DATASET : 논문리뷰 :
HourVideo: 1-Hour Video-Language Understanding
Abstract
저희는 긴 비디오에 대한 언어 이해를 위한 벤치마크 데이터셋인 HourVideo를 소개합니다. 이 데이터셋은 요약, 인지 (회상, 추적), 시각적 추론 (공간적, 시간적, 예측적, 인과적, 반사실적), 그리고 탐색 (방에서 방으로, 객체 검색) 작업을 포함하는 새로운 task suite로 구성됩니다. HourVideo는 Ego4D 데이터셋에서 20분에서 120분까지의 길이를 가진 500개의 수동으로 선별된 egocentric 비디오를 포함하며, 12,976개의 고품질 5지선다형 질문을 특징으로 합니다. 벤치마킹 결과는 GPT-4 및 LLaVA-NeXT를 포함한 multimodal models가 무작위 선택보다 약간의 개선만을 달성함을 보여줍니다. 이와는 대조적으로 인간 전문가는 최첨단 long-context multimodal model인 Gemini Pro 1.5 (85.0% vs. 37.3%)를 훨씬 능가하여 multimodal capabilities에 상당한 격차가 있음을 보여줍니다.
1 Introduction
인간은 긴 시간 동안 시각적 자극을 처리하는 놀라운 능력을 보여주며, 이를 통해 현실 세계에서 인지하고, 계획하고, 행동할 수 있습니다. 식사를 요리하는 일상적인 작업을 생각해 보세요. 이 활동에는 재료와 도구를 식별하고 사용하고, 다양한 요리의 상태 변화를 모니터링하고, 색상과 질감과 같은 시각적 신호를 기반으로 요리 시간/기술을 조정하는 등 지속적이고 적응적인 시각적 프로세스가 포함됩니다. 이러한 지속적인 시각적 처리는 원하는 요리 결과를 얻는 데 매우 중요합니다. 당연히 자율 에이전트에 이러한 기능을 부여하는 것은 인공 지능 분야의 오랜 목표였습니다.
최근 몇 년 동안 large multimodal models [1–3]은 이 목표를 달성하기 위한 유망한 접근 방식으로 부상했습니다. 일반적으로 이러한 모델은 객체 인식 [4, 5], 이미지 이해 [6–8], 동작 인식 [9]과 같은 기능을 테스트하는 여러 데이터 세트를 사용하여 평가됩니다. 그러나 이러한 벤치마크는 종종 단일 이미지 또는 짧은 비디오 클립으로 제한되며 일반적으로 몇 초에서 최대 3분까지 지속됩니다 [9–12]. 이러한 벤치마크는 상당한 발전을 이끌었지만 미래의 자율 에이전트 및 어시스턴트의 기초를 형성할 수 있는 multimodal systems을 개발하려면 long-form video-language understanding에 대한 심층적인 탐구가 필수적입니다.
long-form video-language understanding capabilities를 평가하는 데 있어 중요한 과제는 long-range dependencies가 필요한 작업, 즉 장기적인 이해가 필요한 작업을 설계하는 것입니다. 긴 비디오의 짧은 부분을 보면 답할 수 있는 질문을 하는 것은 사실상 작업을 시간적 지역화와 짧은 클립 이해의 조합으로 축소시킵니다. 또한 텔레비전 쇼 및 영화와 같은 long-form 비디오에 대해 흥미로운 내러티브 질문을 공식화할 수 있지만 최신 large language models에 인코딩된 방대한 사전 지식으로 인해 질문에 쉽게 답할 수 없는지 확인하는 것이 중요합니다.
이 작업에서 우리는 long-form video-language understanding을 위해 설계된 벤치마크 데이터셋인 HourVideo를 소개합니다. 장기적인 이해가 필요한 작업을 설계하기 위해 먼저 요약, 인지 (회상, 추적), 시각적 추론 (공간적, 시간적, 예측적, 인과적, 반사실적) 및 탐색 (방에서 방으로, 객체 검색) 작업을 포함하는 새로운 task suite (표 1)를 제안합니다. 각 작업에 대해 long-form 비디오 내의 여러 시간적 세그먼트에서 정보를 식별하고 합성해야 정확하게 답변할 수 있도록 설계된 질문 프로토타입을 수동으로 만듭니다. task suite의 안내에 따라 Ego4D 데이터셋 [13]에서 500개의 egocentric 비디오를 선별했습니다. 이 비디오는 77가지의 고유한 일상 활동을 다루며 20분에서 120분까지 지속됩니다. 프로토타입을 기반으로 질문을 생성합니다. 포괄적인 task suite와 일상적인 평범한 egocentric 비디오의 조합은 long-form 비디오를 이해하는 데 있어 multimodal models의 기능을 엄격하게 평가할 수 있는 강력한 프레임워크를 제공합니다. 마지막으로 훈련된 인간 주석자 (800시간 이상의 노력)와 large language models (LLM)의 전문 지식을 활용하는 질문-답변 생성 파이프라인을 개발하여 12,976개의 고품질 5지선다형 질문 모음을 만들었습니다.
HourVideo에서 zero-shot 설정으로 GPT-4V [2], Gemini 1.5 Pro [3], LLaVA-NeXT [14]를 포함한 최첨단 multimodal models를 포괄적으로 평가합니다 (표 2, 그림 4). 우리의 연구 결과는 GPT-4V와 LLaVA-NeXT가 무작위 예측 변수 (20%)에 비해 약간의 개선만을 달성하여 각각 25.7%와 22.3%의 정확도를 얻는다는 것을 보여줍니다. long-context multimodal understanding을 위해 특별히 설계된 Gemini 1.5 Pro는 37.3%의 정확도를 얻었는데, 이는 더 나은 수치이지만 여전히 85.0%인 인간 전문가의 평균 성능보다 상당히 낮습니다. 이러한 결과는 multimodal 커뮤니티가 의미 있는 진전을 이루었지만 이러한 시스템이 인간 수준의 long-form video understanding capabilities와 일치하려면 상당한 격차를 해소해야 함을 시사합니다. long-form video understanding의 발전은 AR 어시스턴트, embodied agents 및 대화형 비디오 플랫폼을 포함한 새로운 애플리케이션을 가능하게 할 수 있습니다. 우리는 HourVideo가 이러한 방향으로 연구를 촉진하고 끝없는 시각적 데이터 스트림을 이해할 수 있는 multimodal models의 개발을 가능하게 하는 벤치마크 역할을 하기를 바랍니다.
1 Introduction 정리 노트
주제: long-form video-language understanding (긴 비디오에 대한 언어 이해)
목표: 인간처럼 긴 시간 동안 시각 정보를 처리하여 현실 세계를 이해하고 상호 작용하는 인공지능 개발
핵심 내용:
- 인간은 요리처럼 복잡한 작업을 수행할 때 지속적인 시각 정보 처리 능력을 보여줌
- 이러한 능력을 인공지능에 부여하기 위해 large multimodal models 연구가 진행 중
- 기존 연구는 짧은 비디오에 집중되어 있음
- long-form video-language understanding 연구의 어려움:
- 장기적인 이해가 필요한 task 설계의 어려움
- 단순히 긴 비디오의 일부분만 보고 답할 수 있는 질문은 long-form video understanding을 제대로 평가할 수 없음
- large language models의 방대한 사전 지식으로 인해 질문에 쉽게 답할 수 있는 문제 발생 가능성
HourVideo 소개:
- long-form video-language understanding을 위한 새로운 벤치마크 데이터셋
- 장기적인 이해가 필요한 task suite 제안 (요약, 인지, 시각적 추론, 탐색)
- Ego4D 데이터셋에서 500개의 egocentric 비디오 (20~120분 길이) 선별
- 12,976개의 고품질 5지선다형 질문 생성 (인간 주석자와 LLM 활용)
주요 결과:
- GPT-4V, LLaVA-NeXT 등 최첨단 multimodal models는 무작위 예측보다 약간 나은 수준의 정확도를 보임
- Gemini 1.5 Pro는 더 나은 성능을 보이지만 인간 전문가에는 미치지 못함
- long-form video understanding 분야에서 인간 수준의 능력을 달성하기 위해서는 아직 해결해야 할 과제가 많음
2 Benchmark Design and Construction
open-ended question answering은 인간의 상호 작용을 밀접하게 모방하지만 free-form 자연어 응답에 대한 평가를 자동화하는 것은 여전히 어려운 과제입니다. long-form video-language understanding capabilities를 평가하는 것이 주요 목표이므로 5지선다형 질문 답변 (MCQ) task를 선택합니다. 이 접근 방식은 aggregate question-answering accuracy metric을 계산할 수 있도록 하여 평가 프로세스를 단순화합니다. 다음 섹션에서는 다양한 고품질 5지선다형 질문 (MCQ)을 선별하도록 설계된 task suite와 질문-답변 생성 파이프라인에 대해 자세히 설명합니다.
2 Benchmark Design and Construction
open-ended question answering은 인간의 상호 작용을 밀접하게 모방하지만 free-form 자연어 응답에 대한 평가를 자동화하는 것은 여전히 어려운 과제입니다. long-form video-language understanding capabilities를 평가하는 것이 주요 목표이므로 5지선다형 질문 답변 (MCQ) task를 선택합니다. 이 접근 방식은 aggregate question-answering accuracy metric을 계산할 수 있도록 하여 평가 프로세스를 단순화합니다. 다음 섹션에서는 다양한 고품질 5지선다형 질문 (MCQ)을 선별하도록 설계된 task suite와 질문-답변 생성 파이프라인에 대해 자세히 설명합니다.
2.1 Task Suite
long-form video-language understanding을 위한 포괄적인 벤치마크를 만드는 것은 어려운 일입니다. 주된 이유는 전문적인 인간 주석자에게도 다양한 시간적 세그먼트에 걸쳐 정보를 처리하고 종합해야 하는 의미 있는 질문을 공식화하는 것이 매우 까다롭기 때문입니다. 또한 이미지 또는 짧은 비디오 클립 이해를 위한 벤치마크조차도 구성하기 어렵다는 점에 유의해야 합니다. 결과적으로 벤치마크 생성을 위한 두 가지 일반적인 전략을 볼 수 있습니다. (1) 특정 기술 또는 좁은 도메인 내에서 테스트하는 미리 정의된 레이블 공간 (예: Kinetics 및 Something-Something) 또는 (2) 각각 특정 모델 기능을 테스트하도록 설계된 서로 다른 데이터 세트를 결합하는 것입니다. 이와 대조적으로 모델 기능 제품군을 포괄적으로 테스트할 수 있는 단일 벤치마크는 연구 커뮤니티에 큰 도움이 될 수 있습니다.
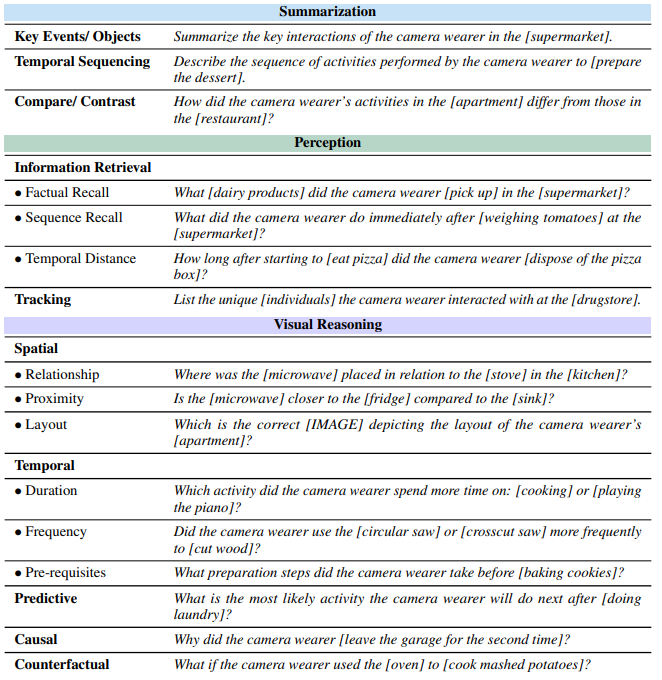
우리는 두 가지 연구 방법론에서 영감을 얻어 1시간 길이의 비디오에 대한 long-form video-language understanding capabilities를 벤치마킹하도록 설계된 새로운 task suite를 소개합니다. task suite는 요약, 인지 (회상, 추적), 시각적 추론 (공간적, 시간적, 예측적, 인과적, 반사실적) 및 탐색 (방에서 방으로, 객체 검색) 작업을 포함하여 포괄적인 인지적 작업 세트를 포함합니다. 전략은 앞서 논의된 두 가지 일반적인 접근 방식에서 영감을 얻습니다. (1) 질문-답변 생성 프로세스를 크게 간소화하기 위해 좁게 초점을 맞춘 질문 프로토타입을 설계하고 (2) 광범위한 multimodal capabilities를 전체적으로 평가하는 다양한 task suite를 만드는 것입니다. 수동으로 설계된 질문 프로토타입이 있는 task suite는 표 1에 나와 있습니다. 특히 제안된 task suite에는 18개의 하위 task가 있으며 HourVideo의 MCQ 예는 그림 1에 나와 있습니다.
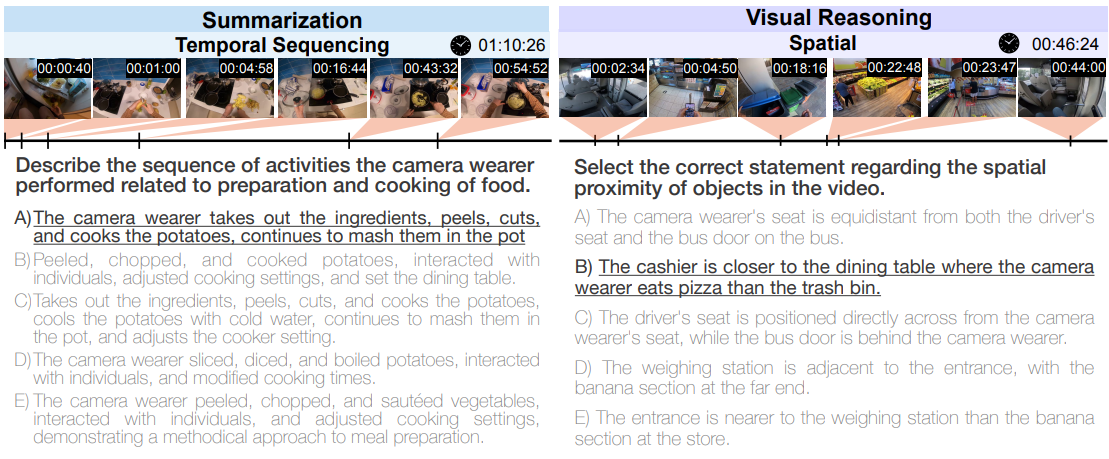
1. Summarization (요약)
- Key Events/Objects: 비디오에서 특정 장소 (예: 슈퍼마켓) 에서 카메라 착용자의 주요 행동을 요약합니다.
- Temporal Sequencing: 카메라 착용자가 특정 목표 (예: 디저트 준비) 를 달성하기 위해 수행한 일련의 활동을 순서대로 설명합니다.
- Compare/Contrast: 서로 다른 장소 (예: 아파트 vs. 레스토랑) 에서 카메라 착용자의 활동을 비교하고 대조합니다.
2. Perception (인지)
- Information Retrieval: 비디오에서 특정 정보를 찾아내는 능력을 평가합니다.
- Factual Recall: 특정 장소에서 카메라 착용자가 어떤 물체 (예: 유제품) 를 가져갔는지 기억합니다.
- Sequence Recall: 특정 행동 (예: 토마토 무게 측정) 직후 카메라 착용자가 무엇을 했는지 기억합니다.
- Temporal Distance: 두 행동 사이의 시간적 거리 (예: 피자 먹기 시작 후 피자 박스 버리기까지 걸린 시간) 를 측정합니다.
- Tracking: 비디오에서 특정 대상 (예: 특정 인물) 의 움직임을 추적합니다.
3. Visual Reasoning (시각적 추론)
- Spatial: 공간적 관계를 이해하는 능력을 평가합니다.
- Relationship: 특정 물체 (예: 전자레인지) 가 다른 물체 (예: 스토브) 와 공간적으로 어떤 관계 (예: 위, 아래, 옆) 에 있는지 파악합니다.
- Proximity: 어떤 물체가 다른 두 물체 중 어느 것에 더 가까운지 판단합니다.
- Layout: 특정 장소 (예: 아파트) 의 공간 배치를 보여주는 이미지를 선택합니다.
- Temporal: 시간적 관계를 이해하는 능력을 평가합니다.
- Duration: 카메라 착용자가 어떤 활동 (예: 요리 vs. 피아노 연주) 에 더 많은 시간을 소비했는지 판단합니다.
- Frequency: 카메라 착용자가 특정 목적 (예: 나무 자르기) 을 위해 어떤 도구 (예: 원형 톱 vs. 십자형 톱) 를 더 자주 사용했는지 판단합니다.
- Pre-requisites: 특정 행동 (예: 쿠키 굽기) 전에 카메라 착용자가 어떤 준비 단계를 거쳤는지 파악합니다.
- Predictive: 비디오 내용을 바탕으로 카메라 착용자의 다음 행동을 예측합니다.
- Causal: 특정 행동의 원인을 파악합니다.
- Counterfactual: 특정 상황이 달랐다면 어떤 결과가 발생했을지 추론합니다.
4. Navigation (탐색)
- Room-to-Room: 특정 위치 (예: 건물 입구) 에서 다른 위치 (예: 아파트) 까지 카메라 착용자가 어떻게 이동했는지 파악합니다.
- Object Retrieval: 특정 위치 (예: 부엌) 에서 특정 물체 (예: TV 리모컨) 를 찾는 방법을 설명합니다.
이처럼 HourVideo의 Task Suite는 다양한 유형의 질문을 통해 long-form video-language understanding에 필요한 다양한 능력을 종합적으로 평가하도록 설계되었습니다.
2.2 Dataset Generation Pipeline
이 섹션에서는 HourVideo를 만들기 위해 개발한 질문-답변 생성 파이프라인에 대한 개요를 제공합니다. 파이프라인은 그림 2에 요약되어 있습니다.
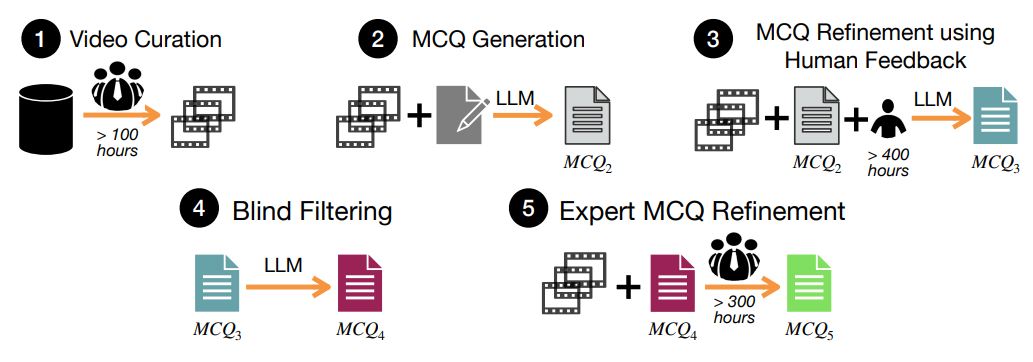
그림 2: 데이터셋 생성 파이프라인.
HourVideo를 만들기 위해 5단계로 구성된 데이터셋 생성 파이프라인을 개발했습니다. 비디오 큐레이션 (1단계), 인적 피드백을 사용한 MCQ 개선 (3단계) 및 전문가 MCQ 개선 (5단계) 단계에 해당하는 총 800시간 이상의 인력을 활용합니다. MCQ 생성 (2단계), 인적 피드백을 사용한 MCQ 개선 (3단계) 및 블라인드 필터링 (4단계)에는 LLM을 사용합니다. 인과 관계, 반사실적 및 탐색 질문은 인간 전문가가 수동으로 생성합니다 (자세한 내용은 섹션 2.2 참조).
비디오 큐레이션, 1단계. 이 벤치마크의 중요한 디자인 고려 사항은 비디오 소스와 유형을 선택하는 것입니다. 여러 가지 이유로 비디오용 Ego4D 데이터 세트를 선택했습니다. (1) egocentric perspective는 자율 에이전트 및 어시스턴트의 일반적인 시각적 입력과 잘 일치합니다. (2) 다양한 객관식 질문을 만드는 데 도움이 되는 광범위한 시각적 내레이션이 특징입니다. (3) Ego4D 라이선스에 따라 쉽게 액세스할 수 있습니다. Ego4D 데이터 세트에서 20분에서 120분까지 지속되는 1,470개의 비디오를 수동으로 검토하여 task suite의 다양한 task에 대한 관련 질문을 생성할 수 있는 잠재력을 평가했습니다. 비디오 큐레이션을 위해 5명의 인간 전문가를 참여시켰습니다. 이 프로세스에 따라 500개의 egocentric 비디오를 선별했습니다.
후보 MCQ 생성, 2단계. 이 단계의 목표는 long-form 비디오의 여러 시간적 세그먼트에 걸쳐 정보를 분석하고 종합해야 하는 각 task에 대해 고품질 MCQ를 생성하는 것입니다. 처음에 suite의 각 task에 대한 질문 템플릿을 수동으로 개발합니다. 표 1에 표시된 것처럼 질문 템플릿을 실제 질문으로 변환하려면 task 및 템플릿에 맞게 조정된 비디오별 정보를 통합해야 합니다. 이를 용이하게 하기 위해 Ego4D 데이터 세트의 자세한 내레이션을 활용하여 LLM에서 처리할 수 있는 구조화된 형식으로 변환합니다. 특히 비디오를 20분 간격으로 분할하며 각 세그먼트의 표현에는 요약과 비디오에서 카메라 착용자가 만난 도구, 음식, 기술, 인간, 애완 동물 및 물리적 위치 목록이 포함됩니다. 구조화된 표현과 질문 템플릿을 정답과 오답이 있는 유효한 질문으로 종합하는 것은 고급 LLM에게도 상당한 과제입니다. 결과적으로 각 task에 대해 질문 프로토타입, 포괄적인 지침, 컨텍스트 내 예제 및 질문 템플릿을 유효한 후보 MCQ2로 변환하는 방법에 대한 단계별 지침을 제공하는 자세한 프롬프트를 공식화합니다. 총 25개의 task별 프롬프트를 개발했습니다.
인적 피드백을 사용하여 LLM으로 MCQ 개선, 3단계. 이 단계의 목적은 이전 단계에서 생성된 MCQ2를 개선하는 것입니다. MCQ2에는 유효하지 않은 질문, 틀린 답변, 사소한 틀린 옵션 및 기타 다양한 문제가 포함될 수 있습니다. 이러한 문제의 중요한 원인은 Ego4D의 노이즈가 많은 내레이션에 의존했기 때문임을 확인했습니다. 예를 들어 동일한 비디오 내의 다른 내레이터가 식기 세척기를 "접시 랙"이라고 하거나 다른 용어를 사용할 수 있으며, 한 개인은 내레이션의 다양한 시간에 "성인", "빨간색과 흰색 셔츠를 입은 사람", "남자 Y" 또는 "십 대"로 설명될 수 있습니다. 이러한 불일치는 첫 번째 단계의 자동 질문 생성과 결합되어 유효하지 않은 MCQ가 생성될 수 있습니다. 노이즈가 많은 MCQ를 해결하기 위해 훈련된 주석자가 다음을 수행하는 인적 피드백 시스템을 구현합니다. 1) 각 질문의 유효성을 평가하여 비디오 콘텐츠와 일치하는지 확인하고 2) 주어진 답변의 정확성을 확인합니다. 틀린 것으로 확인되면 자유 형식 텍스트로 정답을 제공합니다. 3) 모든 틀린 옵션이 사실적으로 틀리고 정답과 명확하게 구별되는지 확인합니다. 400시간 이상의 인력을 투입하여 모든 MCQ2에 대한 인적 피드백을 수집합니다. 그런 다음 이 인적 피드백을 사용하여 MCQ2를 자동으로 개선하여 MCQ3을 생성하기 위한 프롬프트를 설계합니다. 이 단계에서 7명의 훈련된 주석자를 참여시켰습니다.
블라인드 필터링, 4단계. 최신 LLM은 방대한 사전 지식을 보유하고 있으므로 비디오를 분석할 필요 없이 특정 질문에 쉽게 답할 수 있습니다. 이 단계의 목표는 사전 지식을 통해 답변할 수 있거나 비디오에서 정보를 요구하지 않고 사소하게 답변할 수 있는 질문을 제거하는 것입니다. 이를 해결하기 위해 두 개의 별도 블라인드 LLM (GPT-4-turbo 및 GPT-4)을 활용하여 MCQ3을 블라인드 필터링합니다. 특히 비디오 입력 없이 하나 이상의 LLM에서 정확하게 답변하는 MCQ는 제외합니다. 이 방법은 MCQ를 공격적으로 제거할 수 있지만 나머지 MCQ4가 고품질이며 long-form video-language understanding을 테스트하도록 특별히 조정되었는지 확인합니다.
전문가 개선, 5단계. 이 단계의 목표는 선택된 인간 전문가 주석자 그룹을 활용하여 MCQ4의 품질을 향상시키는 것입니다. 이 단계는 이전 단계에서 지속되었을 수 있는 다양한 나머지 문제를 해결하기 위한 포괄적인 단계 역할을 합니다. 전문가 개선의 예로는 "카메라 착용자가 열쇠를 어디에 두었습니까?"와 같은 광범위한 질문을 "카메라 착용자가 쇼핑 후 집에 돌아온 후 자전거 열쇠를 어디에 두었습니까?"와 같은 더 정확한 질문으로 변환하는 것이 있습니다. 이 단계에서 300시간 이상의 전문 인력이 투입되어 MCQ4를 신중하게 검토하고 개선하여 고품질 MCQ5를 만들었습니다. 이 단계에서 4명의 인간 전문가를 참여시켰습니다.
수동 생성. 완전히 또는 부분적으로 자동화하기 위한 광범위한 노력에도 불구하고 특정 task가 앞서 설명한 파이프라인과 잘 맞지 않는다는 것을 발견했습니다. 특히 인과 관계, 반사실적, 공간 레이아웃 및 탐색 task의 경우 다단계 파이프라인을 통해 처리하는 것보다 인간 전문가와 함께 수동으로 질문을 생성하는 것이 더 효과적이라는 것을 알았습니다. 결과적으로 벤치마크의 이러한 task에 대해 더 적은 양이지만 고품질 질문을 생성했습니다. 이 단계에는 4명의 인간 전문가가 참여하여 총 658개의 MCQ (5.1%)를 생성했습니다.
구현 세부 정보. 복잡한 다단계 지침을 따르는 인상적인 기능을 제공하므로 파이프라인에서 GPT-4를 사용했습니다. 파이프라인에서 LLM과 관련된 모든 단계에 대해 Chain-of-Thought 프롬프트 전략과 0.1의 온도를 사용했습니다. 그림 B.2에서 MCQ 수명 주기의 예를 보여줍니다. 데이터 세트 생성에 대한 자세한 내용은 보충 자료 B를 참조하십시오. 다음 task에 대해 MCQ2를 생성하는 데 사용된 정확한 프롬프트를 포함합니다. • 내레이션 편집 (그림 E.1), • 요약 (그림 E.2, E.3), • 인지/정보 검색/사실적 회상 (그림 E.4, E.5), • 시각적 추론/공간/관계 (그림 E.6, E.7).
2.3 HourVideo 통계
HourVideo는 요리, 청소, 식사, TV 시청, 베이킹 등과 같은 77가지 일상 생활 시나리오를 다루는 Ego4D 데이터 세트의 500개 비디오로 구성됩니다 (그림 3). 데이터 세트에는 381시간 분량의 비디오 영상이 포함되어 있으며 비디오 길이는 20분에서 120분까지입니다 (그림 3). 평균적으로 각 비디오는 약 45.7분 길이로 long-form video-language understanding에 대한 이전 작업보다 15배 더 큽니다. 또한 데이터 세트의 113개 비디오는 길이가 1시간을 초과합니다. 각 비디오에는 평균 26개의 고품질 5지선다형 질문이 함께 제공되며 데이터 세트에는 총 12,976개의 질문이 있습니다. 마지막으로 선택된 비디오 그룹에 대해 질문이 수동으로 생성된 인과 관계, 반사실적 및 탐색 task를 제외하고 suite의 모든 task에서 MCQ를 균등하게 분배하기 위해 노력합니다.