VLM : 논문리뷰 : Is A Picture Worth A Thousand Words? Delving IntoSpatial Reasoning for Vision Language Models
Abstract
대규모 언어 모델(LLM)과 시각-언어 모델(VLM)은 다양한 작업과 영역에서 괄목할 만한 성능을 보여주었습니다. 하지만 이러한 가능성에도 불구하고, 인간 인지의 핵심 요소인 공간 이해 및 추론 능력은 아직 충분히 탐구되지 않았습니다.
본 연구에서는 관계 이해, 탐색, 계산 등 공간 추론의 다양한 측면을 다루는 새로운 벤치마크를 개발했습니다. 그리고 경쟁력 있는 언어 모델과 시각-언어 모델을 포괄적으로 평가했습니다.
본 연구 결과는 기존 연구에서 간과되었던 몇 가지 반직관적인 통찰을 제시합니다.
(1) 공간 추론은 경쟁 모델들이 무작위 추측보다 뒤처질 수 있는 상당한 어려움을 제기합니다.
(2) 추가적인 시각적 입력에도 불구하고, VLM은 종종 LLM보다 성능이 떨어집니다.
(3) 텍스트 및 시각 정보가 모두 제공될 때, 멀티모달 언어 모델은 충분한 텍스트 단서가 제공되면 시각 정보에 대한 의존도가 낮아집니다. 또한, 시각과 텍스트 간의 중복성을 활용하면 모델 성능을 크게 향상시킬 수 있음을 보여줍니다.
본 연구는 공간 지능을 향상시키고 인간 지능과의 격차를 더욱 좁히기 위한 멀티모달 모델 개발에 도움이 될 것으로 기대합니다.
Related work
Large language models.
최근 몇 년 동안 트랜스포머 아키텍처를 기반으로 하는 생성적 대규모 언어 모델(LLM)이 성공을 거두었습니다. BERT , OPT, PaLM , Gemma , Mistral , GPT-3 , GPT-4 , Claude3 , Grok-1 , Llama , Llama2 , Llama3 등과 같은 LLM은 컨텍스트 내 학습, 구성 능력 및 적응 능력과 같은 새로운 능력으로 인해 세상을 크게 변화시켰습니다. LLM은 금융 , 생물 정보학 , 법률 , 교육 , 코딩 , 심지어 최고 AI 컨퍼런스 리뷰 와 같은 창의적인 글쓰기 등 인간 활동에 참여해 왔습니다.
Large vision-language models and multi-modality.
LLM의 성공은 ViT , Beit , CLIP , MAE , Swin 및 DiT 과 같이 컴퓨터 비전 커뮤니티 내에서 트랜스포머 아키텍처 채택을 촉진했습니다. 강력한 LLM의 기능을 기반으로 구축된 Flamingo , LLaMA-Adapter , LLava , stable-diffusion , BLIP , MiniGPT-4 , Qwen , Gemini , MM1 과 같은 다중 모드 언어 모델(MLLM)은 해결 가능한 작업 범위를 크게 확장했습니다. 이러한 모델은 다양한 형태의 입력을 능숙하게 처리하며 수학적 추론 , 시각적 질문 답변 , 이미지-텍스트 검색 , 시각적 추론 등 광범위한 작업에서 놀라운 성능을 보여주었습니다.
Spatial understanding and reasoning.
공간 추론은 공간 관계를 이해하고 조작하는 것을 수반하며, 이는 시각적 접지 보다 훨씬 더 어려운 작업입니다. GPT-4 및 Claude3 와 같은 LLM에 대한 자연어 처리, 평가 및 벤치마크의 진행 상황은 주로 텍스트 또는 관계 추론에 중점을 두었습니다.
이러한 초점은 종종 공간 추론 작업의 복잡한 특성을 간과합니다. 특히, 최근 연구에서는 다양한 작업에 대한 철저한 평가를 수행했습니다. 그러나 그들은 공간 추론 능력에 대한 탐구가 부족함을 보여주며 현재 벤치마크에서 이 복잡한 인지 기술을 평가하는 데 있어 격차를 강조합니다. 특히, Zhang et al. 는 MLLM이 시각적 다이어그램보다 텍스트 단서를 활용하여 수학 문제를 해결하는 데 주로 초점을 맞추고 수학 문제에만 초점을 맞춘다고 제안합니다.
Yamada et al. 은 간단한 탐색 작업을 설계하고 LLM이 공간 구조의 특정 측면을 암묵적으로 포착하는 것처럼 보이지만 개선의 여지가 남아 있는 반면, 우리의 벤치마크는 단순한 기하학적 지도를 기반으로 하는 탐색 작업보다 더 복잡합니다. Fu et al. 은 공간 추론과 관련된 제한적인 탐구와 함께 과학 및 게임에 대한 벤치마크를 제안하는 반면, 우리는 심층 분석과 함께 다양한 공간 추론 작업에 전념합니다.
Dataset and Task Construction
3.1 dataset setup
LLM과 VLM의 공간 추론 능력을 평가하기 위해 공간 관계, 탐색, 위치 이해 및 계산을 포함한 세 가지 다양한 작업을 구성했습니다. 모달리티의 영향을 체계적으로 연구하기 위해 각 작업에 대해 세 가지 유형의 입력 프롬프트를 설계했습니다.
- 텍스트 전용: 입력은 순수한 텍스트이며 사람이 질문에 답하는 데 필요한 모든 정보를 포함합니다.
- 시각 전용: 입력은 이미지로만 구성되며 사람이 쉽게 답변할 수 있을 만큼 충분한 세부 정보를 제공합니다. 이 형식은 문헌에서 시각적 질문 답변(VQA)이라고도 합니다.
- 시각-텍스트: 입력에는 이미지와 자세한 설명이 포함된 텍스트 표현이 모두 포함되어 두 가지 형태의 정보가 중복됩니다.
동일한 질문 세트에 대해 텍스트 전용 입력을 사용하는 언어 모델과 텍스트 전용, 시각 전용 및 시각-텍스트 입력을 사용하는 다중 모드 언어 모델을 평가합니다.
이 연구에서는 합성 데이터를 선택합니다. 합성 데이터는 몇 가지 설득력 있는 장점을 제공합니다.
- 데이터 누출 방지: 대규모 언어 모델은 웹 규모 데이터에 대해 사전 훈련되므로 테스트 데이터가 훈련 중에 보이지 않았는지 확인하는 것이 중요합니다.
- 구성 가능성: 완전히 구성 가능하므로 제어된 실험을 허용하고 추가 작업으로 확장할 수 있습니다.
- 확장성: 테스트 샘플 수를 쉽게 조정할 수 있어 결과의 통계적 유의성을 높일 수 있습니다.
Spatial-Map
지도상의 객체 간 공간 관계를 이해하는 것은 인간 인지 능력의 기본적인 측면입니다.
이러한 환경을 시뮬레이션하기 위해 K개의 객체를 가진 Spatial-Map이라는 지도와 유사한 데이터 세트를 만듭니다.
여기서 K는 구성 가능합니다. 각 객체에는 Unicorn Umbrellas 및 Gale Gifts와 같은 고유한 위치 이름이 연결됩니다. 모달리티의 영향을 연구하기 위해 각 입력의 텍스트 표현은 Brews Brothers Pub is to the Southeast of Whale's Watches와 같은 쌍별 관계로 구성됩니다. K = 6인 예제가 그림 1에 텍스트 전용, 시각 전용 및 시각 텍스트 입력과 함께 표시됩니다. 이러한 질문에는 두 위치 간의 공간 관계와 특정 공간 기준을 충족하는 객체 수를 묻는 질문이 포함됩니다.

그림 1: 여러 위치가 있는 지도를 시뮬레이션하는 Spatial-Map 작업을 보여줍니다. 모달리티의 영향을 조사하기 위해 텍스트 전용, 시각 전용 및 시각-텍스트의 세 가지 입력 형식을 고려합니다. 동일한 질문 세트에 대해 언어 모델(텍스트 전용 입력)과 다중 모드 언어 모델(시각 전용 및 시각-텍스트 입력)을 평가합니다.
Maze-Nav
복잡한 공간을 탐색하는 능력은 지능형 시스템에게 필수적입니다. 이러한 능력을 평가하기 위해 Maze-Nav라는 미로와 유사한 데이터 세트를 개발했습니다. 시각적으로 각 샘플은 색상 블록으로 표현될 수 있으며, 여기서 다른 색상은 서로 다른 요소를 나타냅니다. 녹색 블록은 시작점(S)을 표시하고, 빨간색 블록은 출구(E)를 나타내며, 검은색 블록은 통과할 수 없는 벽을 나타내고, 흰색 블록은 탐색 가능한 경로를 나타내며, 파란색 블록은 S에서 E까지의 경로를 추적합니다.
목표는 S에서 E까지 파란색 경로를 따라 이동하는 것이며, 4가지 기본 방향(위, 아래, 왼쪽, 오른쪽)으로 이동할 수 있습니다. 또는 각 입력을 ASCII 코드를 사용하여 텍스트 형식으로 묘사할 수 있습니다. 그림 2에는 텍스트 전용, 시각 전용 및 시각-텍스트 입력의 예가 나와 있습니다. 이 작업은 오픈 소스 라이브러리 [24]를 기반으로 구성됩니다. 질문에는 S에서 E까지의 회전 횟수 세기와 S와 E 간의 공간 관계 결정이 포함됩니다. 이러한 질문은 인간에게는 쉽지만 섹션 4에서 볼 수 있듯이 최신 멀티모달 언어 모델에는 상당한 어려움을 제시합니다.

그림 2: 미로-탐색(Maze-Nav) 작업의 예시입니다. 이 작업은 시작점(S)에서 출구(E)까지 탐색하는 모델의 능력을 평가합니다. 텍스트 전용, 시각 전용, 시각-텍스트의 세 가지 입력 형식을 고려합니다. 동일한 질문 세트에 대해 언어 모델(텍스트 전용 입력)과 다중 모드 언어 모델(시각 전용 및 시각-텍스트 입력)을 평가합니다.
Spatial-Grid
구조화된 환경 내에서의 공간 이해를 조사하기 위해, 객체들이 임의로 배치되는 Spatial-Map과 대비되는 격자 형태의 데이터 세트인 Spatial-Grid를 소개합니다.
시각적으로 각 입력은 셀 격자로 구성되며 각 셀에는 이미지(예: 토끼)가 포함됩니다. 예시는 그림 3에 나와 있습니다. 또는 이 격자는 순수한 텍스트 형식으로도 표현할 수 있습니다.
예를 들어 첫 번째 행은 코끼리 | 고양이 | 기린 | 코끼리 | 고양이.
평가는 특정 객체(예: 토끼) 세기 및 격자의 특정 좌표(예: 첫 번째 행, 두 번째 열)에 있는 객체 식별과 같은 작업에 중점을 둡니다.

그림 3: 엄격한 격자 구조에서 모델의 공간 추론 능력을 평가하는 Spatial-Grid 작업의 예시입니다. 텍스트 전용, 시각 전용 및 시각-텍스트의 세 가지 입력 형식을 고려합니다. 동일한 질문 세트에 대해 언어 모델(텍스트 전용 입력)과 다중 모드 언어 모델(시각 전용 및 시각-텍스트 입력)을 평가합니다.
3.2 Models
다양한 규모의 경쟁력 있는 오픈 소스 언어 모델을 고려했습니다. 여기에는 Phi2-2.7B , LLaMA 계열 모델(LLaMA-2-7B, LLaMA-2-13B, LLaMA3-8B) , Mistral-7B , Vicuna 계열(Vicuna-7B-1.5 및 Vicuna-13B-1.5) , Nous-Hermes-2-Yi-34B가 포함됩니다.
다중 모드 언어 모델의 경우 Bunny 계열(Bunny-Phi2-SigLIP, Bunny-Phi-1.5-SigLIP, Bunny-Phi-2-EVA, Bunny-Phi-1.5-EVA) , CogVLM , CogAgent , InstructBLIP 계열(InstructBLIP-Vicuna-7B 및 InstructBLIP-Vicuna-13B) , LLaVA 계열(LLaVA-1.6-Mistral-7B, LLaVA-1.6-Vicuna-7B, LLaVA-1.6-Vicuna-13B, LLaVA-1.6-34B) 를 고려했습니다.
또한 Open AI의 GPT-4V, GPT-4O, GPT-4, Google Gemini Pro 1.0 및 Anthropic Claude 3 Opus와 같은 독점 모델도 평가했습니다.
평가. 기본적으로 각 작업의 각 샘플에는 3개의 질문(Q1~Q3이라고 함)이 연결되어 있습니다. 각 질문에는 네 가지 옵션이 포함되어 있으므로 정확도를 주요 평가 지표로 사용합니다. 모든 질문 끝에는 동일한 사용자 프롬프트가 추가됩니다.
먼저 한 문장으로 간결하게 답변하십시오. 그런 다음 자세하고 단계별 설명을 통해 답변의 근거를 자세히 설명하십시오.
각 모델에 대해 argmax(결정적 디코딩) 및 top-p(비결정적 디코딩)와 같은 기본 구성 및 디코딩 전략을 채택합니다. 비결정적 디코딩의 경우, 오픈 소스 모델에 대해서는 결과를 3번의 독립적인 실행에 대해 평균을 냈습니다. 독점 모델의 경우, 제한된 사용 가능성과 증가된 계산 시간 및 비용으로 인해 한 번만 실행했습니다.
Main Results and Analysis
Spatial reasoning remains surprisingly challenging
공간 추론은 여전히 놀라울 정도로 어려운 과제입니다. Spatial-Map, Maze-Nav, Spatial-Grid에 대한 오픈 소스 모델의 평가 결과는 그림 4에 나와 있습니다. 각 작업에 대해 보고된 정확도는 모든 질문에 대해 평균화됩니다. 시각-언어 모델의 경우, 시각적 질문 답변(VQA)에서 일반적으로 사용되는 Vision-only 입력 형식을 선택했습니다. 각 그림에는 빨간색 점선을 사용하여 무작위 추측으로 답변할 경우 예상되는 정확도를 나타냅니다.
본 연구 결과는 다음과 같은 몇 가지 주목할 만한 통찰력을 보여줍니다.
(1) 시각 전용 입력: 사람은 이러한 작업을 쉽게 처리하지만 대부분의 경쟁력 있는 멀티모달 언어 모델은 무작위 추측과 비슷하거나 거의 넘지 않는 수준의 성능을 보입니다.
(2) 텍스트 전용 입력: 텍스트 표현에는 필수적인 공간 정보가 포함되어 있습니다. 그러나 이러한 입력 형식은 일반적으로 경쟁력 있는 언어 모델의 공간 추론 능력을 향상시키지 않습니다. Llama-3가 71.9%의 정확도를 달성하고 Mistral-7B-Instruct가 62.1%를 달성하는 Spatial-Grid 작업에서 예외가 발생하며, 둘 다 무작위 추측을 훨씬 능가합니다. 이러한 성공에도 불구하고 이러한 모델의 성능은 여전히 인간 수준에 비해 크게 뒤떨어집니다.
이러한 결과는 공간 이해 및 추론에 맞는 기술을 추가로 개발해야 할 필요성을 강조합니다.

그림 4: 공간 추론 과제 성능 개요. 모든 질문에 대한 평균 정확도를 보고합니다. 시각-언어 모델의 경우 VQA(시각 전용) 형식을 고려합니다.
빨간색 점선은 무작위 추측의 예상 정확도를 나타냅니다. Spatial-Map 및 Maze-Nav 작업의 경우 일부 모델만 무작위 추측보다 훨씬 뛰어난 성능을 보입니다.
The impact of input modality
입력 형태의 영향을 조사하기 위해, 동일한 언어 백본을 가진 대규모 언어 모델(LLM)과 시각-언어 모델(VLM)의 성능을 비교합니다. 시각-언어 모델의 경우 VQA(시각 전용) 형식을 고려합니다.
결과는 그림 5에 나와 있습니다. 거미 플롯의 각 꼭짓점은 (VLM, LLM) 쌍의 평균 정확도를 나타냅니다. Spatial-Map 및 Spatial-Grid에서 대부분의 VLM은 추가적인 시각 인코더가 있음에도 불구하고 LLM 대응 모델에 비해 성능이 더 낮다는 것을 알 수 있습니다. 예를 들어 Spatial-Grid에서 Mistral-7B는 평균 62.1%의 정확도를 달성하는 반면 LLaVA-v1.6-Mistral-7B는 47.1%(15% ↓)의 정확도만 나타냅니다. 자세한 결과는 부록 D에서 확인할 수 있습니다.

그림 5: 공간 추론 작업에서 TQA(텍스트 질의응답) 대 VQA(시각 질의응답) 비교. 거미 플롯의 각 꼭짓점은 동일한 언어 백본을 가진 (VLM, LLM) 쌍의 평균 정확도를 나타냅니다. 즉, LLM 대 해당 LLM을 추가로 미세 조정한 VLM입니다. VLM은 빨간색으로, LLM은 파란색으로 표시됩니다. VLM은 LLM 대응 모델에 비해 성능이 거의 향상되지 않는 것을 볼 수 있습니다.
Delving Into Spatial Reasoning for Vision-Language Models
5.1 Seeing Without Understanding: The Blindness of Multimodal Language Models
멀티모달 언어 모델의 맹점
멀티모달 언어 모델이 시각 정보를 어떻게 처리하는지 더 잘 이해하기 위해 VTQA(시각-텍스트 입력) 설정에서 일련의 통제된 실험을 수행합니다. 각 샘플에 대해 원본 이미지 입력(텍스트 설명과 일치하는 이미지)을 다음 중 하나로 교체합니다.
- 이미지 없음: 이미지 입력 없이 텍스트 입력만 유지합니다.
- 노이즈 이미지: 작업과 관련 없는 가우시안 노이즈 이미지로 대체합니다.
- 임의 이미지: 데이터셋에서 텍스트 설명과 일치하지 않는 임의의 이미지로 대체합니다(그림 6 참조)

그림 6: 그림 2의 예시에 대한 임의 이미지 및 노이즈 이미지 설명.
VLMs exhibit improved performance when visual input is absent
시각적 입력이 없을 때 VLM의 성능이 향상되는 현상이 나타났습니다.
원본 이미지를 완전히 제거하고 텍스트 설명에만 의존하는 실험을 진행했습니다. 결과는 그림 7에 나와 있습니다. 각 작업에 대해 모든 질문에 대한 평균 정확도를 보고했습니다. 놀랍게도 시각적 입력이 없을 때 다양한 VLM 아키텍처에서 더 나은 성능을 보였습니다. 예를 들어 Spatial-Grid 작업에서 LLaVA-1.6-34B는 원본 이미지가 있을 때보다 이미지가 없을 때 성능이 20.1% 향상되었습니다.
이러한 관찰은 텍스트 정보만으로 질문에 답할 수 있을 때 추가적인 시각적 입력이 반드시 성능을 향상시키는 것은 아니며 오히려 성능을 저해할 수도 있음을 보여줍니다. 이는 시각적 단서가 이해에 큰 도움이 되는 인간의 능력과는 뚜렷한 대조를 이룹니다. 시각적 입력을 제거하면 모델이 텍스트 정보를 활용하여 공간 추론 작업을 해결하도록 유도됩니다.

그림 7: VTQA에서 원본 이미지 vs. 이미지 없음 비교. 시각적 입력이 없을 때 VLM은 공간 추론 작업에서 향상된 성능을 보입니다.
Noise image can improve the performance
노이즈 이미지가 성능을 향상시킬 수 있습니다. 원본 이미지를 노이즈 이미지로 교체하되 원본 텍스트 설명은 그대로 유지했습니다. 그 결과는 그림 8에 나와 있습니다. '원본 이미지 대 이미지 없음'에서의 결과와 일치하게 노이즈 이미지를 사용하는 것도 다양한 VLM 아키텍처에서 성능을 향상시킵니다.
예를 들어, Maze-Nav 작업에서 LLaVA-1.6-Vicuna-13B의 정확도는 원본 이미지가 아닌 노이즈 이미지를 사용할 때 6.5% 증가합니다. '이미지 없음' 설정과 달리 노이즈 이미지는 제한적인 시각적 단서를 제공합니다. 그럼에도 불구하고 모델은 특히 시각적 단서가 작업과 관련이 없을 때 텍스트 정보를 우선시하는 경향이 있습니다.
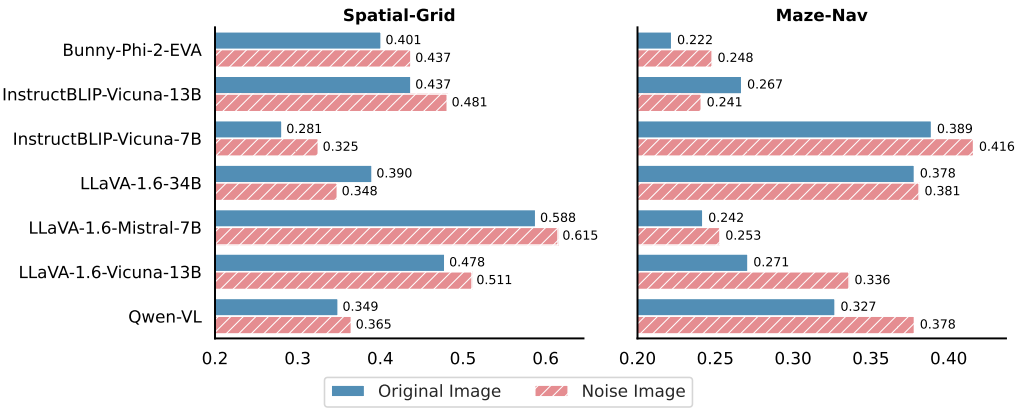
그림 8: VTQA에서 원본 이미지 vs. 노이즈 이미지. 원본 이미지를 가우시안 노이즈 이미지로 교체하면 다양한 VLM 아키텍처에서 성능이 향상됩니다.
Mismatched image-text does not necessarily hurt

그림 9: VTQA에서 원본 이미지 vs. 임의 이미지. Maze-Nav에서 원본 이미지를 임의 이미지로 교체하면 다양한 VLM 아키텍처에서 성능 향상이 발생합니다.
5.2 Leveraging Redundancy in Multimodal Inputs
멀티모달 언어 모델은 다중 모드 입력을 처리하는 데 있어 상당한 다재다능함을 제공합니다. 시각적 입력만으로도 사람이 공간 추론 작업을 쉽게 처리할 수 있는 충분한 세부 정보를 제공하는 경우가 많지만, VLM은 시각 데이터와 함께 텍스트 설명을 포함하면 상당한 중복성이 도입되더라도 상당한 이점을 얻는다고 제안합니다.
다양한 VLM 아키텍처에서 VQA(Vision-only 입력)와 VTQA(Vision-text 입력)를 비교하여 이 가설을 검증합니다. 결과는 그림 10에 나와 있으며, 거미 플롯의 각 꼭짓점은 동일한 VLM을 기반으로 하는 (Vision-only, Vision-text) 쌍의 평균 정확도를 나타냅니다. Spatial-Map 및 Spatial-Grid의 경우 추가 텍스트 입력(VTQA)이 있는 경우 다양한 VLM 아키텍처에서 이미지만 사용하는 경우(VQA)보다 성능이 향상되는 것을 분명히 알 수 있습니다. 이는 텍스트 입력이 VLM에서 공간 추론의 정확도를 향상시킨다는 것을 시사합니다. 부록 C에서는 TQA와 VTQA를 추가로 비교합니다. 자세한 결과는 부록 D에 포함되어 있습니다.
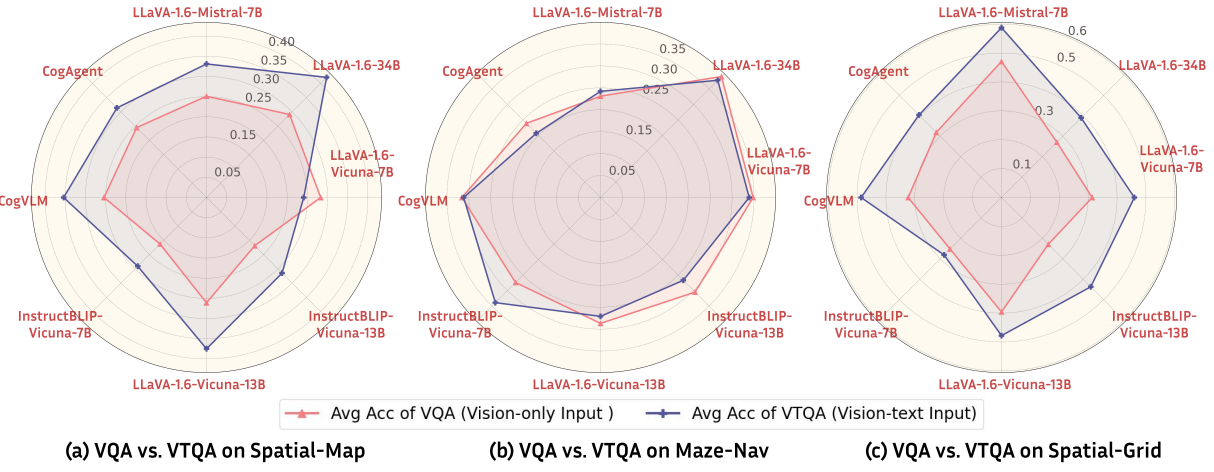
그림 10: 공간 추론 작업에서 VQA 대 VTQA 비교. 거미 플롯의 각 꼭짓점은 동일한 VLM 모델을 사용하는 (Vision-only, Vision-text) 쌍의 평균 정확도를 나타냅니다. 추가 텍스트 입력(VTQA)이 있으면 이미지만 사용하는 경우(VQA)보다 성능이 향상되는 것을 알 수 있습니다.
Text-only input with LLM vs. Text-only input with VLM
LLM의 텍스트 전용 입력 vs. VLM의 텍스트 전용 입력. 텍스트 전용 입력의 효과가 입증됨에 따라, 텍스트 전용 입력을 사용하여 LLM과 VLM을 비교하는 절제 연구를 수행했습니다.
시각 데이터 없이 텍스트를 처리할 수 있는 VLM을 고려했습니다. 결과는 그림 11에 나와 있습니다. CogVLM을 제외한 대부분의 VLM은 해당 LLM 백본보다 성능이 뛰어납니다. 이는 VLM의 언어 모델 백본이 멀티모달 학습을 통해 향상된 공간 추론 능력을 보여준다는 것을 시사합니다. 반대로, 시각 정보를 추가하는 것이 반드시 추가적인 이점을 제공하지는 않습니다.

그림 11: LLM의 텍스트 전용 입력(TQA) vs. VLM의 텍스트 전용 입력(No Img) 비교. 텍스트 전용 입력을 지원하는 VLM을 고려합니다. 거미 플롯의 각 꼭짓점은 동일한 언어 모델 백본을 가진 (LLM, VLM) 쌍의 평균 정확도를 나타냅니다.
최근 많은 벤치마크에서 독점 모델이 일반적으로 오픈 소스 모델보다 성능이 뛰어나다는 것을 보여주었듯이, 관찰된 추세가 독점 모델에서도 유지되는지 이해하는 것이 중요합니다.
여러 최고 독점 모델(GPT-4, GPT-4V, GPT-4O, Gemini Pro 1.0 및 Claude 3 Opus)의 성능이 그림 12에 나와 있습니다. 다음과 같은 중요한 관찰 결과가 있습니다.
(1) 예상대로 SoTA 오픈 소스 모델과 독점 모델 간에는 상당한 성능 격차가 존재합니다. 또한 텍스트 전용 및 시각-텍스트 형식 모두에서 GPT-4V 및 GPT-4O는 모든 작업에서 무작위 추측을 크게 능가합니다. 예를 들어, Vision-text 형식에서 GPT-4O는 Spatial-Grid에서 0.989의 정확도를 달성합니다(표 2).
(2) 그러나 오픈 소스 모델에서 관찰된 추세는 유지되며, VQA는 TQA 및 VTQA에 비해 지속적으로 성능이 저조합니다. 예를 들어 GPT-4V의 성능은 Vision-only에서 Vision-text 입력으로 전환할 때 Spatial-Grid에서 25.6% 향상됩니다. 또한 TQA와 VTQA 사이에는 명확한 승자가 없습니다(자세한 내용은 부록 C 참조). 이는 독점 모델, 심지어 새로운 GPT-4O 모델조차도 여전히 시각적 입력을 완전히 활용하지 못하는 것으로 보입니다.
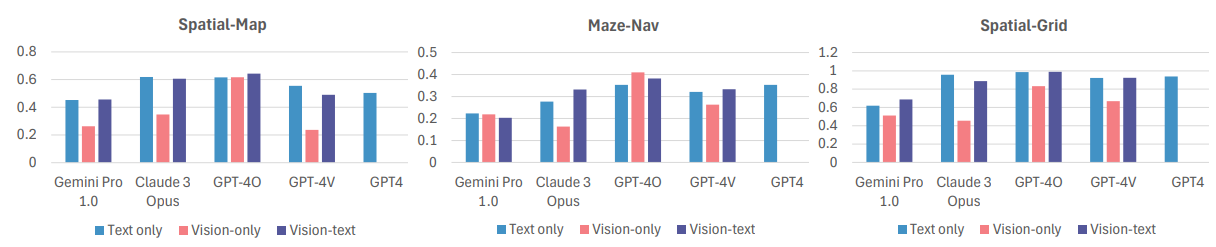
그림 12: 독점 모델 결과. 오픈 소스 모델과 유사한 추세가 관찰됩니다.
6 논의 및 결론
우리는 VLM 및 LLM의 공간 이해 능력을 탐구했습니다. SoTA 오픈 소스 및 독점 모델에 대한 실험을 통해 몇 가지 놀라운 결론을 얻었습니다.
(1) VLM은 공간 추론 작업에 어려움을 겪고,
(2) 멀티모달 모델은 시각적 입력에 의존할 때 LLM을 거의 능가하지 못하며,
(3) 텍스트 및 시각적 입력이 모두 제공되는 경우 멀티모달 언어 모델은 시각적 입력에 덜 의존하며,
(4) VLM은 종종 텍스트 전용 입력을 사용하는 LLM보다 성능이 뛰어납니다. 이는 현재 VLM이 광범위한 비전-텍스트 작업에서 고성능을 발휘한다는 믿음에 도전합니다.
그러나 좀 더 생각해 보면 아마도 이것은 결국 예상되는 결과일 것입니다.
현재 알려진 VLM 아키텍처는 시각 입력을 언어 공간으로 "번역"하려고 시도하며 모든 추론은 언어 도메인에서 수행됩니다. 텍스트 전용 시나리오에서처럼 이 자동 번역 경로가 사람이 제공하는 텍스트 번역보다 성능이 떨어지는 것은 논리적입니다. 따라서 이 연구는 번역 접근 방식의 한계를 보여줍니다. 대신 인간 수준의 성능과의 격차를 해소하기 위해 미래 모델에는 시각 입력을 일류 정보 소스로 취급하고 공동 시각-언어 공간에서 추론하는 새로운 아키텍처가 필요합니다. 이 연구가 이러한 방향으로의 개발에 도움이 되기를 바랍니다.