LLM : 논문 리뷰 : ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search 학습 노트
Overall Summary
ReST-MCTS*는 process reward guided tree search (MCTS*)를 통해 LLM self-training을 수행하는 새로운 framework. MCTS*를 통해 자동으로 inferred process reward를 생성하고, 이를 value target 및 high-quality trace selection에 활용하여 policy model과 reward model을 동시에 개선한다. 실험 결과는 기존 reasoning 및 self-training baselines보다 우수한 성능을 보였으며, 이는 process-level supervision의 중요성을 시사한다. 하지만, 다양한 task로의 generalization, value model scaling, 그리고 computation cost 감소 등의 future work가 필요하다.
쉬운 설명: 이 논문은 LLM이 문제를 푸는 과정에서 각 단계별로 "잘 하고 있는지"를 스스로 평가하고, 이 평가를 바탕으로 더 좋은 풀이 과정을 찾도록 학습하는 방법(ReST-MCTS*)을 제안합니다. 마치 사람이 어려운 문제를 풀 때, 각 단계별로 "이 방법이 맞나?"를 생각하고, 더 나은 방법을 찾아가는 것과 유사합니다. 이를 위해, "나무 탐색 (tree search)"과 "보상 (reward)" 개념을 활용하여, LLM이 스스로 학습하는 효율적인 방법을 제시합니다.
Purpose of the Paper
- 기존 문제: LLM self-training은 주로 outcome reward (최종 결과의 정확성)에 의존하여, reasoning trace의 중간 단계(intermediate reasoning steps)가 부정확하거나 불필요해도 최종 결과만 맞으면 positive sample로 간주하는 문제 (false positives)가 발생.
- 해결 목표: Process reward (각 reasoning step의 정확성)를 활용하여, 더 높은 quality의 reasoning trace를 수집하고, policy 및 reward model을 동시에 self-training하는 방법 (ReST-MCTS*) 제시.
- Novel Approach: Process reward를 자동으로 생성하기 위해, tree-search (MCTS*) 기반 reinforcement learning을 활용. Oracle final correct answer가 주어지면, MCTS*가 각 step이 correct answer로 이어질 확률을 추정하여 inferred reward를 생성.
Key Contributions
- ReST-MCTS* Framework: Process reward guidance와 tree search MCTS*를 결합한 reinforced self-training approach 제시.
- Novelty: Process reward model 학습을 위한 per-step manual annotation 없이, tree-search-based reinforcement learning으로 process reward를 자동으로 추론(infer).
- MCTS* Algorithm:
- Novelty: Per-step process reward (value) model로 guided되는 modified Monte Carlo Tree Search (MCTS) algorithm (MCTS*)을 reasoning policy로 사용.
- Automated Per-step Labeling: Sufficient rollouts을 통해 per-step label을 자동으로 생성하여 process reward model 학습.
- Dual-Purpose Inferred Rewards:
- Value Targets: Process reward model을 refine하기 위한 value target으로 사용.
- Trace Selection: Policy model self-training을 위한 high-quality trace selection에 활용.
- Iterative Self-Training: Tree-search policy (MCTS*)로 찾은 traces를 training data로 사용하여, policy model과 process reward model을 multiple iterations 동안 continuously enhance.
Experimental Highlights
- Reasoning Policy (MCTS*) 성능:
- Same Search Budget: Best-of-N, Tree-of-Thought 등 prior LLM reasoning baselines보다 SciBench, MATH benchmark에서 더 높은 accuracy 달성.
- Self-Training: ReST-MCTS*가 ReST<sup>EM</sup>, Self-Rewarding LM 등 other self-training algorithms보다 우수한 성능 (Table 2).
- Process Reward Model 성능:
- Higher Quality: MATH-SHEPHERD 등 previous process reward generation techniques보다 더 높은 quality의 process reward model 학습 (Table 3).
- Datasets: SciBench, MATH, GSM8K, TheoremQA.
- Metrics: Accuracy.
- Baselines: Self-Consistency (SC), Best-of-N (BoN), Tree-of-Thought (ToT), ReST<sup>EM</sup>, Self-Rewarding LM.
Limitations and Future Work
- Generalization: Math 외의 다른 reasoning task (coding, agent 등) 및 ground-truth 없는 task (dialogue, SWE-Bench 등)로의 generalization 필요.
- Value Model Scaling: 더 큰 scale의 value model backbone 및 다양한 data filtering techniques 필요.
- Online RL Integration: Value model과 policy model self-training을 위한 online RL algorithms 통합 고려.
- High Computation Cost of Tree Search: 특히 초기 단계에서 exploration에 많은 계산 비용 발생.
Abstract
LLM self-training의 최신 방법론은 주로 LLM이 responses를 generating하고 정답 output answers를 가진 것들을 training data로 filtering하는 것에 의존합니다. 이 접근 방식은 종종 낮은 품질의 fine-tuning training set (예: incorrect plans 또는 intermediate reasoning)을 생성합니다.
본 논문에서는, ReST-MCTS*라고 불리는 reinforced self-training 접근법을 개발합니다. 이는 process reward guidance를 tree search MCTS*와 integrating하여 더 높은 품질의 reasoning traces와 per-step value를 collecting하여 policy 및 reward models을 train합니다.
ReST-MCTS*는 일반적으로 process rewards를 train하기 위해 사용되는 per-step manual annotation을 tree-search-based reinforcement learning을 통해 circumvent합니다. oracle final correct answers가 주어지면, ReST-MCTS*는 이 step이 정답으로 이어지는 데 도움이 될 수 있는 probability를 estimating하여 올바른 process rewards를 infer할 수 있습니다.
이러한 inferred rewards는 두 가지 용도로 사용됩니다.
- process reward model을 further refining하기 위한 value targets의 역할을 합니다.
- policy model self-training을 위한 high-quality traces의 selection을 facilitate합니다.
우리는 먼저 ReST-MCTS*의 tree-search policy가 동일한 search budget 내에서 Best-of-N 및 Tree-of-Thought와 같은 이전 LLM reasoning baselines에 비해 더 높은 accuracy를 achieves한다는 것을 보여줍니다.
그런 다음 이 tree-search policy에 의해 searched된 traces를 training data로 사용하여, 여러 iterations 동안 세 가지 language models를 continuously enhance할 수 있으며, ReSTEM 및 Self-Rewarding LM과 같은 다른 self-training algorithms보다 outperform한다는 것을 보여줍니다.
1 Introduction
Large Language Models (LLMs)는 대부분 human-generated data로 trained됩니다. 그러나 웹에서 사용 가능한 고품질의 human-produced text가 대부분 크롤링되어 LLM training에 사용되는 시점에 접근함에 따라, 연구 초점은 LLM-generated content를 사용하여 self-training을 conduct하는 쪽으로 shifted되었습니다.
대부분의 Reinforcement Learning (RL) 문제와 유사하게, LLM self-training에는 reward signal이 필요합니다. 대부분의 기존 reinforced self-improvement approaches (예: STaR, RFT, ReSTEM, V-STaR)는 ground-truth reward model (supervised dataset의 labels 또는 pre-trained reward model)에 대한 access를 assume합니다. 이러한 approaches는 LLM을 사용하여 각 question에 대해 multiple samples를 generate하고, high reward (correct solution)로 이어지는 sample이 high-quality sample이라고 assume하며, 나중에 이러한 samples에 대해 train합니다 (따라서 self-training). 이러한 procedures는 LLM performance를 improving하는 데 effective할 수 있으며, 어떤 경우에는 base LLM이 otherwise solve할 수 없는 reasoning tasks를 solving하기도 합니다.
그러나 위의 procedure의 key limitation은 reasoning trace가 correct solution을 result하더라도, 전체 trace가 accurate하다는 것을 necessarily imply하지 않는다는 것입니다. LLMs는 종종 wrong 또는 useless intermediate reasoning steps를 generate하면서도, 우연히 correct solution을 find합니다. 결과적으로, self-training dataset은 종종 많은 false positives (intermediate reasoning traces 또는 plans는 incorrect하지만 final output은 correct)를 contain할 수 있으며, 이는 complex reasoning tasks에 대한 LLM fine-tuning의 final performance를 limits합니다.
이 문제를 해결하는 한 가지 way는 value function 또는 reward model을 사용하여 reasoning traces의 correctness를 verify하는 것입니다 (이는 self-training을 위한 learning signal로 serves합니다). 그러나 reasoning trace의 every step을 verify하는 reliable reward model을 training하는 것은 generally dense human-generated annotations (per reasoning step)에 depends하며, 이는 scale well하지 않습니다. 우리의 research는 verification purposes를 위해 reward signals를 effectively utilizing하면서 reliable reasoning traces의 acquisition을 automates하는 novel approach를 developing하여 이러한 gap을 address하는 것을 aims합니다. 우리의 key research question은 다음과 같습니다. How can we automatically acquire high-quality reasoning traces and effectively process reward signals for verification and LLM self-training?
본 논문에서는, model-based RL training을 사용하여 LLMs를 training하는 framework인 ReST-MCTS*를 propose합니다. 우리의 proposed approach는 trained per-step process reward (value) model에 의해 guided되는 reasoning policy로서 modified Monte Carlo Tree Search (MCTS) algorithm (MCTS*로 denoted됨)을 utilizes합니다. 우리 method의 key aspect는 sufficient number of rollouts를 performing하여 per-step reward models를 training하기 위한 per-step labels를 automatically generate할 수 있다는 것입니다. 이 labeling process는 additional human intervention을 requiring하지 않고도 highest quality를 가진 samples의 subset을 effectively filters out합니다.
Table 1은 우리 approach와 previous approaches 간의 key distinctions를 summarizes합니다. 우리는 experimentally ReST-MCTS*가 SciBench 및 MATH benchmarks에서 동일한 search budget 하에 Self-Consistency (SC) 및 Best-of-N (BoN)과 같은 prior work in discovering good reasoning traces를 outperforms하며, 이는 consequently improved self-training으로 leads한다는 것을 validate합니다.
요약하자면, 우리의 contributions는 다음과 같습니다.
- 우리는 MCTS*에 의해 searched된 process rewards를 generates하는 self-training approach인 ReST-MCTS*를 propose합니다. Key step은 MCTS*를 사용하여 sufficient times of rollouts를 통해 each intermediate node의 process reward를 automatically annotate하는 것입니다. 우리는 multiple reasoning benchmarks를 validate하고 ReST-MCTS*가 Table 2에서 shown된 것처럼 existing self-training approaches (예: ReSTEM 및 Self-Rewarding)를 outperforms하고, Table 4에서 shown된 것처럼 reasoning policies (예: CoT 및 ToT)를 outperforms한다는 것을 find합니다.
- ReST-MCTS*의 reward generator는 Table 3에서 shown된 것처럼 previous process reward generation techniques (예: MATH-SHEPHERD)에 비해 higher-quality process reward model로 leads합니다.
- 동일한 search budget이 given된 경우, ReST-MCTS*의 search algorithm (MCTS*)은 Figure 2에서 shown된 것처럼 Self-Consistency 및 Best-of-N보다 higher accuracy를 achieves합니다.
1 Introduction 정리 노트 (AI 연구자 대상)
핵심 문제 제기:
- LLM self-training에서, 기존 방식(e.g., STaR, RFT, ReSTEM)은 정답을 맞춘 reasoning trace라도 중간 과정이 틀릴 수 있다는 문제(false positives)가 있음.
- 이는 LLM fine-tuning 성능을 저해하는 요인이 됨.
- Process reward model로 각 단계를 검증하는 것이 이상적이나, dense human annotation은 scalable하지 않음.
본 논문의 핵심 아이디어 (ReST-MCTS*):
- Automated Process Reward Generation: MCTS*를 사용해 충분한 rollout을 수행, 각 단계의 process reward를 자동으로 레이블링. (human annotation 없이!)
- 이를 통해, 정답으로 이어질 가능성이 높은 단계를 판별.
- Dual Purpose of Inferred Rewards:
- Process reward model을 더 정교하게 만드는 value target으로 활용.
- Policy model self-training을 위한 고품질 trace 선택에 활용.
- MCTS* Search: 기존 LLM reasoning 방식(Best-of-N, Tree-of-Thought)보다 동일 budget에서 더 높은 accuracy 달성.
주요 Contribution:
- ReST-MCTS* Framework: MCTS*로 process reward를 생성하는 self-training 방식 제안. 자동화된 process reward annotation이 핵심.
- Higher-Quality Process Reward Model: 기존 방식(MATH-SHEPHERD)보다 더 나은 process reward model 생성.
- Improved Search Algorithm: MCTS*가 Self-Consistency, Best-of-N보다 높은 정확도 달성.
이 논문이 중요한 이유:
- LLM self-training에서 고질적인 문제(false positives in reasoning traces)를 자동화된 방식으로 해결하려는 시도.
- Process reward model의 학습과 활용을 효율적으로 결합한 새로운 framework 제시.
- 실험적으로 기존 방식들보다 우수한 성능 입증.
쉬운 설명:
LLM(Large Language Model)이 스스로 학습하는 방법 중 하나는, 문제를 풀고 정답을 맞히면 "잘했어!"라고 보상(reward)을 받는 거에요. 마치 강아지 훈련처럼요! 그런데 문제는, LLM이 정답은 맞혔지만 문제를 푸는 과정(reasoning trace)이 엉터리일 수도 있다는 거에요. 예를 들어, 찍어서 맞춘 것처럼요.
기존 연구들은 이 "엉터리 과정" 때문에 LLM 학습 효율이 떨어지는 문제가 있었어요. 이걸 해결하려면 각 단계를 일일이 사람이 검사해서 "잘했다/못했다" 알려줘야 하는데, 너무 힘들겠죠?
이 논문에서는 이걸 자동화했어요! MCTS*라는 똑똑한 알고리즘을 써서 여러 번 문제를 풀어보게 하고, "이 단계가 정답으로 가는 데 도움이 될 확률"을 계산해요. 이걸 process reward라고 부르는데, 이걸 자동으로 알아내니까 사람이 일일이 검사할 필요가 없죠.
이렇게 얻은 process reward는 두 가지로 활용돼요.
- "이 단계가 얼마나 중요한지" 알려주는 점수(value target)로 써서, process reward를 더 정확하게 만드는 데 사용하고,
- "진짜 잘 푼 과정"만 골라서 LLM을 학습시키는 데 사용해요.
결과적으로, 이 논문의 방법(ReST-MCTS*)은 기존 방법들보다 더 똑똑하게 LLM을 스스로 학습시킬 수 있다는 걸 보여준답니다!
2 Background on Reasoning & Self-Training
우리는 LLM-based reasoning의 standard setup을 따릅니다. 우리는 policy(π로 denoted)에서 start하며, 이는 base LLM을 사용하여 instantiated됩니다. Input problem Q가 주어지면, 가장 simple한 case에서, π는 autoregressively next token을 predicting하여 reasoning steps (s1, s2, ..., sK) ~ π(·|Q)의 output sequence, 또는 trace를 generate할 수 있습니다. Simplicity를 위해, 우리는 reasoning step이 single sentence (이는 itself multiple tokens를 comprises)를 comprises한다고 assume합니다. 또한 last output sK가 final step이라고 assume합니다. LLMs는 또한 certain traces를 따라 generation을 bias하도록 prompted되거나 conditioned될 수 있습니다. Prompt c에 대해, 우리는 policy를 π(·|Q, c)로 write할 수 있습니다. 이 idea는 chain-of-thought (CoT)에서 가장 famously하게 used되었습니다.
Self-Consistency (SC). Self-Consistency는 π에서 multiple reasoning traces를 samples하고 가장 frequently하게 appears하는 final answer를 chooses합니다.
Tree-Search & Value Function. 또 다른 idea는 intermediate reasoning steps에서 branch하는 tree-structured reasoning traces를 사용하는 것입니다. 소위 tree-search reasoning algorithm을 using하는 데 있어 one key issue는 otherwise combinatorially large search process를 guide하기 위해 value function을 have해야 할 need입니다. Two common value functions는 Outcome Reward Models (ORMs) (final answer의 correctness에만 trained됨)와 Process Reward Models (PRMs) (each reasoning step의 correctness에 trained됨)를 include합니다. 우리는 rsk가 k-th step에서 PRM의 output sigmoid score라고 assume합니다. 우리의 ReST-MCTS* approach는 good PRM을 automatically learn하기 위해 tree-search를 uses합니다.
Best-of-N. Self-Consistency에 대한 alternative로, learned value function (PRM 또는 ORM)을 사용하여 highest value를 가진 reasoning trace를 select할 수도 있습니다.
Self-Training. High level에서, self-training에는 two steps가 있습니다. First step은 generation으로, 여기서 우리는 π (in our case, tree-structured traces)를 사용하여 multiple reasoning traces를 sample합니다. Second step은 improvement로, 여기서 reasoning traces에 learning signal이 constructed되고, 이는 then π를 fine-tune하는 데 used됩니다. 이 process는 multiple iterations 동안 repeat될 수 있습니다.
Limitation of Prior Works. Reliable self-training을 수행하는 데 있어 main challenge는 useful learning signal의 construction입니다. Ideally, one은 PRM에 의해 given되는 every intermediate reasoning step의 correctness에 대한 dense learning signal을 want할 것입니다. Otherwise, sparse learning signals를 사용하면 reinforcement learning에서와 similar한 credit assignment problem을 suffers합니다. Historically, PRM을 learning하는 데 있어 main challenge는 reasoning step per supervised annotations의 lack입니다. 이것이 우리 ReST-MCTS* approach가 overcome하고자 seeks하는 principal challenge입니다. 우리는 Appendix A에서 detailed preliminaries를 describe합니다.
2. Background on Reasoning & Self-Training 정리 노트 (AI 연구자 대상)
기존 LLM Reasoning 및 Self-Training 방식:
- Policy (π): Base LLM을 사용, input problem에 대한 reasoning steps의 sequence (trace) 생성.
- Chain-of-thought (CoT): prompting을 통해 특정 trace 생성 유도.
- Reasoning Trace 생성 기법:
- Self-Consistency (SC): 여러 trace를 샘플링, 가장 빈번한 최종 답변 선택.
- Tree-Search: 중간 단계에서 branching하는 tree 구조. Value function 필요.
- Value Function:
- Outcome Reward Model (ORM): 최종 답변의 정확성에만 기반하여 학습.
- Process Reward Model (PRM): 각 reasoning step의 정확성에 기반하여 학습. (본 논문에서 중요!)
- Value Function:
- Best-of-N: 학습된 value function (PRM or ORM)을 사용, 최고 가치의 trace 선택.
- Self-Training:
- Generation: π를 사용, 여러 (tree-structured) reasoning traces 생성.
- Improvement: Reasoning traces에 대한 learning signal 구성, π fine-tuning. (반복 가능)
이 논문의 핵심과 연결되는 기존 연구의 한계:
- Reliable Self-Training의 어려움: 유용한 learning signal 구축이 관건.
- 이상적인 Learning Signal: 각 reasoning step의 정확성에 대한 dense signal (PRM이 제공).
- Sparse signal은 credit assignment 문제 야기 (reinforcement learning과 유사).
- PRM 학습의 어려움: 각 reasoning step에 대한 supervised annotation 부족 (이것이 ReST-MCTS*가 해결하려는 핵심 문제).
핵심: 이전 연구들은 각 reasoning step에 대한 detailed feedback (supervised annotation)이 없어서 좋은 PRM을 만들기 어려웠다는 점을 지적. ReST-MCTS*는 이 부분을 자동화하여 해결하려는 것.
쉬운 설명:
LLM이 문제를 푸는 과정(reasoning)을 생각해 봅시다.
- Policy (π): LLM이 문제를 풀 때 사용하는 "전략"이라고 할 수 있어요.
- Chain-of-thought (CoT): "이렇게 저렇게 생각해 봐"라고 힌트(prompt)를 줘서 LLM이 특정 방식으로 문제를 풀게 하는 거에요.
문제를 푸는 방법(Reasoning Trace 생성)은 여러 가지가 있어요:
- Self-Consistency (SC): 여러 가지 방법으로 풀어보고, 가장 많이 나온 답을 고르는 거에요.
- Tree-Search: 나무처럼 여러 갈래로 뻗어 나가면서 문제를 푸는 거에요. 이 때는 어떤 가지가 좋은지 알려주는 "가치 함수(Value Function)"가 필요해요.
- Outcome Reward Model (ORM): 최종 답이 맞았는지 틀렸는지만 보고 "잘했다/못했다"를 판단해요.
- Process Reward Model (PRM): 문제를 푸는 매 단계마다 "잘했다/못했다"를 판단해요. (이게 더 좋겠죠!)
- Best-of-N: ORM이나 PRM 점수가 가장 높은 풀이 방법을 선택하는 거에요.
스스로 학습(Self-Training)은 이렇게 진행돼요:
- Generation: LLM이 여러 가지 방법으로 문제를 풀어요.
- Improvement: 어떤 풀이 방법이 좋았는지 평가하고, LLM을 더 좋게 만들어요(fine-tuning).
그런데, 기존 연구들은 문제가 있었어요. 매 단계마다 "잘했다/못했다"를 알려주는 PRM이 있으면 좋은데, 이걸 만들려면 사람이 일일이 채점해야 했거든요. 너무 힘들잖아요!
그래서 이 논문의 ReST-MCTS*가 등장한 거에요. 이 방법은 사람이 채점하지 않아도 자동으로 PRM을 만들 수 있게 해줘요! (이전 섹션에서 설명한 것처럼요.)
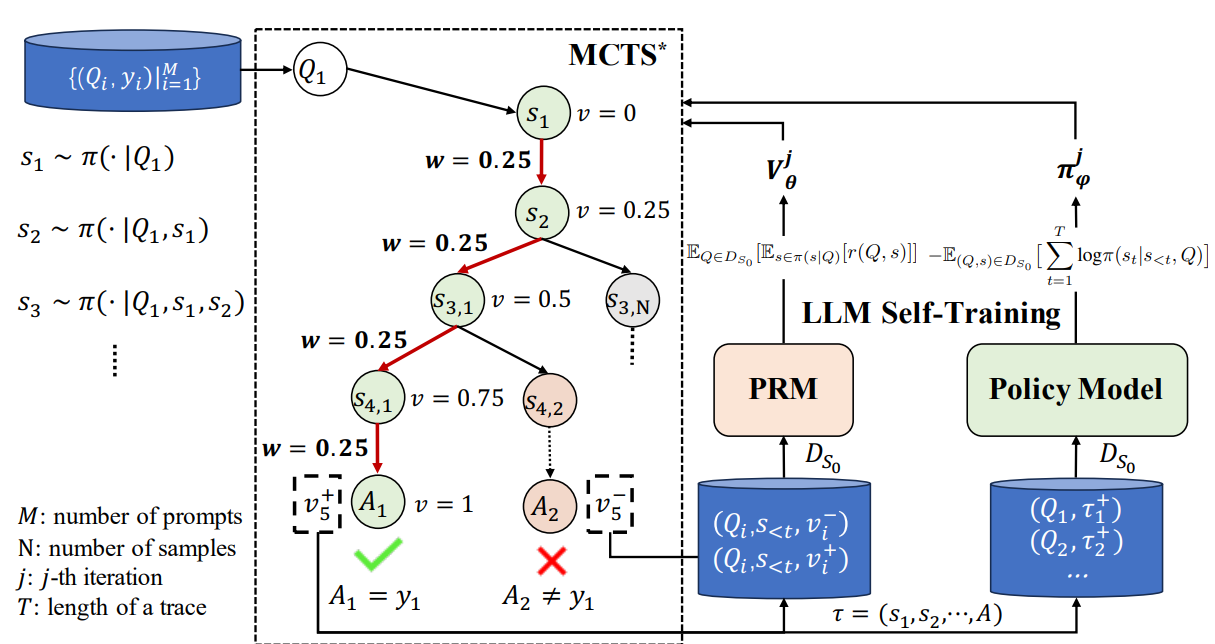
Figure 1: 왼쪽 부분은 process rewards를 inferring하는 process와 process reward guide tree-search를 conduct하는 how를 presents합니다. 오른쪽 부분은 process reward model and policy model both의 self-training을 denotes합니다.
3 The ReST-MCTS* Method
우리 approach, ReST-MCTS*는 Figure 1에 outlined되어 있으며, four main components를 사용하여 developed됩니다.
- MCTS*: PRM의 guidance 하에 sufficient rollout time으로 tree search를 performs합니다.
- Process Reward Model (PRM): any partial solution의 quality를 evaluates하고 MCTS*를 guides합니다.
- Policy Model: each question에 대해 multiple intermediate reasoning steps를 generates합니다.
- LLM Self-Training: MCTS*를 사용하여 reasoning traces를 collect하고, positive samples에 대해 policy model을 trains하고, all generated traces에 대해 process reward model을 trains합니다.
3.1 Search-based Reasoning Policy for LLM
Partial Solution에 대한 Value vk. Partial solution pk = [s1, s2, ..., sk]의 value (process) reward vk는 following basic qualities를 satisfy해야 합니다.
- Limited range: vk는 specific range 내로 constrained됩니다. 이 restriction은 vk의 values가 bounded되고 certain limit을 exceed하지 않도록 ensures합니다.
- Reflecting probability of correctness: vk는 partial solution이 complete and correct answer일 probability를 reflects합니다. Higher values of vk는 better quality 또는 correct answer에 closer할 higher likelihood를 indicate합니다.
- Reflecting correctness and contribution of solution steps: vk는 each solution step의 correctness and contribution을 both incorporates합니다. Partial solution에서 starting할 때, correct next step은 false ones에 비해 higher vk를 result해야 합니다. Additionally, final answer를 향해 more correct deductions를 만드는 step은 higher vk value로 lead해야 합니다. 이 property는 vk가 correct solution을 향해 만들어진 incremental progress를 captures하고 solution의 overall correctness에 contribute하는 steps를 rewards하도록 ensures합니다.
Partial Solution에 대한 Reasoning Distance mk. Solution step의 progress를 estimate하기 위해, 우리는 pk의 reasoning distance mk를 policy model이 pk에서 starting하여 correct answer에 reach하기 위해 requires하는 minimum reasoning steps로 define합니다. Reasoning distance는 progress made뿐만 아니라 current steps를 based on correct answer를 figure out하는 policy의 difficulty를 reflects하므로, further pk의 quality를 evaluate하는 데 used될 수 있습니다. However, 우리는 mk가 directly calculated될 수 없다는 것을 point out합니다. 이는 pk에서 starting하는 simulations 또는 trace sampling을 performing하고 correct answer를 discover하는 데 used된 actual minimum steps를 finding하여 estimated될 수 있는 hidden variable에 more like합니다.
Single Step에 대한 Weighted Reward wsk. Partial solutions를 evaluating하기 위한 desired qualities를 based on, 우리는 current step sk의 quality를 reflect하기 위해 weighted reward의 concept를 introduce하며, wsk로 denoted됩니다. Common PRM reward rsk를 based on, wsk는 further reasoning distance mk를 weight factor로 incorporates하여 sk가 만드는 incremental progress를 reflecting합니다.
Quality Value and Weighted Reward에 대한 Representations. Step k에서 partial solution의 quality value vk를 determine하기 위해, 우리는 previous quality value와 current step의 weighted reward를 incorporate합니다. Previous quality value를 considering함으로써, 우리는 preceding step까지 achieved된 cumulative progress and correctness를 account합니다. Therefore, vk는 iteratively 다음과 같이 updated될 수 있습니다.
vk = { 0, if k = 0; max(vk-1 + wsk, 0), otherwise } (1)
Current step의 weighted reward wsk는 overall solution을 향한 that specific step의 quality and contribution의 measure를 provides합니다. mk (where mk = K - k and K is the total number of reasoning steps of a solution s), previous quality value vk-1, and rsk in MATH-SHEPHERD를 based on, 우리는 weighted reward wsk의 definition을 iteratively 다음과 같이 update할 수 있습니다.
wsk = (1 - vk-1) / (mk + 1) * (1 - 2rsk), k = 1, 2, ... (2)
k가 increases함에 따라, mk는 decreases하며, 이는 correct answer에 reach하기 위해 fewer reasoning steps가 needed됨을 indicating합니다. 이는 current step의 weighted reward에 placed된 higher weight로 leads합니다. 우리는 also wsk and vk가 below theorem에 shown된 expected boundedness를 satisfy한다는 것을 derive할 수 있습니다.
Theorem 1 (Boundedness of wsk and vk). If rsk is a sigmoid score ranged between [0, 1], then wsk and vk defined as above satisfy following boundedness: wsk ≤ 1 - vk-1, vk ∈ [0, 1].
Derivation. Please refer to the detailed derivation in Appendix B.1.
Therefore, 우리는 wsk and vk가 our expectations와 match하는 following properties를 has한다는 것을 conclude할 수 있습니다.
- Observation 1. If a reasoning route starting from pk requires more steps to get to the correct answer, then the single-step weighted reward wsk is lower.
- Observation 2. wsk decreases as the PRM's predicted sigmoid score rsk rises. Thus, wsk has a positive correlation with the PRM's prediction of a step's correctness.
- Observation 3. vk → 1 ⇐⇒ rsk → 0, mk = 0, i.e. vk converges to upper bound 1 only when sk reaches the correct answer.
vk and wsk의 features를 based on, 우리는 precise PRM과 mk의 accurate prediction을 have하면 partial solutions의 quality value를 directly predict하고 search를 guide할 수 있습니다. Our approach에서는, rsk and mk를 predict하기 위해 separately training models하는 instead of, 우리는 simply process reward model Vθ를 train하여 vk를 predict하며, 이는 common PRM의 variant로 serving합니다. Reward가 vk의 calculation에 incorporated되므로, separately reward model을 train할 need가 없으며, answer selection을 위한 considerable effort를 saving합니다.
Process Reward Model Guided Tree Search MCTS*. Tree search methods like and require a value function and outcome reward model rϕ to prune branches, evaluate final solutions and backup value. However, ORM을 사용하여 final solutions를 evaluate하고 backpropagate하는 것은 every search trace가 completely generated되어야 함을 means하며, 이는 costly and inefficient합니다. Recent work suggests using a learned LLM value function in MCTS so the backup process can happen in the intermediate step, without the need for complete generations. Their work greatly improves search efficiency but still relies on an ORM to select the final answer. Drawing inspiration from these works, we further propose a new variant of MCTS, namely MCTS*, which uses quality value vk as a value target for a trained LLM-based process reward model and guidance for MCTS as well.
Given the above properties, 우리는 directly process reward model Vθ를 사용하여 any partial solution의 quality를 evaluate하고, intermediate nodes에서 select and backpropagate할 수 있습니다. Quality value의 use aside from, 우리는 also efficiency and precision을 enhance하기 위해 special Monte Carlo rollout method and self-critic mechanism을 incorporate하며, 이는 Appendix C.1에 detailedly explained됩니다. 우리는 MCTS*를 each iteration에서 four main stages, namely node selection, thought expansion, greedy MC rollout, and value backpropagation을 comprises하는 algorithm으로 express합니다. Common MCTS settings와 similar하게, the algorithm은 each single science reasoning question q에 대해 search tree Tq에서 runs합니다. Every tree node C는 a series of thoughts or steps를 represents하며, 여기서 partial solution pC, number of visits nC, and corresponding quality value vC가 recorded됩니다. Simplicity를 위해, 우리는 each node를 tuple C = (pC, nC, vC)로 denote합니다. MCTS*에 대한 overall pseudo-code는 Algorithm 2에 presented됩니다.
3.2 Self-Training Pipeline
Figure 1에 shown된 것처럼, proposed tree search algorithm MCTS*를 based on, 우리는 reasoning policy and process reward model에 대해 self-improvement를 perform합니다. Policy π and process reward model Vθ의 initialization after, 우리는 iteratively them을 employ하고 process에서 generated된 search tree Tq를 utilize하여 specific science or math questions에 대한 high-quality solutions를 generate하고 self-improvement process (ReST-MCTS*라고 called됨)를 conduct합니다. Our work는 MuZero framework에서 inspiration을 draws하고 이를 "MuZero-style learning of LLMs"라고 term하는 LLMs의 training에 applies합니다.
Instruction Generation. In this stage, initialization은 training process reward model Vθ를 위한 original dataset D0에서 starts합니다.
- Collect process reward for process reward model. New value data의 extraction은 relatively more complex하며, 우리는 pruned search tree T'q의 correct reasoning path near every tree node의 partial solutions의 target quality value를 derive합니다. 우리는 first T'q에서 correct answer에 get to하기 위해 required되는 minimum reasoning steps에 according to its (root를 including) at least one correct reasoning trace에 on인 every tree node C에 대해 mk를 calculate합니다. Then, 우리는 Eq. (11) in to calculate rsk, i.e. rsk = 1 - rHEsk, which means a reasoning step is considered correct if it can reach a correct answer in T'q를 use합니다. mk and rsk를 using, 우리는 one correct reasoning trace에 on or near every node의 partial solution의 value를 derive할 수 able to입니다. At least one correct trace에 on인 each node C (with partial solution pC = [s1, s2, ..., sk-1]) and a relevant forward step sk에 대해, 우리는 Eq. (11)에서 rHEsk = 0인 경우 mk를 mk-1과 same as로 set하여 Eq. (1)을 using하는 value vk and Eq. (2)를 using하는 weighted reward wk를 derive할 수 있습니다. 이 inferring process의 concrete and detailed example은 Figure 3에 shown됩니다. 우리는 root에서 starting하는 all these rewards and values를 update하고 all (Q, p, v) pairs를 collect하여 i-th iteration에서 DVi를 form하며, 이는 next iteration에서 process reward model을 training하는 데 used됩니다.
- Collect reasoning traces for policy model. Figure 4에 shown된 것처럼, search process는 multiple reasoning traces를 consisting of search tree Tq를 produces합니다. 우리는 first all the unfinished branches (final answer에 reach하지 않는 branches)를 prune합니다. Then 우리는 tree search에서 acquired된 other traces' final answers를 their correctness according to simple string matching or LLM judging을 통해 verify하고 correct solutions를 select합니다. These verified reasoning traces (as DGi(Aj=a*)|Nj=1 (where N is the number of sampling solutions, Aj is the j-th solution, and a* is the final correct answer) in i-th iteration) are then used for extracting new training data for policy self-improvement. This process는 policy self-training을 execute하기 위해 Eq. (13) (i ≥ 1)에 followed됩니다.
Mutual Self-training for Process Reward Model and Policy Model. Policy에 대한 self-training만을 concerns하고 policy가 iteratively new traces를 generating하고 itself에 의해 generated된 high-reward ones에서 learning함으로써 improve될 수 있음을 demonstrates하는 previous work like ReSTEM과 compared to, our work는 simultaneously process reward model and policy model self-training을 improves합니다. Process reward model의 training set DV0가 initialized되고 new problem set DG가 given되면, 우리는 Vθ and π에 대한 iterative self-training process를 start할 수 있습니다. 우리는 π를 사용하여 MCTS*를 perform하고 Section 3.1에 illustrated된 implement details를 사용하여 DG에 대한 solutions를 generate합니다. i-th (i = 1, 2, ...) iteration에서, 우리는 DVi-1로 Vθ를 train하여 Vi를 obtain하고 DGi에 대해 policy model πSi-1을 train하여 new generator πSi를 generate합니다. At the same time, DGi는 Vi의 Vi+1로의 update를 drives합니다. 우리는 process reward model and policy model이 Algorithm 1에서 each other를 complement하는 iterative self-training을 present합니다.
3. The ReST-MCTS* Method 정리 노트 (AI 연구자 대상)
ReST-MCTS* Framework 구성 요소:
- MCTS*:
- PRM guidance 하에 충분한 rollout을 통한 tree search 수행.
- 기존 MCTS와 차별점:
- Process Reward Model (PRM) 활용: 각 partial solution의 quality 평가, search guiding. (ORM 대신 PRM!)
- Automated Process Reward Learning: Rollout을 통해 per-step label 자동 생성 (핵심!).
- Value Target: Quality value (vk)를 LLM-based PRM의 value target으로 사용.
- Efficiency & Precision Enhancements: Special Monte Carlo rollout method, self-critic mechanism (자세한 내용은 Appendix C.1).
- Process Reward Model (PRM):
- Partial solution의 quality 평가 (vk 예측).
- MCTS* guiding.
- 일반적인 PRM과 달리, 별도의 reward model training 불필요 (vk 계산에 reward 통합).
- Policy Model:
- 각 question에 대한 multiple intermediate reasoning steps 생성.
- LLM Self-Training:
- MCTS*를 이용, reasoning traces 수집.
- Positive samples (정답을 맞춘 traces)로 policy model 학습.
- Generated traces 전체로 process reward model 학습.
- "MuZero-style learning of LLMs": MuZero framework에서 영감을 받아, policy model과 process reward model을 동시에 self-training.
Key Concepts & Formulas:
- Quality Value (vk): Partial solution의 quality를 나타내는 값.
- Bounded range (0과 1 사이).
- Correctness probability 반영.
- Solution steps의 correctness and contribution 반영.
- Iterative update: vk = max(vk-1 + wsk, 0) (Equation 1)
- Reasoning Distance (mk): Partial solution에서 correct answer까지 도달하는 데 필요한 최소 reasoning steps 수 (hidden variable).
- Weighted Reward (wsk): Current step의 quality를 나타내는 값.
- PRM reward (rsk)와 reasoning distance (mk)를 weight factor로 통합.
- wsk = (1 - vk-1) / (mk + 1) * (1 - 2rsk) (Equation 2)
- Properties:
- 더 많은 steps가 필요할수록 wsk 감소.
- PRM의 correctness prediction과 positive correlation.
- Correct answer에 도달하면 vk → 1.
Self-Training Pipeline (ReST-MCTS*):
- Initialization:
- Original dataset (D0)으로 process reward model (Vθ) training.
- Iterative Self-Training (Algorithm 1):
- Instruction Generation:
- MCTS*를 사용하여 search tree (Tq) 생성.
- Process Reward Model Training:
- Pruned search tree (T'q)에서 correct reasoning path 근처의 node들에 대해 target quality value (vk) derive.
- (Q, p, v) pairs를 collect하여 training data (DVi) 구성.
- Policy Model Training:
- Unfinished branches prune.
- Correct solutions select (string matching or LLM judging).
- Verified reasoning traces를 training data (DGi)로 사용.
- Mutual Self-Training:
- Process reward model (Vθ)과 policy model (π)을 번갈아 가며 학습.
- V(i) = Train(Vθ, DV(i-1))
- π(Si) = Train(π(Si-1), DG(i))
- DGi가 Vi를 Vi+1로 update하는 데 기여.
- Instruction Generation:
핵심:
- MCTS*를 활용, automated process reward generation 및 efficient tree search.
- Quality value (vk)와 weighted reward (wsk)를 통해 partial solution quality를 정량화.
- MuZero 스타일의 iterative self-training으로 policy model과 process reward model을 동시에 개선.
쉬운 설명:
ReST-MCTS*는 LLM이 스스로 문제를 더 잘 풀도록 가르치는 방법이에요. 크게 4가지 요소로 구성되어 있어요.
- MCTS*: 똑똑한 탐색 알고리즘이에요.
- 기존 MCTS와 달리, "과정 점수(Process Reward)"를 보면서 어떤 경로가 좋을지 판단해요.
- 사람이 채점하지 않아도, 여러 번 시뮬레이션(rollout)해서 각 단계의 점수를 자동으로 매겨요 (이게 핵심!).
- Process Reward Model (PRM): 각 단계의 "과정 점수"를 예측하는 모델이에요. MCTS*가 탐색할 때 참고하는 나침반 같은 거죠.
- Policy Model: 실제로 문제를 푸는 LLM이에요.
- LLM Self-Training: MCTS*로 문제를 풀면서 데이터를 모으고, 그걸로 Policy Model과 Process Reward Model을 번갈아 가면서 학습시켜요.
핵심 개념은 다음과 같아요:
- ㄱ (vk): 지금까지 푼 과정이 얼마나 좋은지 나타내는 점수 (0~1 사이).
- Reasoning Distance (mk): 여기서부터 정답까지 몇 단계나 남았는지 나타내는 값.
- Weighted Reward (wsk): 현재 단계가 얼마나 좋은지 나타내는 점수.
Self-Training 과정은 이래요:
- 초기화: 원래 데이터로 Process Reward Model을 대충 학습시켜요.
- 반복 학습:
- MCTS*로 문제를 풀면서 탐색 트리를 만들어요.
- Process Reward Model 학습: 탐색 트리에서 정답에 가까운 경로들을 찾아서, 각 단계의 "진짜" Quality Value를 계산해요. 이걸로 Process Reward Model을 더 정확하게 학습시켜요.
- Policy Model 학습: 정답을 맞힌 풀이 방법들만 골라서 Policy Model을 학습시켜요.
- Process Reward Model과 Policy Model을 번갈아 가면서 계속 학습시켜요. (마치 서로 가르쳐주는 것처럼!)
이 방법의 핵심은, 사람이 일일이 채점하지 않아도 MCTS*가 스스로 "좋은 풀이 과정"을 찾아내고, 그걸 바탕으로 LLM을 효과적으로 학습시킨다는 거에요!