VLM : 논문리뷰 : Evaluating Language Models for Mathematics through Interactions
Evaluating Language Models for Mathematics through Interactions
Abstract
대규모 언어 모델(LLM) 기반 문제 해결 비서 구축에 대한 기대가 높지만, 기존의 정적인 입출력 쌍에 의존하는 평가 방법은 LLM의 적절한 활용 환경을 판단하기에 부족합니다.
정적 평가는 LLM 배포의 핵심 요소인 상호작용을 고려하지 않아 언어 모델의 능력을 제한적으로 이해하게 합니다.
본 연구에서는 인간이 LLM과 상호작용하고 평가할 수 있는 적응형 플랫폼인 CheckMate를 소개합니다.
CheckMate를 활용하여 InstructGPT, ChatGPT, GPT-4 등 세 가지 언어 모델을 대학 수학 증명 보조 도구로 평가하며, 학부생부터 수학 교수까지 다양한 참가자와 함께 연구를 진행했습니다.
이를 통해 얻은 상호작용 및 평가 데이터 세트인 MathConverse를 공개합니다.
MathConverse 분석을 통해 인간 행동 분류 체계를 도출하고, LLM 생성의 정확성과 유용성 간에 전반적으로 긍정적인 상관관계가 있지만, 특정 경우에는 불일치가 발생함을 발견했습니다. 또한, 수학 전문가들이 기여한 사례 연구를 통해 GPT-4의 수학 문제 해결 능력을 더욱 세밀하게 이해할 수 있었습니다.
(답변의 정확성과 모델의 유용성이 불일치 하는 경우도 있다는 말.)
본 연구는 ML 실무자와 수학자에게 다음과 같은 실행 가능한 시사점을 제공합니다. 불확실성을 전달하고 사용자 수정에 잘 반응하며, 해석 가능하고 간결한 모델이 더 나은 보조 도구가 될 수 있습니다. 상호작용 평가는 이러한 모델의 능력을 파악하는 유망한 방법이며, 인간은 언어 모델의 대수적 오류 가능성을 인지하고 적절한 활용 분야를 식별해야 합니다.
Introduction
기존의 LLM 평가 방식은 주로 정적인 입출력 쌍에 의존하여 실제 사용 사례와는 부합하지 않을 수 있습니다.
따라서 본 논문에서는 LLM의 능력을 제대로 이해하기 위해 상호작용적이고 동적인 평가가 필요하다고 주장하며, 이러한 평가 방식을 통해 LLM의 한계, 바람직하지 않은 행동, 잠재적 위험을 더욱 명확히 파악하고자 합니다.
특히, 수학 정리 증명은 형식적인 정확성을 요구하면서도, 자연어로 표현되는 경우가 많기 때문입니다. 이러한 과제의 중요한 품질 척도는 유용성과 정확성인데, 이는 자동화된 평가 지표로는 충분히 측정될 수 없습니다. 따라서 인간이 시스템과 직접 소통하고 평가하는 것이 LLM 평가에 필수적입니다.

그림 1:
a) 전형적인 정적 평가(상단)와 상호작용 평가(하단)의 대비. 상호작용 평가에서는 인간이 모델에 반복적으로 질문하고 응답의 품질을 평가합니다.
b) LLM과 상호작용하기 위한 CheckMate의 채팅 인터페이스 예시.
참가자에게 문제와 특히 관련 있는 지침이 제시되고, 아래에 채팅을 입력합니다(LaTeX으로 컴파일된 내용을 볼 수 있음). 사용자가 참조할 수 있도록 채팅 기록이 표시됩니다.
본 연구에서는 인간과 LLM 간의 수학적 추론 상호작용을 분석하기 위해 두 가지 방법을 사용합니다.
첫째, 대화에서 생성된 모든 LLM 응답에 대한 구조화된 평가입니다.
둘째, 수학 전문가들이 사례별 심층 분석을 수행하는 자유 형식 평가입니다.
이는 최근 모델 행동 이해에 도메인 전문가를 참여시키는 연구 흐름에 발맞춰, LLM 시스템을 더 잘 이해하기 위한 비 ML 학자들의 참여를 촉구하는 요구에 직접적으로 부응합니다.
본 연구는 학제 간 연구를 기반으로 합니다. 수많은 LLM 기반 챗봇이 존재하지만, 사용자와의 상호작용에 대한 세밀한 평가를 대규모로 이끌어낼 수 있는 개방적이고 통합된 플랫폼은 부족합니다.
따라서 본 연구에서는 CheckMate라는 경량화된 상호작용 평가 플랫폼을 개발했습니다. CheckMate는 InstructGPT, ChatGPT, GPT-4 등 다양한 언어 모델을 활용하여 학부 수준 정리 증명 문제에 대한 실증 연구를 수행하는 데 활용됩니다. 이 연구 결과는 261개의 인간-모델 상호작용 데이터와 사용자 행동 분류 체계를 포함하는 MathConverse 데이터 세트로 공개됩니다.
본 연구는 다양한 수학적 경험을 가진 참가자를 포함할 뿐만 아니라, 기존 연구보다 높은 수준의 문제 난이도를 다룬다는 점에서 특히 주목할 만합니다. 또한, CheckMate는 수학 외 다른 분야에도 쉽게 확장될 수 있습니다. 더불어, 현재 LLM의 수학적 추론 능력을 더 잘 파악하기 위해 세 명의 수학 전문가를 초대하여 심층적인 상호작용 사례 연구를 진행했습니다.
본 연구는 LLM 전반에 대한 광범위한 결론을 도출하기보다는, 상호작용을 평가 과정에 통합하는 것의 타당성과 가치를 강조하고, 특히 수학 분야에서 잠재적인 인간 및 모델 행동 패턴을 밝히는 것을 목표로 합니다.
본 연구의 세 가지 핵심 기여는 다음과 같습니다.
• CheckMate 플랫폼 도입: 인간 사용자와의 상호작용을 통해 언어 모델을 평가하는 적응형 플랫폼인 CheckMate를 소개합니다. CheckMate를 사용하여 세 가지 언어 모델을 수학 정리 증명 과제에서 평가함으로써, 확장 가능하고 가치 있는 동적 상호작용 평가가 실현 가능함을 입증합니다.
• 사용자 행동 분류 및 데이터셋 공개: CheckMate를 통해 다양한 배경의 사용자 집단으로부터 수집된 상호작용 및 평가 데이터를 기반으로, LLM 기반 수학 비서에게 필수적으로 요구되는 능력을 식별하는 사용자 행동 분류 체계를 도출했습니다. 또한, CheckMate 상호작용 및 평가 데이터셋인 MathConverse를 공개합니다.
• 전문가 사례 연구 통한 LLM 약점 분석: 수학 전문가들이 수행한 사례 연구를 통해, 본 연구에서 탐구한 LLM의 여러 약점(대수적 조작, 과도한 장황함, 기억된 해결책에 대한 과도한 의존 등)에 대한 실증적 증거를 추가했습니다. 이러한 문제 해결을 위한 ML 실무자들의 해결책(불확실성에 대한 더 나은 전달 및 사용자 수정 업데이트 능력 등)을 촉구하고, LLM 사용자를 위한 권장 사항(예: 생성된 내용 검토 시 주의, 오류가 미묘할 수 있음)을 제안합니다.
수학 및 그 외 분야에서 LLM과의 추가적인 상호작용 평가를 통해, 이러한 모델을 어떻게, 언제, 어떤 상황에서 지원 도구로 활용할지 결정하는 데 필요한 정보를 제공할 것을 독려합니다.
Results
본 연구에서는 구조화된 다단계 상호작용 평가와 자유 형식 사례 기반 평가(그림 2 참조)라는 두 가지 평가 방법을 사용했습니다. 이제 각 연구 결과를 제시하고, 주요 통찰을 종합적으로 분석하겠습니다.

그림 2:
(a) 참가자가 선호하는 수학 비서 모델에 대한 상호작용 후 순위 (낮을수록 선호도 높음).
동점 허용 및 포함: 참가자는 여러 모델에 동일한 순위를 부여할 수 있었습니다 (자세한 내용은 SI 추가 설문 조사 관찰 참조).
(b) 각 모델에 대해 받은 수학적 정확성 및 인지된 유용성 점수 (모든 점수는 정수 ∈ {0, 1, ..., 6}, 높을수록 좋음).
각 점수 척도와 관련된 텍스트에 대한 자세한 내용은 SI 추가 설문 조사 세부 정보에 포함되어 있습니다.
(c) 각 모델 생성에 대한 참가자의 수학적 정확성 점수와 인지된 유용성 점수 비교.
각 점은 단일 인간-모델 상호작용에 대한 점수입니다. 점들이 겹치는 경우 시각적 편의를 위해 약간의 지터를 추가했습니다. 흥미롭게도, 생성의 인지된 유용성과 정확성이 분기되는 경우, 즉 특정 인스턴스가 부정확하지만 다소 유용하거나 정확하지만 다소 도움이 되지 않는 것으로 간주될 수 있는 경우를 관찰할 수 있습니다.
(d) 정확성 및 유용성 점수와 단계가 종료되었는지 여부(즉, 참가자가 특정 문제에 대해 상호 작용을 중단한 후 단계) 간의 관계.
버블의 크기는 특정 점수 쌍(정확성, 유용성)의 수를 나타냅니다. 고정된 점수 쌍의 경우 불투명도는 중지 단계의 비율, 즉 총 단계 수로 나눈 종료 단계 수를 나타냅니다.
2.1 Observations from Applying CheckMate
본 섹션에서는 수학 분야에 CheckMate를 적용하여 얻은 주요 결과와 MathConverse 데이터셋(그림 1b 및 보충 정보(SI) 참조)을 소개합니다.
챗봇에 최적화된 시스템 선호 참가자들은 어떤 모델과 상호작용하고 평가하는지 알지 못했지만,
그림 2a에서 예상대로 챗봇에 최적화된 모델(ChatGPT 및 GPT-4)이 그렇지 않은 모델(InstructGPT)보다 꾸준히 선호되는 것으로 나타났습니다.
특히 GPT-4는 가장 자주 선호되었고 최하위 선호도를 받는 경우가 훨씬 적었습니다.
즉, GPT-4의 최악의 성능도 다른 모델보다 일관되게 더 나았습니다 (예: GPT-4는 최악의 비서로 평가된 적이 없습니다). 이러한 평가는 모델 성능에 대한 절대적인 평가를 의미하는 것이 아니라, 표준 벤치마크 데이터셋에서의 일반적인 "스냅샷" 평가를 넘어 상호작용 평가를 통해 모델 행동에 대한 더욱 미묘한 이해를 얻을 수 있음을 강조합니다.
모델별 인지된 유용성 다음으로 개별 상호작용을 살펴보았습니다.
참가자들은 각 생성에 대한 수학적 정확성과 인지된 유용성을 평가하도록 요청받았으며,
그림 2b는 모델별 유용성 및 정확성 평가를 보여줍니다. 이 데이터는 모델 간의 차이를 더욱 명확하게 보여줍니다. 특히 GPT-4는 일관되게 높은 유용성 평가를 받아 잠재적인 인지된 유용성을 강조합니다.
여기서 생성 4는 "여러 개의 중요한 수학 오류"(정확성 점수 2)가 있지만 "다소 유용"(유용성 점수 4)하다고 평가되었습니다.
그림 2c에서 세 가지 모델 모두 인지된 유용성과 정확성 사이에 양의 상관관계가 있음을 알 수 있습니다. 하지만 흥미롭게도, 완전히 수학적으로 정확하지만 특별히 도움이 되지 않는다고 판단되는 생성도 있었습니다(예: 정확성 6, 유용성 3). 이는 예를 들어 지나치게 장황한 답변의 경우 발생할 수 있습니다.
이러한 데이터는 단일 척도의 "우수성" 점수를 넘어 다중 요인 LLM 평가의 가치를 더욱 확고히 합니다. 본 연구의 전문가 사례 연구에서 이 두 가지 점을 더 자세히 설명합니다.
2.2 Taxonomising User Behaviour from MathConverse
본 연구에서는 참가자들이 LLM과 상호작용하는 특징을 질적으로 분석했습니다.
핵심 동기는 수학자들이 실제로 이러한 시스템을 어떻게 사용하는지, 어떤 질문을 시작하고 상호작용 과정에서 모델을 어떻게 따라가는지 파악하는 것입니다. 본 데이터에서 발견되는 질문 유형에 대한 예비 분류 체계를 제시합니다.
모든 상호작용 기록은 익명으로 저장소에 공개되어 인간-기계 상호작용에 대한 추가 연구를 지원하며, 주석이 달린 분류 체계도 함께 제공됩니다. 이러한 분류 체계를 구성하고 주석을 다는 방법에 대한 자세한 내용은 방법론 및 SI 분류 체계 구성에 대한 추가 세부 정보에 포함되어 있습니다.
초기 상호작용 행동 참가자들은 일반적으로 AI 비서에게 첫 번째 질문을 할 때 네 가지 접근 방식 중 하나를 취합니다. 놀랍게도, 각 문제에 대한 참가자들의 첫 번째 상호 작용의 90% 이상이 다음과 같은 상호 작용 행동 유형 중 하나에 속합니다.
- 문제에 언급된 개념에 대한 특정 정의를 찾습니다(예: "홀 부분군의 정의" 또는 "선형 대수에서 '무효'의 정의는 무엇입니까?").
- 문제와 관련된 수학에 대한 일반적인 질문을 합니다(예: "R3의 평면은 언제 R3의 다른 평면과 평행합니까?" 또는 "수학에서 A ∈ Kn×n이 의미하는 바는 무엇입니까?").
- 전체 문제 설명이나 원래 설명을 약간 수정하여 선택적으로 앞에 지침을 추가하여 복사하여 붙여넣습니다(예: "다음 명제를 증명하는 데 도움을 줄 수 있습니까? [...]").
- 한 번에 전체 문제가 아닌 문제의 한 단계에 대한 모델 프롬프트를 표시합니다(예: "먼저 보조 정리를 증명합니다. 보조 정리 1이라고 합시다 [...]").
중간 상호작용 행동 첫 번째 상호 작용 후에는 더 다양한 상호 작용 모드가 관찰됩니다. 사용자가 더 많은 정의를 요구하는 등 위의 내용을 반복하는 것 외에도 다음과 같은 일반적인 패턴을 발견했습니다.
- 명확한 질문을 합니다(예: "p가 소수가 아닌 경우에도 유지됩니까?").
- 모델 출력을 수정하고 때로는 명확한 질문을 합니다(예: "이해합니다. 하지만 귀하의 예는 오해의 소지가 있습니다. 귀하의 예에서 f는 2차이고 2개의 근을 가지므로 유효한 반례를 나타내지 않습니다. 다항식이 차수보다 더 많은 근을 갖는 예를 제시할 수 있습니까?").
- 모델에서 생성된 내용에 대해 설명을 요청합니다(예: 특정 기호가 의미하는 바 — "여기서 τ는 무엇입니까?").
- 모델이 뭔가를 한 이유를 묻습니다(예: "2단계에서 전체 세트를 추가해야 하는 이유는 무엇입니까?").
- 암묵적으로 모델을 수정합니다(예: "동종형성이 있다는 것처럼 들립니다. 하지만 수축은 동종형성이 아닙니까?").
- 특정 구성의 인스턴스를 요청합니다(예: "예를 들어 설명해 주시겠습니까?").
또한, 일부 참가자는 모델이 중간에 멈추면 "계속"하도록 요청하고, 일부 참가자는 인기 있는 프롬프트 엔지니어링 트릭을 시도하는 것처럼 보였습니다.
예를 들어, 모델에게 이전에 수행한 작업을 잊어버리라고 말하여 모델을 "다시 시작"하도록 시도했습니다.
"지금까지 말씀하신 내용을 잊고 다시 시도하십시오. nx + ny = nz로 시작하고 양변을 nz로 나눈 다음 거기에서 추론하십시오." 또한 한 참가자가 개념에 대한 직관을 요청했습니다.
"이 진술에 대한 증명의 직관은 무엇입니까?" 여기서 모델(GPT-4)은 "확실히 도움이 된다"고 평가된 응답을 제공했으며, 이는 앞으로 흥미로운 지원 사례가 될 가능성을 나타냅니다.
이러한 관찰은 수학자들이 어떤 종류의 상호작용을 하는지 밝혀냄으로써 그러한 상호작용(예: 참가자가 설명을 요청할 때)을 더 잘 처리할 수 있도록 툴 설계를 동기 부여하는 데 도움이 될 뿐만 아니라, AI 시스템이 어떤 도움을 줄 수 있는지, 그리고 이러한 도움을 얻기 위해 가장 잘 질문하는 방법(예: 특정 프롬프트 기술)에 대한 더 광범위한 대중 교육에 대한 지표로도 볼 수 있습니다.
상호작용 추적에 대한 평가 역학 앞서 언급했듯이 여러 참가자가 모델의 출력을 수정하거나 설명을 요청하려고 시도하는 것을 관찰했습니다.
때때로 이러한 발생은 몇 번의 연속적인 시도 동안 계속될 것입니다.
우리는 이러한 수정-실수 상호 작용의 틀을 "좌절 주기"라고 부릅니다. 상호 작용 추적에서 평가 역학을 검사하여 이러한 행동 중 일부를 볼 수 있습니다. SI 그림 S6에서 우리는 일반적으로 참가자의 평가가 상호 작용 과정에서 떨어지기 시작하는 것을 볼 수 있으며 그림 2d를 통해 참가자들은 두 평가가 모두 4보다 높을 때 (모델이 명확하게 문제를 해결하고 "도울" 수 있음을 나타냄) 또는 두 평가가 모두 2보다 낮을 때 (모델이 추가적인 유용한 수학 지식을 제공하는 데 완전히 실패했음을 나타냄) 중단하는 것처럼 보입니다. 참가자가 중단하기로 선택한 이유에 대한 참가자 추천글은 SI 참가자의 설문 후 추천글에 포함되어 있습니다.
2.3 Investigations into the MathConverse Annotated Taxonomy
본 연구에서는 각 사용자 질문에 코드를 부여하여 주석 분류 체계를 구축했습니다.
자세한 내용은 아래 방법론 및 SI 분류 체계 구성에 대한 추가 세부 정보에 포함되어 있습니다.
이 분류 체계는 사용자가 어떤 종류의 질문을 하는지 이해하는 데 도움을 줍니다.
여기서 몇 가지 질문을 제기합니다.
(1) 첫 번째 상호작용에서의 질문과 두 번째 상호작용에서의 질문은 어떻게 비교됩니까?
(2) AI 시스템과 상호 작용한 경험이 많은 참가자와 그렇지 않은 참가자가 하는 질문의 종류 사이에 관계가 있습니까?
(3) 특정 상호 작용 유형과 모델의 해당 응답에 할당된 점수 사이에 관계가 있습니까?
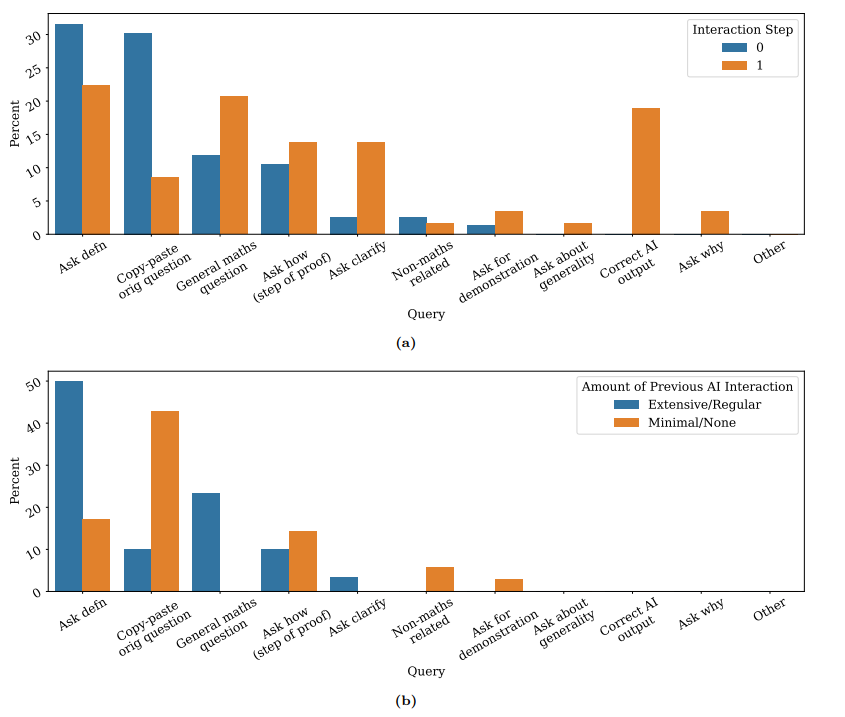
그림 3:
(a) 상호작용 단계의 함수로서의 질문 프로필. 사용자는 두 번째 상호작용에서 모델의 출력을 수정하고 이유를 묻는 등에 비해 첫 번째 상호작용에서 정의나 일반적인 수학 질문을 요청하고 전체 텍스트를 붙여넣는 것을 선호합니다. 상호 작용 단계 0은 초기 상호 작용입니다. 1단계는 0단계에서 질의에 대한 첫 번째 AI 응답을 받은 후 질의입니다.
(b) 사용자가 참여하기 전에 AI 시스템에 대한 경험의 양에 따른 질의 프로필 - 첫 번째 상호 작용 단계(즉, 0단계).
질문 (1)과 (2)에 답하기 위해 "질문 프로필"을 조사합니다. 질문 프로필은 특정 상호 작용 기간 동안 사용자(또는 사용자 하위 집합)가 만든 질문 종류의 "서명"입니다.
그림 3a에서 첫 번째 상호작용과 두 번째 상호작용에서 참가자가 만든 질문 종류에 대한 질문 프로필을 비교하여 질문 (1)에 답합니다.
첫 번째 상호작용과 두 번째 상호작용 간에 질문 프로필에 뚜렷한 차이가 있음을 관찰하여 AI 시스템 동작을 상호작용을 통해 연구하는 것의 중요성을 나타냅니다. 질문 패턴은 시간이 지남에 따라 진화할 수 있습니다.
질문 (2)에 답하기 위해 그림 3b에서 사전 AI 전문 지식이 거의 없는 사용자(즉, AI 시스템과 상호 작용한 적이 없거나 거의 상호 작용한 적이 없다고 응답)가 전체 프롬프트 텍스트를 간단히 붙여넣을 가능성이 더 높다는 것을 알 수 있습니다.
AI 시스템에 대한 경험이 더 많은 사람들과는 달리 더 정기적으로 분해된 작업을 요청했습니다(예: 정의 요청 또는 증명의 단일 단계에 대한 도움 요청). 이러한 행동의 차이는 바람직한 응답을 유도하는 프롬프트 행동의 종류에 대한 사용자 전반의 일반적인 AI 리터러시를 향상시키는 것의 잠재적인 중요성을 암시합니다.
질문 (3)은 SI MathConverse 분류 체계의 추가 조사에서 살펴보고 특정 질문이 차별적인 정확성 및 유용성 평가와 관련되어 있음을 발견하여 중요성을 암시합니다. 특정 질문 유형 및 인간 수정과 관련된 질문에 대한 모델 성능에 대한 추가 체계적인 연구는 향후 연구 과제로 남아 있습니다.
2.4 Qualitative Observations from Case Studies
다음으로, 자유 형식 상호작용과 관련하여 각 전문가가 제공한 주요 내용을 포함합니다. 그런 다음 사례 연구 전체에서 핵심 통찰력을 종합합니다.
2.5 Per-Expert Conclusions
각 분야 전문가들은 GPT-4와의 상호작용 후 주요 내용을 언급했습니다.
Dr. William Hart
GPT-4는 매우 흔한 기초 정수론 자료를 암기하고 간단한 문제를 처리할 수 있지만, 대수적 조작에 큰 어려움을 겪고 백트래킹, 중간 보조 정리 증명 또는 광범위한 계획이 필요한 새로운 문제를 해결하는 능력은 거의 없습니다.
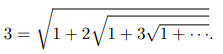
을 보여달라는 요청을 받았을 때 이러한 문제점이 분명하게 드러납니다.
여기서 일관된 문제는 중첩된 근호를 설명하는 재귀 관계에 대한 올바른 표현을 작성하지 못하는 것입니다.
GPT-4는 각 제곱근 아래의 표현이 동일하다고 확신하는 것처럼 보이므로,
초기 표현 ....... 등도 갖게 됩니다.
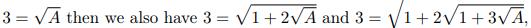
좀 더 자세히 살펴보기 위해 GPT-4는 부분적인 진행을 허용하는 방향으로 대신 프롬프트되었습니다.
힌트는 전체 중첩 근호의 값이 3이어야 한다는 원하는 결과에서 역으로 작업하면서 오른쪽에 있는 표현을 한 번에 한 제곱근씩 벗겨내어 내부 중첩 근호 값에서 일부 패턴을 찾을 수 있는지 확인하는 것이었습니다.
GPT-4가 해당 방향으로 진행하도록 쉽게 프롬프트할 수 있었지만, 모든 생성에서 절망적인 대수적 및 수치적 오류를 범했으며, 다시 한번 GPT-4의 발목을 잡는 것은 수학의 깊이가 아니라 고등학교 수준의 대수임을 보여주었습니다.
Dr. Wenda Li
저희는 GPT-4가 여러 ProofWiki 문제의 변형에 대해 상당히 만족스러운 성능을 보인다는 것을 발견했습니다.
GPT-4는 문제와 자체 증명에 사용된 개념의 정의를 안정적으로 검색할 수 있었고, 특정 가정을 완화하면 증명이 성립하지 않는지를 정확하게 평가할 수 있었습니다. 또한, 자신의 답변을 검토할 기회가 주어지면 변수를 매우 강력하게 인스턴스화할 수 있었습니다. 확률적 생성 방식의 특성을 고려할 때, 언어 모델이 어느 정도 "이해"하는지에 대한 논쟁이 있었습니다 (Bender et al., 2021b; Piantadosi and Hill, 2022). 본 연구에서는 단순 암기 이상의 수학적 이해를 바탕으로 가정 및 변수 인스턴스화를 수행하는 언어 모델 기반 비서의 몇 가지 간단한 사례를 발견했습니다. 예를 들어, GPT-4에게 다음과 같은 표준 확률 이론 문제를 풀도록 요청했습니다.
X를 확률 변수라고 합시다. µ ∈ R이고 var(X) = σ2 (σ2 ∈ R>0)인 µ에 대해 E(X) = µ라고 가정합니다. 모든 k > 0에 대해 다음을 보여주세요. Pr (|X − µ| ≥ kσ) ≤ 1/k2.
GPT-4는 먼저 체비쇼프 부등식을 사용할 수 있다고 언급한 다음, 거의 동일한 방식으로 문제를 다시 설명했지만 변수 이름은 다르게 지정했습니다. 이는 특정 수준의 변수 통합을 보여줍니다. 그런 다음 k에 다음과 같은 구체적인 값을 할당할 때 증명이 여전히 유효한지 물어봄으로써 비서가 변수를 인스턴스화하는 방법을 알고 있는지 확인했습니다. 2, √2, √2 − 1, √2 − 2 및 (√2 − 2)2. 사람이 검사한 결과 비서의 행동이 정확하다는 것을 알 수 있었습니다.
비서는 k가 비교적 복잡한 숫자(예: √2 − 1)일 때도 구체적인 계산을 처리할 수 있습니다. 또한 모델은 음수인 k = √2 − 2일 때 이전의 유도가 수행될 수 없다는 것을 알고 있었습니다.
Professor Timothy Gowers
GPT-4에서 관찰된 강점과 약점은 다른 LLM과 관련하여 여러 번 언급된 것들입니다. 예를 들어, GPT-4는 계산에는 능숙하지 않고, 주요 결론을 뒷받침하지 않는 사실을 무시하는 경향이 있으며 (GPT-4가 생성한 사실일지라도), 결론을 뒷받침하는 사실을 날조하기도 합니다 (Azamfirei et al., 2023). 예시를 만들 때 GPT-4는 또 다른 약점을 보입니다.
즉, 추론 과정을 통해 예시의 모습을 제한하고 나서 예시를 제시하는 대신, 먼저 예시를 제시한 다음 원하는 속성을 갖는다는 정당성을 제공하는 것을 선호합니다.
초기 제안이 정확하면 괜찮을 수 있지만 (항상 정당성이 정확하지는 않음), 종종 제시하는 예시가 정확하지 않으며, 일반적으로 훈련된 수학자에게는 매우 명백한 결함이 있는 "정당성"을 따릅니다. 이러한 행동은 확률적 앵무새 관점을 뒷받침하는데, 수학적 구성은 일반적으로 문헌에서 동일한 도움이 되지 않는 방식으로 제시되기 때문입니다. 먼저 예시를 제시하고, 그 다음 작동 방식을 검증합니다.
GPT-4가 이러한 방식으로 답변을 구성하지 않도록 프롬프트 엔지니어링을 사용할 수 있습니다. 예를 들어 모델에게 즉시 예시를 제공하지 말고 먼저 일반적인 전략을 설명한 다음 전략 구현을 설명하도록 요청하거나, 학생인 척하고 힌트를 제공하도록 요청할 수 있습니다. 이러한 방법은 GPT-4의 출력을 다소 개선했지만, 전반적인 결론에 영향을 미칠 만큼 큰 차이는 없었기 때문에 주로 더 간단한 프롬프트를 사용했습니다.
GPT-4와 상호 작용하는 경험에 부정적인 영향을 미치는 또 다른 특징은 정답을 제시하더라도 종종 지루한 사례별 방식으로 설명하고 속성을 확인하며, 이러한 확인이 필요하지 않은 경우가 많다는 것입니다.
예를 들어, 8개의 꼭짓점을 가진 3-정규 그래프를 구성하라는 요청을 받으면 일반적으로 모든 꼭짓점과 가장자리를 나열한 다음 각 꼭짓점에 대해 이웃을 말하고 3개가 있다고 언급합니다.
또는 행렬 [0 1, 0 0]이 0 행렬로 제곱된다는 사실이 필요한 경우, 단순히 그렇게 주장하는 대신 [0 1, 0 0]^2 = [0 1, 0 0] [0 1, 0 0] = [0 0, 0 0] 과 같이 작성하는데, 이는 행렬 곱 계산에 대한 세부 정보가 제공되지 않기 때문에 (물론 원하지도 않음) 빈약한 주장에 거의 아무것도 추가하지 않습니다. 마찬가지로, 때로는 행렬과 그 전치를 작성하고 작성된 두 행렬이 동일하다는 점에 주목하여 행렬이 대칭인지 "확인"합니다.
긍정적인 측면에서 GPT-4는 단순한 암기라고 보기 어려운 방식으로 몇 가지 질문에 잘 답변했습니다. 간
단한 예를 들자면, 함수를 미분하라는 요청을 받으면 일반적으로 매우 능숙하게 수행하여 일반화 능력이 어느 정도 있음을 시사합니다. (미분은 잘하지만 산술은 잘 못하는 이유에 대한 한 가지 가능한 설명은 단계별 설명과 함께 완성된 미분 연습 예제가 산술 연습 예제보다 훨씬 더 많기 때문입니다.)
더 많은 예제는 SI 전문가와의 대화형 사례 연구에서 논의되며, GPT-4가 이러한 예제를 잘 수행하는 이유에 대한 몇 가지 추측이 제시됩니다.
2.6 Key Findings
이제 CheckMate를 수학 분야에 적용하여 수집한 MathConverse 데이터 세트와 수학자들이 GPT-4와 깊이 있게 상호작용하여 특정 관점에서 문제를 해결하는 전문가 사례 연구에서 도출된 두 가지 평가에서 핵심적인 결과를 종합해 보겠습니다.
[Key finding 1] Correctness and helpfulness of model responses are related, but can diverge in interesting ways
[주요 결과 1] 모델 응답의 정확성과 유용성은 관련이 있지만, 흥미로운 방식으로 분리될 수 있습니다.
사람이 질문을 했을 때, 모델 답변의 인지된 유용성과 정확성 사이에는 어떤 관계가 있을까요?
저희는 모든 인간-모델 상호 작용에서 유용성과 정확성 평가가 높은 상관관계를 보인다는 것을 발견했습니다 (피어슨 상관 계수 r = 0.83).
이러한 결과는 Welleck et al. (2022a)의 연구와 일치하는데, 단계별 증명과 완전 생성된 증명 모두에서 정확성이 인지된 유용성보다 뒤처지지만, 두 가지 특성이 밀접하게 관련되어 있음을 보여줍니다.
이러한 경향은 중요한 점을 강조합니다. 즉, 수학적 언어 모델이 유용한 비서가 되기 위해서는 수학적으로 대체로 정확한 응답을 일관되게 생성해야 한다는 것입니다.
흥미로운 현상은 극단적인 경우에도 나타납니다 (그림 2c 참조). 생성된 답변이 부정확하지만 도움이 되거나, 정확하지만 도움이 되지 않는 경우가 있습니다 (SI 쉬운 문제와 어려운 문제 사이의 경계 조사의 예 4 및 3 참조). 예를 들어, 모델은 완전히 수학적으로 정확하지만 적당히 유용하다고 판단되는 지나치게 장황한 답변을 생성할 수 있습니다.
SI 전문가와의 인터랙티브 사례 연구에서 암기를 조사하기 위한 문제 변형 사례에서, 모델은 정의를 제공하는 데 능숙하며 흥미롭게도 전체 증명의 세부 사항이 부정확하더라도 문제에 대한 유용한 발판 (예: 올바른 전략 또는 처음 몇 단계)을 생성할 수 있음을 알 수 있습니다. 이러한 사례는 유용한 비서를 만들기 위해서는 이러한 모델의 수학적 정확성을 높이는 것만으로는 충분하지 않다는 것을 보여줍니다.
[Key finding 2] Lack of verification can induce errors
[주요 결과 2] 검증 부족은 오류를 유발할 수 있습니다.
CheckMate 평가는 1인칭 시점에서 결정됩니다.
즉, 참가자는 자신이 받은 답변을 평가합니다. 하지만 참가자가 수학적 정확성을 검증할 수 없는 경우는 어떻게 될까요?
모델과 상호 작용하기 전에 참가자들은 스스로 문제를 해결할 수 있다는 자신감을 나타내도록 요청받습니다. 자신감이 낮다고 표시한 참가자 (즉, 자신감 <= 3; 평가 척도는 SI 설문 설정에 대한 추가 세부 정보 참조) 가 생성된 답변이 정확하지 않음에도 불구하고 완전히 정확하다고 평가하는 경우가 있었습니다. 이러한 예시와 참가자들의 증언은 SI 추가 설문 조사 관찰에서 확인할 수 있습니다.
사례 연구에서는 모델이 정확한 해결책을 제시하더라도, 이 해결책이 항상 "인간과 유사한" 방식으로 도출되는 것은 아닙니다. 예를 들어, 모델은 순방향 계획보다는 추측 및 확인 접근 방식을 따를 수 있습니다 .
그러나 추측 및 확인은 해결책을 "확인"할 수 없는 경우 제대로 작동하지 않습니다. 실제로, 일반적으로 대수 조작 문제는 분포 내 및 분포 외 성능에 영향을 미치는 것을 확인할 수 있습니다 (예: SI 전문가와의 인터랙티브 사례 연구, 정수론 평가의 예시).
또한, 본 연구에서는 인간 사용자가 모델을 수정하려고 시도할 때 발생하는 상호 작용 문제를 강조합니다. 한 사례 연구에서는 모델에게 불확실성에 대해 질문했을 때 모델이 정확했음에도 불구하고 사과하기 시작하는 흥미로운 행동을 보여주었습니다 (SI 전문가와의 인터랙티브 사례 연구, 암기를 조사하기 위한 문제 변형 참조).
[Key finding 3] The double-edged sword of reliance on memorised solutions
[주요 결과 3] 기억된 해결책에 대한 의존의 양면성
중요한 개념과 정의를 암기하는 것은 세상의 지식을 습득하는 데 중요한 측면입니다. MathConverse 분류 체계는 인간이 수학적 정의에 대한 질문을 자주 하고, 받은 답변이 모든 범주 중 가장 도움이 된다고 생각하는 것으로 나타났습니다.
정의와 달리 특정 문제에 대한 해결책은 이상적으로 일반화할 수 있는 방식으로 이해해야 하며 완전히 암기해서는 안 됩니다.
GPT-4의 기능을 약간 새로운 문제나 예시를 만들어야 하는 문제에 적용하여 조사한 결과, 모델이 그럴듯하게 암기된 예시나 패턴에 과도하게 의존하는 경향이 있음을 알 수 있었습니다. 모델의 학습 데이터에 직접 접근할 수 없기 때문에 이러한 예시가 실제로 "암기된" 것인지 확실하게 판단할 수는 없습니다. 그러나 그 행동으로 보아, 우리는 이것이 사실일 가능성이 높다고 강하게 의심합니다.
Discussion
구조화된 평가와 사례 기반 평가에서 도출된 주요 관찰 결과를 바탕으로, 다양한 독자층에게 도움이 될 수 있는 일련의 실행 가능한 시사점을 제시합니다.
본 연구의 학제적 특성을 고려하여, 각 분야의 독자들에게 맞춤형 시사점을 제공합니다.
균형 잡힌 관점을 제시하기 위해, 먼저 조사 대상 중 최고의 LLM은 학부 수준의 수학 문제에서 사용자와 유용하고 정확하게 협력하는 능력을 어느 정도 보여주었다는 점을 언급합니다 (그림 2b 참조).
사용자가 LLM이 생성한 답변의 타당성을 평가할 수 있다면, LLM은 몇몇 문제에 대해 의미 있는 도움을 줄 수 있습니다. 답변이 암기된 것이고 인터넷 어딘가에서 찾을 수 있다고 해도, LLM은 기존 검색 엔진보다 입력 및 출력 측면에서 유연하다는 장점이 있습니다.
마지막으로 본 연구 방법론의 한계점을 제시합니다.
3.1 Takeaways for ML Developers
모델이 교정된 불확실성을 전달하고 수정 사항을 수용할 수 있도록 지원
사용자가 모델의 오류를 수정하려고 시도했을 때, 모델이 사과하고 필요한 수정이나 명확한 설명 없이 답변을 제공하는 경우를 관찰했습니다. 이러한 패턴은 사용자가 지루함을 느껴 중단할 때까지 반복되는 경우가 많았습니다.
사용자 경험을 개선하기 위해서는 불확실성 교정등을 통해 사용자 수정에 적절하게 대응할 수 있는 시스템이 필요합니다.
실제로, 본 연구에서 탐색한 모델에서는 모델이 언제 확신하지 못하는지 명확하지 않았습니다. 설문 조사 후 참가자들과 함께 이러한 문제에 대한 논의 내용을 포함했습니다. 사용자가 언제 모델 출력을 신뢰할 수 있는지 알 수 있도록 불확실성을 전달하고 적절한 수준의 신뢰를 조정하는 데 도움을 주는 것이 중요합니다. 그러나 LLM에서 정확하고 교정된 불확실성 추정치를 얻는 것은 어려운 작업이 될 수 있습니다.
근거 제시 기능 활성화
MathConverse의 여러 참가자는 모델이 특정 증명 단계를 수행한 "이유"를 물었습니다. 선택에 대한 정당성을 확장하는 것은 귀중한 교육 도구가 될 수 있습니다. 즉석에서 요청에 따라 설득력 있는 설명을 생성하는 기능(설명이 실제로 대표성이 있고 오해의 소지가 없는 경우)은 수학자와의 파트너십에서 이러한 시스템의 유용성을 더욱 높이기 위해 탐구하고 개발할 가치가 있는 것으로 보입니다.
간결성 추구
설문 조사와 전문가 사례 연구 모두에서 수학적 정확성이 고급 수학에서 유용한 지원의 기초가 되는 경우가 많지만 항상 충분하지는 않다는 사실을 발견했습니다. 너무 장황한 답변은 때때로 덜 유용하다고 간주되었습니다. 수학 질문에 대한 간결한 답변을 생성하는 시스템을 설계하는 것은 유망한 미래 방향이며, 필요한 경우 "작업"을 보여줄 수 있는 기능과 함께 사용하는 것이 가장 좋습니다. 수학 이외의 다른 분야에 대한 적용 가능성은 여전히 연구되어야 합니다. 의학과 같이 공감을 불러일으키는 더 긴 답변이 선호될 수도 있습니다.
3.2 Takeaways for Mathematicians (Students, Educators, and Researchers)
주의를 기울이세요!
대규모 언어 모델은 매우 설득력 있는 자연어를 생성할 수 있습니다. 이는 무시해서는 안 될 놀라운 기술적 성과이며, 우리 연구에서도 볼 수 있듯이 유용할 수 있습니다. 그러나 이러한 능력은 독자가 오류를 인식하지 못하도록 유도할 수 있다는 점을 간과하게 만들 수 있습니다. 따라서 게으른 검증의 함정에 빠지지 않도록 주의해야 합니다 (참가자들의 의견에서 SI 설문 조사 후 참가자들의 의견 참조). 이는 LLM의 생성물로부터 학습하거나 평가하는 사용자, 예를 들어 학생 및 과제 채점자에게 유의해야 할 사항입니다. 또한, 단순히 모델에서 나왔다는 이유만으로 모델의 출력에 부적절하게 과도하게 의존하는 자동화 편향의 위험성을 인지하는 것이 중요합니다 (Cummings, 2004).
이러한 모델이 언제 도움이 될 수 있는지에 대한 미묘한 관점을 가지세요
(Frieder et al., 2023)의 연구 결과와 유사하게, 본 연구에서도 LLM이 정의 검색에 유용할 수 있으며 (SI 추가 분류 관찰 참조), 때로는 문제 해결 방법에 대한 유용한 발판을 제공할 수 있음을 관찰했습니다 (SI 추가 설문 조사 관찰 및 SI 전문가와의 인터랙티브 사례 연구 참조). 작업 공간의 한 영역에서 잘 수행되는 모델이 다른 영역에서도 반드시 잘 수행될 것이라고 추정해서는 안 됩니다(Bhatt et al., 2023; Kelly et al., 2023). 모라벡의 역설(Moravec's Paradox) (Moravec, 1988)처럼 직관에 반하는 것은, 모델이 인간이 어렵다고 생각하는 작업에는 성공하지만, 인간이 쉽다고 생각하는 작업에는 실패할 수 있다는 것입니다 (예: 유도 대 대수 조작). 수학자는 질의 프로필을 활용하여 숙련된 동료들이 수학을 위해 언어 모델을 더 잘 활용하기 위해 어떻게 행동을 조정하는지 배울 수 있습니다.
현재 LLM을 (단독으로) 대수 연산에 사용할 때 주의하십시오
특히, 본 연구는 이전 연구(Bubeck et al., 2023; Dziri et al., 2023; Frieder et al., 2023)와 마찬가지로 현재 모델의 대수 조작 문제를 더욱 강조합니다. 따라서 수학자들이 상당한 대수 연산이 포함된 작업에 이러한 시스템을 사용할 경우 주의해야 한다고 생각합니다. 본 논문에서는 플러그인(OpenAI, 2023a)이나 대체 하이브리드 신경 기호 접근 방식 (예: (Gowers, 2022; Jiang et al., 2022b; Kazemi et al., 2022; Li et al., 2022; Poesia and Goodman, 2022; Wong et al., 2023))을 다루지 않았지만, 이러한 접근 방식은 이러한 실패 모드 중 일부에 대한 유용한 해결책이 될 수 있습니다.
3.3 Takeaways for LLM Development, Evaluation, and Deployment
LLM을 개발, 평가 또는 실제로 배포하는 모든 사람들을 위한 광범위한 시사점을 제시하며 결론을 맺습니다.
AI 기반 비서가 필요한 시점 (또는 활용할 가치가 있는 시점)을 신중하게 파악
보완 시스템을 구축하려면 AI 기반 비서가 언제 도움이 되는지 이해하는 것이 가장 중요합니다. 이러한 비서는 모든 환경에서 도움이 되는 경우는 거의 없습니다 (Bhatt et al., 2023). 중요한 질문은 어떤 설정에서 이러한 비서가 수학자의 에이전시를 훼손하지 않고 유용할 수 있는가 하는 것입니다. 예를 들어, 이미 LLM을 수업 과정에 사용하는 것을 고려할 때 제안되는 종류의 것입니다 (Ba and Wang, 2023). 향후 연구에서는 필요할 때 지원을 제공하는 상보성을 위해 최적화된 유용한 비서를 구축하는 방법을 고려하는 것이 좋습니다 (Miller, 2023).
ML 실무자와 도메인 전문가 간의 협력은 가치가 있습니다
도메인 전문가와 협력하여 조사를 수행하는 것은 특히 전문가 사례 연구에서 입증된 것처럼 완전히 새로운 작업을 설계함으로써 모델 행동을 특성화하는 데 특히 유용할 수 있습니다 (Davies et al., 2021; McGrath et al., 2022; Mirowski et al., 2023). 수학 및 그 외 분야에서 이러한 학제 간 파트너십을 구축하는 것이 좋습니다.
LLM 기능 평가에 상호 작용성 통합
LLM 기능의 전체적인 상황을 진정으로 이해하려면 대화형 평가를 통합하는 것이 가장 중요하다고 생각합니다.
본 연구는 이러한 모델의 강점과 약점에 대한 더 깊은 통찰력을 얻고 지원 환경에 더 적합할 수 있는 특성을 조사하는 방법으로 상호 작용 평가의 중요성을 더욱 강조합니다.
그러나 여기서 강조하는 바와 같이, LLM에 대한 상호작용 연구는 모델 행동을 특성화하는 역할을 할 뿐만 아니라, 인간이 스스로 이러한 모델과 상호작용하고 실제로 이러한 시스템을 사용하는 방식을 식별합니다 (Ringer et al., 2020). 점점 더 많은 연구들이 프롬프트 선택에 대한 이러한 모델의 민감성을 조명하고 있습니다 (Wei et al., 2022; Yao et al., 2023; Zhou et al., 2023). 따라서 특정 사용자 쿼리에 더 적합한 시스템을 설계하고 사용자에게 모범 사례를 알리기 위해 인간이 이러한 시스템과 상호 작용하는 데 사용할 수 있는 쿼리의 형식과 내용을 고려하는 것이 중요합니다.
시스템 관리자는 쿼리에 대한 응답 품질을 높이는 기술에 대한 정보를 더 잘 제공하기 위해 사용자가 이러한 전략을 활용하고 있는지 여부를 인식하는 것이 중요할 수 있습니다. 우리는 LLM을 인간-컴퓨터 상호 작용의 맥락에서 연구하는 (Lee et al., 2022a, c; Mirowski et al., 2023)와 같은 더 많은 연구가 나오기를 바랍니다.
CheckMate는 전문가 사례 연구에서 수행하는 종류의 자유 형식 평가와 함께 잠재적으로 보완될 수 있는 시작점을 제공합니다.
Limitations
본 연구는 수학자들이 언어 모델을 어떻게 사용할 수 있는지에 대한 통찰력을 제공하고 향후 상호 작용 평가를 위한 문을 열어주지만, 수학적 지원을 위한 LLM 평가의 첫 걸음일 뿐입니다.
표본 크기는 작지만 유익하며, MathConverse는 향후 방법론 및 배포 시 고려 사항을 촉발하기 위한 예비 데이터 세트로 간주됩니다. 또한, 각 참가자에게 자신의 상호 작용 기록 중에 제공된 생성물을 평가하도록 요청했습니다. 이는 (Lee et al., 2022b)에서 요구하는 1인칭 평가를 허용하지만, 문제를 해결하는 방법을 이미 알고 있지 않은 사람들에게는 생성의 정확성을 잘못 판단할 수 있다는 의미이기도 합니다.
합리적인 다음 단계는 두 가지입니다.
아직 그러한 문제를 해결하지 못한 학생들을 대상으로 평가 플랫폼을 배포하고,
외부 평가를 위해 상호 작용 기록을 전송하는 것입니다.
또한, 시간이 지남에 따라 수학자 상호 작용을 재평가하는 것이 좋습니다. 인간이 이러한 시스템과 상호 작용하는 방식은 기능이 성장함에 따라 진화할 가능성이 매우 높습니다.
또한, 분류 체계 범주가 완전하지 않으며 대체 분류가 가능할 수 있습니다. 그럼에도 불구하고, 본 연구의 분류 체계는 유용한 결과를 도출하기에 충분하다고 판단했습니다. 사례 연구는 전문 수학자의 프롬프트 행동과 모델 성능에 대한 추가적인 특성화에 대한 귀중한 통찰력을 제공하지만,
각 개인은 모델의 강점과 약점에 대한 자신의 기대를 가지고 있을 수 있으며, 이는 프로빙 행동 선택 및 모델 출력 해석 방식에 영향을 미칠 수 있습니다.
설문 조사 결과와 마찬가지로, 이러한 통찰력은 이러한 모델의 기능이나 잠재력에 대한 확고한 증거로 받아들여서는 안 되며, 모든 언어 모델에 대해서는 더욱 그렇습니다 (본 연구에서는 소수의 OpenAI 계열 모델만 고려했습니다). 오히려, 본 연구에서 확장된 평가 툴킷이 수학 및 그 외 분야에서 문제 해결을 위한 LLM 활용에 대한 추가 연구의 길을 열어주기를 바랍니다.
Conclusion
LLM이 비서 역할을 할 수 있는 인간 중심 환경에 점점 더 많이 배포됨에 따라, LLM의 효능 평가에는 상호 작용 맥락에서의 평가가 반드시 포함되어야 합니다 (Lee et al., 2022b). 본 연구에서 입증했듯이, 이러한 상호 작용 평가는 구조화 (예: CheckMate 활용)되거나 자유 형식 (예: 소싱된 도메인 전문가 또는 대상 사용자 상호 작용을 통해)으로 이루어질 수 있습니다. LLM 및 기본 모델은 광범위하게 복잡하고 종종 놀라운 행동을 보이며, 인간도 마찬가지입니다.
따라서 LLM 및 인간 상호 작용에서 잠재적인 실패 모드를 특성화하려면 상호 작용 평가와 고전적인 정적 스냅샷 평가를 모두 포함하는 다중 요인 평가 접근 방식이 필요합니다 (Burnell et al., 2023).
본 연구를 통해 LLM 기반 수학 비서 및 추론 엔진 활용을 고려할 때 신중한 설계 및 배포에 도움이 될 수 있는 통찰력을 도출했습니다. 본 연구는 특히 도메인 전문가와의 긴밀한 협력을 통해 수학 및 기타 분야에서 기본 모델 사용에 대한 추가 평가의 길을 열어줄 것이라고 믿습니다.
Methods
6.1 CheckMate: Adaptable Platform for Interactive Evaluation
본 연구에서는 언어 모델의 상호작용 평가를 지원하기 위해 적응형 플랫폼인 CheckMate를 소개합니다. CheckMate를 통해 사람들은 언어 모델이 생성한 텍스트와 상호작용하고 평가할 수 있으며, CheckMate는 이러한 "상호작용 흔적"을 기록합니다. CheckMate는 두 가지 평가 방식을 지원하도록 설계되었습니다.
(1) 단일 모델과의 상호작용 연구,
(2) 여러 모델 간의 선호도 비교 연구입니다.
먼저, 단일 모델에 대한 평가 체계를 소개하고, 그 다음 여러 모델에 대한 비교 평가를 지원하는 방법을 논의합니다. 본 연구는 수학 정리 증명 분야에 초점을 맞추고 있지만, CheckMate는 더 폭넓게 확장될 수 있습니다(CheckMate 사용자 가이드 참조).
Evaluation for a Single Model
평가는 참가자가 문제를 해결하기 위해 모델과 자유롭게 상호작용하도록 허용하는 것으로 시작됩니다.
참가자들은 자신이 문제를 해결하려고 노력하고 있다고 상상하고 도움을 요청하도록 권장됩니다.
참가자는 최대 20회의 상호작용 교환을 통해 지원을 계속 탐색할 수 있습니다.
참가자가 지원 수준에 만족하거나 (또는 상호 작용을 종료하고 싶을 정도로 충분히 만족하지 못하는 경우) 전체 상호 작용의 각 단계를 평가합니다.
CheckMate는 연속적인 인간 질의-모델 생성 쌍에 대한 상호 작용 추적에 대해 다차원 평가를 지원하도록 설계되었습니다. 현재 플랫폼은 리커트 척도와 라디오 버튼이 혼합되어 설계되었습니다 (SI 설문 설정에 대한 추가 세부 정보 및 CheckMate 사용 설명서 참조). 그러나 CheckMate는 원하는 경우 개별 오류 프로파일링(Welleck et al., 2022a) 또는 (Lee et al., 2022c; Shen and Wu, 2023)에서 제안한 추가 상호 작용 지표를 처리하기 위해 대체 평가 유형으로 쉽게 확장할 수 있습니다.
Comparative Evaluation Across Models
인간이 활용할 수 있는 언어 모델 제품군이 계속 증가함에 따라 이러한 모델이 이전 버전과 어떻게 비교되는지 기능을 비교하는 것이 중요합니다. 이러한 비교는 일반적으로 단일 스냅샷을 포함합니다.
CheckMate를 사용하면 상호 작용 추적에 대한 선호도를 연구할 수 있으며 지원 잠재력의 발전을 탐색하는 데 유용한 도구가 될 수 있습니다. CheckMate에서 참가자는 두 개 이상의 모델과 상호 작용한 후 상호 작용을 선호하는 모델에 대한 순위를 제공합니다. 플랫폼의 이 인스턴스는 참가자가 모델별로 다른 작업과 상호 작용하도록 설정되어 있습니다(동일한 문제를 여러 번 고려할 때 "블리드 오버" 효과를 방지하기 위해). 그러나 대체 설계, 예를 들어 작업별 모델 평가 또는 평가할 모델 하위 샘플링은 패러다임에 대한 가능한 적응입니다(CheckMate 사용 설명서 참조). 중요하게도 참가자는 언제든지 어떤 모델을 평가하고 있는지 알 수 없습니다.
이렇게 하면 어떤 모델이 더 효과적일 수 있다는 선입견에 영향을 받지 않습니다. 순위 순서에서 참가자는 어떤 모델을 선호하는지 잘 모르는 경우 동일한 순위를 부여할 수 있습니다.
향후 연구에서는 보다 광범위한 비교 우선순위 평가를 고려할 수 있습니다. CheckMate 및 설문 조사 호스팅에 대한 자세한 내용은 SI CheckMate 사용자 가이드에 나와 있습니다.
Instantiating CheckMate for Mathematics to Collect MathConverse
설문 조사 참가자들은 수학적 진술을 증명하고 이 과제를 수행하기 위해 AI 시스템을 사용하여 어떤 식으로든 도움을 받도록 요청받습니다.
상호 작용은 자유 형식이므로 전체 문제에 대한 도움 요청, 정의 명확히 하기 또는 특정 생성된 증명 단계에 대한 설명 요청까지 상호 작용 범위가 다양할 수 있습니다.
참가자에게는 사전에 가능한 상호 작용 행동이 제공되지 않아 프라이밍을 방지합니다. 참가자가 지원 수준에 만족하거나 (또는 상호 작용을 종료하고 싶을 정도로 충분히 만족하지 못하는 경우) 전체 상호 작용의 각 단계를 평가합니다. 참가자는 세 가지 모델(Instruct-GPT, ChatGPT 및 GPT-4)에 대해 서로 다른 문제를 해결하며, 모델 순서는 무작위로 지정되고 참가자는 어떤 모델과 상호 작용하고 있는지 알 수 없습니다. 다음으로 평가를 수행할 작업 설정에 대해 설명합니다. 이 연구는 Cambridge University Computer Science Ethics Division의 승인을 받아 수행되었습니다. 수학용 CheckMate의 예시 인터페이스 화면은 보충 자료에 포함되어 있습니다.
Tasks
ProofWiki에서 학부 수준 수학 문제 54개를 선정했습니다. 선형 대수학, 정수론, 확률 이론, 대수학, 위상 수학, 군론 등 6개 수학 주제에서 각각 9개의 문제를 선택했습니다. 이러한 주제는 일반적인 학부 수학 커리큘럼의 다양한 주제 영역을 포괄하도록 선택되었습니다.
Rating Scales
참가자는 (Lee et al., 2022c)에서 정의한 대로 각 단계의 인지된 유용성과 수학적 정확성을 평가하고 "선호도"와 "품질" 지표를 하나씩 선택합니다. 인지 부하 및 편향은 설계의 각 단계에서 염두에 두고 있습니다. 예를 들어 페이지당 평가 수를 줄이고 가능한 순서 효과를 줄이기 위해 모델 평가 순서를 무작위로 지정합니다.
평가는 7점 리커트 척도로 제공되며, 폭은 잠재적인 평가 붕괴(즉, 참가자가 척도 끝점 사용을 주저하는 현상(Bishop and Herron, 2015))를 개선하기 위해 선택되었습니다. 또한, 평가하는 동안 과도한 인지 부하를 방지하기 위해 단계별로 두 가지 요소만 선택합니다.
참가자는 응답하기 전에 스스로 문제를 해결할 수 있다는 자신감을 명시합니다.
세 가지 모델과 세 가지 다른 문제에 대해 상호 작용한 후 참가자에게는 각 모델과의 전체 상호 작용 흔적이 표시되고 드롭다운 바를 통해 (맹목적으로) 어떤 모델을 비서로 선호하는지 (맹목적으로) 나타냅니다.
Language Model Selection and Set-Up
참가자는 챗 모드에서 세 가지 인기 있는 언어 모델인 InstructGPT(Ouyang et al., 2022), ChatGPT(OpenAI, 2022) 및 GPT-4(OpenAI, 2023b)를 평가합니다.
새로운 언어 모델이 도입됨에 따라 최적의 프롬프트를 설계하는 방법론이 빠르게 발전하고 있습니다(예: (Wei et al., 2022; Yao et al., 2023; Zhou et al., 2023)). 실제 도메인 사용자(즉, 수학자)가 이러한 시스템과 실제로 어떻게 상호 작용하는지 연구하고 있으므로 프롬프트에서 모델에 도움이 되는 수학 비서가 되도록 요청하는 것 외에는 간결한 기본 프롬프트를 유지합니다. 실험 설정에 대한 자세한 내용은 SI 설문 설정에 대한 추가 세부 정보에서 확인할 수 있습니다.
Participants
수학자 자원봉사자를 모집하여 평가에 참여시킵니다. 총 261개의 인간-모델 상호 작용으로 구성된 25개의 항목을 받았습니다. 여기에는 25명의 고유한 참가자.
수학자들은 현재 학부생부터 전문 수학 교수까지 다양한 경험 수준을 가지고 있습니다. 공식적인 수학 학위가 없는 참가자의 경우 고급 수학에 대한 어느 정도의 노출이 있을 가능성이 높습니다(SI 참가자 모집 및 추가 세부 정보 참조).
각 참가자는 6개 주제 중 하나를 선택하고 원하는 만큼 많은 질문을 평가할 수 있습니다(최대 9개까지).
참가자의 전문 지식 범위(세계적인 전문가까지)와 수학을 전공하는 학생들이 교과서나 연습 문제에서 접할 수 있는 수준의 문제라는 사실을 고려하면 일부 참가자는 이미 문제를 풀 수 있고 다른 참가자는 그렇지 않을 수 있습니다.
참가자가 문제 해결 방법을 알고 있는 경우 문제 해결 방법을 모르는 사람의 경험 수준에 있었다면 어떤 종류의 도움을 받고 싶었을지 상상해 보도록 요청합니다. 채용, 데이터 처리 및 전문 지식에 대한 자세한 내용은 SI 설문 설정에 대한 추가 세부 정보에서 확인할 수 있습니다.
6.2 Deriving a Taxonomy from MathConverse
MathConverse에서는 수학자들이 AI 비서와 상호작용하는 다양한 스펙트럼을 관찰했습니다.
우리는 이러한 상호작용의 초기 분류 체계를 도출하고 분류 체계에 따라 각 상호작용에 주석을 달았습니다.
분류 체계를 구축하기 위해 저자 팀의 하위 집합이 각 상호 작용(즉, 사용자의 쿼리)을 수동으로 검사하고 대부분의 상호 작용이 속하는 것으로 보이는 10개의 광범위한 범주를 식별했습니다.
이러한 범주는 결과의 사용자 행동 분류 하위 섹션에 명시되어 있습니다. 10가지 범주에 속하지 않는 쿼리를 위한 추가 "기타" 버킷을 포함했습니다.
이러한 범주에 속하는 사례는 주석 작성자 간에 논의되었습니다. 그런 다음 네 명의 저자가 각 사용자 쿼리에 수동으로 주석을 달아 이러한 버킷에 넣었습니다. 주석 작성자는 상호 작용이 버킷에 속하는지 여부를 표시하고 불확실한지 여부를 지정할 수 있는 옵션을 사용하여 표시하도록 요청받았습니다. 각 상호 작용에는 단일 주석 작성자가 주석을 달았습니다. 그러나 혼란이나 불일치가 발생하는 경우 주석 작성자는 논의하고 합의된 코딩에 도달했습니다. 주석이 달린 분류법은 저장소에서 공개합니다. 주석 작성자에게 제공된 전체 지침은 분류 체계 구성에 대한 SI 추가 세부 정보에 포함되어 있습니다.
6.3 Interactive Case Studies with Experts
구조화된 대화형 평가를 통해 훌륭한 정량적 결과를 얻을 수 있지만 LLM의 기능을 깊이 이해하려면(수학 및 그 이상의 맥락에서) 인스턴스 수준 평가(Burnell et al., 2023)와 같은 자유 형식 상호 작용이 특히 중요할 수 있습니다.
여기서 우리는 GPT-4가 쉽다고 생각하는 문제와 어렵다고 생각하는 문제 사이의 경계를 찾으려고 시도하면서 평가 범위를 확장하고 싶습니다.
CheckMate를 사용한 정량적 연구에서 우리는 수학적 정확성과 인지된 유용성 사이의 밀접한 관계를 관찰했습니다. 그러나 상관관계가 인과관계는 아니므로 증명 보조 도구로서의 유용성에 대한 정보를 제공하기 위한 기반으로 이러한 모델의 더 광범위한 수학적 추론 능력을 추가로 탐구합니다.
우리는 GPT-4를 비판하기 위해 선별하려는 것이 아님을 다시 한번 강조합니다.
오히려 우리의 목표는
1) 더 나은 수학 비서 설계를 안내하고 한계를 특성화함으로써 안전하고 신뢰할 수 있는 사용에 대한 정보를 제공하기 위해 LLM을 사용한 최초의 실제 전문 수학자 대화형 사례 연구 중 하나를 제공하고,
2) 추가 대화형 평가를 위한 길을 열고,
3) 이전에 커뮤니티에 알려지지 않은 인간-컴퓨터 상호 작용 패턴을 강조합니다. 특히 상호 작용하는 인간이 해당 분야를 선도하는 전문가일 때 그렇습니다.
이 작업이 ML 엔지니어 및 연구원, 인지 과학자, 인간-컴퓨터 상호 작용 전문가, 수학자, 교육자 등에게 도움이 되기를 바랍니다.
각 사례 연구 예시에 대한 전체 상호 작용 내용은 보충 자료에 포함되어 있습니다. 정확성과 일관성을 위해 약간의 편집만 거쳐 각 사례 연구 저자의 원본 텍스트를 유지합니다.
ProofWiki 문제와의 상호 작용의 경우 더 명확하게 시각화할 수 있도록 샘플 탐색기와 함께 호스팅합니다.
먼저 채용된 전문가들이 이전 평가에서 살펴본 몇 가지 문제를 더 자세히 살펴봅니다.
구체적으로, 우리는 문제를 놀이터로 사용하여 모델이 관련 개념에 대해 얼마나 "알고" 있는지 탐색하고 어떤 상호 작용이 더 나은(또는 더 나쁜) 성능과 지원 경험을 얻을 수 있는지 추가로 특성화합니다.
CheckMate를 사용한 정량적 연구에서 가장 강력한 전반적인 성능을 보였기 때문에 챗 모드에서 GPT-4에 중점을 둡니다. 첫 번째 사례 연구는 정수론 전문가인 William Hart 박사가 제공했습니다. 두 번째는 주로 공식 수학 전문가인 Wenda Li 박사가 기고했으며 세 번째는 필즈상 수상자이자 수학 교수인 Timothy Gowers 교수가 수행했습니다.
추후 해결해야할 연구를 정리하면 다음과 같다.
- 상호작용 평가 방식 다양화: 본 연구에서는 CheckMate 플랫폼을 활용한 구조화된 평가와 전문가 사례 연구를 통한 자유 형식 평가를 수행했지만, 더 다양한 상호작용 평가 방식을 개발하고 적용하여 LLM의 능력을 더욱 포괄적으로 평가해야 합니다.
- 대수적 조작 능력 향상: LLM의 대표적인 약점 중 하나인 대수 조작 능력을 향상시키기 위한 연구가 필요합니다. 플러그인이나 하이브리드 신경 기호 접근 방식 등 다양한 방법을 통해 이를 개선할 수 있을 것입니다.
- 간결하고 명확한 답변 생성: LLM이 지나치게 장황한 답변을 생성하는 문제를 해결하고, 사용자가 이해하기 쉽고 간결한 답변을 생성하도록 유도해야 합니다.