어는 원문 그대로 유지되었습니다.
2 Related Work
LLM을 이용한 추론. 많은 연구에서 LLM 추론은 프롬프트 및 aggregation과 같은 고급 테스트 시간 접근 방식을 통해 개선될 수 있음을 보여주었습니다. 대표적인 방법으로는 Chain-of-Thought (CoT), Self-Consistency, Tree-of-Thought 프롬프트, Self-Reflection, Multi-agent collaboration 등이 있습니다. 여러 연구에서 역방향 추론을 활용하여 사고의 연쇄를 확인하고 수학적 추론을 개선하는 것이 제안되었지만 이러한 방법은 테스트 시간에 작동하여 self-consistency와 같은 다른 테스트 시간 방법에 비해 적당한 개선을 보여줍니다. 또한 이러한 방법은 대부분 수학적 작업을 위해 개발되어 일반화 가능성이 제한적입니다. 이와 대조적으로 REVTHINK는 신중하게 선별된 데이터를 사용하여 student model을 훈련하여 구조화된 방식으로 역방향 추론 기술을 개발할 수 있도록 합니다. 이 접근 방식은 zero-shot 프롬프트와 동일한 테스트 시간 효율성을 유지하면서 더 큰 개선을 제공하고 더 광범위한 작업으로 일반화합니다.
Knowledge Distillation. Knowledge Distillation은 더 큰 teacher model에서 더 작은 student model로 지식을 전달하는 효과적인 방법입니다. 고전적인 Knowledge Distillation은 teacher model의 분포에서 학습하며 목표는 teacher와 함께 student 분포를 최소화하는 것입니다. LLM의 최근 발전으로 인해 이러한 더 큰 모델의 출력을 활용하는 데 중점을 두게 되었습니다. Teacher model은 teacher에서 직접 샘플링하거나, 부트스트래핑을 통해 생성하거나, 여러 teacher model에서 얻을 수 있는 Chain-of-Thought 근거를 제공합니다. 또한 teacher model 출력을 사용하여 ground truth 데이터를 보강할 수 있습니다. 방법은 이러한 최근 추세와 일치하여 teacher model을 활용하여 CoT 추론을 생성하고 역방향 질문 및 역방향 추론과 함께 데이터를 보강합니다. 일련의 작업은 수학 관련 데이터 세트를 부트스트래핑하여 수학적 추론을 개선하는 데 중점을 둡니다. 섹션 1에서 주장하는 바와 같이 수학적 추론은 본질적으로 구조화되어 있어 이름과 변수를 수정하여 부트스트래핑에 더 적합합니다. 마찬가지로 Guo et al.은 기존 수학 데이터 세트를 뒤집고 강력한 LLM조차도 이를 해결하는 데 어려움을 겪는다는 것을 발견했습니다. 이는 이러한 모델이 진정한 이해 없이 문제를 암기하고 있음을 의미합니다. 우리가 아는 한, 우리는 광범위한 추론 작업에서 더 작은 student model에 역방향 추론을 가르치려는 첫 번째 시도입니다.
Dual Learning. Dual Learning은 기계 번역, 대화 생성 및 질문 답변에서 광범위하게 연구되었습니다. 핵심 개념은 번역에서 영어와 독일어 간의 양방향 관계와 같이 task에 내재된 primal-dual 구조를 활용하는 것입니다. 이러한 이중성은 훈련 중에 일종의 정규화 역할을 하여 두 작업 모두에서 성능을 향상시킵니다. REVTHINK는 또한 추론 기능을 향상시키기 위해 정규화의 한 형태로 역방향 질문 생성 및 역방향 추론을 통합합니다. Dual Learning은 우리 작업과 밀접한 관련이 있지만 기계 번역의 소스-대상 언어 쌍과 같이 이전 연구에서 설정된 이중 관계는 비교적 간단합니다. 이와 대조적으로 우리는 질문과 그 역방향 질문 간의 상호 역 관계에 중점을 둡니다. 추론 작업에서 역방향 질문과 역방향 추론은 종종 없으며 LLM에서 생성해야 합니다. 우리의 혁신은 순방향 추론이 있는 순방향 질문과 역방향 추론이 있는 역방향 질문 간의 연결을 설정하여 훈련 목표 내에서 이 연결의 일관성을 활용하는 데 있습니다.
2 Related Work 정리 노트
주제: REVTHINK 프레임워크 관련 연구 동향
1. LLM을 이용한 추론
- 기존 연구의 한계:
- 대부분 수학 문제처럼 답이 명확하고 구조화된 영역에만 효과적
- 테스트 시점에서 답변 검증 용도로만 사용, 모델 자체의 추론 능력 향상에는 기여 X
- REVTHINK의 차별점:
- 구조화되지 않은 영역에도 적용 가능
- 학습 단계에서 역방향 추론을 활용하여 모델 자체의 추론 능력 향상
- 효율적인 테스트 시간 유지
2. Knowledge Distillation
- 기존 연구의 한계:
- Teacher model의 답변만 학습시키는 방식에 집중
- REVTHINK의 차별점:
- Teacher model을 활용하여 순방향/역방향 추론, 역방향 질문 등 풍부한 데이터 생성
- 이를 통해 Student model의 다양한 추론 능력 향상
3. Dual Learning
- 기존 연구의 한계:
- 번역이나 질문-답변처럼 쌍으로 이루어진 task에만 적용
- Dual 관계가 비교적 단순 (예: 영어-한국어 번역)
- REVTHINK의 차별점:
- 질문과 역방향 질문 간의 복잡한 관계에 적용
- LLM을 사용하여 역방향 질문 및 추론 생성
- 순방향/역방향 질문 및 추론 간의 연결을 활용하여 학습 목표 설정
요약:
REVTHINK는 기존 연구들과 비교하여 다음과 같은 차별점을 가짐
- 역방향 추론: 학습 단계에서 적용하여 모델 자체의 추론 능력 향상
- 데이터 augmentation: Teacher model을 활용하여 풍부한 데이터 생성
- Dual Learning: 질문과 역방향 질문 간의 복잡한 관계에 적용
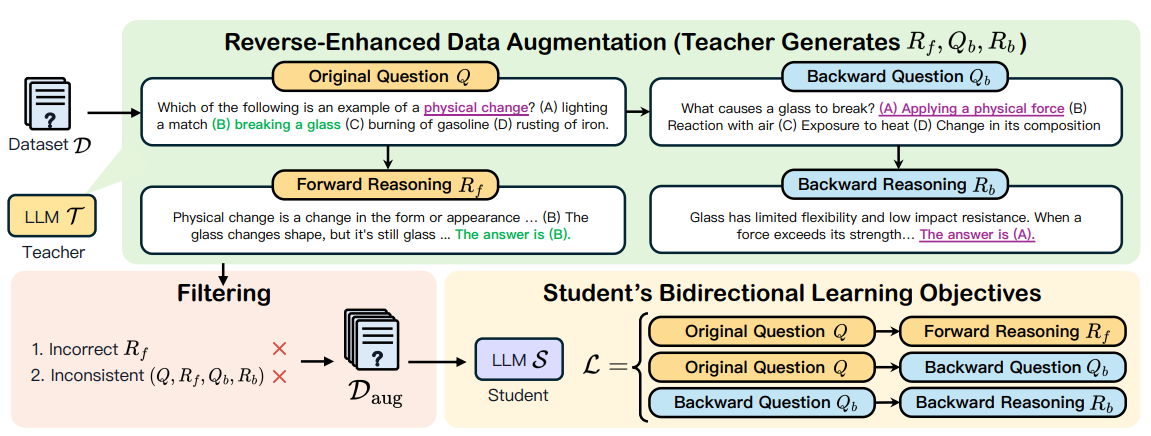
그림 2: REVTHINK는 두 단계로 구성됩니다.
(1) 데이터 augmentation 및 (2) student model 학습. 먼저 데이터셋 D = {(Q(i), A(i))}n i=1이 주어지면 teacher model에 순방향 추론, 역방향 질문 및 역방향 추론을 생성하도록 프롬프트하여 이를 보강합니다. 정확한 순방향 추론 (ground truth에 의해 검증됨)과 일관된 순방향-역방향 추론 (teacher model에 의해 검증됨)이 있는 인스턴스만 유지합니다. 이렇게 하면 보강된 데이터셋 Daug = (Q(i), R(i) f, Q(i) b, R(i) b)n i=1이 생성됩니다. 다음으로 student model을 세 가지 목표로 훈련합니다. Q → Rf, Q → Qb 및 Qb → Rb를 사용하여 학생이 훈련 중에 양방향으로 추론할 수 있도록 합니다. 테스트 시 student model은 순방향 추론만 수행하므로 테스트 시간 계산이 zero-shot 프롬프트만큼 효율적입니다.
3 Method
REVTHINK는 주로 두 단계로 구성됩니다. 섹션 3.1에서는 문제 설정에 대한 공식적인 설명을 제공합니다. 그런 다음 섹션 3.2에서는 훈련 데이터 생성에 대한 세부 정보를 설명합니다. 마지막으로 섹션 3.3에서는 학습 목표를 소개합니다.
3.1 문제 설정
D = {(Q(i), A(i))}n i=1을 n개 샘플의 데이터셋이라고 하자. 여기서 각 샘플은 질문 Q(i)와 해당 답변 A(i)로 구성됩니다. 출력은 얻을 수 있지만 teacher의 logits는 얻을 수 없는 teacher model T에 대한 블랙박스 액세스를 가정하고 목표는 더 작은 student model S를 훈련하고 추론 기능을 향상시키는 것입니다. 훈련 단계에서 teacher의 역방향 질문 및 역방향 추론 데모를 사용하여 D를 보강하여 Daug를 생성합니다. 역방향 질문은 원래 질문을 뒤집는 질문입니다. 예를 들어 수학 단어 문제가 주어졌을 때 John에게는 사과가 3개 있고 Emma에게는 2개가 있습니다. 총 몇 개의 사과가 있습니까? 해당 역방향 질문은 다음과 같습니다. John과 Emma는 총 5개의 사과를 가지고 있습니다. Emma에게 2개가 있는 경우 John에게는 몇 개가 있습니까? 역방향 추론은 이 뒤집힌 질문을 해결하는 과정을 말합니다. 그런 다음 Daug를 사용하여 student model S를 훈련합니다. 테스트 시 student model은 zero-shot 프롬프트와 유사하게 원래 질문만 묻습니다.
3.2 데이터 Augmentation
추론 데이터셋 D = {(Q(i), A(i))}n i=1이 주어지면 이를 보강하여 Daug를 생성하는 것으로 시작합니다. 여기서 Daug의 각 데이터 포인트는 (Q(i), R(i) f, Q(i) b, R(i) b)로 구성되며 각각 원래 질문, 순방향 추론, 역방향 질문 및 역방향 추론을 나타냅니다. Rf, Qb, Rb는 모두 teacher model T에서 생성됩니다. 먼저 T를 프롬프트하여 순방향 추론 Rf를 생성하고 Rf가 정답으로 이어지는 샘플만 유지합니다. 즉, g(Rf) = A입니다. 여기서 g는 답변 추출 함수입니다. 그런 다음 자세한 지침 Ibq (부록 B 참조)를 사용하여 원래 질문 Q와 ground truth 답변 A를 조건으로 하여 역방향 질문을 생성합니다. Qb = T (Q, A; Ibq).
역방향 질문을 얻은 후 teacher model에 역방향 질문에 답하여 역방향 추론을 생성하도록 프롬프트합니다. Rb = T (Qb). 일관성 없는 쌍을 필터링하기 위해 (즉, 역방향 추론이 원래 질문과 충돌을 일으키는 경우) T에 지침 Icon (부록 C 참조)을 사용하여 일관성을 확인합니다. c = T (Q, A, Qb, Rb; Icon). 여기서 c ∈ {0, 1}은 순방향-역방향 추론이 일관성이 있는지 여부를 나타냅니다. 일관성이 없는 데이터 포인트, 즉 c = 0을 필터링합니다. 즉, teacher model에 역방향 질문과 역방향 추론을 통합하도록 프롬프트하여 D를 보강하고 (1) 순방향 추론이 정확하고 (2) 질문과 일치하는 역방향 추론일 때만 샘플을 유지합니다.
3.3 학습 목표
보강된 데이터셋 Daug로 student model S를 훈련합니다. 역방향 추론 프로세스를 내재화하기 위해 다음 목표를 사용합니다.
L = (1/3n) Σ {ℓ(S(Q(i)), R(i) f) + ℓ(S(Q(i)), Q(i) b) + ℓ(S(Q(i) b), R(i) b)} (1)
여기서 ℓ은 예측된 토큰과 대상 토큰 간의 cross-entropy입니다. 특히 목적 함수 L은 보강된 데이터를 최대한 활용하는 세 가지 손실로 구성됩니다. (a) 순방향 추론 생성에서 학습, (b) 역방향 질문 생성에서 학습, (c) (b)에서 생성된 역방향 질문을 조건으로 하여 역방향 추론 생성에서 학습. 아래에서 각 구성 요소에 대한 세부 정보를 소개합니다.
(a) 순방향 추론 생성. student model은 symbolic knowledge distillation과 유사하게 원래 Q를 입력으로 받아 순방향 추론 Rf를 생성합니다.
(b) 역방향 질문 생성. student model은 여전히 Q를 입력으로 사용하지만 대신 Q와 반대로 연결된 질문인 역방향 질문 Qb를 생성하는 방법을 배웁니다.
(c) 역방향 추론 생성. student model은 역방향 질문 Qb를 입력으로 받아 Qb에 답하기 위해 역방향 추론 Rb를 생성합니다.
제안된 목표는 multi-task 학습 방식으로 모든 구성 요소를 하나로 묶는 것을 목표로 합니다. 역방향 질문 생성 학습 목표와 역방향 추론 생성 학습 목표 (목표 (b) 및 (c))는 보조 작업으로 취급됩니다. 추론하는 동안 훈련된 student model에 원래 질문에 답하도록 프롬프트합니다. 표 1과 그림 4에서 이러한 두 가지 보조 작업을 학습하면 테스트 시 성능을 더욱 향상시킬 수 있음을 보여줍니다. multi-task 학습의 또 다른 가능한 방법은 세 가지 목표를 세 가지 인스턴스로 분리하고 fine-tuning을 위해 다른 지침을 적용하는 것입니다. 경험적으로 표 2에 나와 있는 것처럼 제안된 목표가 더 효과적이라는 것을 알았습니다.
3 Method 정리 노트
주제: REVTHINK 프레임워크의 작동 방식
목표: Student model의 추론 능력 향상
핵심 과정:
- 문제 설정:
- D: 질문(Q)과 답변(A)으로 이루어진 데이터셋
- T: Teacher model (크고 뛰어난 LLM)
- S: Student model (작은 LLM)
- 목표: T를 활용하여 S의 추론 능력 향상
- 데이터 Augmentation:
- D를 D_aug로 변환
- D_aug는 Q, 순방향 추론(R_f), 역방향 질문(Q_b), 역방향 추론(R_b)으로 구성
- R_f, Q_b, R_b는 모두 T가 생성
- 필터링:
- R_f incorrect: T의 순방향 추론이 틀린 경우 제거
- inconsistent: 순방향-역방향 추론 과정이 일치하지 않는 경우 제거
- 결과적으로 D_aug는 정확하고 일관된 풀이 과정만 포함
- 학습 목표:
- D_aug를 사용하여 S를 훈련
- S는 다음 3가지 목표를 학습:
- Q → R_f: 질문에서 순방향 추론 생성
- Q → Q_b: 질문에서 역방향 질문 생성
- Q_b → R_b: 역방향 질문에서 역방향 추론 생성
- Multi-task learning: 3가지 목표를 동시에 학습
- 테스트 시에는 S에게 순방향 추론만 수행하도록 함
참고:
- T는 S의 학습을 위한 데이터를 생성하는 역할
- S는 T의 풀이 과정을 모방하여 추론 능력을 학습
- 필터링을 통해 S가 잘못된 정보를 학습하는 것을 방지
- Multi-task learning을 통해 S의 다양한 추론 능력 향상
비유:
- T: 경험 많은 베테랑 요리사
- S: 요리 학교 학생
- D: 요리 레시피
- D_aug: 베테랑 요리사가 직접 요리하는 과정을 상세히 기록한 레시피 (정확하고 일관된 정보만 포함)
- S는 D_aug를 보고 다양한 요리 기술을 익힘