VLM : 논문 리뷰 : What matters when building vision-language models?
Abstract
VLM에 대한 관심이 증가하고 있지만 VLM 설계에 대한 중요한 결정들이 근거가 없다.
이러한 근거 없는 결정은 어떤 선택이 성능을 향상 시켰는지 파악하기 어렵고 분야의 발전은 저해한다고 주장.
-> 이 문제를 해결하기 위해 pretrained 모델, 아키텍쳐 선택, 데이터 및 학습 방법에 대한 광범위한 실험 수행
Introduction
VLM은 다음과 같은 작업에 유용하게 쓰인다.
PDF 내의 검색
차트, 다이어 그램 설명
이미지 내 텍스트 인식
이미지 속 객체 수 세기
이를 위해 연구자들은 다음과 같은 연구를 진행함.
이미지 인코더, 강력한 오픈 대규모 언어모델
그러나 많은 설계 및 실험들이 정당화되지 않거나 매우 간략한 경우가 대부분.
이러한 상황은 모델 성능에 실제로 영향을 미치는 결정을 구별하기 어렵게 만들어서 발전에 혼란을 야기한다.
예를들어
Alayrac는 인터리브드 트랜스포머 기반 교차 어텐션을 사용하여 이미지 정보를 언어 모델에 융합하는 반면
Liu는 이미지 히든 상태 시퀀스를 텍스트 임베딩 시퀀스와 연결하고 연결된 시퀀스를 언어 모델에 입력한다.
이러한 선택은 제대로 분석되지 않았으며, 계산, 데이터 효율성 및 성능 측면에서의 절충점은 제대로 이해되지 않았다.
이에 본 연구에서는 What matters when building vision-language models?라는 질문을 던진다.
(a) 모델 아키텍처, 특히 비전 및 텍스트 양식을 융합하는 커넥터 모듈과 추론 효율성에 미치는 영향
(b) 멀티모달 훈련 절차 및 훈련 안정성에 미치는 영향
주목할 만한 결과는 다음과 같다
(a) 비전-언어 모델의 발전은 주로 사전 학습된 단일 모드 백본의 발전에 의해 주도
(b) 최근의 완전 자기 회귀 아키텍처는 교차 어텐션 아키텍처보다 성능이 우수하지만 안정적인 훈련을 위해 최적화 절차를 수정해야 함
(c) 사전 학습된 비전 백본과 텍스트 및 비전 양식을 연결하는 모듈을 조정하면 추론 시 효율성을 높이고 다운스트림 성능 저하 없이 원본 비율 및 크기의 이미지를 처리할 수 있음
(d) 이미지 처리를 수정하면 추론 비용과 다운스트림 성능 간의 균형을 조정할 수 있음
이러한 점을 바탕으로 80억개의 매개변수를 가진 기존 VLM인 Idefics2를 학습.
Idefics2는 기본 및 미세 조정 버전 모두에서 추론 효율성이 더 뛰어나면서도 다양한 벤치마크에서 동일한 크기 범주 내에서 SOTA 달성.
일부 까다로운 벤치마크에서는 Gemini 1.5 Pro의 성능과 일치
Terminology
교차 어텐션 아키텍처 : 비전 백본을 통해 인코딩된 이미지가 텍스트가 이미지 히든 상태에 교차 어텐션하는 블록을 인터리빙하여 언어 모델 내의 여러 레이어에 주입
완전 자기 회귀 아키텍처 : 비전 인코더의 출력이 텍스트 임베딩 시퀀스에 직접 연결되고, 전체 시퀀스가 언어 모델에 입력으로 전달. 따라서 언어 모델의 입력 시퀀스는 시각 토큰과 텍스트 토큰의 연결

Idefics2에 최종적으로 사용되는 완전 자기 회귀 아키텍처를 보여줌
입력 이미지는 비전 인코더에 의해 처리
결과 시각적 특징은 LLM 입력 공간에 매핑(선택적으로 풀링)되어 시각적 토큰(표준 구성에서는 64개)을 얻음
텍스트 임베딩(녹색 및 빨간색 열)의 입력 시퀀스와 연결
연결된 시퀀스는 텍스트 토큰 출력을 예측하는 언어 모델(LLM)에 공급
Exploring the design space of vision-language models
비전-언어 모델 관련 문헌에서 반복적으로 나타나는 설계 선택들을 비교하고 주요 결과를 강조
모든 실험은 6,000 스텝 동안 진행되며, 다양한 능력을 측정하는 4가지 다운스트림 벤치마크에서 4-shot 성능의 평균 점수를 보고
사용한 벤치마크
- VQAv2 (Goyal et al., 2017): 일반적인 시각적 질문 답변
- TextVQA (Singh et al., 2019): OCR 능력
- OKVQA (Marino et al., 2019): 외부 지식
- COCO (Lin et al., 2014): 캡션 생성
Are all pre-trained backbones equivalent for VLMs?
비전-언어 벤치마크 성능의 가장 큰 향상은 언어 모델을 더 나은 모델로 변경하는 데서 비롯된다는 것을 관찰함.
Chen and Wang (2022)은 비전 인코더의 크기를 늘리는 것이 언어 모델의 크기를 늘리는 것보다 더 큰 성능 향상을 가져온다고 보고
비전 인코더를 늘리면 매개변수 수 증가는 더 적지만, 성능 향상은 더 크다는 것.
EVA-CLIP-5B(Sun et al., 2023)는 SigLIP-SO400M(Zhai et al., 2023)보다 매개변수 수가 10배 더 많지만, 4개 벤치마크에서 유사한 성능
이는 EVA-CLIP-5B가 심각하게 훈련 부족일 수 있음을 시사하며, 오픈 VLM 커뮤니티에는 잘 훈련된 대규모 비전 인코더가 부족하다는 점을 인정
결론 : 고정된 매개변수 수에 대해 언어 모델 백본의 품질이 최종 VLM 성능에 미치는 영향은 비전 백본의 품질보다 더 큼
How does the fully autoregressive architecture compare to the cross-attention architecture?
완전 자기 회귀 아키텍처와 교차 어텐션 아키텍처 사이에는 제대로 된 비교가 이루어지지 않았음
본 연구에서는 성능, 매개변수 수, 추론 비용 등의 측면에서 두 아키텍처의 장단점을 고려하여 이러한 차이를 메우고자 한다.
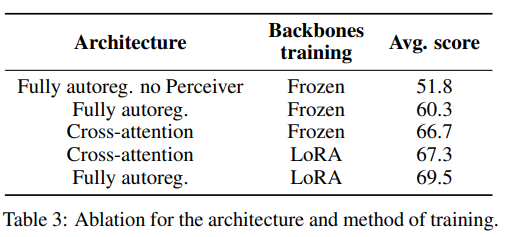
먼저 단일 모드 백본을 고정하고 새로 초기화된 매개변수만 훈련하면서 두 아키텍처를 비교
표 3에서 교차 어텐션 아키텍처가 7점 더 높은 성능을 보이는 것을 확인
총 매개변수 수 중 완전 자기 회귀 아키텍처는 약 15%, 교차 어텐션 아키텍처는 약 25%가 훈련되됨.
이렇게 낮은 비율은 훈련의 표현력을 제한하고 성능을 저해한다고 가정
이 가설을 검증하기 위해 새로 초기화된 매개변수와 사전 학습된 단일 모드 백본의 매개변수를 모두 고정 해제하여 두 아키텍처를 비교
이러한 조건에서는 완전 자기 회귀 아키텍처를 훈련하면 손실이 발산되었고, 학습률을 크게 낮추거나 다양한 구성 요소를 점진적으로 고정 해제하더라도 훈련을 안정화하는 데 성공하지 못함.
안정성 문제를 극복하기 위해 Low-Rank Adaptation (로라) 활용
사전 학습된 매개변수를 조정하고 새로 초기화된 매개변수에는 표준 전체 미세 조정을 사용
이 설정은 훈련을 훨씬 더 안정적으로 만들었고, 더 중요한 것은 완전 자기 회귀 아키텍처에서 12.9점, 교차 어텐션 아키텍처에서 0.6점의 성능 향상을 관찰.
교차 어텐션 아키텍처는 백본이 고정된 상태에서는 완전 자기 회귀 아키텍처보다 성능이 좋지만, 사전 학습된 백본에 자유도를 추가하면 성능이 떨어짐.
또한, LoRA를 사용하면 전체 미세 조정 GPU 메모리 비용의 일부만으로 단일 모드 백본을 훈련할 수 있으며, LoRA 레이어를 원래의 선형 레이어에 다시 병합하여 추론 시 추가 비용을 발생시키지 않을 수 있음.
따라서 이 연구의 나머지 부분에서는 완전 자기 회귀 아키텍처를 선택
이러한 결과는 사전 학습된 시각적 백본을 고정 해제하면 성능이 크게 저하된다고 관찰한 (Karamcheti et al., 2024)의 연구 결과와 상반된다.
- 매개변수 효율적인 미세 조정 방법을 사용하는 것이 주요 차이점 -
결론 2: 교차 어텐션 아키텍처는 단일 모드 사전 학습 백본이 고정된 경우 완전 자기 회귀 아키텍처보다 성능이 좋음.
그러나 단일 모드 백본을 훈련할 때는 완전 자기 회귀 아키텍처가 교차 어텐션 아키텍처보다 성능이 우수
결론 3: 완전 자기 회귀 아키텍처에서 사전 학습된 백본을 고정 해제하면 훈련이 발산될 수 있음.
LoRA를 활용하면 훈련에 표현력을 추가하고 안정화시킬 수 있음
Where are the efficiency gains?
최근 VLM은 일반적으로 비전 인코더의 히든 상태 전체 시퀀스를 풀링 없이 모달리티 투영 레이어로 직접 전달하여 언어 모델에 입력
이는 평균 풀링과 같은 풀링 전략을 추가하면 성능이 저하되는 것으로 밝혀진 이전 연구에 근거한다.
결과적으로 시퀀스 길이가 길어지면 훈련에 많은 계산 비용이 소요되고, 이미지와 텍스트가 인터리빙된 상황에서 학습하려면 매우 큰 컨텍스트 창을 처리할 수 있도록 언어 모델을 수정해야 하므로 어려움이 있음.
본 연구에서는 훈련 가능한 Transformer 기반 풀링 형태로 Perceiver 리샘플러(Jaegle et al., 2021; Alayrac et al., 2022; Bai et al., 2023)를 사용하여 각 이미지의 히든 상태 시퀀스 길이를 줄임.
쿼리 수(잠재 변수라고도 함)는 풀링 후 결과 시각 토큰 수에 해당
학습된 풀링은 두 가지 방식으로 효과적이라는 것을 확인
평균적으로 성능이 8.5점 향상되고 각 이미지에 필요한 시각 토큰 수가 729개에서 64개로 줄어듬

시각 토큰이 많을수록 성능이 높아진다고 했지만, 본 연구에서는 64개 이상의 시각 토큰을 사용해도 성능 향상이 없었음
결론 4: 학습된 풀링으로 시각 토큰 수를 줄이면 다운스트림 작업 성능을 향상시키는 동시에 훈련 및 추론 시 계산 효율성이 크게 향상
SigLIP과 같은 비전 인코더는 일반적으로 고정 크기의 정사각형 이미지로 훈련됨
이미지 크기를 조정하면 원본 종횡비가 변경되어 긴 텍스트를 읽어야 하는 작업에 문제가 될 수 있음
또한 단일 해상도 크기로 훈련하면 낮은 해상도는 중요한 시각적 세부 정보를 누락하고 높은 해상도는 훈련 및 추론 효율성이 떨어지는 등의 제약이 발생
모델이 다양한 해상도로 이미지를 인코딩하도록 허용하면 사용자가 각 이미지에 대해 얼마나 많은 계산량을 사용할지 결정할 수 있음.

이미지 크기를 조정하거나 종횡비를 수정하지 않고 이미지 패치를 비전 인코더에 전달
SigLIP은 고정 크기의 저해상도 정사각형 이미지로 훈련되었으므로 더 높은 해상도를 허용하기 위해 사전 학습된 위치 임베딩을 보간하고 LoRA 매개변수로 비전 인코더를 훈련하여 이러한 수정 사항에 적응
결과에 따르면 종횡비 유지 전략은 다운스트림 작업의 성능 수준을 유지하면서 훈련 및 추론 중에 계산 유연성을 확보할 수 있음을 나타냄
특히 이미지를 동일한 고해상도로 크기를 조정할 필요가 없으므로 GPU 메모리를 절약하고 필요한 해상도로 이미지를 처리할 수 있음
결론 5 : 고정 크기 정사각형 이미지에서 사전 학습된 비전 인코더를 이미지의 원래 종횡비와 해상도를 유지하도록 조정해도 성능이 저하되지 않으면서 훈련 및 추론 속도를 높이고 메모리를 줄일 수 있음
How can one trade compute for performance?
(McKinzie et al., 2024) 연구에서는 모델의 구조를 변경하지 않고도 이미지를 하위 이미지로 분할하여 다운스트림 성능을 향상시킬 수 있음을 보여줌.
이미지를 여러 개의 하위 이미지(예: 4개의 동일한 하위 이미지)로 분할한 다음, 원본 이미지와 연결하여 5개 이미지 시퀀스를 형성
또한, 하위 이미지는 원본 이미지 크기로 조정됩니다. 그러나 이 전략은 이미지를 인코딩하는 데 훨씬 더 많은 토큰이 필요하다는 단점이 있음.
본 연구에서는 명령 미세 조정 단계에서 이 전략을 채택
각 단일 이미지는 4개의 자른 이미지와 원본 이미지로 구성된 5개 이미지 목록이 됨.
이렇게 하면 추론 시 모델이 독립형 이미지(이미지당 64개의 시각적 토큰)와 인위적으로 증강된 이미지(이미지당 총 320개의 시각적 토큰)를 모두 처리할 수 있음
이 전략은 이미지에서 텍스트를 추출하기 위해 충분히 높은 해상도가 필요한 TextVQA 및 DocVQA와 같은 벤치마크에 특히 유용
또한, 훈련 샘플의 50%에만 이미지 분할을 적용했을 때(샘플의 100% 대신) 이미지 분할이 제공하는 성능 향상에 영향을 미치지 않는다는 것을 확인
놀랍게도 평가 시 하위 이미지(및 독립 실행형 이미지)의 해상도를 높이는 것은 이미지 분할만으로 얻을 수 있는 성능 향상에 비해 미미한 성능 향상만 제공한다는 것을 발견
TextVQA 검증 세트에서 하위 이미지의 해상도를 최대로 높였을 때 73.6% vs 하위 이미지 해상도를 높이지 않았을 때 73.0%, DocVQA 검증 세트에서 각각 72.7 vs 72.9 ANLS
결론 6: 훈련 중에 이미지를 하위 이미지로 분할하면 추론 중에 계산 효율성 대비 더 많은 성능을 얻을 수 있음.
성능 향상은 이미지에서 텍스트를 읽는 작업에서 특히 두드러진다.
Idefics2 - an open state-of-the-art vision-language foundation model
Idefics2는 80억 개의 매개변수를 가진 오픈 소스 비전-언어 모델
SigLIP-SO400M 및 Mistral-7B-v0.1을 기반으로 이미지-텍스트 문서, 이미지-텍스트 쌍, PDF 문서 3가지 유형의 데이터에 대해 사전 학습
사전 학습은 두 단계로 진행
첫 번째 단계에서는 최대 이미지 해상도를 384픽셀로 제한하여 대규모 훈련을 수행하고,
두 번째 단계에서는 PDF 문서를 도입하여 최대 980픽셀의 고해상도에서 훈련
Idefics2는 다른 오픈 VLM에 비해 훨씬 더 많은 훈련 데이터(약 15억 개 이미지 및 2250억 개 텍스트 토큰)를 사용하며, VQAv2, TextVQA, OKVQA, COCO 벤치마크에서 다른 최신 기본 VLM과 비교하여 우수한 성능을 보임.
특히 이미지 내 텍스트 읽기 능력이 뛰어남.
명령 미세 조정 단계에서는 50개의 비전-언어 데이터셋과 텍스트 전용 명령 데이터셋으로 구성된 The Cauldron을 활용하여 모델을 학습
이 단계에서 이미지 분할 전략과 다양한 과적합 방지 기술을 사용하여 모델 성능을 향상시키고 안정성을 확보
MMMU, MathVista, TextVQA, MMBench 벤치마크에서 Idefics2는 동급 크기의 다른 VLM보다 우수한 성능을 보이며, 4배 더 큰 모델 또는 Gemini 1.5 Pro와 같은 클로즈드 소스 모델과 비슷한 수준의 성능을 달성
마지막으로 채팅 시나리오에 맞춰 Idefics2를 최적화하기 위해 LLaVA-Conv 및 ShareGPT4V와 같은 대화 데이터로 추가 학습을 진행
이를 통해 Idefics2-chatty 버전은 짧은 답변을 넘어 사람들이 선호하는 긴 답변을 생성할 수 있게 됨.
Conclusion
본 연구에서는 VLM 관련 문헌에서 일반적으로 선택되는 사항들을 재검토하고 통제된 실험 환경에서 이러한 선택들을 엄격하게 비교
본 연구의 결과는 다양한 아키텍처의 효과성, 성능/추론 비용 간의 상충 관계, 그리고 훈련 안정성에 대한 내용을 다룸.
이러한 결과를 바탕으로 80억 개의 매개변수를 가진 오픈 비전-언어 모델인 Idefics2를 학습.
Idefics2는 동급 모델 중 다양한 벤치마크에서 최첨단 성능을 보이며 추론 효율성이 훨씬 뛰어남.
연구 결과와 모델 및 훈련 데이터셋을 공개함으로써 VLM의 지속적인 발전과 복잡한 실제 문제 해결에 VLM을 적용하는 데 기여.
결론모음
결론 1 : 고정된 매개변수 수에 대해 언어 모델 백본의 품질이 최종 VLM 성능에 미치는 영향은 비전 백본의 품질보다 더 큼
결론 2: 교차 어텐션 아키텍처는 단일 모드 사전 학습 백본이 고정된 경우 완전 자기 회귀 아키텍처보다 성능이 좋음.
그러나 단일 모드 백본을 훈련할 때는 완전 자기 회귀 아키텍처가 교차 어텐션 아키텍처보다 성능이 우수
결론 3: 완전 자기 회귀 아키텍처에서 사전 학습된 백본을 고정 해제하면 훈련이 발산될 수 있음.
LoRA를 활용하면 훈련에 표현력을 추가하고 안정화시킬 수 있음
결론 4: 학습된 풀링으로 시각 토큰 수를 줄이면 다운스트림 작업 성능을 향상시키는 동시에 훈련 및 추론 시 계산 효율성이 크게 향상
결론 5 : 고정 크기 정사각형 이미지에서 사전 학습된 비전 인코더를 이미지의 원래 종횡비와 해상도를 유지하도록 조정해도 성능이 저하되지 않으면서 훈련 및 추론 속도를 높이고 메모리를 줄일 수 있음
결론 6: 훈련 중에 이미지를 하위 이미지로 분할하면 추론 중에 계산 효율성 대비 더 많은 성능을 얻을 수 있음.
성능 향상은 이미지에서 텍스트를 읽는 작업에서 특히 두드러진다.