Diffusion : 논문 리뷰 : Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation
Abstract
자연어나 레이아웃 조건에서 이미지를 생성하는 분야에서 놀라운 발전이 있었습니다. 그러나 이러한 방법들은 복잡한 객체와 그 관계를 충분히 모델링하지 못해 복잡한 장면을 충실하게 재현하는 데 어려움을 겪습니다.
이 문제를 해결하기 위해 우리는 복잡한 이미지 생성을 위한 강력한 구조화된 표현인 씬 그래프를 활용합니다. 씬 그래프를 직접 생성에 사용하는 이전 연구와 달리, 우리는 다양한 분리된 시각적 단서를 씬 그래프에서 합성하여 일반적인 방식으로 변이형 오토인코더와 확산 모델의 생성 능력을 활용합니다. 구체적으로, 먼저 Semantics-Layout Variational AutoEncoder (SL-VAE)를 제안하여 입력 씬 그래프에서 (레이아웃, 의미)를 함께 파생하여 다양하고 합리적인 one-to-many 매핑을 가능하게 합니다. 그런 다음, Compositional Masked Attention (CMA)를 확산 모델과 통합하여 (레이아웃, 의미)를 미세한 속성과 함께 생성 가이드로 통합합니다. 또한 시각적 내용을 일관성 있게 유지하면서 그래프 조작을 달성하기 위해 "격리된" 이미지 편집 효과를 위한 Multi-Layered Sampler (MLS)를 도입합니다. 광범위한 실험은 우리의 방법이 텍스트, 레이아웃 또는 씬 그래프 기반의 최근 경쟁자보다 생성 합리성과 제어 가능성 측면에서 우수함을 보여줍니다.
1 Introduction
텍스트-투-이미지 (T2I) 생성은 최근 몇 년간 비전-언어 기반 모델의 발전으로 인해 눈부신 발전을 이루었습니다. 그러나 선형 구조의 텍스트 조건은 복잡한 장면의 세부 사항을 정확하게 설명하는 데 어려움이 있습니다.

예를 들어, 그림 1(a)의 DALL-E 3 실패 사례에서 볼 수 있듯이, 복잡한 텍스트 프롬프트인 "A sheep by another sheep ... a boat on the grass"가 주어지면 T2I 모델이 객체 관계나 수량을 정확하게 생성하는 데 어려움이 있을 수 있습니다. 따라서 일부 연구에서는 추가적인 레이아웃 조건을 통합하여 공간 관계(예: "by" 및 "on") 제어를 개선하고자 합니다.

그러나 그림 1(b)의 LayoutDiffusion 실패 사례에서 볼 수 있듯이, 레이아웃-투-이미지(L2I) 방법은 공간 토폴로지 내에서 "playing"을 묘사하는 것과 같은 특정 비공간 상호작용을 나타내는 데 필연적으로 어려움을 겪습니다.
생성 모델을 안내하기 위해 복잡한 장면을 효율적으로 묘사하기 위해 최근 방법은 텍스트 또는 레이아웃 프롬프트 대신 구조화된 장면 그래프를 사용합니다. 장면 그래프는 장면 내의 객체를 노드로, 객체 간의 관계를 간선으로 나타내는 구조화된 그래프 형식으로 장면을 나타냅니다.
장면 그래프-투-이미지(SG2I) 생성은 그래프 간선과 시각적 객체 간의 관계/상호작용 간의 모호한 정렬이 빈번하게 발생하기 때문에 어려운 작업입니다.
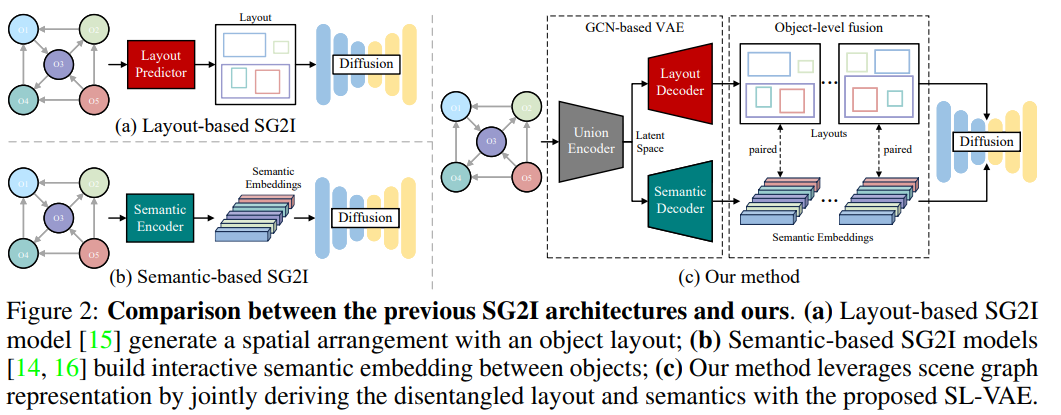
이 문제를 해결하기 위해 레이아웃 기반 SG2I 방법은 추가적인 레이아웃 예측기를 통해 장면에서 객체의 공간 배열을 명시적으로 예측한 다음, 레이아웃에 따라 L2I 합성을 수행합니다(그림 2(a) 참조). 이러한 방법은 일반적으로 일대일 매핑을 사용하며, 즉 단일 장면 그래프는 하나의 레이아웃에만 해당되므로 생성 다양성이 심각하게 제한됩니다. 또한 각 객체가 일반적으로 독립적으로 생성되는 방식으로 비공간 상호작용을 모델링하는 L2I 접근법의 한계를 상속합니다.
반면, 그림 2(b)에서 볼 수 있듯이, 의미 기반 SG2I 방법은 그래프 합성 네트워크(GCN)를 통해 그래프 간선을 노드 임베딩으로 암묵적으로 인코딩하여 객체 의미와 비공간 상호작용을 효과적으로 정렬합니다. 그럼에도 불구하고 이러한 방법은 독립적인 노드의 공간 위치를 논리적으로 결정하는 데 약하며, 이로 인해 생성된 이미지에서 독립적인 노드(예: 그림 1(c)의 "lamp" 및 "stone")가 누락될 수 있습니다.

본 논문에서는 장면 그래프 표현에서 파생된 분리된 레이아웃과 의미를 통합하는 DisCo라는 구성적 이미지 생성 프레임워크를 제안합니다(그림 2(c) 참조).
복잡한 장면에 대한 장면 그래프의 표현 능력을 향상시키기 위해 노드와 간선 표현을 CLIP 텍스트 임베딩으로 확장하고, 학습 중에 노드에 대한 추가적인 공간 정보(즉, 바운딩 박스 임베딩)를 통합합니다.
텍스트 장면 그래프가 구성되면, 우리는 SL-VAE(Semantics-Layout Variational AutoEncoder)를 제안하여 장면에서 공간 관계와 비공간 상호작용을 함께 모델링합니다.
SL-VAE는 입력 장면 그래프와 일치하는 공간 레이아웃과 상호작용적 의미에 대한 다대다 분리를 허용합니다. 이는 가우시안 분포에서 샘플링하여 확산 프로세스에 대한 객체 수준(레이아웃, 의미) 조건을 제공함으로써 달성됩니다. 레이아웃과 의미가 글로벌 및 로컬 관계 정보를 내포하고 있다는 점을 감안하여, 우리는 또한 구성적 마스킹 어텐션(CMA) 메커니즘을 도입하여 미세한 속성을 가진 객체 수준 그래프 정보를 확산 모델에 주입하여 관계 혼란과 속성 누출을 방지합니다. 마지막으로, 우리는 SL-VAE가 생성한 다양한 조건을 활용하여 SG2I 작업에서 객체 수준 그래프 조작(즉, 노드 추가 및 속성 제어)에 대한 일반화된 생성을 달성하는 다층 샘플러(MLS) 기술을 제시합니다(그림 1(d)의 두 "양"의 색상 변경).
요약하면, 저희의 주요 기여는 다음과 같습니다.
(i) 우리는 구조화된 장면 표현으로 텍스트 장면 그래프를 적용하고, Semantics-Layout Variational AutoEncoder(SL-VAE)를 도입하여 장면 그래프에서 다양한 공간 레이아웃과 상호작용적 의미를 분리합니다.
(ii) 우리는 구성적 마스킹 어텐션(CMA)을 제시하여 미세한 속성을 가진 추출된 객체 수준 그래프 정보를 확산 모델에 주입하여 관계 혼란과 속성 누출을 방지합니다.
(iii) 우리는 SL-VAE가 생성한 다양한 조건을 활용하여 객체 수준 그래프 조작을 구현하는 동시에 시각적 콘텐츠를 일관적으로 유지하는 다층 샘플러(MLS)를 도입합니다.
(iv) 저희 방법은 관계 생성에서 현재 텍스트/레이아웃 기반 방법을 능가하며, 최첨단 SG2I 모델과 비교하여 훨씬 우수한 생성 성능을 달성하여 복잡한 장면을 묘사하는 데 있어 텍스트 장면 그래프의 일반화를 보여줍니다.
나머지는 요약본 입니다.
이 논문은 "복합 이미지 생성의 일반화를 위한 장면 그래프 분리 및 구성(Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation)"이라는 제목으로, 장면 그래프를 활용해 복잡한 이미지를 생성하는 새로운 프레임워크인 DisCo를 제안하고 있습니다. 주요 내용을 한국어로 요약하면 다음과 같습니다:
- 해결하려는 문제: 기존의 텍스트-이미지 변환(T2I) 모델, 예를 들어 DALL·E 3 같은 모델은 복잡한 장면을 정확하게 생성하는 데 어려움을 겪고 있습니다. 특히, 여러 객체 간의 관계(공간적, 비공간적 관계)를 제대로 표현하기 어렵습니다. 레이아웃 기반의 이미지 생성(L2I) 모델도 비공간적 상호작용을 처리하는 데 한계가 있습니다.
- 제안된 해결책: DisCo는 장면 그래프를 분리하여 **Semantics-Layout Variational AutoEncoder (SL-VAE)**와 확산 모델을 결합한 프레임워크입니다. 이 모델은 다음과 같은 방식으로 이미지 생성 성능을 향상시킵니다:
- 장면 그래프에서 레이아웃(공간적 관계)과 의미(비공간적 상호작용)를 분리하여 처리합니다.
- Compositional Masked Attention (CMA)를 사용하여 확산 과정에서 객체 간 관계를 반영함으로써 객체 간의 일관성을 유지합니다.
- Multi-Layered Sampler (MLS)를 통해 장면 그래프를 조작(예: 객체 추가, 속성 변경)하면서도 생성된 이미지의 일관성을 유지할 수 있습니다.
- 주요 기여:
- 장면 그래프를 사용하여 객체 간 관계와 속성을 더 잘 제어할 수 있는 이미지 생성 방식을 제시합니다.
- SL-VAE는 단일 장면 그래프에서 다양한 공간적 레이아웃과 의미를 유연하게 모델링할 수 있게 해줍니다.
- DisCo는 현재의 최신 방법들과 비교했을 때 이미지 생성 품질이 더 높고, 복잡한 장면에 대한 제어력도 뛰어납니다.
각 해결책 세부 설명
1. 장면 그래프를 사용한 복잡한 이미지 생성 문제
기존의 텍스트-이미지 변환(Text-to-Image, T2I) 모델은 복잡한 장면을 표현하는 데 어려움이 있습니다. 텍스트는 객체 간의 관계나 위치를 세밀하게 설명하기 힘들고, 이로 인해 여러 객체가 등장하는 복잡한 이미지를 정확하게 생성하지 못하는 경우가 많습니다. 기존의 레이아웃 기반 이미지 생성(Layout-to-Image, L2I) 방법도 공간적 관계를 잘 표현할 수 있지만, 비공간적 상호작용(예: 물체들 간의 동작이나 추상적 관계)을 제대로 반영하지 못하는 한계가 있습니다.
이를 해결하기 위해 DisCo는 텍스트 대신 **장면 그래프(Scene Graph)**를 사용합니다. 장면 그래프는 객체를 노드로, 객체 간의 관계를 엣지로 표현하는 구조적 표현 방식입니다. 이 방식은 텍스트보다 더 명확하게 객체와 그들 간의 관계를 나타낼 수 있어 복잡한 이미지 생성에 적합합니다.
2. Semantics-Layout Variational AutoEncoder (SL-VAE)
SL-VAE는 장면 그래프에서 레이아웃과 의미를 분리(분리된(disentangled))하여 처리하는 방식입니다.
- 레이아웃: 객체의 공간적 위치와 관계를 나타냅니다. 예를 들어, A라는 객체가 B 옆에 있거나, C 위에 있다는 공간적 관계를 다룹니다.
- 의미(세만틱스): 객체 간의 비공간적 상호작용이나 의미를 다룹니다. 예를 들어, A가 B를 쫓거나, D가 E를 가지고 노는 등의 상호작용을 설명합니다.
SL-VAE는 장면 그래프에서 레이아웃과 의미를 동시에 모델링하면서도 이 둘을 분리하여 학습합니다. 이렇게 함으로써 다양한 레이아웃과 의미를 생성할 수 있으며, 이를 통해 동일한 장면 그래프에서 다양한 이미지가 생성될 수 있습니다. 이는 기존 방식들이 1:1 대응을 통해 단일한 레이아웃만을 생성하는 한계를 극복하게 해줍니다.
SL-VAE는 다음과 같은 단계로 동작합니다:
- 장면 그래프를 입력으로 받아 **노드(객체)**와 **엣지(관계)**의 임베딩을 생성합니다.
- 이 임베딩들을 그래프 유니온 인코더로 보내, 공간적 배치와 비공간적 상호작용을 모두 고려한 잠재 공간(latent space)에서 학습된 표현을 만듭니다.
- 이 표현에서 다양한 레이아웃과 의미를 샘플링해, 이미지 생성에 필요한 다양한 조건을 만들어냅니다.
3. Compositional Masked Attention (CMA)
CMA는 장면 그래프에서 추출된 객체 간 관계와 **세부 속성(색상, 모양 등)**을 확산 모델에 통합하는 역할을 합니다. 이를 통해 객체들 간의 혼동을 방지하고, 각 객체의 속성이 다른 객체의 속성과 섞이는 것을 방지합니다.
기존의 **확산 모델(Diffusion Model)**에서는 모든 객체가 동일한 층에서 학습되다 보니, 객체 간의 상호작용이 혼동될 가능성이 있었습니다. 예를 들어, "강아지가 고양이를 쫓고 있다"는 장면에서, 강아지와 고양이의 행동이 서로 섞일 수 있습니다.
CMA는 다음과 같은 방식으로 이러한 문제를 해결합니다:
- 각 객체의 **시각적 토큰(Visual Token)**과 **객체 임베딩(Object Embedding)**을 분리하여 처리합니다.
- 마스크된 주의(attention) 메커니즘을 사용하여 객체별로 시각적 토큰이 다른 객체와 혼동되지 않도록 주의를 분산합니다.
- 이를 통해 각 객체의 속성과 위치를 보다 명확하게 생성하며, 상호작용이나 속성 누락을 방지합니다.
이 방식은 객체 간의 관계 혼동을 방지하고, 더 정밀한 속성 제어를 가능하게 해줍니다.
4. Multi-Layered Sampler (MLS)
MLS는 생성 과정에서 객체별로 독립적으로 조작할 수 있는 기능을 제공합니다. 이는 생성된 이미지에서 객체를 추가하거나, 속성을 변경하면서도 전체 이미지의 일관성을 유지할 수 있게 합니다.
기존의 이미지 생성 모델에서는 객체를 추가하거나 속성을 변경하면 전체 이미지에 영향을 미쳐 일관성이 깨지는 경우가 많았습니다. 예를 들어, 장면에 새로운 물체를 추가할 때, 이미지의 다른 객체들이 원래 있던 위치나 모양에서 어긋나게 될 수 있습니다.
MLS는 이러한 문제를 해결하기 위해, 객체를 **층(layer)**으로 정의하고 각 객체를 독립적으로 샘플링할 수 있도록 합니다. 이 방식은 다음과 같이 동작합니다:
- 각 객체의 레이아웃과 의미를 샘플링하여 고정된 레이아웃 시드를 생성합니다.
- 각 객체별로 **비중첩 마스크(non-overlapping masks)**를 사용하여 독립적인 확산 과정을 수행합니다.
- 이를 통해 하나의 객체가 추가되거나 속성이 변경되어도 나머지 객체는 영향받지 않으면서 이미지가 생성됩니다.
이 방법을 사용하면 생성된 이미지에서 특정 객체를 추가하거나 속성을 조정하는 작업을 더 정밀하게 제어할 수 있습니다.