Dataset : 논문리뷰 : Data curation via joint example selectionfurther accelerates multimodal learning
Abstract
대규모 사전 학습에서 데이터 큐레이션은 필수적인 요소입니다.
본 연구에서는 데이터 배치를 공동으로 선택하는 것이 개별 예제를 선택하는 것보다 학습에 더 효과적임을 보여줍니다.
다중 모드 대조 학습 목표는 데이터 간의 의존성을 드러내므로 자연스럽게 배치의 공동 학습 가능성을 측정하는 기준을 제공합니다.
본 연구는 이러한 배치를 선택하기 위한 간단하고 다루기 쉬운 알고리즘을 도출하며, 이는 개별적으로 우선순위가 지정된 데이터 포인트를 넘어 학습을 크게 가속화합니다. 더 큰 슈퍼 배치에서 선택함으로써 성능이 향상됨에 따라, 최근 모델 근사화의 발전을 활용하여 관련 계산 오버헤드를 줄입니다.
결과적으로, 본 연구의 접근 방식인 공동 예제 선택을 통한 다중 모드 대조 학습(JEST)은 최대 13배 적은 반복 횟수와 10배 적은 계산량으로 최첨단 모델을 능가합니다.
JEST 성능의 핵심은 사전 학습된 참조 모델을 통해 데이터 선택 프로세스를 더 작고 잘 큐레이션된 데이터 세트의 분포로 유도하는 능력이며, 이는 데이터 큐레이션 수준을 신경망 스케일링 법칙의 새로운 차원으로 드러냅니다.
어려워서 한번 정리 하겠습니다.
데이터 큐레이션의 중요성: 인공지능 모델을 학습시킬 때, 방대한 데이터 중에서 어떤 데이터를 선택하느냐가 성능에 큰 영향을 미칩니다. 이처럼 학습에 적합한 데이터를 선별하는 과정을 '데이터 큐레이션'이라고 합니다. 특히, 대규모 인공지능 모델을 미리 학습시키는 단계에서는 데이터 큐레이션이 더욱 중요합니다.
JEST (Joint Example Selection for Training): 본 연구는 'JEST'라는 새로운 방법을 제안합니다. JEST는 데이터를 무작위로 선택하는 대신, 데이터 간의 관계를 고려하여 함께 선택하는 방식입니다. 이는 마치 레고 블록을 조립할 때, 서로 잘 맞는 블록을 찾아서 함께 끼우는 것과 비슷합니다.
JEST의 장점:
- 학습 속도 향상: 기존 방식보다 최대 13배 빠르게 학습 가능
- 계산량 감소: 기존 방식보다 10배 적은 계산량으로 동일한 성능 달성
- 데이터 효율성 증가: 더 적은 데이터로도 높은 성능 달성 가능
- 새로운 연구 방향 제시: 데이터 큐레이션의 중요성을 강조하고, 인공지능 모델 학습의 새로운 가능성 제시
비유를 통한 설명
JEST는 마치 요리사가 최고의 요리를 만들기 위해 신선하고 좋은 재료를 엄선하는 것과 같습니다. 아무 재료나 사용하는 것이 아니라, 각 재료의 궁합과 맛을 고려하여 최상의 조합을 찾아내는 것입니다. 이처럼 JEST는 인공지능 모델이 최고의 성능을 발휘하도록 돕는 데이터 큐레이션 전문가라고 할 수 있습니다.
Introduction
대규모 사전 학습의 성능을 좌우하는 핵심 요소는 데이터 품질입니다.
언어, 비전 또는 다중 모드 모델링 등 어떤 분야에서든, 잘 큐레이션된 데이터 세트를 사용하여 학습하면 훨씬 적은 데이터로도 뛰어난 성능을 얻을 수 있음이 지속적으로 입증되었습니다. 그러나 현재 데이터 파이프라인은 수동 큐레이션에 크게 의존하고 있으며, 이는 확장하기 어렵고 비용이 많이 듭니다. 반면, 학습 중인 모델의 특징을 사용하여 고품질 데이터를 선택하는 모델 기반 데이터 큐레이션은 이론적으로뿐만 아니라 실제로도 다양한 분야에서 대규모 사전 학습의 느린 power-law 스케일링을 개선할 수 있다는 가능성을 보여줍니다.
기존 방법들은 개별 데이터 포인트 수준에서 큐레이션을 적용합니다. 그러나 배치의 품질은 개별 데이터 포인트의 품질 합 외에도 구성에 따라 달라집니다. 컴퓨터 비전에서는 hard negative(즉, 서로 가깝지만 다른 레이블을 포함하는 포인트 클러스터)가 쉽게 해결할 수 있는 것보다 더 효과적인 학습 신호를 제공하는 것으로 나타났습니다.
본 연구에서는 모델 기반 데이터 선택 기준을 데이터 배치에 적용하는 것이 예제를 개별적으로 선택하는 것보다 학습을 가속화할 수 있는지 질문을 던짐으로써 이 개념을 일반화하고자 합니다. 다중 모드 학습에서 대조 목표는 배치 내 예제 간의 상호 작용을 직접적으로 보여줍니다.
따라서 모델 기반 점수를 기반으로 훨씬 더 큰 '슈퍼 배치'에서 관련 '하위 배치' 데이터를 효율적으로 선택하는 공동 예제 선택(JEST)을 위한 간단하고 다루기 쉬운 알고리즘을 도출했습니다. 사전 학습된 참조 모델(즉, easy-reference)로 배치 점수를 매길 때 JEST는 균일한 배치 선택에 비해 학습을 가속화하며, 동일한 참조를 사용하는 독립적인 예제 선택(CLIPScore에서처럼)을 크게 개선합니다. 온라인 모델 손실을 고려하여 학습 가능성에 따라 배치 점수를 매길 때 JEST는 더욱 향상되어 최대 13배 적은 학습 반복 횟수로 최첨단 모델의 성능과 비슷한 수준을 달성합니다.
학습 가능성이 높은 배치를 발견하려면 훨씬 더 큰 원시 데이터 슈퍼 배치를 샅샅이 조사해야 합니다. 최근 온라인 모델 근사화 기술의 발전을 활용하여 대규모 배치의 학습 가능성 점수 계산을 용이하게 만들었습니다.
이를 통해 계산량을 줄이면서도 유용한 예측을 제공할 수 있습니다. 단일 모델을 여러 해상도로 병렬 학습하여 대규모 슈퍼 배치 점수를 효율적으로 매기고, 가장 학습 가능성이 높은 하위 배치를 찾아 더 가치 있는 계산을 학습에 사용합니다.
학습 및 예제 점수 계산 모두에서 절약 덕분에 학습 효율성의 상당한 이점을 유지하면서 점수 계산의 오버헤드를 133%에서 10%의 추가 FLOP으로 줄였습니다.
이러한 근사 점수 프레임워크인 Flexi-JEST는 11배 적은 반복 횟수와 10배 적은 FLOP으로 최첨단 모델을 생성합니다. 마지막으로, 본 프레임워크 성능의 핵심은 큐레이션 프로세스를 더 작고 잘 큐레이션된 데이터 세트의 분포로 유도하는 능력임을 발견했습니다. 이는 사전 학습된 참조 모델이라는 개념을 통해 고려하는 모델 기반 선택 기준을 통해 자연스럽게 발생하며, 학습된 데이터와 가장 유사한 예제를 우선시합니다.
결정적으로, 이 프로세스는 강력한 데이터 품질 부트스트래핑을 가능하게 함을 발견했습니다. 소규모 큐레이션된 데이터 세트로 학습된 참조 모델은 훨씬 더 큰 데이터 세트의 큐레이션을 효과적으로 안내하여 많은 다운스트림 작업에서 참조 모델의 품질을 훨씬 능가하는 모델 학습을 가능하게 합니다.
Related Work
Offline curation: example-level data pruning
예제 수준 데이터 제거.
대규모 노이즈가 있는 이미지-텍스트 데이터를 수집하고 필터링하는 방법은 처음에는 텍스트 캡션의 품질과 고품질 참조 데이터 세트에 대한 근접성에 초점을 맞췄습니다. 대신 모델 기반 필터링 접근 방식은 사전 학습된 모델(CLIP 및 BLIP 등)을 이미지-텍스트 정렬을 통해 데이터를 큐레이션하기 위한 평가 지표로 사용합니다. 중요한 것은 이러한 모든 방법이 예제 전체에 걸쳐 독립적으로 적용되므로 배치 내 예제 간의 관련 종속성을 고려하지 못한다는 점입니다.
문제 되는 이유:
- 중복 데이터 학습으로 인한 비효율성: 불필요한 데이터를 학습하는 데 시간과 자원을 낭비하게 됩니다.
- 편향된 학습: 특정 주제나 특징에 편중된 데이터만 학습하여 모델의 일반화 성능을 저해할 수 있습니다.
- 데이터 간 상호 작용 무시: 데이터 간의 관계를 통해 얻을 수 있는 추가적인 정보를 활용하지 못합니다.
따라서 본 논문에서는 데이터 묶음 단위로 평가하고 데이터 간의 관계를 고려하는 새로운 방법을 제안할 것 같음.
Offline curation: cluster-level data pruning.
클러스터 수준 데이터 제거. 의미론적 중복 감소 또는 코어셋 선택과 같은 다른 방법들은 주변 데이터 포인트를 고려하여 데이터 포인트의 한계 중요도를 기반으로 큐레이션하는 것을 제안했습니다. 그러나 이러한 방법들은 학습 목표와 분리된 휴리스틱에 기반합니다. 반면, 본 연구의 방법은 대조 사전 학습 목표 함수를 가속화하도록 특별히 조정된 공동 예제 선택을 가능하게 합니다.
- 의미론적 중복 감소 (Semantic Redundancy Reduction): 비슷한 의미를 가진 데이터를 제거하여 데이터셋의 다양성을 높이는 방법입니다. 예를 들어, "고양이가 소파에 앉아 있다"와 "고양이가 의자에 앉아 있다"라는 두 문장은 의미적으로 유사하므로, 둘 중 하나만 선택하여 데이터셋에 포함시키는 것입니다.
- 코어셋 선택 (Core-set Selection): 전체 데이터셋을 대표하는 작은 부분 집합(코어셋)을 선택하는 방법입니다. 이는 마치 많은 사람들 중에서 대표 몇 명을 선출하는 것과 비슷합니다. 코어셋은 전체 데이터셋의 특징을 잘 반영하면서도 크기가 작기 때문에 학습 시간을 단축하고 효율성을 높일 수 있습니다.
본 연구에서는 JEST(Joint Example Selection for Training)라는 새로운 방법을 제안하여 기존 방법들의 한계를 극복하고자 했습니다.
- 휴리스틱 탈피: 기존의 의미론적 중복 감소나 코어셋 선택 방법은 경험적이고 직관적인 휴리스틱에 의존했습니다. 하지만 JEST는 모델 기반 점수를 활용하여 데이터 묶음의 학습 가능성을 객관적으로 평가합니다. 즉, 모델이 실제로 학습하는 과정에서 해당 데이터 묶음이 얼마나 유용한 정보를 제공하는지를 판단하는 것입니다.
- 학습 목표와의 연계: JEST는 단순히 데이터의 특징만 고려하는 것이 아니라, 모델 학습의 목표 함수를 직접적으로 고려하여 데이터 묶음을 선택합니다. 이는 마치 특정 목적에 맞는 도구를 선택하는 것과 같습니다. 예를 들어, 그림을 그릴 때는 붓을 선택하고, 글을 쓸 때는 펜을 선택하는 것처럼, JEST는 모델 학습 목표에 가장 적합한 데이터 묶음을 선택합니다.
- 공동 예제 선택: JEST는 개별 데이터를 독립적으로 평가하는 것이 아니라, 데이터 묶음 전체를 하나의 단위로 간주하고 데이터 간의 상호 작용을 고려하여 평가합니다. 이는 마치 팀 스포츠에서 개별 선수의 능력뿐만 아니라 팀워크까지 고려하여 선수를 선발하는 것과 비슷합니다.
Online data curation with model-based scoring.
모델 기반 점수화. 위에서 설명한 큐레이션 절차를 사용한 사전 필터링은 데이터 품질을 크게 향상시킬 수 있습니다. 그러나 고정된 큐레이션 전략은 학습 과정에서 학습 예제의 관련성이 변경될 수 있다는 점을 고려하지 않아 대규모 활용에 제약이 있습니다. 이러한 문제는 모델이 아직 학습하지 않은 고품질 예제를 식별하는 온라인 데이터 큐레이션 방법으로 해결됩니다. 본 연구는 모델 기반 기준을 예제 수준이 아닌 배치 수준 손실에 적용하고 그에 따라 데이터를 선택하여 이러한 방법을 일반화합니다.
인공지능 모델 학습에 앞서 미리 데이터를 선별하는 과정(사전 필터링)은 데이터 품질을 높이는 데 도움이 됩니다. 하지만 이러한 방식은 모델이 학습하면서 데이터의 중요도가 변할 수 있다는 점을 고려하지 못합니다.
즉, 처음에는 중요해 보였던 데이터가 학습이 진행됨에 따라 덜 중요해지거나, 처음에는 중요하지 않아 보였던 데이터가 나중에 중요해질 수 있습니다.
이러한 문제를 해결하기 위해 '온라인 데이터 큐레이션' 방법이 등장했습니다. 온라인 데이터 큐레이션은 모델이 학습하는 과정 중에 실시간으로 데이터를 평가하고, 모델이 아직 배우지 못한 유용한 데이터를 찾아내는 방법입니다.
본 연구에서는 기존의 온라인 데이터 큐레이션 방법을 더욱 발전시켜, 개별 데이터가 아닌 데이터 묶음(배치) 단위로 평가하고 선택하는 새로운 방법을 제안합니다. 이를 통해 모델이 학습하면서 변화하는 데이터의 중요도를 더욱 효과적으로 반영하고, 학습 효율을 높일 수 있습니다.
Hard negative mining
기존 metric-learning뿐만 아니라 최근 contrastive learning에서도 적절한 negative example 세트를 선택함으로써 얻을 수 있는 효율성 향상에 대한 많은 연구가 진행되어 왔습니다. 본 연구에서는 hard negative mining을 두 가지 방식으로 일반화합니다.
1) 전체 배치를 선택하여 positive pair와 negative pair를 모두 공동으로 mining하고,
2) 학습자에게는 어렵지만 사전 학습된 모델에게는 쉬운 'learnable negative'에 우선순위를 두는 방법을 탐구합니다.
인공지능 모델을 학습시킬 때, 모델이 쉽게 구분할 수 있는 데이터만 계속 학습하면 실력이 늘지 않습니다. 마치 덧셈만 계속 연습하면 덧셈 실력은 늘지만 뺄셈은 배우지 못하는 것과 같습니다. 따라서 인공지능 모델에게 좀 더 어려운 문제를 제시하여 학습 효과를 높이는 것이 중요합니다. 이러한 어려운 문제를 'Hard Negative'라고 합니다.
기존 연구에서는 Hard Negative를 효과적으로 활용하여 모델 학습 효율을 높이는 방법을 주로 두 가지 분야에서 연구해왔습니다.
- Metric Learning (거리 학습): 데이터 간의 유사도를 측정하는 방법을 학습하는 분야입니다. 예를 들어, 얼굴 인식 모델을 학습할 때, 서로 다른 사람의 얼굴을 구분하기 위해 얼굴 간의 거리를 측정하는 방법을 학습합니다.
- Contrastive Learning (대조 학습): 비슷한 데이터는 가깝게, 다른 데이터는 멀게 표현하는 방법을 학습하는 분야입니다. 예를 들어, 이미지 분류 모델을 학습할 때, 같은 종류의 이미지는 비슷하게, 다른 종류의 이미지는 다르게 표현하는 방법을 학습합니다.
본 연구에서는 이러한 Hard Negative Mining 개념을 더욱 발전시켜 새로운 방법을 제안합니다.
- Positive & Negative Pair 공동 마이닝: 기존에는 주로 Hard Negative에만 초점을 맞췄지만, 본 연구에서는 Positive (서로 비슷한 데이터)와 Negative (서로 다른 데이터) 쌍을 모두 함께 고려하여 학습 효과를 높입니다.
- Learnable Negative 우선 학습: 학습 중인 모델에게는 어렵지만, 이미 잘 학습된 모델에게는 쉬운 문제인 Learnable Negative를 우선적으로 학습시켜 모델의 성장을 촉진합니다. 이는 마치 숙련된 선생님이 학생에게 적절한 난이도의 문제를 제시하여 실력 향상을 돕는 것과 같습니다.
용어 설명:
- Hard Negative: 학습 중인 모델이 구분하기 어려운 데이터 샘플 또는 샘플 쌍
- Metric Learning (거리 학습): 데이터 간의 유사도를 측정하는 방법을 학습하는 분야
- Contrastive Learning (대조 학습): 비슷한 데이터는 가깝게, 다른 데이터는 멀게 표현하는 방법을 학습하는 분야
- Learnable Negative: 학습 중인 모델에게는 어렵지만, 사전 학습된 모델에게는 쉬운 문제
Model approximation
여러 연구에서 더 작은 모델을 훨씬 더 큰 모델의 대체재로 사용하여 데이터 선택을 할 수 있음을 입증했습니다. 그러나 최근에는 추론 시간에 계산량과 성능 간의 균형을 조절할 수 있는 여러 기술이 개발되어 더 작은 모델을 별도의 학습 없이 "임베딩"할 수 있습니다. 비전 트랜스포머의 경우, 패치 제거 또는 레이어 제거 또는 토큰 해상도 감소는 특징적인 균형을 만듭니다. 본 연구는 온라인 데이터 선택에서 이러한 기술을 최초로 사용한 연구입니다.
Methods
3.1 Model-based batch-selection criteria
본 연구에서 학습하고자 하는 모델을 학습자라고 합니다.
크기가 B인 '슈퍼 배치' D에서 학습에 가장 관련성이 높은 하위 배치 B = {xi, i ∈ [1, ..., b]} ⊂ D를 추출하고자 합니다.
우선순위 샘플링은 개별 예제의 점수를 매긴 다음 이 점수에 비례하여 샘플링을 수행합니다.
본 연구에서는 대신 전체 하위 배치의 점수를 매기고 이러한 배치 수준 점수에 따라 샘플링을 수행합니다. 학습자 모델 및 또는 사전 학습된 참조 모델의 손실을 사용하는 모델 기반 점수 함수를 고려합니다.
Hard Learner. 직관적인 휴리스틱은 매개변수 θ를 사용하여 학습자에서 높은 손실을 갖는 배치 B에 우선순위를 부여하는 것입니다:

이는 사소한 데이터를 버리는 바람직한 속성을 가지고 있습니다. 이 휴리스틱은 작고 깨끗한 데이터 세트에서는 효과가 있는 것으로 입증되었지만, 노이즈가 있는 예제도 업샘플링하기 때문에 더 크고 덜 큐레이션된 데이터 세트에서는 이점보다 해가 되는 경향이 있습니다
이 수식의 의미는 다음과 같습니다.
- : 하위 배치(B)에 대한 Hard Learner 점수를 의미합니다. 즉, 현재 학습 중인 모델(θ로 표현)이 해당 하위 배치를 얼마나 어려워하는지를 나타내는 점수입니다.
- : 현재 학습 중인 모델(θ)이 하위 배치(B)에 대해 계산한 손실(loss) 값을 의미합니다. 손실 값은 모델의 예측과 실제 정답 간의 차이를 나타내며, 손실 값이 클수록 모델이 해당 데이터를 학습하기 어렵다는 것을 의미합니다.
따라서 Hard Learner 점수는 학습 중인 모델이 특정 하위 배치를 얼마나 어려워하는지를 손실 값을 통해 정량화한 것입니다. Hard Learner 점수가 높은 하위 배치는 모델이 아직 충분히 학습하지 못한 부분을 나타내므로, 이러한 하위 배치를 우선적으로 학습시키면 모델의 성능 향상에 도움이 될 수 있습니다.
장점:
- 사소한 데이터 제거: Hard Learner 점수는 모델이 쉽게 처리할 수 있는 데이터(즉, 이미 잘 학습된 데이터)에는 낮은 점수를 부여합니다. 따라서 이 점수를 기준으로 데이터를 선별하면 모델이 이미 알고 있는 정보를 반복 학습하는 것을 피할 수 있습니다. 이는 학습 시간을 단축하고 모델의 성능을 향상시키는 데 도움이 됩니다.
단점:
- 노이즈 데이터 업샘플링: Hard Learner 점수는 모델이 처리하기 어려운 데이터(즉, 노이즈가 많거나 잘못 레이블링된 데이터)에는 높은 점수를 부여합니다. 따라서 이 점수를 기준으로 데이터를 선별하면 노이즈 데이터가 학습에 더 많이 사용될 수 있습니다. 이는 모델의 학습을 방해하고 성능을 저하시킬 수 있습니다.
결론:
Hard Learner 점수는 작고 깨끗한 데이터셋에서는 효과적으로 작동합니다. 하지만 노이즈가 많거나 덜 정제된 대규모 데이터셋에서는 오히려 모델 학습에 방해가 될 수 있습니다. 따라서 본 연구에서는 Hard Learner 점수만 사용하는 대신, 다른 점수 함수와 함께 사용하거나 더 발전된 데이터 선별 방법을 제안합니다.
Easy Reference. 반대로, 매개변수 θ∗를 사용하여 사전 학습된 참조 모델에서 "쉬운"(손실이 적은) 데이터를 업샘플링하도록 선택할 수도 있습니다:

이 쉬운 참조 휴리스틱은 다중 모드 학습에서 고품질 예제를 식별하는 데 성공적으로 사용되었지만, 학습자의 현재 상태를 반영하지 않으므로 참조 모델 선택에 지나치게 의존할 수 있으며 대규모 계산 예산으로 확장되지 않을 수 있습니다.
이 수식은 Easy Reference 점수를 나타내는 수식입니다.
- : 사전 학습된 참조 모델의 매개변수를 의미합니다. 즉, 이미 잘 학습되어 특정 작업에 대한 성능이 좋은 모델입니다.
- : 하위 배치(B)에 대한 Easy Reference 점수를 의미합니다. 즉, 사전 학습된 참조 모델()이 해당 하위 배치를 얼마나 쉽게 처리할 수 있는지를 나타내는 점수입니다.
- : 사전 학습된 참조 모델()이 하위 배치(B)에 대해 계산한 손실(loss) 값에 음수 부호를 붙인 값입니다. 손실 값이 작을수록 모델이 해당 데이터를 쉽게 처리할 수 있다는 것을 의미하므로, 음수 부호를 붙여 점수가 높아지도록 합니다.
따라서 Easy Reference 점수는 사전 학습된 참조 모델이 특정 하위 배치를 얼마나 쉽게 처리할 수 있는지를 손실 값을 통해 정량화한 것입니다. Easy Reference 점수가 높은 하위 배치는 참조 모델이 이미 잘 알고 있는 정보를 담고 있을 가능성이 높습니다. 이러한 하위 배치를 우선적으로 학습시키면 학습 중인 모델이 새로운 지식을 효율적으로 습득하는 데 도움이 될 수 있습니다.
장점:
- 고품질 예제 식별: 사전 학습된 모델을 활용하여 학습에 유용한 고품질 데이터를 효과적으로 찾아낼 수 있습니다.
- 다중 모드 학습에 적합: 이미지와 텍스트 등 다양한 형태의 데이터를 함께 학습하는 다중 모드 학습에 성공적으로 적용되어 왔습니다.
단점:
- 학습자 상태 미반영: 학습 중인 모델의 현재 상태나 학습 진행 상황을 고려하지 않고 데이터를 선택합니다. 따라서 학습 초반에는 유용했던 데이터가 학습 후반에는 불필요해질 수 있습니다.
- 참조 모델 의존성: 어떤 참조 모델을 사용하느냐에 따라 데이터 선택 결과가 크게 달라질 수 있습니다. 따라서 최적의 참조 모델을 선택하는 것이 중요하며, 잘못된 참조 모델을 사용하면 학습 효율이 떨어질 수 있습니다.
- 대규모 학습의 비효율성: 대규모 데이터셋에 적용할 경우, 참조 모델을 이용한 데이터 점수 계산에 많은 시간과 자원이 소모되어 비효율적일 수 있습니다.
Learnability. 마지막으로, Mindermann 등은 손실 차이를 기준으로 우선순위를 지정하여 이러한 점수를 결합하는 것을 제안합니다:

본 연구에서 학습 가능성 점수라고 하는 이 휴리스틱은 학습되지 않았지만 학습 가능한 데이터를 업샘플링하는 이점이 있으며, 개별 예제를 독립적으로 우선순위를 지정할 때도 대규모 학습을 가속화하는 것으로 나타났습니다.
따라서 본 연구에서는 주로 학습 가능성 점수를 고려하지만, 완전성을 위해 easy reference 점수를 사용한 ablation study도 제공합니다.
"하위 배치"와 "슈퍼 배치" 크기의 비율은 필터링 비율 f = 1 - b/B를 정의합니다.
즉, 각 반복에서 버려지는 데이터의 비율입니다. 주어진 학습자 배치 크기 b에 대해 더 높은 필터링 비율은 슈퍼 배치에 대한 더 많은 추론 통과가 필요하므로 점수 계산 비용을 증가시킵니다.
이 수식은 Learnability 점수를 나타냅니다. Learnability 점수는 Hard Learner 점수와 Easy Reference 점수를 결합한 것으로, 현재 학습 중인 모델에게 적절한 난이도의 데이터를 제공하기 위한 점수입니다.
- : 하위 배치(B)에 대한 Learnability 점수를 의미합니다. 즉, 현재 학습 중인 모델(θ)에게 얼마나 학습하기 적합한지를 나타내는 점수입니다.
- : Hard Learner 점수로, 현재 학습 중인 모델(θ)이 하위 배치(B)에 대해 계산한 손실(loss) 값입니다. 손실 값이 클수록 모델이 해당 데이터를 학습하기 어렵다는 것을 의미합니다.
- : Easy Reference 점수로, 사전 학습된 참조 모델(θ*)이 하위 배치(B)에 대해 계산한 손실(loss) 값에 음수 부호를 붙인 값입니다. 손실 값이 작을수록 모델이 해당 데이터를 쉽게 처리할 수 있다는 것을 의미하므로, 음수 부호를 붙여 점수가 높아지도록 합니다.
따라서 Learnability 점수는 아래와 같이 계산됩니다.
s_learn(B|θ, θ∗) = s_hard(B|θ) + s_easy(B|θ∗) = ℓ(B|θ) - ℓ(B|θ∗)
즉, Learnability 점수는 현재 학습 중인 모델에게는 어렵지만(높은 Hard Learner 점수), 사전 학습된 참조 모델에게는 쉬운(높은 Easy Reference 점수) 데이터에 높은 점수를 부여합니다. 이러한 데이터는 학습 중인 모델이 아직 배우지 못한 새로운 정보를 담고 있으면서도, 너무 어렵지 않아 학습에 적합하다고 판단할 수 있습니다.
Learnability 점수를 활용하면 모델 학습에 가장 도움이 되는 데이터를 효율적으로 선택할 수 있으며, 이는 모델의 성능 향상과 학습 시간 단축에 기여할 수 있습니다.
Learnability 점수의 효과를 검증하기 위해, 본 연구에서는 'Ablation Study'라는 실험을 진행
본 연구에서는 주로 Learnability 점수를 활용하여 모델 학습에 가장 도움이 되는 데이터 묶음(하위 배치)을 선택합니다. 하지만 연구의 완성도를 높이기 위해, Easy Reference 점수만 사용했을 때 어떤 결과가 나오는지 비교하는 실험(Ablation Study)도 함께 진행합니다.
필터링 비율 (Filtering Ratio)
필터링 비율(f)은 전체 데이터 묶음(슈퍼 배치, 크기 B)에서 실제로 학습에 사용되는 데이터 묶음(하위 배치, 크기 b)의 비율을 나타냅니다. 수식으로 표현하면 다음과 같습니다.
f = 1 - b/B
- b: 하위 배치의 크기 (학습에 실제로 사용되는 데이터 수)
- B: 슈퍼 배치의 크기 (전체 데이터 수)
예를 들어, 슈퍼 배치의 크기(B)가 1000이고 하위 배치의 크기(b)가 100이라면, 필터링 비율(f)은 0.9 (90%)가 됩니다. 이는 전체 데이터 중 90%를 버리고 10%만 학습에 사용한다는 의미입니다.
3.2 Joint example selection (JEST) for multimodal learning
Multimodal learning losses.
인터넷 규모의 이미지-텍스트 쌍 데이터 세트를 사용할 수 있게 됨에 따라 멀티 모달 학습은 시각적 표현을 학습하는 기본적인 수단이 되었습니다.
Contrastive learning은 쌍으로 구성된 예제의 두 modality 정렬을 최대화하는 동시에 쌍이 아닌 예제의 정렬을 최소화하는 것을 목표로 합니다.
Sigmoid- 및 softmax-contrastive 손실은 배치 수준 손실

를 통해 이를 달성하며,
여기서 조건부 손실 ℓ(xi |θ, B)는 sigmoid 또는 softmax 대조 함수를 사용할 수 있습니다. Zhai 등은 sigmoid-contrastive 손실이 softmax-contrastive 손실보다 확장 가능한 대안임을 입증했으므로 기본적으로 이를 채택합니다. 그럼에도 불구하고 본 연구의 결과는 softmax-contrastive 손실을 사용할 때도 유효함을 보여줍니다.
본 논문에서는 다음과 같은 수식으로 다중 모드 학습 손실 함수를 정의합니다.
ℓ(B|θ) = 1/b Σ^b_i=1 ℓ(xi |θ, B)
- ℓ(B|θ): 배치(B) 전체의 손실 값을 의미합니다.
- b: 배치(B)에 포함된 데이터 샘플의 개수입니다.
- ℓ(xi |θ, B): i번째 데이터 샘플()에 대한 조건부 손실 값을 의미합니다. 즉, 배치(B) 내 다른 데이터 샘플들과의 관계를 고려하여 계산된 손실 값입니다.
Sigmoid-Contrastive Loss vs. Softmax-Contrastive Loss
조건부 손실 값 ℓ(xi |θ, B)를 계산하는 방법에는 여러 가지가 있습니다. 본 논문에서는 'Sigmoid-Contrastive Loss'와 'Softmax-Contrastive Loss' 두 가지 방법을 비교하고, Sigmoid-Contrastive Loss가 더 효율적이고 확장성이 좋다는 것을 보여줍니다.
Sigmoid-Contrastive Loss: 각 데이터 쌍(이미지-텍스트 쌍)에 대해 독립적으로 손실 값을 계산합니다.
Softmax-Contrastive Loss: 배치 내 모든 데이터 쌍을 고려하여 손실 값을 계산합니다.
Sigmoid-Contrastive Loss는 Softmax-Contrastive Loss보다 계산량이 적기 때문에 대규모 데이터셋 학습에 더 적합합니다.
Sigmoid-Contrastive Loss:
- 데이터 쌍 단위 비교: 각 데이터 쌍(예: 이미지-텍스트 쌍)을 독립적으로 비교하여 손실을 계산합니다. 즉, 긍정적인 쌍(관련 있는 이미지-텍스트 쌍)은 서로 가깝게, 부정적인 쌍(관련 없는 이미지-텍스트 쌍)은 서로 멀게 표현하는 것을 목표로 합니다. 각 쌍의 손실 값은 다른 쌍과 무관하게 계산됩니다.
Softmax-Contrastive Loss:
- 배치 내 모든 쌍 고려: 배치(Batch) 내 모든 데이터 쌍을 고려하여 손실을 계산합니다. 즉, 긍정적인 쌍은 서로 가깝게 표현될 뿐만 아니라, 배치 내 다른 모든 부정적인 쌍보다 더 가깝게 표현되는 것을 목표로 합니다. 각 쌍의 손실 값은 배치 내 다른 쌍과의 관계에 따라 달라집니다.

이 알고리즘은 대량의 데이터 쌍(이미지-텍스트) 묶음(super-batch)에서 학습에 가장 유용한 하위 묶음(sub-batch)을 효율적으로 선택하는 방법을 제공합니다.
입력:
- learner_loss: 현재 학습 중인 모델이 각 데이터 쌍에 대해 계산한 손실 값 (Hard Learner 점수)
- ref_loss: 사전 학습된 참조 모델이 각 데이터 쌍에 대해 계산한 손실 값
- n_chunks: 하위 배치를 몇 개의 청크로 나눌지 결정하는 매개변수 (기본값: 16)
- filter_ratio: 버려지는 데이터 비율 (기본값: 0.8, 즉 80%의 데이터를 버리고 20%만 선택)
- method: 점수 계산 방법 ("learnability" 또는 "easy_reference")
출력:
- inds: 선택된 하위 배치의 인덱스 배열
코드 설명:
- 점수 계산:
- method에 따라 Learnability 점수 또는 Easy Reference 점수를 계산합니다.
- 데이터 크기 계산:
- n_images: 전체 데이터 쌍의 개수
- n_draws: 각 청크의 크기 (선택될 데이터 쌍의 개수 / 청크 수)
- 첫 번째 청크 샘플링:
- logits_ii: 각 데이터 쌍 자체와의 유사도 점수(대각선 요소)를 추출합니다.
- inds: 첫 번째 청크를 무작위로 샘플링합니다.
- 나머지 청크 샘플링 (반복):
- is_sampled: 현재까지 샘플링된 데이터 쌍을 나타내는 이진 배열을 생성합니다.
- logits_ij, logits_ji: 샘플링된 데이터와 나머지 데이터 간의 유사도 점수를 계산합니다.
- logits: 위에서 계산된 점수를 합산하여 각 데이터 쌍의 조건부 학습 가능성 점수를 계산합니다.
- logits = logits - is_sampled * 1e8: 이미 샘플링된 데이터는 다시 선택되지 않도록 매우 낮은 점수를 부여합니다.
- new_inds: 조건부 학습 가능성 점수에 따라 다음 청크를 샘플링합니다.
- inds: 샘플링된 인덱스 배열을 확장합니다.
- 선택된 인덱스 반환:
- inds: 최종적으로 선택된 하위 배치의 인덱스 배열을 반환합니다.
추가 설명:
- random.choice: 주어진 확률 분포에 따라 무작위로 샘플을 추출하는 함수입니다.
- np.diag: 행렬의 대각선 요소를 추출하는 함수입니다.
- np.eye: 단위 행렬을 생성하는 함수입니다.
- np.exp: 지수 함수(e^x)를 계산하는 함수입니다.
이 알고리즘은 효율적으로 데이터 묶음을 평가하고 선택하여 학습 시간을 단축하고 모델 성능을 향상시키는 데 기여합니다.
def jointly_sample_batch(learner_loss, ref_loss, n_chunks=16, filter_ratio=0.8, method="learnability"):
# 점수 계산 방법 선택: learnable 또는 easy_reference
scores = learner_loss - ref_loss if method == "learnability" else -ref_loss
n_images = scores.shape[0] # 전체 이미지-텍스트 쌍 개수 (B)
n_draws = int(n_images * (1 - filter_ratio) / n_chunks) # 각 청크(chunk)의 크기 (b/n_chunks)
logits_ii = np.diag(scores) # 각 데이터 쌍 자체와의 유사도 점수 (대각 행렬)
inds = random.choice(logits_ii, n_draws) # 첫 번째 청크 무작위 샘플링
for _ in range(n_chunks - 1): # 나머지 청크 샘플링 (반복)
is_sampled = np.eye(n_images)[inds].sum(axis=0) # 현재 샘플링된 데이터 표시 (1 또는 0)
# 샘플링된 데이터와 나머지 데이터 간 유사도 점수 계산
logits_ij = (scores * is_sampled.reshape(n_images, 1)).sum(axis=0)
logits_ji = (scores * is_sampled.reshape(1, n_images)).sum(axis=1)
logits = logits_ii + logits_ij + logits_ji # 조건부 학습 가능성 점수 계산
logits = logits - is_sampled * 1e8 # 이미 샘플링된 데이터는 제외
new_inds = random.choice(n_images, n_draws, p=np.exp(logits)) # 다음 청크 샘플링
inds = np.concatenate((inds, new_inds)) # 샘플링된 인덱스 추가
return inds # 선택된 하위 배치 인덱스 반환
scores = learner_loss - ref_loss if method == "learnability" else -ref_loss
- learner_loss: 현재 학습 중인 모델이 해당 데이터 쌍에 대해 계산한 손실 값입니다. 값이 클수록 모델이 해당 데이터 쌍을 학습하기 어렵다는 것을 의미합니다.
- ref_loss: 사전 학습된 참조 모델이 해당 데이터 쌍에 대해 계산한 손실 값입니다. 값이 작을수록 참조 모델이 해당 데이터 쌍을 쉽게 처리할 수 있다는 것을 의미합니다.
따라서 learner_loss - ref_loss 값이 크다는 것은, 현재 학습 중인 모델에게는 어렵지만 참조 모델에게는 쉬운 데이터 쌍이라는 것을 의미합니다. 즉, Learnability 점수가 높은 데이터 쌍은 학습 중인 모델의 성능을 향상시키는 데 가장 도움이 될 가능성이 높은 데이터 쌍입니다.
n_images = scores.shape[0] # 전체 이미지-텍스트 쌍 개수 (B)
n_draws = int(n_images * (1 - filter_ratio) / n_chunks) # 각 청크(chunk)의 크기 (b/n_chunks)
n_images = scores.shape[0]
- scores: 앞서 계산된 Learnability 점수 또는 Easy Reference 점수를 담고 있는 배열입니다. 이 배열의 형태는 (B, B)이며, 여기서 B는 슈퍼 배치(전체 데이터 묶음)의 크기를 나타냅니다.
- scores.shape[0]: scores 배열의 첫 번째 차원의 크기를 반환합니다. 즉, 슈퍼 배치에 포함된 데이터 쌍의 개수를 의미합니다.
- n_images: 전체 데이터 쌍의 개수를 저장하는 변수입니다.
2. n_draws = int(n_images * (1 - filter_ratio) / n_chunks)
- filter_ratio: 필터링 비율을 나타내는 변수로, 0.8이면 전체 데이터 쌍의 80%를 버리고 20%만 선택한다는 의미입니다.
- n_chunks: 하위 배치를 몇 개의 청크로 나눌지를 나타내는 변수입니다. 기본값은 16입니다.
- n_images * (1 - filter_ratio): 필터링 후 남은 데이터 쌍의 개수를 계산합니다.
- n_images * (1 - filter_ratio) / n_chunks: 각 청크에 포함될 데이터 쌍의 개수를 계산합니다.
- int(): 계산 결과를 정수로 변환합니다.
- n_draws: 각 청크에 포함될 데이터 쌍의 개수를 저장하는 변수입니다.
요약:
- n_images: 전체 데이터 쌍의 개수를 저장합니다.
- n_draws: 각 청크에 포함될 데이터 쌍의 개수를 계산하고 저장합니다.
이 두 변수는 이후 JEST 알고리즘에서 데이터 쌍을 샘플링하고 하위 배치를 구성하는 데 사용됩니다.
청크(Chunk)는 JEST 알고리즘에서 데이터 묶음(하위 배치)을 구성하기 위해 사용되는 중간 단계의 데이터 묶음입니다.
JEST 알고리즘은 전체 데이터 묶음(슈퍼 배치)에서 학습에 가장 유용한 데이터를 한 번에 모두 선택하는 것이 아니라, 여러 단계에 걸쳐 조금씩 선택합니다. 이때 각 단계에서 선택되는 데이터 묶음을 청크라고 합니다.
예를 들어, 1000개의 데이터 쌍으로 이루어진 슈퍼 배치에서 100개의 데이터 쌍을 선택하여 하위 배치를 구성하고 싶다고 가정해 봅시다. 이때 청크 크기를 10으로 설정하면, JEST 알고리즘은 10개의 데이터 쌍씩 10번에 걸쳐 선택하여 총 100개의 데이터 쌍으로 이루어진 하위 배치를 구성합니다.
청크를 사용하는 이유는 다음과 같습니다.
- 계산 효율성: 전체 데이터 묶음을 한 번에 평가하는 것은 계산량이 많아 비효율적입니다. 청크를 사용하면 각 단계에서 더 적은 데이터만 평가하면 되므로 계산 효율성을 높일 수 있습니다.
- 다양성 확보: 한 번에 많은 데이터를 선택하면 특정 유형의 데이터에 편향될 가능성이 있습니다. 청크를 사용하면 여러 단계에 걸쳐 다양한 유형의 데이터를 선택할 수 있어 데이터 다양성을 확보할 수 있습니다.
- 점진적 개선: 각 청크를 선택할 때마다 이전에 선택된 데이터를 고려하여 다음 데이터를 선택합니다. 이를 통해 모델이 학습하면서 변화하는 데이터의 중요도를 반영하고, 점진적으로 더 좋은 데이터를 선택할 수 있습니다.
본 논문에서 제시하는 JEST 알고리즘은 청크를 활용하여 효율적으로 데이터 묶음을 선택하고, 이를 통해 학습 시간을 단축하고 모델 성능을 향상시키는 데 기여합니다.
Joint example selection.
배치의 대조 손실은 조건부 손실의 합으로 분해되기 때문에,

의 공동 학습 가능성은 배치 내 다른 예제가 주어졌을 때 각 예제의 조건부 학습 가능성 s(x|θ, θ∗ , B)의 합으로 분해됩니다.
본 연구는 차단된 Gibbs 샘플링에서 영감을 받은 순차적 접근 방식(알고리즘 1 참조)을 통해 공동 학습 가능성에 비례하여 배치를 샘플링하고자 합니다.
즉,

반복 n에서 배치에 이미 포함된 예제의 하위 집합 Bn이 주어지면 나머지 후보 예제 xi의 조건부 학습 가능성 s(xi |θ, θ∗ , Bn)을 계산하고, 이러한 확률에 따라 새로운 예제 청크 {Xk}를 독립적으로 그리고 중복 없이 샘플링합니다. p(Xk = xi) ∝ exp(s(xi |θ, θ∗ , Bn)). 이 청크를 이전 하위 집합에 추가하여 배치를 업데이트합니다. Bn+1 = Bn ∪ {Xk}이며, n = N, 즉 청크 수가 될 때까지 반복합니다.
첫 번째 청크 B1은 무조건 학습 가능성(즉, 자기 유사성만) s(xi |θ, θ∗ , ∅)) = ℓ(xi |θ, ∅) − ℓ(xi |θ ∗ , ∅)을 사용하여 샘플링하며, 여기서 무조건 손실은 softmax-contrastive 손실의 경우

sigmoid-contrastive 손실의 경우

로 계산됩니다.
비교적 적은 수의 청크(N = 16, 각 반복에서 b/N = 2,048개의 예제를 독립적으로 샘플링)만으로도 학습 가능성이 매우 높은 배치를 복구할 수 있음을 발견했습니다(4.1절, 알고리즘 1 참조).
3.3 Efficient scoring and multi-resolution training
Efficient scoring with online model approximation.
대규모 슈퍼 배치의 점수 계산은 반복당 비용을 증가시켜 전체 FLOP 측면에서 효율성 이득을 감소시킵니다.
Evans 등은 더 큰 학습자를 대신하여 데이터를 효율적으로 점수화하기 위해 추가적인 소형 프록시 모델이 필요했지만, 본 연구에서는 온라인 모델 근사화를 사용하여 이러한 요구 사항을 제거했습니다.
각 추론 단계에서 대부분의 비용을 차지하는 이미지 인코딩만 근사화합니다. 이를 위해 FlexiViT 아키텍처를 채택했습니다. 이 아키텍처는 성능 저하를 최소화하면서 이미지 해상도를 낮춥니다 (패치 드롭과의 비교는 그림 9 참조). 실험에서는 32x32 픽셀 패치로 슈퍼 배치를 평가했습니다. 이는 16x16 패치 크기에서의 전체 해상도 점수 계산과 비교하여 FLOP를 72%, 실제 시간을 67% 감소시킵니다 (A.4절 참조).

그림 9: 모델 근사화 전략 비교. 50% 필터링 비율에서 Flexi-JEST와 PatchDrop-JEST를 비교합니다.
X축에서 공동 학습 점수 모델에 사용되는 데이터 비율을 변경합니다. 녹색 곡선은 JEST 실행을, 파란색 곡선은 데이터 큐레이션 없이 동일한 IID 실행을 보여줍니다. 모든 실행은 isoFLOP에서 수행되었으며, 그림 4를 참조하십시오.
왼쪽: FlexiViT 점수는 분포 외 추론에서 0-shot 성능이 좋지 않지만, 공동 학습을 통해 빠르게 회복됩니다.
오른쪽: 패치 드롭은 0-shot 추론에서 더 강건하지만, 공동 학습의 이점을 많이 얻지 못합니다.
A.4 FLOP calculations for JEST / Flexi-JEST
단일 데이터 포인트 학습 비용은 학습자 모델의 순방향 전달(forward pass) F의 약 3배라고 가정합니다 [25]. 따라서 단일 JEST 업데이트 비용은 다음과 같이 계산할 수 있습니다.

여기서 B와 b는 각각 슈퍼 배치와 하위 배치 크기이며, f = 1 - b/B입니다.
기본 JEST 방법은 학습자에 대한 근사치를 사용하지 않으므로 점수 계산 중 순방향 전달을 캐시하고 기울기 계산에 다시 사용할 수 있습니다. IID 업데이트에 비해 필터링 비율 f = 0.8에서 단일 JEST 반복 비용은 αJEST = 7/3 = 2.33입니다.
Flexi-JEST는 두 가지 근사치를 사용합니다.
첫째, 학습 배치를 전체:근사 학습자 간에 50:50으로 분할하여 효과적으로 방법을 병렬화하고 학습 데이터 포인트당 비용을 줄입니다.
둘째, 점수를 계산할 때 학습자를 근사화하여 점수 계산 비용을 줄입니다. 따라서 단일 Flexi-JEST 업데이트의 전체 비용은 다음과 같이 계산할 수 있습니다.

여기서 A는 모델 근사화로 인한 FLOP 감소 계수입니다(즉, 패치 크기 증가, 3.3절 참조). 근사 학습자 버전으로 계산되기 때문에 점수 계산의 순방향 전달을 더 이상 캐시할 수 없습니다. IID 업데이트에 비해 필터링 비율 f = 0.8 및 근사 계수 A = 0.25에서 단일 Flexi-JEST 반복 비용은 αFlexi-JEST = 1.04입니다. 실제로, 패치 크기가 두 배로 증가하여 FLOP 감소가 A = 0.28에 더 가깝다고 추정했으며, 이는 패치 수를 0.5^2만큼 줄여 예상되는 A = 0.25보다 약간 높습니다. 본 연구에서는 이러한 보수적인 계산(αFlexi-JEST = 1.10)을 사용합니다.
: 단일 반복 비용은 1.1배 늘었지만 학습 시간은 75% 줄었다.
A.4: JEST와 Flexi-JEST의 계산량 비교 분석 (쉽게 설명)
인공지능 학습 비용 절감: FLOP 계산
A.4는 JEST와 Flexi-JEST라는 두 가지 데이터 선별 방법을 사용했을 때, 인공지능 모델 학습에 필요한 계산량을 비교 분석한 내용입니다. 여기서 계산량은 FLOP(Floating Point Operations, 부동 소수점 연산 횟수)으로 측정합니다. FLOP은 컴퓨터가 인공지능 모델을 학습시키는 데 필요한 계산 횟수를 의미하며, FLOP이 높을수록 더 많은 시간과 컴퓨터 자원이 필요합니다.
JEST vs. Flexi-JEST: 누가 더 효율적일까?
- JEST: 기본적인 JEST 방법은 모델을 단순화하지 않고, 데이터 묶음(배치) 단위로 점수를 매겨 학습에 유용한 데이터를 선별합니다. 이 방법은 정확도는 높지만, 계산량이 많다는 단점이 있습니다.
- Flexi-JEST: Flexi-JEST는 JEST의 변형으로, 모델을 단순화하여 계산량을 줄이는 기술을 적용했습니다. 즉, 모델을 '다이어트'시켜 계산량을 줄이면서도 학습에 필요한 유용한 데이터를 효과적으로 선별하는 방법입니다.
계산량 비교 결과: Flexi-JEST의 승리!
연구 결과, Flexi-JEST는 JEST보다 훨씬 적은 계산량으로 비슷한 수준의 성능을 달성할 수 있었습니다. 이는 Flexi-JEST가 모델을 단순화하여 계산량을 줄이면서도 학습에 필요한 핵심 정보를 효과적으로 파악하기 때문입니다.
결론: 효율적인 인공지능 학습을 위한 Flexi-JEST
본 논문에서는 Flexi-JEST를 통해 인공지능 모델 학습에 필요한 계산량을 크게 줄이면서도 성능을 유지하는 방법을 제시합니다. 이는 인공지능 모델 학습의 효율성을 높이고, 더 빠르고 저렴하게 고성능 모델을 개발하는 데 기여할 수 있습니다.
Multi-resolution training.
저희는 낮은 해상도(즉, 큰 패치 사용)로 예제 점수를 매기고 싶지만, 테스트 시에는 전체 해상도(즉, 작은 패치 사용)로 모델을 평가하고 싶습니다. 두 해상도의 계산을 모두 가능하게 하기 위해, 간단히 두 해상도 모두에서 학습을 진행합니다.
구체적으로, 학습할 하위 배치 B가 주어지면 이를 무작위로 두 부분, B^lo와 B^hi로 나누고 각 부분을 다른 해상도로 인코딩합니다.
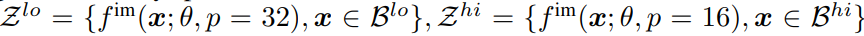
그런 다음 이러한 이미지 임베딩은 Z = Z lo ∪ Z^hi로 연결되고 나머지 학습은 평소처럼 진행됩니다. 다중 해상도 학습은 효율적인 점수 계산을 가능하게 할 뿐만 아니라, 그 자체로 효율성 향상을 가져옵니다. B^lo는 4배 적은 토큰으로 처리되므로 거의 4배 빠른 속도를 얻습니다.
B^lo와 B^hi가 각각 배치의 절반을 차지하는 경우, B에 대한 다중 해상도 학습 비용은 전체 해상도 학습 FLOP의 64%, 시간의 67%입니다. 전체 해상도 JEST 및 다중 해상도 Flexi-JEST 구현에 대한 의사 코드는 알고리즘 2에 자세히 설명되어 있습니다.
# 설정 값 (Configuration)
cfg = ConfigDict(
n_chunks=16, # 하위 배치를 나눌 청크 수 (기본값: 16)
filter_ratio=0.8, # 필터링 비율 (기본값: 0.8, 즉 80% 데이터 버리고 20% 선택)
method="learnability", # JEST 방법 ("learnability" 또는 "easy_ref")
method="jest", # 전체 알고리즘 유형 ("jest" 또는 "flexi-jest")
softmax_score_gain=100.0, # Softmax 점수 조정 계수
loss_type="sigmoid", # 손실 함수 유형 ("sigmoid" 또는 "softmax")
)
# Sigmoid Cross Entropy Loss 함수 정의
def sigmoid_nll(params, embeds):
zimg, ztxt = embeds # 이미지 및 텍스트 임베딩 분리
logits = np.dot(zimg, ztxt.T) # 이미지-텍스트 유사도 행렬 계산
logits = logits * params["alpha"] + params["beta"] # 파라미터 적용 (스케일링 및 이동)
eye = np.eye(zimg.shape[0]) # 단위 행렬 (대각선만 1)
m1_diag1 = -np.ones_like(logits) + 2 * eye # 대각선은 1, 나머지는 -1인 행렬 생성
nll_mat = -log_sigmoid(m1_diag1 * logits) # sigmoid-contrastive loss 계산
nll = np.sum(nll_mat, axis=-1).mean() # 배치 평균 손실 값 계산
return nll, nll_mat # 평균 손실 값과 손실 행렬 반환
# Sigmoid 기반 점수 계산 함수
def get_scores_sigmoid(embeds, embeds_ref, params, params_ref):
_, nll_mod = sigmoid_nll(params, embeds) # 학습 중인 모델의 손실 행렬
_, nll_ref = sigmoid_nll(params_ref, embeds_ref) # 참조 모델의 손실 행렬
if cfg.scoring == "learnability": # learnable 점수 계산
scores = nll_mod - nll_ref
elif cfg.scoring == "easy_ref": # easy_ref 점수 계산
scores = -nll_ref
return scores * cfg.softmax_score_gain # 점수 조정 후 반환
# 주 손실 함수 (Loss Function)
def loss_fn(params, params_ref, batch):
images, texts = batch # 배치에서 이미지와 텍스트 분리
approx = True if cfg.method == "flexi-jest" else False # Flexi-JEST 사용 여부 확인
# 초기 슈퍼 배치 점수 계산 및 하위 배치 샘플링
embeds = model.forward(images, texts, params, approx=approx) # 이미지-텍스트 임베딩
embeds_ref = batch["embeds_ref"] # 미리 계산된 참조 임베딩
if cfg.loss_type == "sigmoid":
scores = get_scores_sigmoid(embeds, embeds_ref, params, params_ref) # 점수 계산
inds = jointly_sample_batch(scores, cfg.n_chunks, cfg.filter_ratio, cfg.learnability)
elif cfg.loss_type == "softmax": # softmax loss의 경우 반복 샘플링에서 점수 재계산
inds = jointly_sample_batch_softmax(embeds_ref, embeds, params_ref, params, cfg.n_chunks, cfg.filter_ratio)
images, texts = stop_grad(images[inds]), stop_grad(texts[inds]) # 선택된 하위 배치 추출 및 기울기 중단
# 공동 학습 (Co-training)을 위해 배치 분할
images_full, images_approx = images[::2], images[1::2]
texts_full, texts_approx = texts[::2], texts[1::2]
# 전체 손실 계산
embeds_full = model.forward(images_full, texts_full, params, approx=False) # 전체 해상도 임베딩
embeds_approx = model.forward(images_approx, texts_approx, params, approx=approx) # 근사 임베딩
zimg = np.concatenate([embeds_full[0], embeds_approx[0]], axis=0) # 이미지 임베딩 결합
ztxt = np.concatenate([embeds_full[1], embeds_approx[1]], axis=0) # 텍스트 임베딩 결합
if loss_type == "sigmoid": # sigmoid loss 계산
loss, _ = sigmoid_nll(params, (zimg, ztxt))
elif loss_type == "softmax": # softmax loss 계산
loss, _, _ = softmax_nll(params, (zimg, ztxt), is_sampled=None)
return loss # 최종 손실 값 반환
Training datasets.
모든 JEST 실험에서 학습자 모델은 WebLI 데이터 세트에서 학습됩니다.
구체적으로 이미지-텍스트 정렬로 대략적으로 필터링된 10억 개 규모의 영어 이미지-텍스트 쌍 하위 집합을 big_vision 코드베이스를 사용하여 학습합니다. 참조 모델을 학습하기 위해 더 작은 고품질 데이터 세트를 사용합니다. JEST/Flexi-JEST 참조 모델은 높은 텍스트 및 이미지 품질과 이미지-텍스트 정렬을 위해 필터링된 WebLI의 1억 개 규모의 강력하게 필터링된 하위 집합에서 학습되며, 이를 "WebLI-curated"라고 합니다. 또한 동일한 강력한 큐레이션 파이프라인으로 필터링된 약 6억 개의 추가 웹스크랩 이미지-텍스트 쌍을 추가하는 "WebLI-curated++"에서 학습된 참조 모델을 사용하여 데이터 큐레이션(JEST++/FlexiJEST++) 확장을 탐색합니다.
달리 명시되지 않는 한 보고되는 평균 성능은 ImageNet 0-Shot 및 10-Shot 분류와 COCO 이미지-텍스트 및 텍스트-이미지 상위 1 검색이라는 4가지 표준 벤치마크를 사용합니다.
4. Experiments
4.1 Joint example selection yields learnable batches
본 연구는 먼저 공동 예제 선택(JEST)이 학습 가능한 배치를 선택하는 데 얼마나 효과적인지 평가하는 것으로 시작합니다. 본 방법에 대한 직관을 얻기 위해 먼저 학습 가능성 행렬(즉, 배치 내 모든 예제 쌍에 대한 학습자 모델과 참조 모델 간의 손실 차이)을 시각화합니다.
JEST는 합산된 학습 가능성에 비례하여 예제의 하위 행렬을 샘플링하도록 설계되었습니다. 행렬이 강하게 비대각선(그림 2, 왼쪽)이므로 독립적인 선택은 분명히 차선책이 될 것입니다.
적은 수의 반복(배치를 N = 16개의 청크로 채우는 것에 해당)을 통해 하위 배치의 학습 가능성이 빠르게 증가하여 수천 번의 반복이 필요한 무차별 대입 Gibbs 샘플링에 의해 추출된 배치의 학습 가능성과 일치함을 알 수 있습니다(그림 2, 중간). 필터링 비율 0.5, 0.8 및 0.9에 대해 각각 크기가 65,536, 163,840 및 327,680인 슈퍼 배치에서 32,768개의 예제 하위 배치를 선택합니다. 그림 2, 오른쪽에서 하위 배치의 학습 가능성은 더 큰 필터링 비율에 따라 증가함을 알 수 있습니다. 요약하면, 본 연구의 공동 예제 선택(JEST) 알고리즘은 학습 중에 학습 가능성이 높은 배치를 선택하는 효과적이고 효율적인 수단입니다.

그림 2: Joint example selection은 더 학습 가능한 배치를 생성합니다.
왼쪽: 배치의 학습 가능성은 매우 구조화되어 있으며 비대각선입니다.
중간: 공동 예제 선택은 무차별 대입 깁스 샘플링과 동등하게 학습 가능성이 높은 하위 배치를 빠르게 발견합니다.
오른쪽: 샘플링된 배치의 학습 가능성은 더 높은 필터링 비율(즉, 더 큰 슈퍼 배치에서 선택)에 따라 향상됩니다.
4.2 Joint example selection accelerates multimodal learning
이제 JEST 알고리즘으로 선택된 학습 가능한 배치에서 학습하는 효과를 조사합니다.
모든 실행은 WebLI-curated에서 학습된 참조 모델, ViT-B/16 및 Bert-B 이미지-텍스트 듀얼 인코더, 30억 개의 학습 예제 및 sigmoid-contrastive 손실을 사용합니다.
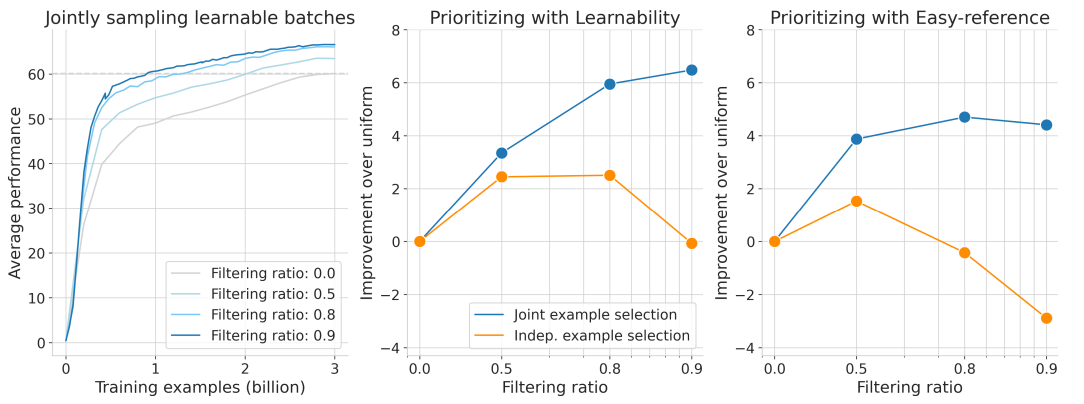
그림 3: Joint example selection 은 다중 모드 학습을 가속화합니다.
왼쪽: 2배, 5배 또는 10배 더 큰 슈퍼 배치에서 선택된 가장 학습 가능한 하위 배치에 대한 학습은 다중 모드 학습을 크게 가속화합니다.
중간: 학습 가능한 배치를 공동으로 우선순위를 지정하면 개별 예제를 우선순위를 지정하는 것보다 훨씬 더 나은 결과를 얻을 수 있습니다.
오른쪽: 공동 예제 선택은 쉬운 참조 우선순위 지정도 향상시키지만, 학습 가능성은 더 공격적인 필터링으로 더 잘 확장됩니다.
그림 3 (왼쪽)은 학습 과정에서 여러 다운스트림 작업(ImageNet 0-Shot/10-Shot 정확도 및 COCO 이미지-텍스트/텍스트-이미지 검색)에 대한 평균 성능을 보여줍니다.
필터링 비율을 각각 50%, 80%, 90%로 사용할 때 JEST는 학습을 크게 가속화하여 20억, 10억, 6억 7천만 개의 학습 예제만으로 3B-uniform 기준선의 최종 성능에 도달합니다.
더 큰 필터링 비율에서는 더 큰 배치 크기에서 관찰되는 것과 유사한 학습 불안정성이 관찰되어, Adam optimizer(β2 = 0.95)를 안정화하기 위한 수정이 필요하며, JEST를 사용한 데이터 큐레이션은 유효 배치 크기를 늘리는 것으로 생각할 수 있음을 시사합니다 (부록 A.2, A.3). 최종 성능 측면에서 JEST는 90%의 데이터를 필터링할 때 최대 6%의 상당한 이득을 제공합니다 (그림 3, 중간, 파란색 곡선). 특히, 이러한 스케일링 동작은 개별 예제의 독립적인 우선순위 지정에 기반한 이전 선택 방법에는 없는 것입니다 (그림 3, 중간, 주황색 곡선). 마지막으로 JEST가 학습 가능성 이외의 다른 우선순위 지정 기준도 개선하는지 평가합니다.
그림 3, 오른쪽은 다양한 필터링 비율에 대한 easy-reference 우선순위 지정 모델의 성능을 보여줍니다. 학습 가능성 기반 우선순위 지정과 일관되게 JEST는 독립적인 예제 선택보다 훨씬 뛰어난 성능을 보이며, 특히 높은 필터링 비율(독립적인 예제 선택은 성능 저하로 이어짐)에서 그렇습니다. 가장 높은 손실을 가진 데이터를 우선적으로 처리하면 더 작은 이득을 얻었고 더 많은 데이터를 필터링할수록 더 빨리 성능이 저하됩니다 (그림 10). 학습 가능성 기반 JEST가 최상의 스케일링 동작을 나타내므로 이후 실험에서는 이 기준을 유지합니다.

그림 10: 학습자에게 어려운 데이터 우선순위 지정.
easy-reference 및 learnability 점수(그림 2)와 비교할 때, 높은 학습자 손실을 가진 데이터를 우선적으로 처리하면 50% 필터링 비율에서 약간의 이득을 얻지만, 더 많은 양의 데이터를 필터링할수록 빠르게 성능이 저하됩니다. 공동 예제 선택은 더 큰 필터링 비율에서 이 효과를 악화시키는데, 이는 hard-learner 우선순위 지정이 데이터의 노이즈 샘플링을 우선시한다는 해석과 일치합니다.
Synergies between multi-resolution training and online batch selection
공동 예제 선택을 통한 학습 가능성 점수는 각 배치에서 더 많은 부분을 필터링할수록 더 효율적이 됩니다. 그러나 점수 계산 비용으로 인해 상당한 오버헤드가 발생합니다. 슈퍼 배치의 80%를 필터링하면 IID 학습보다 반복당 FLOP가 4배 더 많아지며, 참조 모델 점수를 캐싱하면 2.3배 더 많아집니다 (부록 A.4). JEST는 학습 반복 측면에서 훨씬 더 효율적이지만(이하 '학습 효율성'), 추가 점수 FLOP는 IID 기준선에 비해 계산 효율성을 감소시킵니다(그림 1, 왼쪽 대 오른쪽). 따라서 본 연구에서는 다중 해상도 학습과 저해상도 점수 계산을 사용하여 총 오버헤드를 기준선 대비 10%까지만 줄이는 계산 효율적인 변형 Flexi-JEST를 조사했습니다(그림 4, 왼쪽, A.4절 참조). 이러한 근사화가 성능에 미치는 영향은 무엇일까요?
예상할 수 있듯이 Flexi-JEST의 반복당 성능은 JEST에 비해 감소하지만 IID에 비해 여전히 상당한 속도 향상을 제공합니다(그림 1, 왼쪽, 그림 4, 중간). 그러나 총 FLOP 감소를 고려할 때 반복당 성능 감소는 더 유리합니다. 최고의 Flexi-JEST 모델은 40B Siglip 실행과 동일한 평균 성능을 9.9배 적은 FLOP로 생성하며, 전체 해상도 JEST보다 2배 적습니다(그림 1, 오른쪽, 그림 4, 중간). Flexi-JEST에서 효율적인 점수 계산과 다중 해상도 학습의 상대적인 기여도는 무엇일까요?
선택된 배치의 전체 및 낮은 해상도에서 학습된 부분(즉, Bhi 및 Blo의 상대적 크기, 방법 참조)을 변경하는 ablation study를 수행했습니다. 이 경우 반복당 FLOP가 감소하므로 근사 모델에 더 많은 데이터를 보낼수록 학습 반복 횟수를 늘려 학습자가 동일한 FLOP를 사용하도록 합니다(자세한 내용은 A.7절 참조). 그림 4(오른쪽)는 근사 모델에 더 많은 데이터를 보낼수록 IID 기준 성능이 증가함을 보여주며, 이는 근사 학습의 FLOP 효율성에 대한 증가하는 연구 문헌과 일치합니다 [4, 29, 13, 40]. 그럼에도 불구하고 Flexi-JEST는 저해상도 모델이 학습자와 정렬될 수 있을 만큼 충분한 데이터(예: ≥ 25% 데이터)로 학습하는 한 다중 해상도 기준선보다 훨씬 뛰어난 성능을 발휘합니다.
이러한 실험은 다중 해상도 학습과 공동 예제 선택 간의 시너지 효과를 보여줍니다. 전자는 후자를 가속화하기 위한 효율적이고 정확한 점수화 기능을 제공합니다. 또한 결과는 데이터 큐레이션 전략의 Pareto front를 가리킵니다. 계산 비용을 희생하더라도 학습 속도 또는 학습 효율성을 극대화하는 것이 바람직한 경우, 전체 해상도 JEST 방법은 유사한 IID 학습 실행에 비해 최대 13배 속도 향상을 가져옵니다.
학습 효율성을 희생하더라도 FLOP를 최소화해야 하는 경우 Flexi-JEST가 가장 유리한 균형점을 제공합니다. 다음 배치 점수는 학습과 병행하여 별도의 장치에서 구현할 수 있어 추가적인 실제 시간을 더욱 단축할 수 있습니다.
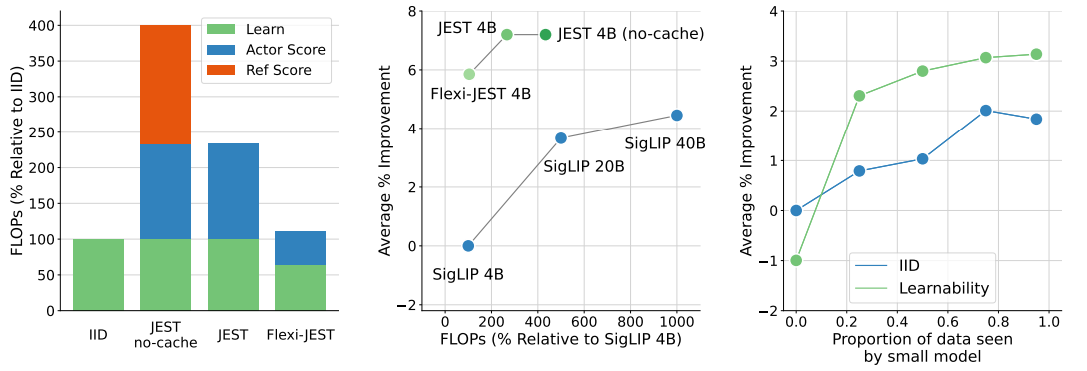
그림 4: 효율적인 점수 계산 및 다중 해상도 학습.
왼쪽: 학습자 및 참조 모델을 사용하여 대규모 슈퍼 배치 점수를 매길 때 JEST는 반복당 큰 계산 비용이 발생합니다. 데이터 세트에 고정 참조 모델 점수를 캐싱하면 이 오버헤드를 절반으로 줄일 수 있습니다. 효율적인 점수 계산 및 다중 해상도 학습은 이를 표준 IID 학습과 비슷한 수준으로 더욱 줄입니다.
중간: Flexi-JEST는 표준 IID 학습에 비해 JEST의 총 FLOP 효율성을 향상시킵니다.
오른쪽: 다중 해상도 학습은 표준 IID 학습보다 Flexi-JEST를 더 많이 향상시킵니다. 다중 해상도 학습 없이(가장 왼쪽 지점) Flexi-JEST는 IID 기준선보다 성능이 떨어지지만(학습되지 않은 근사 모델 때문), 소량의 공동 학습(25%)만으로도 빠르게 개선됩니다.
Joint examples selection enables strong data-quality bootstrapping
학습 가능성 기반 점수화의 핵심은 우리가 선택한 작고 큐레이션된 데이터 세트에서 학습된 참조 모델입니다. 품질 대 수량의 균형을 맞추는 다양한 큐레이션 전략에 따라 JEST 성능은 어떻게 달라질까요? 또한 JEST 학습의 개선이 참조 모델의 성능과 상관관계가 있습니까, 아니면 이러한 지표가 분리되어 있습니까?
Understanding quality vs. quantity trade-offs.
이미지-텍스트 정렬(ITA) 필터를 사용한 약한(10억 개 규모) 큐레이션, ITA 필터 또는 텍스트 품질(TQ) 필터를 사용한 중간(3억 개 규모) 큐레이션, TQ, ITA 및 추가 이미지 품질(미적) 필터 조합을 사용한 강력한(1억 개 규모) 큐레이션의 세 가지 큐레이션 척도를 탐색합니다.
본 연구에서는 이 강력하게 큐레이션된 하위 집합을 "WebLI-curated"라고 합니다. 이러한 4개의 WebLI 하위 집합에 대해 각각 10 epoch 동안 표준 SigLIP 인코더를 학습시키고, 전체 WebLI 데이터 세트에 대한 JEST 학습을 위한 참조 모델로 사용합니다. 모든 큐레이션 방법에서 참조 모델 성능과 JEST 성능은 분리되어 있는 것으로 보이며(또는 심지어 음의 상관관계를 보입니다. 그림 5, 왼쪽), 이는 고정 데이터 큐레이션에 대한 이전 연구 결과와 일치합니다. 큐레이션을 늘리고(데이터 세트 크기를 줄이고) 모델을 약화시키면 JEST 사전 학습의 참조 모델로 사용할 때 반대 효과가 나타납니다. 강력하게 큐레이션된 참조 모델을 사용하는 JEST는 2.7% 향상되고, 중간 정도는 1.5% 향상되고, 약하게는 0.3% 향상됩니다.
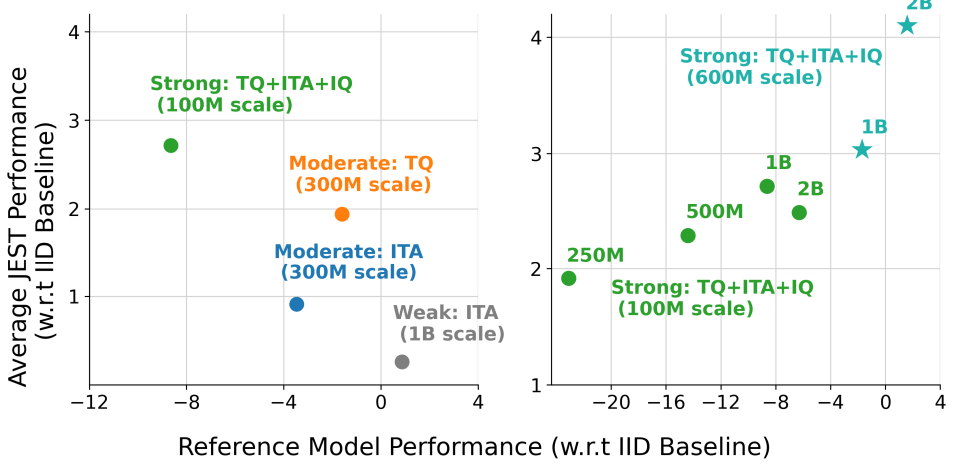
그림 5: 강력한 데이터 큐레이션 확장은 JEST 성능을 향상시킵니다.
왼쪽: 이미지-텍스트 정렬(ITA)을 사용한 '약한' 큐레이션, ITA 또는 텍스트 품질(TQ)을 사용한 '중간' 큐레이션, TQ, ITA 및 추가 이미지 품질(IQ) 조합을 사용한 '강력한' 큐레이션의 4가지 큐레이션 유형에 대해 JEST 성능 대 참조 모델 성능(균일 기준선 대비)을 비교합니다.
오른쪽: 최상의 참조 데이터 세트(TQ+ITA+IQ)를 사용하고 참조 사전 학습 중에 본 예제 수를 변경하여 JEST 대 참조 성능을 평가합니다. 추가 참조 학습과 JEST 성능 간에는 강력한 상관관계가 있으며 10억 개 예제를 본 후에는 포화 상태가 됩니다. 강력한 데이터 큐레이션을 6억 개 데이터 세트로 확장하면 이 포화 상태가 해제되어 10억 및 20억 개 참조 학습에 대해 참조 모델 및 JEST 성능이 모두 향상됩니다.
Scaling data curation.
본 연구진은 참조 모델 성능과 JEST 성능 간의 일반적인 분리는 단순히 데이터 큐레이션으로 인한 데이터 세트 크기 제한으로 설명될 수 있다고 가정했습니다. 이 효과를 이해하기 위해 WebLI-curated에서 총 예제 수(2억 5천만~30억 개)를 다양하게 변경하면서 5개의 참조 모델을 학습시켰습니다. 이러한 맥락에서 그림 5(오른쪽)는 개선된 참조 모델과 더 나은 JEST 사전 학습 간의 놀라운 상관관계를 보여줍니다. 이는 "분리" 현상이 주로 큐레이션 후 데이터 세트 크기 감소로 인한 참조 모델의 포화 때문일 수 있음을 시사합니다.
그림 5(오른쪽)의 상관관계는 데이터 세트가 포화 상태일 때, 즉 10 epoch 또는 10억 개 예제를 본 후에 무너지기 시작합니다. 이러한 결과는 JEST가 참조 데이터 세트의 데이터 큐레이션 확장으로 추가적인 이점을 얻을 수 있음을 시사합니다. 이를 테스트하기 위해 확장된 이미지-텍스트 쌍 세트에서 가져온 약 6억 개의 예제로 WebLI-curated를 확장했습니다. 그러나 이 규모에서는 WebLI-curated의 엄격한 TQ/ITA 기준을 충족하기가 어렵습니다. 따라서 원래 ITA 임계값을 충족하지 않는 모든 이미지-텍스트 쌍에 대해 PaLI 모델 제품군을 기반으로 고품질 합성 캡션을 사용하여 이미지에 다시 캡션을 지정했습니다. 이 데이터 세트를 "WebLI-curated++"라고 합니다.
이 확장된 데이터 세트를 사용하면 참조 모델 및 JEST 성능(그림 5, 오른쪽: ⋆)이 모두 크게 향상됨에 따라 "WebLI-curated"에 대한 20억 개 포화점을 깰 수 있습니다. 따라서 최고의 모델인 JEST++ 및 FlexiJEST++에 WebLI-curated++를 사용합니다. WebLI-curated++를 사용하여 데이터 큐레이션을 확장하면 참조 모델 성능이 크게 향상되므로 원래 WebLI 데이터 세트에 대한 사전 학습이 전혀 필요한지 질문했습니다. 그러나 데이터 세트에서 참조 모델의 성능을 평가할 때 매우 불균형하다는 것을 알 수 있습니다.
2개의 다운스트림 작업에서는 WebLI 사전 학습보다 성능이 뛰어나지만 다른 6개 작업에서는 성능이 크게 떨어지며 평균적으로도 마찬가지입니다(표 5). 반대로 WebLI에서 JEST++ 사전 학습을 수행하면 8개 벤치마크 중 6개뿐만 아니라 평균적으로 기준선을 능가하는 일반 기초 모델이 생성됩니다.

표 1: 이전 연구와의 비교. FLOP %는 SigLIP 대비 측정됩니다. Mean은 모든 지표에 대한 평균 성능을 나타냅니다. "Per Iter."는 반복당 FLOP를 나타냅니다.
Comparison to prior art
이제 400억 개의 예제에 대해 학습된 최첨단 SigLIP 모델과 최근 강력한 CLIP 변형을 포함하여 이전 연구와 비교합니다. 표 1은 학습 효율성이 가장 높은 모델인 JEST++가 10배 적은 반복 횟수와 4배 적은 계산량을 사용하면서 ImageNet과 COCO 모두에서 새로운 최첨단 기술을 달성했음을 보여줍니다. 특히 COCO에서 JEST++는 이전 최첨단 기술을 5% 이상 향상시킵니다. 가장 계산 효율적인 모델인 Flexi-JEST++는 평균적으로 이전 SoTA를 능가하며 9배 적은 계산량을 사용합니다. JEST를 더 오래 학습하면 이러한 이득이 더욱 커집니다(부록 표 4 참조).
본 연구의 결과는 모델 크기에 따라 우아하게 확장됩니다. 동일한 WebLI-curated++ 데이터 세트에서 학습된 ViT-L 학습자 및 ViT-L 참조 모델로 학습할 때 JEST++는 계속해서 강력하게 가속화된 학습을 제공하여 단 40억 개의 예제만으로 SigLIP ViT-L 40B 기준선과 일치합니다(표 1).
마지막으로 공개적으로 사용 가능한 LAION-2B 데이터 세트에 대해 JEST++를 사전 학습에 적용합니다. 안전하지 않은 이미지-텍스트 쌍을 제거하는 표준 관행을 따르지만 데이터 세트를 사전 필터링하지는 않습니다. JEST++는 이전 최첨단 기술보다 4배 적은 학습 예제를 사용했음에도 오프라인 데이터 큐레이션을 위한 이전 방법을 훨씬 능가합니다(표 2). 이 학습 예산으로 SigLIP 사전 학습은 모든 방법보다 성능이 크게 떨어지므로 JEST의 이점이 더욱 강조됩니다.

표 2: LAION 사전 학습과의 비교. JEST++는 훨씬 적은 학습 반복 횟수를 요구하면서도 이전 연구 결과를 크게 능가합니다. COCO 성능은 이미지-텍스트 및 텍스트-이미지 검색의 평균을 나타냅니다.
Simplifying data curation
본 연구의 사전 학습 실험에 사용된 WebLI 데이터 세트는 이미 높은 이미지-텍스트 정렬을 위해 필터링되었습니다. 표 3에서 볼 수 있듯이 이러한 오프라인 큐레이션은 강력한 IID 학습 성능에 중요합니다. 그러나 JEST++의 경우 필터링되지 않은 WebLI에서 학습할 때 성능이 저하되지 않으므로 이러한 사전 필터링은 불필요하며 기본 데이터 세트의 필요성을 줄여줍니다.

표 3: 데이터 큐레이션 단순화. 모든 모델은 40억 개의 예제를 학습했습니다. JEST++의 성능은 원시(큐레이션되지 않은) 데이터와 필터링된 데이터에 대해 사전 학습했을 때 거의 동일합니다. 색상 그라데이션은 필터링된 WebLI에서 IID 학습에 상대적으로 측정되었습니다.
Discussion
본 연구에서는 JEST라는 방법을 제안하여 가장 학습 가능성이 높은 데이터 배치를 공동으로 선택함으로써 대규모 다중 모드 학습을 크게 가속화하여 이전 최첨단 기술을 최대 10배 적은 FLOP 및 13배 적은 예제로 능가했습니다.
특히, 본 연구의 실험은 작은 큐레이션된 데이터 세트를 사용하여 훨씬 더 크고 큐레이션되지 않은 데이터 세트에 대한 학습을 안내하는 "데이터 품질 부트스트래핑"의 강력한 잠재력을 보여줍니다. 최근 연구에 따르면 다운스트림 학습에 대한 지식 없이 정적 데이터 세트 필터링을 수행하면 궁극적으로 성능이 제한될 수 있습니다.
본 연구의 결과는 온라인에서 구성해야 하는 유용한 배치가 개별적으로 선택된 예제를 넘어 사전 학습 효율성을 향상시킨다는 것을 보여줍니다. 따라서 이러한 연구 결과는 일반적인 기본 데이터 세트보다 더 일반적이고 효과적인 대안으로 기본 분포를 옹호합니다. 이는 easy-reference JEST를 사용하는 사전 점수가 매겨진 데이터 세트를 통해서든, 또는 학습 가능성 JEST를 사용하여 모델의 요구 사항에 맞춰 동적으로 조정하든 관계없습니다.
제한 사항. 본 연구의 방법은 표준 다운스트림 작업의 다중 모드 학습을 가속화했지만 훨씬 더 큰 큐레이션되지 않은 데이터 내에서 우선순위를 지정할 분포를 지정하는 작고 잘 큐레이션된 참조 데이터 세트에 의존했습니다. 따라서 향후 관심 있는 다운스트림 작업 세트에서 참조 데이터 세트의 추론을 탐색하는 연구가 필요합니다.