Diffusion : 논문리뷰 : VIDEODIRECTORGPT: Consistent Multi-Scene Video Generation via LLM-Guided Planning
Abstract
최근 텍스트-투-비디오 (T2V) 생성 방법은 상당한 발전을 이루었습니다. 그러나 이러한 연구의 대부분은 단일 이벤트의 짧은 비디오 클립 (즉, 단일 장면 비디오)을 생성하는 데 중점을 둡니다. 한편, 최근 대규모 언어 모델 (LLM)은 downstream visual module을 제어하기 위한 레이아웃 및 프로그램을 생성하는 능력을 입증했습니다. 이는 중요한 질문을 제기합니다. 시간적으로 일관된 긴 비디오 생성을 위해 이러한 LLM에 내장된 지식을 활용할 수 있을까요?
이 논문에서 우리는 LLM의 지식을 비디오 콘텐츠 계획 및 grounded video generation에 사용하는 일관된 다중 장면 비디오 생성을 위한 새로운 프레임워크인 VIDEODIRECTORGPT를 제안합니다. 특히, 단일 텍스트 프롬프트가 주어지면 먼저 비디오 플래너 LLM (GPT-4)에 장면 설명, 각 레이아웃이 있는 엔티티, 각 장면의 배경 및 엔티티의 일관성 그룹을 포함하는 '비디오 계획'으로 확장하도록 요청합니다. 다음으로, 이 비디오 계획의 안내를 받아 Layout2Vid라는 비디오 생성기는 공간 레이아웃을 명시적으로 제어하고 여러 장면에서 엔티티의 시간적 일관성을 유지하면서 이미지 수준 주석으로만 학습할 수 있습니다.
우리의 실험은 제안된 VIDEODIRECTORGPT 프레임워크가 단일 및 다중 장면 비디오 생성 모두에서 레이아웃 및 movement control을 크게 개선하고 일관성 있는 다중 장면 비디오를 생성하는 동시에 open-domain 단일 장면 T2V 생성에서 SOTA와 경쟁력 있는 성능을 달성할 수 있음을 보여줍니다. LLM을 사용한 레이아웃 제어 강도의 동적 조정 및 사용자 제공 이미지를 사용한 비디오 생성을 포함한 자세한 ablation study는 프레임워크의 각 구성 요소의 효과와 향후 잠재력을 확인합니다.
문제점: 기존 T2V 모델은 짧고 단일 장면 비디오 생성에 집중, 다중 장면 비디오의 시간적 일관성 유지 어려움
해결책: LLM (GPT-4) 기반의 VIDEODIRECTORGPT 프레임워크 제안
핵심 아이디어:
- 비디오 플래너 (GPT-4): 텍스트 프롬프트를 '비디오 계획'으로 확장 (장면 설명, 엔티티 레이아웃, 배경, 일관성 그룹 포함)
- 비디오 생성기 (Layout2Vid): 비디오 계획을 기반으로 공간 레이아웃 및 시간적 일관성 제어, 이미지 수준 주석만으로 학습
장점:
- 다중 장면 비디오에서 레이아웃 및 movement control 향상
- 일관성 있는 다중 장면 비디오 생성 가능
- open-domain 단일 장면 T2V 생성에서 SOTA와 경쟁력 있는 성능
실험 결과:
- Ablation study를 통해 프레임워크 각 구성 요소의 효과 및 잠재력 확인
- LLM을 사용한 레이아웃 제어 강도의 동적 조정 및 사용자 제공 이미지를 사용한 비디오 생성 가능
1 Introduction
텍스트-투-이미지 (T2I) 생성의 성공에 이어 텍스트-투-비디오 (T2V) 생성 분야도 빠르게 발전하고 있습니다. 대부분의 T2V 생성 연구는 주어진 텍스트 프롬프트에서 짧은 비디오 (예: 2fps에서 16 프레임)를 생성하는 데 중점을 둡니다. 긴 비디오 생성에 대한 최근 연구는 전체적인 시각적 일관성을 가진 몇 분 분량의 긴 비디오를 생성하는 것을 목표로 합니다. 이러한 연구는 더 긴 비디오를 생성할 수 있지만, 생성된 비디오는 종종 여러 변화하는 행동/이벤트의 전환 및 역학 (예: 캐러웨이 케이크를 만드는 방법에 대한 5단계) 대신 단일 행동 (예: 자동차 운전)의 연속 또는 반복적인 패턴을 보여줍니다. 한편, 대규모 언어 모델 (LLM)은 downstream visual module을 제어하기 위한 레이아웃 및 프로그램을 생성하는 능력을 보여주었으며, 특히 이미지 생성 모델에서 그러합니다. 이는 흥미로운 질문을 제기합니다. 일관된 다중 장면 비디오 생성 계획을 위해 이러한 LLM에 내장된 지식을 활용할 수 있을까요?
이 연구에서 우리는 일관된 다중 장면 비디오 생성을 위한 새로운 프레임워크인 VIDEODIRECTORGPT를 소개합니다.

그림 1: VIDEODIRECTORGPT 프레임워크. 먼저, 다중 구성 요소 비디오 계획을 작성하기 위한 비디오 플래너로 GPT-4를 사용합니다. 다음으로, 레이아웃 및 일관성 제어를 통해 다중 장면 비디오를 렌더링하기 위해 grounded video generation 모듈인 Layout2Vid를 활용합니다.
그림 1에서 볼 수 있듯이 VIDEODIRECTORGPT는 T2V 생성 작업을 비디오 계획 및 비디오 생성의 두 단계로 분해합니다.
첫 번째 비디오 계획 단계 (그림 1 파란색 부분 참조)에서는 LLM을 사용하여 비디오 계획을 생성합니다. 비디오 계획은 여러 장면이 있는 비디오의 전체 플롯으로, 각 장면은 장면에 대한 텍스트 설명과 엔티티 이름/레이아웃, 배경으로 구성됩니다. 또한 장면 전체에서 다시 나타나는 특정 엔티티의 일관성 그룹으로 구성됩니다.
두 번째 비디오 생성 단계 (그림 1 노란색 부분 참조)에서는 비디오 계획에서 다중 장면 비디오를 생성하는 새로운 grounded video generation 모듈인 Layout2Vid를 소개합니다.
우리의 프레임워크는 다음과 같은 강점을 제공합니다.
(1) 단일 텍스트 프롬프트에서 여러 장면이 있는 비디오 생성을 안내하는 비디오 계획을 작성하기 위해 LLM을 사용합니다. (2) 이미지 수준 레이아웃 주석만 사용하여 비디오 생성에서 레이아웃을 제어합니다.
(3) 여러 장면에서 시각적으로 일관된 엔티티를 생성합니다.
첫 번째 단계인 비디오 계획 (3.1절)에서는 downstream 비디오 합성 프로세스를 안내하기 위해 여러 장면이 있는 다중 구성 요소 비디오 스크립트인 비디오 계획을 생성하기 위한 비디오 플래너로 LLM (예: GPT-4)을 사용합니다.
우리의 비디오 계획은 네 가지 구성 요소로 구성됩니다.
(1) 다중 장면 설명,
(2) 엔티티 (이름 및 2D 경계 상자),
(3) 배경,
(4) 일관성 그룹 (시각적으로 일관성을 유지해야 하는 위치를 나타내는 각 엔티티에 대한 장면 인덱스).
우리는 다른 in-context 예제를 사용하여 LLM을 프롬프트하여 두 단계로 비디오 계획을 생성합니다.
첫 번째 단계에서는 단일 텍스트 프롬프트를 LLM을 사용하여 다단계 장면 설명으로 확장합니다. 여기서 각 장면은 텍스트 설명, 엔티티 목록 및 배경으로 설명됩니다 (자세한 내용은 그림 2 파란색 부분 참조). 또한 LLM에 각 엔티티에 대한 추가 정보 (예: 색상, 복장 등)를 생성하고 프레임과 장면에서 엔티티를 그룹화하도록 프롬프트하여 비디오 생성 단계에서 일관성을 안내하는 데 도움을 줍니다.
두 번째 단계에서는 엔티티 목록과 장면 설명이 주어지면 프레임당 엔티티의 경계 상자를 생성하여 LLM을 사용하여 각 장면의 상세한 레이아웃을 확장합니다. 이러한 전체 '비디오 계획'은 downstream 비디오 생성을 안내합니다.

그림 2: VIDEODIRECTORGPT 세부 사항. 1단계: 다중 장면 비디오의 전체적인 플롯을 제공하는 비디오 계획을 작성하기 위해 LLM을 비디오 플래너로 사용합니다. 2단계: 비디오 계획을 기반으로 비디오를 렌더링하기 위해 grounded video generation 모듈인 Layout2Vid를 활용합니다 (3.2절).
두 번째 단계인 비디오 생성 (3.2절)에서는 생성된 비디오 계획을 기반으로 비디오를 렌더링하는 grounded video generation 모듈인 Layout2Vid를 소개합니다 (그림 2의 노란색 부분 참조). grounded video generation 모듈의 경우 기존 T2V 생성 모델인 ModelScopeT2V를 기반으로 원래 매개변수를 고정하고 gated-attention 모듈을 통해 적은 수의 학습 가능한 매개변수 (총 매개변수의 13%)를 통해 엔티티의 공간/일관성 제어를 추가합니다. 이를 통해 Layout2Vid는 레이아웃 주석이 달린 이미지에서만 학습할 수 있으므로 주석이 달린 비디오 데이터 세트에 대한 값비싼 학습이 필요하지 않습니다. 장면 전체에서 엔티티의 ID를 유지하기 위해 동일한 일관성 그룹 내에서 엔티티에 대한 공유 표현을 사용합니다. 또한 엔티티 접지 조건으로 joint image+text embedding을 사용할 것을 제안합니다. 이는 엔티티 ID 보존에서 기존 텍스트 전용 접근 방식보다 더 효과적이라는 것을 알았습니다 (부록 H 참조). 전반적으로 Layout2Vid는 값비싼 비디오 수준 학습을 방지하고 객체 레이아웃 및 movement control을 개선하며 객체의 장면 간 시간적 일관성을 유지합니다.
우리는 단일 장면 및 다중 장면 비디오 생성 모두에서 실험을 수행합니다. 실험 결과 VIDEODIRECTORGPT는 ModelScopeT2V 및 AnimateDiff, I2VGen-XL, SVD를 포함한 최신 비디오 생성 모델과 비교하여 더 나은 레이아웃 기술 (객체, 개수, 공간, 스케일) 및 객체 movement control을 보여줍니다. 또한 VIDEODIRECTORGPT는 장면 간에 시각적 일관성을 가진 다중 장면 비디오를 생성할 수 있으며 단일 장면 open-domain T2V 생성에서 SOTA와 경쟁력이 있습니다 (5.1절 및 5.2절). 레이아웃 제어 강도의 동적 조정, 서로 다른 LLM에서 생성된 비디오 계획, 사용자 제공 이미지를 사용한 비디오 생성을 포함한 자세한 ablation study는 프레임워크의 효과와 용량을 확인합니다 (5.3절 및 부록 H).
우리의 주요 기여는 다음과 같이 요약할 수 있습니다.
- 단일 텍스트 프롬프트에서 다중 장면 비디오를 생성할 수 있는 비디오 콘텐츠 계획 및 grounded video generation의 두 단계가 있는 새로운 T2V 생성 프레임워크 VIDEODIRECTORGPT입니다.
- LLM을 사용하여 비디오 생성을 안내하는 자세한 장면 설명, 엔티티 레이아웃 및 엔티티 일관성 그룹이 있는 다중 구성 요소 '비디오 계획'을 생성합니다.
- 이미지/텍스트 기반 레이아웃 제어 기능과 엔티티 수준 시간적 일관성을 결합한 새로운 grounded video generation 모듈인 Layout2Vid를 소개합니다. Layout2Vid는 이미지 수준 레이아웃 주석만 사용하여 효율적으로 학습할 수 있습니다.
- 실험 결과는 프레임워크가 객체 레이아웃과 움직임을 정확하게 제어하고 시간적으로 일관된 다중 장면 비디오를 생성할 수 있음을 보여줍니다.
기존 연구의 한계:
- 대부분의 T2V 모델은 짧고 단일 장면 비디오 생성에 집중
- 긴 비디오 생성 연구에서도 단일 행동의 반복적인 패턴만 생성, 다중 장면 전환 및 역동성 부족
새로운 접근 방식:
- LLM (GPT-4)의 지식을 활용하여 다중 장면 비디오의 일관성 유지
- VIDEODIRECTORGPT 프레임워크 제안 (2단계)
- 비디오 계획: LLM을 이용하여 텍스트 프롬프트를 상세한 '비디오 계획'으로 확장
- 각 장면에 대한 텍스트 설명, 엔티티 목록, 배경 정보 포함
- 여러 장면에 걸쳐 등장하는 객체의 일관성 유지 위한 정보 포함
- 비디오 생성: Layout2Vid 모듈을 이용하여 비디오 계획을 기반으로 영상 생성
- 이미지 수준 레이아웃 주석만 사용하여 학습 가능
- gated-attention 모듈을 통해 객체의 위치 및 움직임 정확하게 제어
- joint image+text embedding & 객체의 공유 표현을 통해 객체 일관성 유지
- 비디오 계획: LLM을 이용하여 텍스트 프롬프트를 상세한 '비디오 계획'으로 확장
Layout2Vid의 장점:
- 효율적인 이미지 기반 학습
- 객체 레이아웃 및 movement control 향상
- 객체의 장면 간 시간적 일관성 유지
2 Related Works
텍스트-투-비디오 생성. 처음부터 T2V 생성 모델을 학습시키는 것은 계산 비용이 많이 듭니다. 최근 연구에서는 Stable Diffusion과 같은 사전 학습된 텍스트-투-이미지 (T2I) 생성 모델을 텍스트-비디오 쌍에서 파인튜닝하여 활용하는 경우가 많습니다. 이러한 warm-start 전략을 통해 고해상도 비디오 생성이 가능하지만, T2I 모델은 긴 비디오에서 일관성을 유지하는 기능이 부족하기 때문에 짧은 비디오 클립만 생성할 수 있다는 한계가 있습니다. 반면, 긴 비디오 생성에 대한 최근 연구는 몇 분 분량의 긴 비디오를 생성하는 것을 목표로 합니다. 그러나 생성된 비디오는 종종 여러 행동/이벤트의 전환 대신 연속 또는 반복적인 행동을 보여줍니다. 이와 대조적으로, Layout2Vid는 데이터 및 매개변수 효율적인 학습을 통해 사전 학습된 T2V 생성 모델에 레이아웃 제어 및 다중 장면 시간적 일관성을 주입하면서 원래의 시각적 품질을 유지합니다.
레이아웃을 사용한 텍스트-투-이미지 생성. 해석 가능하고 제어 가능한 생성을 위해, 여러 연구에서는 T2I 생성 작업을 텍스트-투-레이아웃 생성 및 레이아웃-투-이미지 생성의 두 단계로 분해합니다. 초기 모델은 처음부터 레이아웃 생성 모듈을 학습시키는 반면, 최근 방법에서는 사전 학습된 LLM을 사용하여 텍스트에서 이미지 레이아웃을 생성하는 데 대한 지식을 활용합니다. 우리가 아는 한, 우리의 연구는 텍스트에서 구조화된 비디오 계획을 생성하기 위해 LLM을 활용하여 정확하고 제어 가능한 긴 비디오 생성을 가능하게 한 최초의 연구입니다.
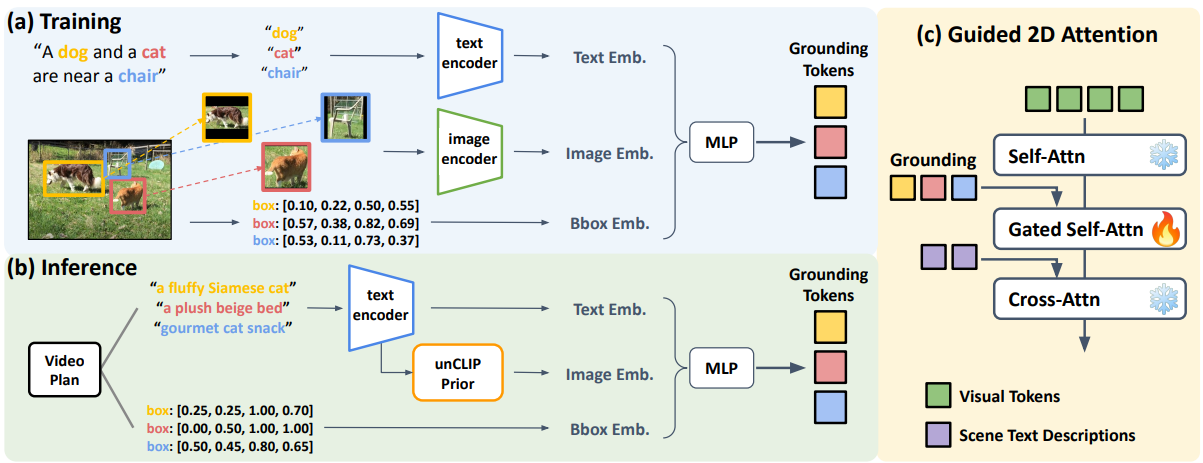
그림 3: Layout2Vid의 그림. (a) 학습. Layout2Vid는 이미지 수준 경계 상자 주석에서 효율적으로 학습됩니다. 텍스트, 이미지 및 경계 상자 임베딩을 입력으로 받는 MLP를 사용하여 엔티티 접지 토큰을 구성합니다. (b) 추론. unCLIP Prior를 사용하여 텍스트 설명에서 엔티티의 이미지 임베딩을 얻습니다. 시간적 일관성을 보장하기 위해 장면 전체에서 동일한 엔티티 임베딩을 사용합니다. (c) 안내된 2D Attention. 접지 토큰과 텍스트 토큰을 사용하여 시각적 표현을 조절합니다.
- 기존 방식:
- 처음부터 학습하는 방식은 계산 비용이 너무 큼
- T2I 모델을 파인튜닝하는 방식은 짧은 비디오만 생성 가능
- 긴 비디오 생성 연구는 있지만, 단일 행동 반복에 그침
- Layout2Vid의 차별점:
- 효율적인 학습: 데이터 및 파라미터 효율적인 학습으로 기존 T2V 모델 개선
- 레이아웃 제어: gated-attention 모듈을 통해 객체의 위치 및 움직임 정확히 제어
- 시간적 일관성: 다중 장면에서 객체의 일관성 유지
- 고품질 유지: 원본 모델의 시각적 품질 유지
T2I 생성 연구 동향
- 제어 가능한 생성: T2I 생성을 텍스트-투-레이아웃, 레이아웃-투-이미지 두 단계로 분해하는 연구 증가
- LLM 활용: 최근에는 LLM을 활용하여 텍스트에서 이미지 레이아웃 생성
- VIDEODIRECTORGPT의 기여: LLM을 활용하여 텍스트에서 구조화된 비디오 계획 생성, 정확하고 제어 가능한 긴 비디오 생성
3 VIDEODIRECTORGPT
3.1 비디오 계획: LLM을 사용한 비디오 계획
비디오 계획. 그림 2의 파란색 부분에서 볼 수 있듯이 GPT-4는 비디오 생성을 안내하는 자세한 비디오 계획을 제공하는 플래너 역할을 합니다. 비디오 계획에는 네 가지 구성 요소가 있습니다. (1) 다중 장면 설명: 각 장면을 설명하는 문장, (2) 엔티티: 이름과 2D 경계 상자, (3) 배경: 각 장면의 위치에 대한 텍스트 설명, (4) 일관성 그룹: 시각적으로 일관성을 유지해야 하는 위치를 나타내는 각 엔티티에 대한 장면 인덱스. 비디오 계획은 GPT-4를 독립적으로 프롬프트하여 두 단계로 생성됩니다. 각 단계에 대한 입력 프롬프트 템플릿은 부록 C에 나와 있습니다.
1단계: 다중 장면 설명, 엔티티 이름 및 일관성 그룹 생성. 첫 번째 단계에서는 GPT-4를 사용하여 단일 텍스트 프롬프트를 다중 장면 비디오 계획으로 확장합니다. 그런 다음 정확히 일치하는 항목을 사용하여 여러 장면에 나타나는 엔티티와 배경을 그룹화합니다. 예를 들어 '요리사'가 1~4장면에 나타나고 '오븐'이 1장면에만 나타나는 경우 엔티티 일관성 그룹을 {chef:[1,2,3,4], oven:[1]}으로 형성합니다. 후속 비디오 생성 단계에서는 동일한 엔티티 일관성 그룹에 공유 표현을 사용하여 시간적으로 일관된 모양을 유지합니다 (3.2절 참조).
2단계: 각 장면에 대한 엔티티 레이아웃 생성. 두 번째 단계에서는 엔티티와 장면 설명을 기반으로 각 프레임에 있는 엔티티에 대한 경계 상자 목록을 생성합니다. 각 장면에 대해 9개 프레임의 레이아웃을 생성한 다음 선형적으로 보간하여 더 밀도가 높은 프레임 (예: 장면당 16개 프레임)에 대한 정보를 수집합니다. VPGen과 마찬가지로 경계 상자에 [x0, y0, x1, y1] 형식을 채택합니다. 여기서 각 좌표는 [0,1] 범위 내에 속하도록 정규화됩니다. 컨텍스트 내 예제의 경우 경계 상자의 최소 단위로 0.05를 표시하며, 이는 20-bin 양자화와 같습니다.
3.2 비디오 생성: Layout2Vid를 사용하여 비디오 계획에서 비디오 생성
예비. 비디오 캡션 c가 있는 T 프레임 비디오 x ∈ RT×3×H×W가 주어지면 먼저 오토인코더를 사용하여 비디오를 잠재 z = E(x) ∈ RT×C×H′×W′로 인코딩합니다. 여기서 C = 4는 잠재 채널 수를 나타내고 H′ = H/8, W′ = W/8은 잠재의 공간적 차원을 나타냅니다. Latent diffusion model (LDM)에서 순방향 프로세스는 잠재 변수 z에 점진적으로 노이즈를 추가하는 고정 확산 프로세스입니다. q(zt|zt−1) = N(zt;√1 − βtzt−1, βtI). 여기서 βt ∈ (0, 1)은 t ∈ {1, ..., T}인 분산 일정입니다. 역방향 프로세스는 학습 가능한 디노이저 모델 ϵθ를 통해 zT에서 시작하여 점진적으로 노이즈가 적은 샘플 zT−1, zT−2, ..., z0를 생성합니다. {1, ..., T}에서 균일하게 샘플링된 타임스텝으로 t를 사용하면 Layout2Vid의 학습 목표를 다음과 같이 표현할 수 있습니다.
minθ LLDM = Ez,ϵ∼N(0,I),t∥ϵ − ϵθ(zt, t, c)∥22.
Layout2Vid: 레이아웃 기반 T2V 생성. 공개 T2V 생성 모델인 ModelScopeT2V에 레이아웃 제어 기능을 통합하여 Layout2Vid를 구현합니다. ModelScopeT2V의 diffusion UNet은 일련의 시공간 블록으로 구성되며, 각 블록에는 공간 컨볼루션, 시간 컨볼루션, 공간 attention 및 시간 attention의 네 가지 모듈이 포함됩니다. ModelScopeT2V와 비교하여 Layout2Vid는 경계 상자로 표시되는 엔티티 목록과 시각적 및 텍스트 콘텐츠를 통해 명시적인 공간 제어를 통해 레이아웃 기반 비디오 생성을 가능하게 합니다. 2D attention을 기반으로 안내된 2D attention을 만듭니다 (부록 D의 그림 9 참조). 그림 3 (c)에 표시된 것처럼 안내된 2D attention은 시각적 잠재 표현을 조절하기 위해 두 가지 조건부 입력을 사용합니다.
(1) gated self-attention으로 조건화된 접지 토큰,
(2) cross-attention으로 조건화된 현재 장면을 설명하는 텍스트 토큰.
이미지+텍스트 임베딩을 사용한 시간적으로 일관된 엔티티 접지. 이전 레이아웃 기반 T2I 생성 모델은 일반적으로 레이아웃 제어에 CLIP 텍스트 임베딩만 사용했지만 엔티티 접지를 위해 CLIP 텍스트 임베딩 외에도 CLIP 이미지 임베딩을 사용합니다. ablation study (부록 H 참조)에서 이 방법이 텍스트 전용 또는 이미지 전용 접지를 사용하는 것보다 더 효과적임을 입증합니다. 아래에 설명된 것처럼 i번째 엔티티에 대한 접지 토큰 hi는 CLIP 이미지 임베딩 fimg(ei), CLIP 텍스트 임베딩 ftext(ei) 및 경계 상자 li = [x0, y0, x1, y1]의 푸리에 특징을 융합하는 2계층 MLP입니다. 시각적/텍스트 특징에 학습 가능한 선형 투영 계층 (Pimg/text로 표시)을 사용합니다. 이는 학습 중 더 빠른 수렴에 도움이 된다는 것을 알았습니다.
hi = MLP(Pimg(fimg(ei)), Ptext(ftext(ei)), Fourier(li))
Layout2Vid의 학습 및 추론 절차는 그림 3의 (a)와 (b) 부분에 각각 나와 있습니다. 학습 중에 이미지 임베딩 fimg(e)는 CLIP 이미지 인코더를 사용하여 엔티티의 이미지 자르기를 인코딩하여 얻습니다. 추론 중에는 모든 입력이 텍스트 형식이므로 (예: 비디오 계획에서) CLIP 텍스트 임베딩을 해당 CLIP 이미지 임베딩으로 변환하기 위해 unCLIP Prior의 공개 구현인 Karlo를 사용합니다. 또한 추론 중에 CLIP 이미지 인코더를 사용하여 이미지를 인코딩하기만 하면 사용자 제공 예제에서 이미지 임베딩을 얻을 수도 있습니다.
매개변수 및 데이터 효율적인 학습. 학습하는 동안 안내된 2D attention의 매개변수 (총 매개변수의 13%)만 업데이트하여 원래 비디오 생성 기능을 유지하면서 사전 학습된 T2V 백본에 레이아웃 안내 기능을 주입합니다. 이러한 전략을 통해 공유 엔티티 접지 토큰을 통해 다중 장면 시간적 일관성을 갖추면서 이미지 수준 레이아웃 주석만으로 모델을 효율적으로 학습할 수 있습니다. 학습 및 추론 세부 정보는 부록 D에 나와 있습니다.
- 비디오 계획 구성 요소:
- 다중 장면 설명: 각 장면을 설명하는 문장
- 엔티티: 객체의 이름과 2D 경계 상자 (위치, 크기 정보)
- 배경: 각 장면의 배경에 대한 텍스트 설명
- 일관성 그룹: 여러 장면에 걸쳐 등장하는 객체들을 그룹화 (시간적 일관성 유지)
- 생성 과정 (2단계):
- GPT-4를 이용하여 텍스트 프롬프트 확장: 다중 장면 설명, 엔티티, 배경 정보 생성, 일관성 그룹 생성
- 각 장면의 엔티티 레이아웃 생성: GPT-4를 이용하여 각 엔티티의 경계 상자 정보 생성 (9개 프레임 생성 후 보간)
3.2 비디오 생성: Layout2Vid를 사용하여 비디오 계획에서 비디오 생성
- Layout2Vid: ModelScopeT2V 모델을 기반으로 레이아웃 제어 기능을 추가한 grounded video generation 모듈
- 핵심 기술:
- gated-attention: 객체의 경계 상자 정보를 활용하여 객체의 위치 및 움직임 정확하게 제어
- joint image+text embedding: 이미지와 텍스트 정보를 결합하여 객체를 더욱 정확하게 표현, 일관성 유지
- 객체의 공유 표현: 동일한 객체에 대해 동일한 표현 사용, 여러 장면에서 일관성 유지
- 학습:
- 효율적인 학습: 이미지 수준 레이아웃 주석만 사용
- 매개변수 효율성: gated-2D attention 모듈의 파라미터만 학습 (전체 파라미터의 13%)
- Loss 함수: Reconstruction loss + Layout consistency loss (+ 일관성 그룹 내 객체 유사도 loss)
- 추론:
- unCLIP Prior를 이용하여 텍스트 정보에서 이미지 정보 추출
- 사용자 제공 이미지를 활용 가능
논문의 흐름
1. 텍스트, 이미지, bbox 정보가 인풋으로 들어간다.
텍스트 이미지는 클립을 통해, bbox 좌표는 Fourier Feature 변환
2. 각각 인코더를 통해 임베딩 시키고 MLP를 통해 Grounding Tokens로 나온다.
이렇게 임베딩된 정보는 MLP에 입력되어 최종적으로 Grounding Tokens가 만들어져. Grounding Tokens은 객체의 위치, 모양, 그리고 시각적 특징을 학습하는데 사용, 이를 통해 객체가 여러 프레임에서 일관성 있게 배치되고 움직임을 유지
3. 비주얼 토큰이 먼저 셀프 어텐션을 거치고, 그라운딩 토큰과 함께 Gated Self Attention 레이어로 들어간다. 이후 크로스 어텐션을 거친다.
Grounding Tokens은 객체의 위치, 크기, 모양을 정확하게 반영하는 정보를 학습
4. 어떤 아웃풋이 나오고 이미지는 언제 생성되는가?
Gated Attention을 통해 비주얼 토큰이 조정된 후, 이미지 생성은 최종 단계에서
비주얼 토큰과 텍스트 임베딩이 결합된 후, 이 정보를 바탕으로 Stable Diffusion 기반의 생성기가 비디오의 프레임을 만드는데, 여기서 각 프레임의 이미지가 생성
논문에서 9개의 레이아웃 프레임을 먼저 생성하고, 선형 보간법을 통해 이들 사이를 메워서 더 많은 프레임을 확장. 예를 들어, 9개의 프레임을 가지고 16프레임을 만드는 방식
여러 프레임 이미지가 출력되며, 결과적으로 비디오 형식으로 보일 수 있는 이미지 프레임들이 생성
1. 입력 정보 처리:
- 텍스트와 이미지는 CLIP을 통해 임베딩됩니다.
- bbox 좌표는 Fourier Feature 변환을 통해 모델에 입력됩니다. (임베딩 과정은 거치지 않습니다.)
2. Grounding Tokens 생성:
- 임베딩된 텍스트, 이미지 정보와 Fourier Feature 변환된 bbox 정보는 MLP에 입력되어 Grounding Tokens이 생성됩니다.
- Grounding Tokens은 객체의 위치, 모양, 시각적 특징 등을 종합적으로 나타냅니다.
3. Guided 2D Attention:
- Visual tokens은 입력 이미지를 패치 단위로 인코딩한 것입니다. (Vision Transformer 등을 사용)
- Visual tokens은 먼저 Self-Attention을 거쳐 패치 간의 관계를 학습합니다.
- 그 후, Grounding tokens과 함께 Gated Self-Attention 레이어에 입력되어 객체 정보를 반영합니다.
- 최종적으로, Text tokens과 Cross-Attention을 거쳐 전체적인 장면 정보를 반영합니다.
- 이 과정을 통해 Visual tokens은 어떤 시각 정보에 집중해야 할지 학습합니다.
4. 이미지 생성:
- Guided 2D Attention을 통해 조정된 Visual tokens과 Text tokens은 Stable Diffusion 기반의 생성기에 입력되어 이미지를 생성합니다.
- 9개의 레이아웃 프레임을 먼저 생성하고 선형 보간을 통해 더 많은 프레임으로 확장합니다.
추가 설명:
- Grounding Tokens은 객체의 위치, 모양, 시각적 특징을 학습하는 데 사용됩니다. 이를 통해 객체가 여러 프레임에서 일관성 있게 배치되고 움직임을 유지할 수 있습니다.
- Gated Self-Attention은 Grounding tokens을 이용하여 Visual tokens을 조절합니다. 즉, 객체 정보를 기반으로 어떤 시각 정보에 집중해야 할지 결정하는 것이죠.
- 최종적으로 여러 프레임의 이미지가 생성되어 비디오 형태로 출력됩니다.
질문 1. gated self attention을 학습 하기 위한 loss를 어떤 것 을 사용했는지?
질문 2. 16프레임이 과연 long video인지?
질문 3. 일관성을 지키다보면 자연스럽게 갑작스러운 장면전환이나 동작 변화가 많은 video를 생성하기 어려운데 거기엔 전혀 적용을 못하는지?
질문 4. 이미지 레이아웃을 가지고만 프레임 간 자연스러운 움직임이나 장면 전환을 제대로 학습 할 수 있는지?
질문 5. 16프레임으로 multi-scene이 나올 수 있는지?