VLM : 논문리뷰 : Through the Magnifying Glass: Adaptive Perception Magnification for Hallucination-Free VLM Decoding
논문 학습 노트: Through the Magnifying Glass: Adaptive Perception Magnification for Hallucination-Free VLM Decoding
Purpose of the Paper
- 기존 vision-language models (VLMs)는 visual hallucination (visual input에 기반하지 않은 부정확한 응답 생성) 문제를 겪음.
- 기존의 hallucination 완화 방법들은 language reasoning 능력을 저하시키는 trade-off가 존재.
- 본 연구는 language reasoning 능력을 보존하면서 visual perception을 향상시켜 hallucination을 줄이는 새로운 visual decoding 방법인 Perception Magnifier (PM) 를 제안.
- PM은 inference attention을 기반으로 relevant visual regions을 반복적으로 확대하여 VLM이 fine-grained visual details에 집중하도록 유도.
Key Contributions
- Perception Magnifier (PM): hallucination 완화를 위한 novel visual decoding technique.
- Decoding 과정에서 adaptively visual regions of interest를 magnifying.
- Attention Grounding Method:
- Iteratively aggregates attentions across layers.
- Perception map 생성, region magnification during decoding을 guide.
- Novelty : Attention을 기반으로 visual input 을 조작하는 방법
- PM은 추가적인 finetuning 없이 visual faithfulness를 향상시키고, language reasoning 능력을 보존함.
Experimental Highlights
- Datasets: MME, POPE, LLaVA-Bench 사용.
- Metrics:
- Hallucination benchmarks: MME, POPE
- GPT-4o-assisted assessments: reference-based, vision-based settings
- Baselines: Greedy decoding, contrastive decoding-based methods (VCD, VDD, IBD, PAI, ICD, SID), beam search, OPERA, API, ViCrop.
- Results:
- PM은 question answering 및 open-end generation에서 superior hallucination mitigation performance를 달성.
- Reasoning capabilities를 보존하면서 language generation을 향상.
- Extensive ablations를 통해 각 component의 contribution을 분석.
Method MME Score Total* POPE Accuracy AVG* PM (Ours) 683.33 86.70 ... (Baselines) ... ...
Limitations and Future Work
- Limitations:
- Magnification 과정에서 local shape properties가 왜곡될 수 있음 (e.g., precise shape or length recognition tasks).
- Interleaved VLMs with visual tokens corresponding to all patch features에 적용 가능하며, non-trivial correlation을 가진 VLM에는 적용이 복잡할 수 있음.
- Future Work:
- Perception map construction 또는 post-processing techniques 개선을 통해 structure-preserving magnification 달성.
- Input magnification의 decision process 최적화.
- Salient tokens 식별 개선.
- Magnification-based approach를 broader range of VLM architectures로 확장.
Overall Summary
본 논문은 vision-language models (VLMs)의 hallucination 문제를 해결하기 위해 Perception Magnifier (PM)라는 새로운 visual decoding 방법을 제안한다. PM은 inference attention을 기반으로 relevant visual regions을 반복적으로 확대하여 VLM이 fine-grained visual details에 집중하도록 유도한다. 실험 결과, PM은 hallucination을 효과적으로 줄이고, language reasoning 능력은 유지하면서, question answering과 open-ended generation 모두에서 기존 방법들을 능가하는 성능을 보여주었다. 이 연구는 VLM의 신뢰성과 정확성을 향상시키는 데 기여할 수 있다.
쉬운 설명: 이 논문은 큰 언어 모델(LLM)이 이미지를 보고 엉뚱한 소리를 하는 현상("hallucination")을 줄이기 위해, "돋보기"(Magnifier)처럼 이미지의 중요한 부분을 확대해서 보여주는 방법을 제안합니다. 마치 사람이 헷갈리는 부분을 돋보기로 자세히 보듯이, 모델도 이미지의 특정 부분을 더 자세히 볼 수 있게 해주는 거죠. 이 방법은 모델이 이미지를 더 잘 이해하고, 질문에 더 정확하게 답하도록 도와줍니다.
Abstract
기존의 vision-language models (VLMs)은 종종 visual hallucination 현상으로 어려움을 겪습니다. 이는 생성된 응답에 visual input에 근거하지 않은 부정확성이 포함되는 현상입니다. model finetuning 없이 이 문제를 해결하기 위한 노력은 주로 language bias를 줄이거나, bias를 contrastively하게 줄이거나, decoding 중에 visual embedding의 가중치를 증폭시켜 hallucination을 완화하는 방식으로 이루어졌습니다. 그러나 이러한 접근 방식은 language reasoning 능력을 손상시키는 대가로 visual perception을 향상시킵니다.
본 연구에서는 Perception Magnifier (PM)를 제안합니다. 이는 attention을 기반으로 relevant visual tokens를 반복적으로 분리하고 해당 영역을 확대하여, decoding 중에 model이 fine-grained visual details에 집중하도록 유도하는 새로운 visual decoding 방법입니다. 구체적으로, 각 decoding 단계에서 structural 및 contextual information을 보존하면서 critical regions을 확대함으로써, PM은 VLM이 visual input에 대한 면밀한 검토를 강화하여 보다 정확하고 충실한 응답을 생성할 수 있도록 합니다.
광범위한 실험 결과는 PM이 우수한 hallucination 완화를 달성할 뿐만 아니라 강력한 reasoning 능력을 보존하면서 language generation을 향상시킨다는 것을 보여줍니다.
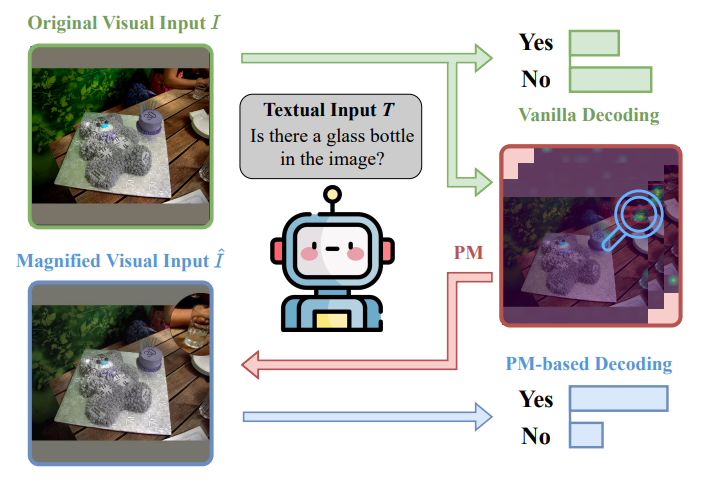
Figure 1.
우리는 Perception Magnifier (PM)를 제안합니다. 이는 inference attention patterns을 기반으로 key visual regions을 찾아 확대하여 더 fine-grained details로 feature 처리를 가능하게 하는 hallucination-mitigating decoding framework입니다. 예를 들어, PM은 오른쪽 상단 모서리에 attention pattern을 위치시키고 유리병(glass bottle)을 확대하여 VLM이 더 잘 인식할 수 있도록 합니다.
1. Introduction
large vision-language models (VLMs)의 발전은 computer vision과 natural language processing의 통합에 혁명을 일으켜 visual modality와 textual modality 간의 원활한 상호 작용을 가능하게 했습니다. 이러한 models은 복잡한 visual inputs을 일관되고 contextually relevant한 textual descriptions으로 효과적으로 변환하여 광범위한 applications에서 발전을 주도합니다. model architectures, training methodologies, 다양한 multimodal datasets의 혁신에 힘입어, large VLMs는 계속해서 기능과 적응성을 확장하여 현대 AI systems에서 foundational tools로서의 역할을 공고히 하고 있습니다.
뛰어난 능력에도 불구하고, VLMs는 hallucination에 취약합니다. 이는 생성된 outputs이 visual input과 일치하지 않아 부정확하거나 불충실한 내용을 포함하는 현상입니다. 일부 hallucinations은 VLMs가 pre-trained large language models (LLMs)와 동일한 architecture를 채택하고 그들의 본질적인 한계를 상속받아 발생하지만, visual and language features의 통합은 language priors에 대한 과도한 의존이나 제한된 visual representation capacity로 이어질 수도 있습니다.
hallucination을 완화하기 위해 debiased dataset 또는 enlarged visual resolution과 같은 training-end techniques부터 hallucination 제거를 위한 post-processing 및 specialized decoding techniques와 같은 inference end methods까지 다양한 접근 방식이 제안되었습니다. 이 중 hallucination-mitigation decoding methods는 model의 추가적인 finetuning 없이 visual faithfulness를 향상시키는 능력으로 인해 큰 주목을 받았습니다. 이러한 methods는 주로 model reasoning 중에 visual information의 기여도를 높여 hallucination을 완화하는 것을 목표로 합니다. 이러한 향상은 visual embeddings의 가중치를 증가시켜 명시적으로 달성하거나, vague, absent, 또는 confused visual interpretations를 나타내는 outputs에 contrastively하게 페널티를 주는 방식으로 암시적으로 달성할 수 있습니다.
그러나 이러한 methods는 불충분한 visual resolution으로 인해 object misinterpretation이 발생하는 시나리오에서 한계에 직면합니다. 동시 연구에서는 cropped key visual region을 추가 input으로 resizing하는 방법을 탐구하지만, 이는 image에서 structural and contextual information을 지우고 여러 input images를 제공하여 VLM을 혼란스럽게 합니다.
VLMs가 inference 중에 많은 visual regions에 marginal attention만 할당한다는 관찰에서 영감을 받아, 우리는 Perception Magnifier (PM)를 제안합니다. 이는 spatial resolution을 adaptively하게 조절하여 key visual regions을 더 자세히 처리하고 덜 relevant areas는 압축하는 visual decoding approach입니다(Fig. 1 참조). decoding 중에 visual input을 refining함으로써 PM은 image의 structural visual context나 VLM의 intrinsic reasoning ability를 손상시키지 않으면서 fine-grained details에 대한 attention을 향상시킵니다. input images에 static modifications를 적용하는 methods와 달리, PM은 decoding throughout에서 image representation을 dynamically하게 조정하여 보다 효과적인 open-ended generation을 가능하게 합니다.
구체적으로, 우리는 deep layers에 걸쳐 generation에 relevant한 high-attention visual tokens를 반복적으로 식별하고 attention scores를 token-level heatmap으로 aggregate하는 gradient-free approach를 도입합니다. 이 heatmap은 coverage와 smoothness를 향상시키기 위해 post-processed된 다음, upsampled되어 pixel-level perception map을 구성합니다. 이 map의 guidance를 받아 PM은 relevant regions을 확대하고 덜 critical areas는 압축하여 visual input을 refining합니다. 이는 resampling process로 구현됩니다. 이러한 dynamic adjustment를 통해 model은 decoding throughout에서 focus를 반복적으로 refine할 수 있으므로 language reasoning을 방해하지 않으면서 향상된 visual faithfulness를 보장합니다.
PM은 unified visual sampling을 사용하는 interleaved VLM에 광범위하게 적용 가능합니다. hallucination benchmarks에 대한 실험과 reference-based and vision-based settings 모두에서 GPT-4o-assisted assessments를 통해, PM은 question answering 및 open-end generation에서 우수한 hallucination mitigation performance를 보일 뿐만 아니라 VLMs의 reasoning capabilities를 보존한다는 것을 보여줍니다. 또한, 우리는 우리 method의 각 component의 contributions를 분석하기 위해 광범위한 ablations를 제공합니다. 우리의 contributions는 다음과 같이 요약할 수 있습니다.
- 우리는 decoding 중에 interest visual regions을 adaptively하게 확대하여 hallucination을 완화하는 decoding technique인 Perception Magnifier (PM)를 제안합니다.
- 우리는 layers에 걸쳐 attentions를 반복적으로 aggregate하여 perception map을 생성하는 새로운 attention grounding method를 도입합니다. 이 map은 decoding 중 region magnification을 guide합니다.
- 우리는 광범위한 evaluations를 통해 experiments를 수행하여 reasoning capabilities를 보존하면서 hallucination을 완화하는 PM의 effectiveness를 입증합니다.
1. Introduction (정리 노트) - AI 연구자를 위한 핵심 요약
문제 제기:
- 기존 VLMs는 visual hallucination 문제 (생성된 텍스트가 이미지와 불일치)를 겪음.
- 이는 language bias에 대한 과도한 의존, 제한적인 visual representation capacity 등에서 기인함.
- 기존 hallucination 완화 방법들은 language reasoning 능력을 저하시키거나, structural/contextual information을 손상시키는 한계 존재.
제안 (Perception Magnifier, PM):
- 핵심 아이디어: inference attention patterns 기반으로 key visual regions을 찾아 확대, fine-grained details에 집중하는 visual decoding 방법.
- 동작 방식:
- Gradient-free 방식으로 high-attention visual tokens 식별.
- Token-level heatmap 생성 후, pixel-level perception map으로 upsampling.
- Perception map 기반으로 relevant regions 확대, less relevant regions 압축 (resampling).
- Decoding 과정 전반에 걸쳐 반복적으로 visual input refinement.
- 기존 방법과의 차별성:
- Static modification (e.g., 단순 resizing)이 아닌, dynamic adjustment를 통해 open-ended generation 성능 향상.
- Structural visual context, VLM의 reasoning ability 보존.
실험 및 결과:
- Hallucination benchmarks, GPT-4o-assisted assessments에서 우수한 성능 입증.
- Reasoning capabilities 보존 확인.
Contribution:
- Decoding 중 visual regions of interest를 adaptively하게 확대하는 PM 제안.
- Perception map 생성을 위한 새로운 attention grounding method 도입.
- 실험을 통해 PM의 hallucination 완화 및 reasoning capabilities 보존 효과 입증.
쉬운 설명 :
VLMs는 이미지와 텍스트를 모두 이해하는 AI 모델인데, 가끔 이미지를 잘못 이해하고 엉뚱한 텍스트를 생성하는 "환각" 현상(hallucination)을 일으킵니다. 기존에는 이 문제를 해결하기 위해 모델을 추가 학습(finetuning)하거나, 텍스트 생성 시 visual 정보의 비중을 높이는 방법을 사용했는데, 이는 모델의 언어 이해 능력을 떨어뜨리거나 이미지의 전체적인 맥락을 놓치는 문제가 있었습니다.
이 논문에서는 "Perception Magnifier (PM)"라는 새로운 방법을 제안합니다. PM은 모델이 이미지에서 "중요하다고 생각하는 부분"을 찾아서 확대하고, "덜 중요하다고 생각하는 부분"은 압축하는 방식으로 작동합니다. 비유하자면, 사람이 어떤 그림을 볼 때 특정 부분에 집중하고 나머지는 대충 보는 것과 비슷합니다. PM은 이러한 과정을 모델이 텍스트를 생성하는 동안 반복적으로 수행하여, 이미지의 세부적인 내용(fine-grained details)을 놓치지 않으면서도 전체적인 맥락(structural visual context)을 유지하도록 돕습니다.
결과적으로, PM은 기존 방법의 단점을 극복하고, 모델이 이미지를 더 정확하게 이해하고, 더 정확한 텍스트를 생성하도록 돕습니다.
2. Related Work
2.1. Vision-Language Models
Computational resources의 scaling up과 large-scale data의 가용성은 pre-training 및 instruction tuning techniques의 발전을 이끌었고, human-like text를 생성하고 다양한 tasks에서 complex reasoning을 수행할 수 있는 수많은 large language models (LLMs)의 등장을 가능하게 했습니다. LLMs의 발전을 기반으로, 많은 vision-language models (VLMs)가 connection modules를 사용하여 powerful language models을 vision encoders와 통합함으로써 개발되었습니다.
cross-attention mechanisms과 projector-based token concatenation이 초기 연구에서 탐구되었지만, 현대 models은 일반적으로 visual and textual features를 정렬하는 데 있어 단순성과 효율성을 위해 후자를 채택합니다. 이러한 VLMs는 image features를 text modality와 정렬하여 기존 LLMs의 힘을 활용하지만, autoregressive nature와 visual model capabilities의 한계는 여전히 hallucination 문제로 이어집니다.
2.2. Hallucination in Vision-Language Models
VLMs는 insufficient context attention 및 capability misalignment으로 인해 LLM backbones에서 상속된 hallucination 외에도, language decoder가 visual tokens보다 preceding textual tokens에 크게 의존할 수 있는 language bias와 같은 multimodal nature에 고유한 문제에 직면합니다.
이를 해결하기 위해, prompting input images를 하거나 visual tokens의 influence를 증폭시켜 visual information의 역할을 강화하는 다양한 methods가 제안되었습니다. VLMs는 또한 vision encoders 또는 connection modules의 limitations으로 인해 hallucination을 일으킵니다. 이전 연구에서는 visual tokenization resolution을 높이거나 이러한 modules의 capacity를 개선하여 이 문제를 해결했습니다.
Hallucination을 제어하려는 노력은 data 측면에도 초점을 맞추어 bias를 완화하고, contrastive learning을 위해 biased samples를 생성하고, hallucination을 평가하는 methods를 개발했으며, hallucination을 정량화하기 위한 다양한 metrics 및 algorithms으로 지원되었습니다. Post-processing techniques도 visually ungrounded outputs를 식별하여 hallucinations를 제거하기 위해 제안되었습니다.
이러한 approaches는 여러 각도에서 hallucination을 다루지만, resolution을 높이는 것 이상으로 visual recognition capabilities를 향상시키는 데 초점을 맞춘 methods는 거의 없습니다. 대신, 우리는 input images에서 fine-grained details를 효과적으로 캡처하기 위해 magnifier를 사용하여 VLMs를 지원하는 새로운 approach를 제안합니다. 동시적이지만 약간 더 이른 연구인 ViCrop은 attention maps를 기반으로 key visual bounding box를 cropping and resizing하여 additional inputs으로 사용하는 유사한 idea를 채택합니다. 그러나 이는 image structure의 integrity를 파괴하고 spatial awareness가 필요한 경우 실패할 수 있는 반면, 우리 method는 key regions을 확대하면서 덜 relevant areas를 압축하여 visual input structure를 보존합니다.
2.3. Hallucination Mitigation Decoding Strategies
Decoding strategies는 model이 next text token을 생성하는 방법을 결정하며, beam search와 같은 methods는 추가적인 fine-tuning 없이 higher-quality text generation을 가능하게 합니다. hallucination control의 context에서, contrastive decoding (CD)은 larger expert LMs가 선호하는 patterns를 증폭시키면서 hallucination에 더 취약한 biased output(일반적으로 smaller amateur LMs에서 파생됨)을 억제하여 output logits를 최적화하는 인기 있는 approach입니다. DoLa는 expert LMs의 early-exit logits를 biased output으로 취급하여 효율적인 CD formulation을 도입했습니다.
CD 외에도, OPERA는 specific aggregation tokens에 과도하게 의존하는 beam outputs에 페널티를 주어 LMs에서 hallucination을 완화합니다. VLMs의 경우, VCD는 noisy image inputs으로 생성된 outputs를 biased outputs로 정의하여 CD를 확장합니다. 후속 연구에서는 image inputs 없이 파생된 logits, key visual tokens 제외, finetuning 또는 prompt-engineering을 통해 hallucinative outputs 생성 등 다양한 biased output designs를 탐구했습니다.
다른 methods는 model에서 visual tokens의 weight를 늘리거나 external detector를 사용하여 focal views를 검색하여 expert outputs를 향상시키는 것을 목표로 합니다. [33]은 entropy-weighted strategy를 사용하여 multiple visually biased samples의 outputs를 fusing하여 VCD를 더욱 refine합니다. 이러한 decoding methods는 덜 visually grounded outputs에 페널티를 주어 hallucinations를 효과적으로 줄이지만, 이를 단순히 'bias'로 취급하는 것은 language-driven contexts에서 logical inferences를 형성하고 coherence를 유지하는 model의 ability를 손상시킬 위험이 있습니다. 대신, 우리 method는 relevant image regions을 adaptively하게 확대하여 visual faithfulness를 향상시키면서 VLMs의 reasoning and language capabilities를 보존함으로써 hallucination을 완화합니다.
2. Related Work (정리 노트) - AI 연구자를 위한 핵심 요약
2.1. Vision-Language Models:
- VLMs는 LLMs 발전에 기반, vision encoders와 language models를 connection modules (주로 projector-based token concatenation)로 연결.
- Autoregressive 특성과 visual model 한계로 hallucination 문제 발생. (당연한 내용)
2.2. Hallucination in Vision-Language Models:
- Hallucination 원인:
- LLM backbone에서 상속된 문제 (e.g., insufficient context attention).
- VLM 고유 문제: language bias (language decoder가 visual tokens보다 textual tokens에 더 의존).
- Vision encoders/connection modules의 한계.
- 기존 Hallucination 해결 노력:
- Training-end: debiased dataset, visual resolution 증가.
- Inference-end: post-processing, specialized decoding techniques (visual information 강화).
- Data 측면: bias 완화, biased samples 생성 (contrastive learning), hallucination 평가 methods 개발.
- 이 논문의 차별점: 단순 resolution 증가를 넘어, "magnifier"를 통해 fine-grained details를 포착하는 새로운 접근 방식 제시. (ViCrop과의 비교를 통해 차별성 강조)
2.3. Hallucination Mitigation Decoding Strategies:
- Decoding strategies: model이 next text token을 생성하는 방법 (e.g., beam search).
- Hallucination control을 위한 Contrastive Decoding (CD):
- Larger expert LM 선호 패턴 증폭, smaller amateur LM 기반 biased output 억제.
- DoLa: expert LM의 early-exit logits를 biased output으로 활용.
- VLM을 위한 CD 확장 (VCD): noisy image inputs으로 생성된 outputs를 biased outputs로 정의.
- 다양한 biased output designs 연구 (e.g., image inputs 없는 logits, key visual tokens 제외).
- 기타 methods: visual tokens 가중치 증가, external detector 활용 focal views 검색.
- 이 논문과 기존 decoding 방법들과의 차이점: 단순히 덜 visually grounded outputs에 페널티를 주는 것을 넘어, relevant image regions을 adaptively하게 확대하여 visual faithfulness와 reasoning/language capabilities를 모두 보존.
쉬운 설명 :
2.1. Vision-Language Models:
VLMs는 이미지와 텍스트를 모두 다루는 AI 모델인데, 큰 언어 모델(LLMs)에 이미지 인식 기능(vision encoders)을 연결해서 만들어요. 연결 방식은 주로 효율적인 방법을 사용하죠. 하지만 VLMs는 텍스트를 순차적으로 생성하고, 이미지 인식 기능에 한계가 있어서 "환각" 현상이 발생할 수 있습니다.
2.2. Hallucination in Vision-Language Models:
VLMs의 "환각"은 언어 모델 자체의 문제(예: 문맥 파악 부족)뿐만 아니라, 텍스트 생성 시 이미지 정보보다 기존 텍스트에 더 의존하는 경향(language bias), 이미지 인식 기능의 한계 때문에 발생합니다.
이 문제를 해결하기 위해,
- 학습 데이터 개선 (debiased dataset), 이미지 해상도 높이기
- 텍스트 생성 후 처리(post-processing), 특별한 텍스트 생성 기술(visual information 강화)
- 데이터 자체를 조작(bias 완화, contrastive learning용 데이터 생성), 환각 평가 방법 개발 등 다양한 노력이 있었습니다.
이 논문은 단순히 이미지 해상도를 높이는 것 대신, "확대경(magnifier)"을 사용해서 이미지의 중요한 부분을 자세히 보도록 하는 새로운 방법을 제시합니다. (비슷한 시기 연구인 ViCrop과 비교하며 차별점을 강조!)
2.3. Hallucination Mitigation Decoding Strategies:
"Decoding strategies"는 AI 모델이 다음에 어떤 단어를 생성할지 결정하는 방법입니다 (예: beam search). "환각"을 줄이기 위해 "Contrastive Decoding (CD)"이라는 방법이 많이 쓰이는데, 이는 더 똑똑한 모델(expert LM)이 선호하는 패턴은 강화하고, 덜 똑똑한 모델(amateur LM)에서 나오는 "환각" 가능성이 높은 출력은 억제하는 방식입니다.
VLMs를 위해 CD를 확장한 방법(VCD)은 이미지를 흐릿하게(noisy) 만들었을 때 생성되는 텍스트를 "나쁜 출력"으로 간주합니다. 그 외에도 이미지 정보 없이 생성된 텍스트, 중요한 이미지 정보(key visual tokens)를 제외하고 생성된 텍스트 등 다양한 "나쁜 출력"을 정의하는 연구가 진행되었습니다.
다른 방법들은 이미지 정보의 중요도를 높이거나, 외부 도구(external detector)를 사용해서 이미지에서 중요한 부분을 찾는 방식을 사용합니다.
이 논문은 단순히 "나쁜 출력"에 벌점을 주는 것이 아니라, 이미지에서 중요한 부분을 확대해서 보여줌으로써 모델이 이미지를 더 잘 이해하고, 텍스트 생성 능력도 유지하는 것을 목표로 합니다.
3. Methods
전통적인 autoregressive VLMs에서, model은 각 decoding step에서 image I 와 text sequence T<sub>i</sub> 를 গ্রহণ করে। 이 input이 주어지면, model은 다음 token T<sub>i+1</sub> 을 예측합니다:
O<sub>i+1</sub> = VLM(I, T<sub>i</sub>)
여기서 O<sub>i+1</sub> 은 vocabulary에 대한 output logits을 나타냅니다. 그런 다음 model은 softmax function을 적용하여 probability distribution을 얻습니다:
P(T<sub>i+1</sub> | I, T<sub>i</sub>) = softmax(O<sub>i+1</sub>)
그런 다음 sampling strategy가 적용되어 final token을 결정합니다. 예를 들어, greedy decoding에서는 가장 높은 probability를 가진 token이 선택됩니다:
T<sub>i+1</sub> = arg max P(T<sub>i+1</sub> | I, T<sub>i</sub>)
이 예측된 token은 sequence에 추가되고, end-of-sequence (EOS) token이 생성될 때까지 process가 반복됩니다.
본 논문에서는 Perception Magnifier (PM)를 제안합니다. 이는 key visual regions을 반복적으로 식별하고 강화하여 보다 효과적인 token generation을 위해 visual input을 refine하는 새로운 approach입니다. Fig. 2에서 볼 수 있듯이, PM은 highly attended visual tokens를 반복적으로 식별하고, block하고, 더 이상 significant attention을 받는 tokens이 없을 때까지 sequence를 re-forward 합니다. 그런 다음 식별된 tokens는 attention scores를 기반으로 aggregate되어 perception map P 를 구성합니다. 이 map은 sampling process를 통해 original image I 를 확대하는 데 사용됩니다.
Î<sub>i</sub> = T(I, P)
Refined image Î<sub>i</sub> 는 현재 decoding step에서 다음 token을 생성하기 위한 refined visual input으로 사용됩니다.
T<sub>i+1</sub> = VLM(Î<sub>i</sub>, T<sub>i</sub>)
다음 섹션에서는 제안된 PM method에서 perception map construction, perception map의 coverage를 개선하기 위한 iterative refinement, attention-based magnification process에 대해 자세히 설명합니다.
3.1. Perception Map Construction
이 섹션에서는 먼저 magnifier를 guide하기 위한 naive perception map을 구성하는 간단한 method를 소개합니다. 이 method는 patchified visual embeddings가 textual tokens와 함께 input sequence에 통합되는 interleaved architecture를 채택하는 모든 mainstream VLMs에 적용 가능합니다. 이러한 models은 system prompts, visual representations, user queries 및 generated responses와 같은 past textual interactions를 backbone LM을 위한 unified sequence로 interleaving하여 정보를 처리합니다.
Input sequence가 형성되면, transformer는 self-attention을 통해 이를 처리합니다. single attention head의 경우, token x<sub>i</sub> 에서 x<sub>j</sub> 로의 attention weight는 다음과 같이 계산됩니다:
Attn<sub>i,j</sub> = Softmax( Q<sub>i</sub>K<sup>T</sup><sub>j</sub> / √d<sub>k</sub> )
여기서 Q<sub>i</sub> 와 K<sub>j</sub> 는 각각 tokens x<sub>i</sub> 와 x<sub>j</sub> 의 query and key vectors이고, d<sub>k</sub> 는 key dimension입니다. 그런 다음 해당 value V<sub>j</sub> 에 Attn<sub>i,j</sub> 를 곱하여 x<sub>i</sub> 의 hidden representation을 얻습니다:
z<sub>i</sub> = Σ<sub>j</sub> Attn<sub>i,j</sub> V<sub>j</sub>
실제로 transformers는 multiple layers and heads를 stack하여 different levels에서 attention weights를 생성합니다. 이러한 attention patterns는 multi-dimensional tensor로 표현될 수 있습니다:
Attn ∈ ℝ<sup>N<sub>l</sub>,N<sub>h</sub>,H,W</sup>
여기서 N<sub>l</sub> 과 N<sub>h</sub> 는 각각 layers and attention heads의 수를 나타내고, H × W 는 visual tokens의 spatial dimensions를 나타내며, 2D feature map으로 reshape될 수 있습니다. PM은 cached Attn을 활용하여 model attention을 기반으로 most relevant visual regions를 강조하는 token-level heatmap을 구성합니다.
이전 연구에서 indicated된 바와 같이, deep networks는 주로 earlier layers에서 visual information을 aggregate and interpret한 후, later layers에서 이러한 representations를 활용합니다. 또한, intermediate features가 이미 competitive performance를 낼 수 있다는 것이 관찰되었습니다. 이러한 findings에 따라, 우리는 empirically하게 middle-layer attention이 종종 final layers의 attention보다 relevant objects를 더 정확하게 localize한다는 점에 주목합니다. 따라서, 우리는 layers l ≥ L 에서 self-attention matrices를 aggregating하고 모든 heads h 에 대해 max pooling을 적용하여 perception map을 구성하여 more visually important regions의 영향을 강조합니다. 공식적으로, token-level heatmap H 는 다음과 같이 얻을 수 있습니다:
H = Σ<sub>l=L</sub><sup>N<sub>l</sub></sup> max<sub>h∈1,...,N<sub>h</sub></sub> Attn<sub>l,h</sub>. (1)
이러한 H ∈ ℝ<sup>H,W</sup> 는 VLM의 intermediate reasoning을 반영하고 식별된 salient regions를 강조합니다.
Post-Processing to Pixel Space. Iterative refinement 없이 구성된 naive perception map은 이미 upsampled되어 magnifier를 guide할 수 있습니다. token-level heatmap H 를 pixel-level perception map으로 up-sampling하기 전에, 먼저 더 smooth하고 well-distributed attention distribution을 얻기 위해 heatmap을 post-process하여 더 나은 magnification quality를 얻습니다. 먼저, H 를 unit interval로 scaling하여 normalize하여 H' 를 얻습니다. 그런 다음, normalized map의 variance를 scaling coefficient α 로 증폭시킨 다음, sigmoid function을 사용하여 값을 다시 [0, 1] 범위로 압축하여 H<sub>proc</sub> 를 얻습니다:
H<sub>proc</sub> = sigmoid( α ⋅ (H' - µ(H')) / σ(H') ). (2)
마지막으로, enhanced heatmap에 kernel size k 의 uniform smoothing filter를 적용한 다음, bilinear upsampling을 적용하여 pixel-level perception map P 를 얻습니다. Fig. 2에서 볼 수 있듯이, 이 post-processing step은 low-magnitude attention values를 증폭시켜 작지만 잠재적으로 중요한 regions도 magnification을 위해 고려되도록 함으로써 heatmap을 refine합니다.
3.2. Iterative Refinement
Naive perception map은 magnification을 위한 simple and effective guide 역할을 하지만, single forward pass는 multiple occurrences가 존재할 때 objects의 모든 instances를 capture하지 못할 수 있습니다. 이러한 limitation은 deep vision models가 lower layers에서 fine-grained features를 exchange하고 이를 information registers 역할을 하는 specific tokens로 aggregate하기 때문에 발생합니다. 이러한 aggregation은 visual information을 few key tokens에 집중시켜 semantically similar regions와 관련된 other visual tokens의 contribution을 줄입니다. 결과적으로, similar visual patterns가 image의 different parts에 나타날 때, VLMs는 주로 key tokens의 subset에 attend하여 certain regions of interest를 간과하는 incomplete perception map으로 이어질 수 있습니다.
Perception map의 coverage를 향상시키기 위해, 우리는 reasoning process에서 key registers를 iteratively blocking하여 VLMs가 additional visual regions에 attend하도록 강제하는 iterative refinement approach on attention을 제안합니다. 그러나, image level에서 key visual regions를 directly masking하는 것은 fine-grained segmentation 또는 ROI localization을 필요로 하므로 computationally challenging합니다. 더욱이, 이러한 approach는 visual tokens의 re-tokenization을 필요로 하므로 decoding에는 infeasible합니다. 대신, 우리는 token level에서 information blocking을 적용하여 이러한 challenges를 효과적으로 완화하면서 inference efficiency를 보존합니다.
구체적으로, first iteration에서 우리는 ones의 vector로 initialized된 default attention mask M<sup>(0)</sup> 을 사용하여 tokenized input을 VLM을 통해 forward하고 initial token-level attention heatmap H<sup>(0)</sup> 을 얻습니다. most visually attended tokens T<sup>(0)</sup> 을 식별하기 위해, 우리는 attention values를 two clusters로 partitioning하는 clustering-based method를 사용하여 higher centroid를 가진 cluster의 tokens를 T<sup>(0)</sup> 으로 선택합니다. visually important tokens는 일반적으로 다른 tokens보다 significantly higher attention을 나타내기 때문입니다. subsequent iterations에서 their influence를 억제하기 위해, attention mask를 다음과 같이 update합니다:
M<sup>(1)</sup> = M<sup>(0)</sup> ∩ ¬T<sup>(0)</sup>
여기서 ¬T<sup>(0)</sup> 는 T<sup>(0)</sup> 에 대한 mask의 complement를 나타내며, 이러한 highly attended tokens가 next pass에서 제외되도록 합니다. updated input은 VLM에 의해 reprocessed되어 new token-level heatmap H<sup>(1)</sup> 을 생성합니다. 이 process는 next iteration의 total attention score가 β 미만이거나 iterations의 upper limits에 도달할 때까지 반복적으로 수행됩니다. 즉, ΣH<sup>(i+1)</sup> < β, for 0 ≤ i ≤ 8이며, 이는 더 이상 substantial amount of attention을 할당할 visually relevant tokens가 남아 있지 않음을 나타냅니다.
마지막으로, 우리는 각 token position에서 repeated contributions를 normalizing하면서 모든 T iterations에 걸쳐 attention을 aggregating하여 refined token-level heatmap H<sup>*</sup> 를 구성합니다:
H<sup>*</sup> = (Σ<sub>i=0</sub><sup>T</sup> H<sup>(i)</sup>) / (Σ<sub>i=0</sub><sup>T</sup> 1<sub>M<sup>(i)</sup></sub>). (3)
Iteratively refined heatmap H<sup>*</sup> 는 앞서 언급한 method를 사용하여 H<sub>proc</sub> 로 post-processed되어 pixel-level perception map P 를 생성합니다. 이 refined perception map은 next-token generation에 relevant한 모든 major visual elements를 capture하여 perception magnifier에 대한 enhanced guide를 제공하고 VLM에 대한 most critical regions에 focus를 보장합니다.
3.3. Attention-Based Magnification
[80]에서 영감을 받아, 우리는 perception magnifier를 attention-based sampling process로 개발합니다. perception map P 는 mass function으로 취급되며, higher perception values를 가진 regions가 더 많이 sampled될 가능성이 높습니다. 이를 위해, 먼저 P 를 horizontal and vertical dimensions를 따라 marginal distributions로 decompose하고 다음과 같이 cumulative distributions F<sub>x</sub>(n) 및 F<sub>y</sub>(n)을 계산합니다:
F<sub>x</sub>(n) := Σ<sub>j=1</sub><sup>n</sup> max<sub>1≤i≤w</sub> P<sub>i,j</sub>,
F<sub>y</sub>(n) := Σ<sub>i=1</sub><sup>n</sup> max<sub>1≤j≤h</sub> P<sub>i,j</sub>, (4)
여기서 w 와 h 는 각각 perception map의 width and height를 나타냅니다. 다음으로, inverse transform sampling을 적용하여 original image coordinates를 resampled coordinates로 remap하여 both dimensions에서 structure-preserving magnification을 보장합니다. magnified image는 다음과 같이 구성됩니다:
Î = T(I, P)<sub>i,j</sub> = Interp(I, F<sup>-1</sup><sub>x</sub>(i), F<sup>-1</sup><sub>y</sub>(j)), (5)
여기서 F<sup>-1</sup>(⋅)는 F(⋅)의 inverse function을 나타내며, uniformly spaced output coordinates를 perception-aware warped space로 remap합니다. smooth spatial mapping을 보장하기 위해, 우리는 equation에서 bilinear interpolation을 Interp method로 사용하여 efficiency and effectiveness의 균형을 맞춥니다. 다른 interpolation methods도 적용될 수 있습니다. magnified image Î 는 original visual input I 를 대체하고 동일한 textual input과 함께 VLM을 통해 forwarded되어 updated model output logits Ô 를 얻습니다. perception-magnified logits Ô 는 next-token generation을 위해 original model output O 와 proportionally combined되거나 contrastively compared될 수 있지만, 우리는 visual content의 enhanced representation을 이미 제공하므로 softmax function 후에 Ô 에서 directly sample합니다. 전체 perception magnification process는 각 autoregressive decoding step에서 적용되어 model이 structural integrity를 보존하면서 visual input의 different regions에 adaptively하게 focus할 수 있도록 하여 perception ability를 향상시키고 hallucination을 완화합니다.
3. Methods (정리 노트) - AI 연구자를 위한 핵심 요약
핵심 아이디어: Perception Magnifier (PM) - 반복적으로 key visual regions을 찾아 확대하여 visual input을 정제하는 방법.
전체 과정 (Fig. 2 참조):
- Perception Map 생성 (3.1):
- Interleaved architecture의 VLM에서 self-attention matrices 활용.
- Middle layers (l ≥ L)의 attention을 aggregating, max pooling (heads 기준)하여 token-level heatmap H 생성.
- Post-processing (H → H' → H<sub>proc</sub> → P):
- Normalization (unit interval).
- Variance 증폭 (scaling coefficient α, sigmoid).
- Smoothing (uniform filter), upsampling (bilinear) → pixel-level perception map P.
- Iterative Refinement (3.2):
- 목표: Multiple object instances가 있을 때, single forward pass의 한계 (key tokens에만 집중) 극복, perception map coverage 향상.
- 방법: Key registers (high-attention tokens)를 반복적으로 blocking하여 VLM이 additional visual regions에 attend하도록 유도.
- Clustering 기반으로 high-attention tokens T<sup>(0)</sup> 식별.
- Attention mask update: M<sup>(1)</sup> = M<sup>(0)</sup> ∩ ¬T<sup>(0)</sup> (highly attended tokens 제외).
- 반복 (total attention score < β or iterations ≤ 8).
- Refined heatmap: H<sup>*</sup> = (Σ H<sup>(i)</sup>) / (Σ 1<sub>M<sup>(i)</sup></sub>).
- Attention-Based Magnification (3.3):
- Perception map P를 mass function으로 간주, higher value regions를 더 많이 sampling.
- Marginal distributions, cumulative distributions (F<sub>x</sub>, F<sub>y</sub>) 계산 (Eq. 4).
- Inverse transform sampling으로 original coordinates → resampled coordinates (Eq. 5).
- Structure-preserving magnification.
- Bilinear interpolation (Interp method).
- Magnified image Î를 visual input으로 사용, updated logits Ô 얻음.
- Ô에서 directly sampling (enhanced representation).
- Autoregressive decoding의 각 step마다 적용.
이 논문만의 차별점/핵심:
- 반복적인 refinement: Key visual regions를 "찾고", "확대"하는 과정을 반복하여, 놓치기 쉬운 details까지 포착.
- Token-level blocking: Image-level masking (computationally expensive, re-tokenization 필요) 대신, token-level에서 information blocking 수행 (inference efficiency 유지).
- Attention-based sampling: Perception map을 기반으로 sampling, structure-preserving magnification 구현.
쉬운 설명 :
이 논문의 핵심 기술인 "Perception Magnifier (PM)"는 VLM이 이미지를 더 잘 이해하도록 돕는 "돋보기" 역할을 합니다. PM은 다음과 같은 세 단계로 작동합니다.
- "관심 지도" 만들기 (Perception Map Construction):
- VLM이 이미지의 어떤 부분에 "주목(attention)"하는지 나타내는 지도(heatmap)를 만듭니다.
- 이미지의 중간 부분(middle layers)에서 VLM이 주목하는 정도를 합산하고, 가장 높은 값들을 골라냅니다.
- 이 지도를 보기 좋게 다듬고(post-processing), 픽셀 단위의 "관심 지도(perception map)"로 확대합니다.
- "관심 지도" 반복 개선 (Iterative Refinement):
- VLM이 한 번에 이미지 전체를 완벽하게 보기 어려울 수 있습니다 (특히 비슷한 물체가 여러 개 있을 때).
- 그래서 VLM이 "가장 주목하는 부분"을 일시적으로 "가리고", 나머지 부분에 더 집중하도록 강제합니다.
- 이 과정을 반복하여, VLM이 이미지의 여러 부분을 골고루 "주목"하도록 만듭니다.
- "주목" 기반 확대 (Attention-Based Magnification):
- "관심 지도"에서 높은 값을 가진 영역 (VLM이 중요하다고 생각하는 영역)을 더 많이 샘플링합니다.
- 이를 통해 이미지의 중요한 부분은 확대되고, 덜 중요한 부분은 축소되는 효과를 얻습니다.
- 확대된 이미지를 VLM에 다시 입력하여, 더 정확한 텍스트를 생성하도록 돕습니다.
PM은 VLM이 텍스트를 생성하는 매 순간마다(each autoregressive decoding step) 작동하여, 이미지의 중요한 부분을 놓치지 않고, 더 정확하고 이미지와 일치하는 텍스트를 생성하도록 돕습니다.