VLM : 논문리뷰 : Multimodal Chain-of-Thought Reasoning inLanguage Models
Abstract
Large language models (LLMs)은 중간 추론 체인을 생성하는 chain-of-thought (CoT) prompting을 활용하여 복잡한 추론 작업에서 인상적인 성능을 보여왔습니다.
그러나 기존 CoT 연구는 주로 언어 modality에 중점을 두었습니다. 우리는 언어 (텍스트) 및 vision (이미지) modality를 rationale 생성과 answer inference를 분리하는 two-stage framework에 통합하는 Multimodal-CoT를 제안합니다.
이를 통해 answer inference는 multimodal 정보를 기반으로 더 잘 생성된 rationales를 활용할 수 있습니다. ScienceQA 및 A-OKVQA benchmark datasets에 대한 실험 결과는 제안된 접근 방식의 효과를 보여줍니다. Multimodal-CoT를 통해 10억 개 미만의 매개변수를 가진 모델은 ScienceQA 벤치마크에서 state-of-the-art 성능을 달성합니다. 분석 결과는 Multimodal-CoT가 hallucination을 완화하고 convergence speed를 향상시키는 이점을 제공함을 나타냅니다.
Introduction
Multimodal CoT 추론
다양한 데이터 modality를 함께 모델링하는 것의 중요성
그림이나 표가 없는 교과서를 읽는 것을 상상해 보세요. 지식 습득 능력은 시각, 언어, 청각과 같은 다양한 데이터 modality를 함께 모델링함으로써 크게 향상됩니다. 최근, large language models (LLMs)은 답을 추론하기 전에 중간 추론 단계를 생성하여 복잡한 추론 작업에서 인상적인 성능을 보여주었습니다. 이 흥미로운 기술은 chain-of-thought (CoT) 추론이라고 불립니다. 그러나 CoT 추론과 관련된 기존 연구는 주로 언어 modality에 국한되어 있으며, multimodal 시나리오에 대한 고려는 거의 없습니다.
Multimodal-CoT 패러다임
Multimodality에서 CoT 추론을 이끌어내기 위해 Multimodal-CoT 패러다임을 제안합니다. 다양한 modality의 입력이 주어지면 Multimodal-CoT는 multi-step 문제를 중간 추론 단계 (rationale)로 분해한 다음 답을 추론합니다. 시각과 언어가 가장 널리 사용되는 modality이므로 이 연구에서는 이 두 modality에 중점을 둡니다.
Multimodal-CoT 추론의 두 가지 주요 패러다임
일반적으로 Multimodal-CoT 추론은 두 가지 주요 패러다임을 통해 이끌어낼 수 있습니다.
(i) LLMs 프롬프팅 및 (ii) 더 작은 모델 fine-tuning. 이러한 패러다임과 관련된 과제에 대해 자세히 설명하겠습니다.
LLMs 프롬프팅을 통한 Multimodal-CoT
Multimodal-CoT를 수행하는 가장 직접적인 방법은 서로 다른 modality의 입력을 통합된 modality로 변환하고 LLMs에게 CoT를 수행하도록 프롬프팅하는 것입니다. 예를 들어, captioning 모델을 통해 이미지에 대한 caption을 생성한 다음, caption을 원래 언어 입력과 연결하여 LLMs에 입력할 수 있습니다. GPT-4V 및 Gemini와 같은 대규모 multimodal 모델의 개발은 생성된 caption의 품질을 크게 향상시켜 더 세밀하고 자세한 설명을 제공합니다. 그러나 captioning 프로세스는 시각 신호를 텍스트 설명으로 변환할 때 여전히 상당한 정보 손실을 초래합니다. 따라서 이미지 caption을 사용하는 것은 서로 다른 modality의 representation space에서 상호 시너지 부족으로 어려움을 겪을 수 있습니다. 또한 LLMs은 유료 서비스이거나 로컬에 배포하기에는 자원을 많이 소모합니다.
더 작은 언어 모델 fine-tuning을 통한 Multimodal-CoT
modality 간의 상호 작용을 촉진하기 위한 또 다른 잠재적인 솔루션은 multimodal features를 융합하여 더 작은 언어 모델 (LMs)을 fine-tuning하는 것입니다. 이 접근 방식은 multimodal features를 통합하기 위해 모델 architecture를 유연하게 조정할 수 있도록 하므로 이 연구에서는 LLMs 프롬프팅 대신 모델 fine-tuning을 연구합니다. 주요 과제는 1000억 개 미만의 매개변수를 가진 언어 모델은 답 추론을 잘못 이끄는 hallucinated rationales를 생성하는 경향이 있다는 것입니다.
성과
우리의 방법은 ScienceQA 벤치마크에서 공개 시점에 state-of-the-art 성능을 달성했습니다. Multimodal-CoT는 hallucination을 완화하고 convergence를 촉진하는 데 유익하다는 것을 발견했습니다.
기여
우리의 기여는 다음과 같이 요약됩니다:
(i) 우리가 아는 한, 이 연구는 과학적인 peer-reviewed 문헌에서 서로 다른 modality에서 CoT 추론을 연구한 최초의 연구입니다.
(ii) 우리는 vision 및 language representations를 융합하여 Multimodal-CoT를 수행하도록 language models를 fine-tuning하는 two-stage framework를 제안합니다. 이 모델은 최종 답변 추론을 촉진하는 유익한 rationales를 생성할 수 있습니다.
(iii) 우리는 CoT를 사용하는 naive 방법이 왜 맥락에서 실패하는지, 그리고 vision features를 통합하는 것이 어떻게 문제를 완화하는지에 대한 분석을 이끌어냅니다. 이 접근 방식은 tasks 및 backbone models 전반에서 일반적으로 효과적인 것으로 나타났습니다.
Background
이 섹션에서는 prompting 및 fine-tuning language models를 통해 CoT 추론을 이끌어내는 연구에 대해 살펴봅니다.
2.1 LLMs를 이용한 CoT 추론
최근, CoT는 LLMs의 multi-step 추론 능력을 이끌어내기 위해 널리 사용되고 있습니다 (Wei et al., 2022b). 구체적으로, CoT 기술은 LLM이 문제 해결을 위한 중간 추론 체인을 생성하도록 장려합니다. 연구에 따르면 LLMs은 Zero-Shot-CoT (Kojima et al., 2022) 및 Few-Shot-CoT (Wei et al., 2022b; Zhang et al., 2023d)라는 두 가지 주요 기술 패러다임을 통해 CoT 추론을 수행할 수 있습니다. Zero-Shot-CoT의 경우, Kojima et al. (2022)은 테스트 질문 뒤에 "Let's think step by step"와 같은 prompt를 추가하여 CoT 추론을 유도함으로써 LLMs가 괜찮은 zero-shot reasoners임을 보여주었습니다. Few-Shot-CoT의 경우, 몇 가지 단계별 추론 데모가 추론 조건으로 사용됩니다. 각 데모에는 질문과 최종 답변으로 이어지는 추론 체인이 있습니다. 데모는 일반적으로 수작업 또는 자동 생성을 통해 얻습니다. 따라서 이 두 가지 기술인 수작업 및 자동 생성은 각각 Manual-CoT (Wei et al., 2022b) 및 Auto-CoT (Zhang et al., 2023d)라고 합니다.
효과적인 데모를 통해 Few-Shot-CoT는 종종 Zero-Shot-CoT보다 더 강력한 성능을 달성하며 더 많은 연구 관심을 끌고 있습니다. 따라서 최근 연구들은 Few-Shot-CoT를 개선하는 방법에 초점을 맞추고 있습니다. 이러한 연구들은
(i) 데모 최적화, (ii) 추론 체인 최적화라는 두 가지 주요 연구 라인으로 분류됩니다. 표 1은 일반적인 CoT 기술을 비교합니다.

Figure 1: Example of the multimodal CoT task.
데모 최적화
Few-Shot-CoT의 성능은 데모의 품질에 달려 있습니다. Wei et al. (2022b)에서 보고된 바와 같이, 서로 다른 annotator가 작성한 데모를 사용하면 추론 작업에서 정확도 차이가 크게 발생합니다. 데모를 수작업으로 만드는 것 외에도 최근 연구에서는 데모 선택 프로세스를 최적화하는 방법을 조사했습니다. 특히, Rubin et al. (2022)은 테스트 인스턴스와 의미적으로 유사한 데모를 검색했습니다. 그러나 이 접근 방식은 추론 체인에 오류가 있을 때 성능이 저하되는 것을 보여줍니다 (Zhang et al., 2023d). 이러한 한계를 해결하기 위해 Zhang et al. (2023d)은 핵심은 데모 질문의 다양성이라는 것을 발견하고 Auto-CoT를 제안했습니다:
(i) 주어진 데이터셋의 질문을 몇 개의 클러스터로 분할,
(ii) 각 클러스터에서 대표 질문을 샘플링하고 간단한 휴리스틱을 사용하여 Zero-Shot-CoT를 통해 추론 체인 생성. 또한, 효과적인 데모를 얻기 위해 reinforcement learning (RL) 및 complexity-based selection 전략이 제안되었습니다. Fu et al. (2022)은 복잡한 추론 체인 (즉, 더 많은 추론 단계를 가진) 예제를 데모로 선택했습니다. Lu et al. (2022b)는 GPT-3.5와 상호 작용할 때 후보 풀에서 최적의 in-context 예제를 찾고 주어진 training 예제에 대한 예측 보상을 극대화하는 agent를 학습했습니다.
추론 체인 최적화
추론 체인을 최적화하는 주목할만한 방법은 문제 분해입니다. Zhou et al. (2022)은 복잡한 문제를 하위 문제로 분해한 다음 이러한 하위 문제를 순차적으로 해결하는 least-to-most prompting을 제안했습니다. 결과적으로, 주어진 하위 문제를 해결하는 것은 이전에 해결된 하위 문제의 답변에 의해 촉진됩니다.
마찬가지로, Khot et al. (2022)은 다양한 분해 구조를 사용하고 각 하위 질문에 답하기 위해 서로 다른 prompt를 설계했습니다. 추론 체인을 자연어 텍스트로 프롬프팅하는 것 외에도 Chen et al. (2022)은 추론 과정을 프로그램으로 모델링하고 생성된 프로그램을 실행하여 답을 도출하도록 LLMs을 프롬프팅하는 program-of-thoughts (PoT)를 제안했습니다.
또 다른 트렌드는 테스트 질문에 대한 여러 추론 경로에 대해 투표하는 것입니다. Wang et al. (2022b)는 LLMs의 여러 출력을 샘플링한 다음 최종 답변에 대해 다수결을 취하는 self-consistency decoding 전략을 도입했습니다. Wang et al. (2022c) 및 Li et al. (2022c)은 입력 공간에 randomness를 도입하여 투표를 위한 더 다양한 출력을 생성했습니다.
2.2 Fine-Tuning Models를 통한 CoT 추론 유도
최근에는 language models를 fine-tuning하여 CoT 추론을 유도하는 것에 관심이 모아지고 있습니다. Lu et al. (2022a)은 CoT annotations가 있는 대규모 데이터셋에서 encoder-decoder T5 모델을 fine-tuning했습니다. 그러나 답변 전에 추론 체인을 생성하는 방식으로 CoT를 사용하여 답을 추론할 때 (reasoning) 극적인 성능 저하가 관찰되었습니다. 대신, CoT는 답변 후에 설명으로만 사용됩니다. Magister et al. (2022) 및 Ho et al. (2022)는 더 큰 teacher model에 의해 생성된 chain-of-thought 출력에 대해 student model을 fine-tuning하여 knowledge distillation을 사용했습니다. Wang et al. (2022a)는 현재 단계의 컨텍스트를 조건으로 하여 동적으로 prompt를 합성하는 iterative context-aware prompting 접근 방식을 제안했습니다.
1B-models를 CoT reasoners로 훈련하는 데에는 중요한 과제가 있습니다. Wei et al. (2022b)에서 관찰된 바와 같이, 1000억 개 미만의 매개변수를 가진 모델은 잘못된 답변으로 이어지는 비논리적인 CoT를 생성하는 경향이 있습니다. 즉, 1B-models에게는 직접 답을 생성하는 것보다 효과적인 CoT를 생성하는 것이 더 어려울 수 있습니다. 질문에 답변하기 위해 multimodal 입력을 이해해야 하는 multimodal 설정에서는 훨씬 더 어려워집니다. 다음 부분에서는 Multimodal-CoT의 과제를 살펴보고 효과적인 multi-step 추론을 수행하는 방법을 조사할 것입니다.
Challenge of Multimodal-CoT
기존 연구들은 CoT 추론 능력이 특정 규모, 예를 들어 1000억 개 이상의 매개변수를 가진 language models에서 나타날 수 있다고 제안했습니다 (Wei et al., 2022a). 그러나 1B-models에서, 특히 multimodal 시나리오에서는 그러한 추론 능력을 이끌어내는 것은 여전히 해결되지 않은 과제입니다. 이 연구는 1B-models에 초점을 맞춥니다. 왜냐하면 이들은 consumer-grade GPUs (예: 32G 메모리)로 fine-tuning 및 배포될 수 있기 때문입니다. 이 섹션에서는 1B-models가 CoT 추론에 실패하는 이유를 조사하고 이러한 과제를 극복하기 위한 효과적인 접근 방식을 설계하는 방법을 연구할 것입니다.
3.1 CoT의 역할 탐구
먼저, ScienceQA 벤치마크에서 CoT 추론을 위해 text-only baseline을 fine-tuning합니다 (Lu et al., 2022a). FLAN-AlpacaBase를 backbone language model로 채택합니다.3 우리의 task는 텍스트 생성 문제로 모델링되며, 모델은 텍스트 정보를 입력으로 받아 rationale과 answer로 구성된 출력 시퀀스를 생성합니다.
그림 1에 나온 예시처럼, 모델은 질문 텍스트 (Q), 컨텍스트 텍스트 (C) 및 여러 옵션 (M)의 토큰 연결을 입력으로 받습니다. CoT의 효과를 연구하기 위해 세 가지 변형과 성능을 비교합니다.
(i) 답을 직접 예측하는 No-CoT (QCM→A);
(ii) 답변 추론이 rationale에 조건부로 이루어지는 Reasoning (QCM→RA);
(iii) rationale이 답변 추론을 설명하는 데 사용되는 Explanation (QCM→AR).

놀랍게도, 표 2에서 볼 수 있듯이, 모델이 답변 전에 rationales를 예측하면 (QCM→RA) 정확도가 12.31% 감소하는 것을 관찰합니다 (81.63%→69.32%). 이 결과는 rationales가 반드시 정답 예측에 기여하는 것은 아닐 수 있음을 의미합니다. Lu et al. (2022a)에 따르면, 그럴듯한 이유는 모델이 필요한 답변을 얻기 전에 최대 토큰 제한을 초과하거나 예측 생성을 조기에 중단하기 때문일 수 있습니다. 그러나 생성된 출력 (RA)의 최대 길이는 항상 400 토큰 미만이며, 이는 language models의 길이 제한 (즉, T5 모델에서 512)보다 낮습니다. 따라서 rationales가 답변 추론에 해를 끼치는 이유에 대한 더 심층적인 조사가 필요합니다.
3.2 Hallucinated Rationales에 의한 오도
rationales가 답변 예측에 어떤 영향을 미치는지 자세히 알아보기 위해 CoT 문제를 rationale 생성과 answer inference의 두 단계로 분리합니다. rationale 생성과 answer inference에 대해 각각 RougeL 점수와 정확도를 보고합니다.

표 3은 two-stage framework를 기반으로 한 결과를 보여줍니다. two-stage baseline 모델은 rationale 생성에서 90.73 RougeL 점수를 달성하지만 answer inference 정확도는 78.57%에 불과합니다. 표 2의 QCM→A 변형 (81.63%)과 비교했을 때, 이 결과는 two-stage framework에서 생성된 rationale이 답변 정확도를 향상시키지 못함을 보여줍니다.
그런 다음 50개의 오류 사례를 무작위로 샘플링하여 모델이 answer inference를 오도하는 hallucinated rationales를 생성하는 경향이 있음을 발견했습니다. 그림 2에 나온 예시처럼, 모델 (왼쪽 부분)은 시각 콘텐츠에 대한 참조 부족으로 인해 "한 자석의 남극이 다른 자석의 남극에 가장 가깝다"는 환각을 일으킵니다. 이러한 오류는 오류 사례 중 56%의 비율로 발생하는 것을 발견했습니다 (그림 3(a)).
3.3 Multimodality는 효과적인 Rationales에 기여합니다
우리는 hallucination 현상이 효과적인 Multimodal-CoT를 수행하는 데 필요한 vision context 부족 때문이라고 추측합니다. vision 정보를 주입하는 간단한 방법은 이미지를 caption으로 변환한 다음 (Lu et al., 2022a) 두 단계의 입력에 caption을 추가하는 것입니다. 그러나 표 3에서 볼 수 있듯이 caption만 사용하면 성능 향상이 미미합니다 (↑0.80%). 그런 다음 vision features를 language model에 통합하여 고급 기술을 탐구합니다.
구체적으로, 이미지를 ViT 모델 (Dosovitskiy et al., 2021b)에 입력하여 vision features를 추출합니다. 그런 다음 디코더에 입력하기 전에 vision features를 encoded language representations와 융합합니다 (자세한 내용은 4절에서 설명).
흥미롭게도, vision features를 사용하면 rationale 생성의 RougeL 점수가 93.46% (QCM→R)로 향상되었으며, 이는 85.31% (QCMR→A)의 더 나은 답변 정확도에 기여합니다. 이러한 효과적인 rationales를 통해 hallucination 현상이 완화됩니다. 3.2절의 60.7% hallucination 오류가 수정되었습니다 (그림 3(b)), 그림 2 (오른쪽 부분)에 예시된 것처럼.5 지금까지의 분석은 vision features가 효과적인 rationales 생성 및 정확한 답변 추론에 실제로 도움이 된다는 것을 설득력 있게 보여줍니다. two-stage 방법이 one-stage 방법보다 더 나은 성능을 달성하므로 Multimodal-CoT framework에서 two-stage 방법을 선택합니다.
Multimodal-CoT
3절에서의 논의를 바탕으로, Multimodal-CoT를 제안합니다. 핵심 동기는 answer inference가 multimodal 정보를 기반으로 더 잘 생성된 rationales를 활용할 수 있도록 하는 것입니다. 이 섹션에서는 framework의 절차를 개괄하고 model architecture의 기술 설계에 대해 자세히 설명합니다.

그림 4: Multimodal-CoT framework 개요.
Multimodal-CoT는 (i) rationale 생성 및 (ii) answer inference의 두 단계로 구성됩니다. 두 단계 모두 동일한 model structure를 공유하지만 입력 및 출력이 다릅니다. 첫 번째 단계에서는 language 및 vision 입력을 모델에 제공하여 rationales를 생성합니다. 두 번째 단계에서는 원래 language 입력에 첫 번째 단계에서 생성된 rationale을 추가합니다. 그런 다음 업데이트된 language 입력과 원래 vision 입력을 모델에 제공하여 answer를 추론합니다.
4.1 Framework Overview
Multimodal-CoT는 (i) rationale 생성 및 (ii) answer inference의 두 가지 operation 단계로 구성됩니다.
두 단계 모두 동일한 model structure를 공유하지만 입력 X와 출력 Y가 다릅니다. 전체 절차는 그림 4에 설명되어 있습니다. vision-language를 예시로 들어 Multimodal-CoT가 어떻게 작동하는지 보여 드리겠습니다.
rationale 생성 단계에서는 X = {X1_language, X_vision}을 모델에 입력합니다. 여기서 X1_language는 첫 번째 단계의 language 입력을 나타내고 X_vision은 vision 입력, 즉 이미지를 나타냅니다. 예를 들어, 그림 4에서 보듯이 X는 multiple choice reasoning 문제의 질문, 컨텍스트 및 옵션의 연결로 인스턴스화될 수 있습니다 (Lu et al., 2022a). 목표는 rationale 생성 모델 R = F(X)를 학습하는 것입니다. 여기서 R은 rationale입니다.
answer inference 단계에서는 rationale R을 원래 language 입력 X1_language에 추가하여 두 번째 단계의 language 입력 X2_language = X1_language ◦ R을 구성합니다. 여기서 ◦는 연결을 나타냅니다. 그런 다음 업데이트된 입력 X' = {X2_language, X_vision}을 answer inference 모델에 입력하여 최종 답변 A = F(X')를 추론합니다.
두 단계 모두에서 동일한 architecture를 가진 두 모델을 독립적으로 훈련합니다. training set에서 annotated된 요소 (예: X → R, XR → A)를 가져와 supervised learning을 수행합니다. 추론 중에는 주어진 X에 대해 첫 번째 단계에서 훈련된 모델을 사용하여 test set에 대한 rationales를 생성합니다. 이 rationales는 두 번째 단계에서 answer inference에 사용됩니다.
4.2 Model Architecture
언어 입력 X_language ∈ {X1_language, X2_language} 및 vision 입력 X_vision이 주어지면, 길이 N의 target text Y (그림 4에서 rationale 또는 answer)를 생성할 확률을 다음과 같이 계산합니다.

여기서 p_θ (Y_i | X_language, X_vision, Y_<i)는 Transformer-based network (Vaswani et al., 2017)로 구현됩니다. 이 네트워크는 encoding, interaction 및 decoding의 세 가지 주요 절차를 가집니다. 구체적으로, language text를 Transformer encoder에 입력하여 textual representation을 얻은 다음, vision representation과 상호 작용하고 융합한 후 Transformer decoder에 입력합니다.
Encoding
모델 F(X)는 language 및 vision 입력을 모두 받아 다음 함수를 통해 text representation H_language 및 image feature H_vision을 얻습니다.
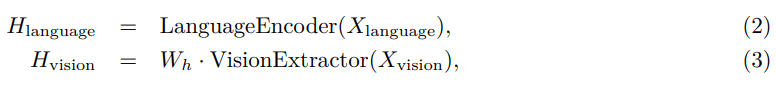
여기서 LanguageEncoder(·)는 Transformer model로 구현됩니다. Transformer encoder의 마지막 layer의 hidden states를 language representation H_language ∈ R^(n×d)로 사용합니다.
여기서 n은 language 입력의 길이를 나타내고
d는 hidden dimension입니다.
한편, VisionExtractor(·)는 입력 이미지를 vision features로 벡터화하는 데 사용됩니다. Vision Transformers (Dosovitskiy et al., 2021a)의 최근 성공에 영감을 받아,
ViT (Dosovitskiy et al., 2021b)와 같은 frozen vision extraction models를 통해 patch-level features를 가져옵니다. patch-level vision features를 얻은 후, 학습 가능한 projection matrix W_h를 적용하여 VisionExtractor(X_vision)의 shape을 H_language의 shape으로 변환합니다. 따라서 H_vision ∈ R^(m×d)를 얻습니다. 여기서 m은 patch의 수입니다.
우리의 접근 방식은 이미지 컨텍스트 유무에 관계없이 두 시나리오 모두에 일반적으로 적용 가능합니다. 관련 이미지가 없는 질문의 경우, 일반 이미지 features와 동일한 shape을 가진 all-zero 벡터를 "blank features"로 사용하여 모델에게 이를 무시하도록 지시합니다.
Interaction
language 및 vision representations를 얻은 후, single-head attention network를 사용하여 text tokens와 image patches를 연관시킵니다. 여기서 query (Q), key (K) 및 value (V)는 각각 H_language, H_vision 및 H_vision입니다. attention 출력 H_attn_vision ∈ R^(n×d)는 다음과 같이 정의됩니다.
H_attn_vision = Softmax(QK⊤/√d_k)V,
여기서 d_k는 single head를 사용하기 때문에 H_language의 dimension과 동일합니다.
그런 다음 gated fusion mechanism (Zhang et al., 2020; Wu et al., 2021; Li et al., 2022a)을 적용하여 H_language 및 H_vision을 융합합니다. 융합된 출력 H_fuse ∈ R^(n×d)는 다음과 같이 얻습니다.
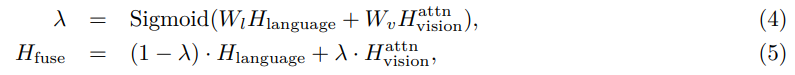
여기서 W_l 및 W_v는 학습 가능한 매개변수입니다.
Decoding
마지막으로 융합된 출력 H_fuse를 Transformer decoder에 입력하여 target Y를 예측합니다.
Experiments
이 섹션에서는 benchmark dataset, 우리 기술의 구현 및 비교를 위한 baselines를 제시합니다. 그런 다음 주요 결과 및 findings를 보고합니다.
5.1 Dataset
우리의 방법은 ScienceQA (Lu et al., 2022a) 및 A-OKVQA (Schwenk et al., 2022) benchmark datasets에서 평가됩니다. 이러한 datasets를 선택한 이유는 annotated reasoning chains를 가진 최신 multimodal reasoning 벤치마크이기 때문입니다.
ScienceQA는 annotated lectures 및 explanations를 포함하는 대규모 multimodal science question dataset입니다. 3개 subjects, 26개 topics, 127개 categories 및 379개 skills에 걸쳐 풍부한 domain diversity를 가진 21k multimodal multiple choice questions를 포함합니다. training, validation 및 test splits에는 각각 12k, 4k 및 4k개의 질문이 있습니다.
A-OKVQA는 knowledge-based visual question answering 벤치마크로, 답변하기 위해 광범위한 상식 및 세계 지식을 필요로 하는 25k개의 질문을 가지고 있습니다. train/val/test에 대해 17k/1k/6k개의 질문이 있습니다. A-OKVQA는 multiple-choice 및 direct answer evaluation 설정을 제공하므로 ScienceQA와의 일관성을 유지하기 위해 multiple-choice 설정을 사용합니다.