VLM : 논문리뷰 : Vision-Language Models Can Self-Improve Reasoning via Reflection
Purpose of the Paper:
기존 연구들은 Large Language Models (LLMs)의 Chain-of-Thought (CoT) reasoning 능력을 향상시키는 데 집중했지만, Multimodal LLMs (MLLMs)에서의 CoT reasoning은 데이터 부족과 복잡성으로 인해 간과되어 왔습니다. 특히, Open-source MLLMs는 Visual cues를 효과적으로 통합하지 못해 CoT reasoning 성능이 미흡하며, GPT-4o와 같은 모델에 비해 현저히 떨어집니다.
본 논문은 이러한 문제점을 해결하고자, Multimodal CoT 데이터에 대한 manual annotation 없이 MLLMs 스스로 reasoning 능력을 self-improve 할 수 있는 새로운 self-training framework, **R³V (Reflect on bootstrapped COT Rationales for Vision-Language Reasoning)**를 제안합니다. R³V는 MLLMs의 기존 CoT 능력을 활용하여 Positive/Negative CoT samples를 bootstrapping하고, Self-reflection mechanism을 통해 reasoning 과정에서의 mistakes를 학습하도록 설계되었습니다.
Key Contributions:
- Iterative Self-Training Framework R³V: MLLMs 스스로 bootstrapped CoT를 활용하여 self-improvement를 달성하는 iterative framework R³V를 제시합니다. 이는 Vision-language reasoning 분야에서 self-training을 적용한 최초의 시도입니다.
- Self-Reflection Mechanism: Negative samples로부터 mistakes를 학습하고, Test-time computation을 통해 reasoning performance를 향상시키는 self-reflection mechanism을 제안합니다. Self-refine loss와 Self-select loss를 통해 flawed rationale을 수정하고, correct answer를 도출하도록 모델을 학습시킵니다.
- Self-Refine Loss: 모델이 생성한 flawed rationale을 correct rationale로 refine하도록 guidance.
- Self-Select Loss: Multiple rationale candidates를 비교하여 correct answer를 선택하도록 guidance.
- Comprehensive Experimental Evaluation: 다양한 Vision-language reasoning benchmark (ChartQA, TabMWP, CLEVR-Math, MiniWob, GeoQA, M³CoT)에서 R³V의 효과를 입증하고, Ablation study 및 Out-of-distribution (OOD) generalization evaluation을 통해 framework의 key factors를 분석합니다.
Novelty:
- Vision-Language Reasoning에서의 Self-Training: Text domain에 집중되었던 self-training을 Vision-language reasoning domain으로 확장하고, MLLMs의 self-improvement 가능성을 개척했습니다.
- Bootstrapped CoT Rationales: MLLMs 자체의 weak CoT 능력을 활용하여 self-training에 필요한 CoT data를 bootstrapping하는 novel approach를 제시합니다. 이는 manual annotation에 대한 의존성을 줄이고, self-supervision 학습 패러다임을 Vision-language reasoning에 도입한 것입니다.
- Reflection-Based Learning from Mistakes: Human reasoning 과정에서 영감을 얻어, mistakes로부터 학습하는 self-reflection mechanism을 framework에 통합했습니다. Self-refine 및 self-select losses는 negative samples를 적극적으로 활용하여 모델의 reasoning 능력을 향상시키는 novel loss functions입니다.
- Test-Time Computation을 통한 성능 향상: Self-select training을 통해 학습된 모델은 inference 시 multiple reasoning paths를 생성하고, self-select mechanism을 통해 superior solution을 선택하여 test-time performance를 further boosting합니다. 이는 MLLMs의 reasoning 능력을 test-time에 dynamically 향상시키는 새로운 접근 방식입니다.
Experimental Highlights:
- Benchmark Performance: R³V는 다양한 Vision-language reasoning benchmark에서 GPT-distilled baseline 대비 **23%에서 60%**의 relative improvement를 달성했으며, strong self-training baseline인 STaR을 consistently outperform 했습니다. 특히, Qwen-VL 모델에 R³V를 적용했을 때 average accuracy가 **48.47%에서 64.37%**로 크게 향상되었습니다.
- Out-of-Distribution Generalization: R³V는 In-domain benchmark뿐만 아니라 OOD benchmark (MMMU, MathVista, VCR)에서도 zero-shot 및 GPT-distilled baseline을 significantly outperform 하며, self-generated CoT data가 OOD generalization에도 효과적임을 입증했습니다.
- Ablation Study: Ablation study 결과, Self-refine loss와 Self-select loss 모두 performance 향상에 crucial한 역할을 하며, Iterative training process 또한 self-improvement에 필수적임을 확인했습니다.
- Test-Time Selection 효과: Test-time selection은 Pass@1 및 majority voting을 consistently surpassing하며, OOD scenarios에서도 robust하고 효과적인 성능 향상을 보여주었습니다. Sample size를 늘릴수록 test-time selection의 성능이 지속적으로 향상되는 scalability를 입증했습니다.
- Noisy Multimodal CoT 극복: R³V는 Multimodal CoT의 noisy nature에도 불구하고 효과적인 self-improvement를 달성했습니다. DPO와 같은 preference learning method가 noisy CoT 환경에서 어려움을 겪는 반면, R³V는 self-reflection mechanism을 통해 mistakes로부터 robust하게 학습하는 능력을 보여주었습니다.
Limitations:
- Noisy CoT Annotations: 현재 MLLMs의 capability 한계로 인해 R³V가 생성하는 CoT annotations에 noise가 포함될 수 있습니다. 이는 CoT quality 저하 및 self-training performance bottleneck으로 이어질 수 있습니다.
- Computational Cost: Iterative self-training process는 considerable computational resources를 요구하며, large-scale experiments 및 hyperparameter tuning에 어려움이 있을 수 있습니다.
- Model Dependency: R³V framework는 base MLLM의 성능에 의존적이며, base model의 capability가 낮은 경우 self-improvement 효과가 제한적일 수 있습니다.
Future Work:
- Higher-Quality CoT Generation: CoT generation model 자체의 성능 향상 (e.g., larger models, improved training methods)을 통해 R³V framework의 self-training data quality를 높이는 연구를 진행할 수 있습니다.
- Advanced MLLMs Exploration: LLaVA, Qwen-VL 외에 더 크고 advanced된 MLLMs (e.g., Gemini, GPT-4V)에 R³V framework를 적용하여 scalability 및 generalization ability를 further investigate 할 수 있습니다.
- Addressing Noisy CoT: Noisy CoT annotations에 robust한 self-training method 개발 (e.g., noise-robust loss functions, CoT filtering techniques)을 통해 R³V framework의 robustness를 향상시킬 수 있습니다.
- Exploring Alternative Self-Reflection Mechanisms: Self-refine 및 self-select loss 외에 다양한 self-reflection mechanisms (e.g., contrastive learning, reinforcement learning)을 R³V framework에 통합하여 self-improvement efficiency를 높이는 연구를 진행할 수 있습니다.
총평:
본 논문은 Multimodal LLMs의 reasoning 능력 향상을 위한 novel self-training framework R³V를 성공적으로 제시하고, 다양한 실험을 통해 framework의 effectiveness를 입증했습니다. 특히, manual annotation 없이 MLLMs 스스로 CoT reasoning 능력을 self-improve할 수 있다는 점, 그리고 self-reflection mechanism을 통해 mistakes로부터 학습하는 novel approach를 제시했다는 점에서 significant contribution을 가진다고 판단됩니다. 향후 Future work 방향을 통해 R³V framework를 더욱 발전시키고, Multimodal reasoning 분야 발전에 기여할 수 있을 것으로 기대됩니다.
Abstract
Chain-of-thought (CoT)는 large language models (LLMs)의 reasoning 능력을 향상시키는 것으로 입증되었습니다. 그러나 multimodal 시나리오의 복잡성과 high-quality CoT data 수집의 어려움으로 인해, multimodal LLMs에서의 CoT reasoning은 크게 간과되었습니다. 이를 위해, 우리는 간단하면서도 효과적인 self-training framework인 R³V를 제안하며, 이는 CoT Rationales에 대한 Reflection을 통해 model의 Vision-language Reasoning을 반복적으로 향상시킵니다. 우리의 framework는 두 가지 interleaved 파트로 구성됩니다. (1) reasoning datasets에 대한 positive 및 negative 솔루션을 반복적으로 bootstrapping하고, (2) mistakes로부터 학습하기 위한 rationale에 대한 reflection입니다. 특히, 우리는 self-refine 및 self-select losses를 도입하여 model이 flawed rationale을 refine하고 rationale 후보들을 비교하여 correct answer를 도출할 수 있도록 합니다. 광범위한 vision-language tasks에 대한 실험은 R³V가 multimodal LLM reasoning을 일관되게 향상시켜 GPT-distilled baselines 대비 23%에서 60%의 상대적 향상을 달성하는 것을 보여줍니다. Additionally, 우리의 접근 방식은 generated solutions에 대한 self-reflection을 지원하여 test-time computation을 통해 performance를 더욱 향상시킵니다.
1 Introduction
인간은 복잡한 reasoning을 수행하기 위해 종종 직관적인 Chain-of-Thought (CoT)에 의존합니다. 이전 연구들은 이러한 CoT capacity가 Large Language Models (LLMs)에서도 나타난다는 것을 보여주었습니다. 간단한 prompting 또는 fine-tuning을 통해 CoT는 LLMs의 reasoning performance를 향상시키면서, 의사 결정 과정에 대한 insights를 제공합니다. 최근에 OpenAI o1은 긴 내부 CoT sequences를 생성하여 reasoning을 더욱 발전시켰으며, LLMs intelligence를 새로운 수준으로 끌어올리고 있습니다.
CoT reasoning은 textual domains에서 LLMs를 크게 발전시켰지만, multimodal settings으로 CoT를 확장하는 것은 여전히 미해결 문제입니다. pre-training corpora에서 풍부하고 unsupervised text-based CoT와는 달리, multimodal CoT resources는 text-dominated 인터넷 컬렉션에서 부족하여 Multimodal LLMs’ (MLLMs) reasoning potential의 완전한 실현을 방해합니다.
최근 연구들은 open-sourced MLLMs가 visual cues를 그들의 reasoning process에 통합하는 데 어려움을 겪어 weak CoT performance를 초래한다는 것을 보여줍니다. Figure 1에서의 우리의 관찰과 일치하게, CoT prompting은 direct prediction에 비해 minimal gains를 제공하며 GPT-4o에 훨씬 뒤쳐집니다. 한 가지 잠재적인 해결책은 post-training을 위해 multimodal CoT annotations를 구축하는 것입니다. 그러나 manual annotation은 엄청나게 비싸고 확장하기 어렵습니다. 이것은 우리의 첫 번째 연구 질문을 제기합니다. MLLMs는 CoT samples에 대한 bootstrapping을 통해 reasoning capabilities를 self-improve할 수 있을까요?
curated CoT annotations에 대한 fine-tuning과는 별개로, positive samples에만 의존하는 것은 reasoning paths의 불충분한 exploration으로 인해 suboptimal policy로 이어질 수 있습니다. 인간 사고에서 영감을 받아, 또 다른 유망한 방향은 trial-and-errors로부터 배우는 것입니다. 여기서 mistakes는 failures가 아니라 reasoning을 향상시킬 수 있는 중요한 기회입니다. 몇 가지 multimodal approaches는 corrupted prompts를 사용하여 preference learning을 위한 negative samples를 생성하여 image comprehension을 개선하는 것을 목표로 합니다. 그러나 이러한 방법들은 reasoning-aligned positive 및 negative CoT solutions를 생성하지 못하여 복잡한 multimodal reasoning tasks에 적합하지 않습니다. 따라서, MLLMs가 reasoning skills를 향상시키기 위해 mistakes로부터 어떻게 효율적으로 학습할 수 있는지는 여전히 해결되지 않은 문제입니다.
위의 두 가지 질문에 답하기 위해, 본 논문은 model이 bootstrapped CoT Rationales에 대해 Reflect하도록 하여 Vision-Language Reasoning을 강화하는 self-training framework인 R³V를 제안합니다. 첫째, 우리는 MLLM의 기존의 그러나 weak CoT 능력을 활용하여 주어진 question에 대한 rationales와 answers를 모두 bootstrap하여 answer correctness를 기반으로 large number의 positive 및 negative solutions를 수집할 수 있도록 합니다. 둘째, 우리는 model이 mistakes로부터 학습하도록 돕기 위해 negative solutions에 대한 reflection mechanism을 도입합니다. Specifically, 우리는 model이 flawed rationales를 correct하고 rationale 후보들을 비교하여 correct answer를 도출하도록 안내하는 self-refine 및 self-select losses를 설계합니다. 위의 synergistic process는 반복될 수 있으며, improved samples는 MLLM의 reasoning을 boosting하고 enhanced model은 rationale generation을 더욱 향상시킵니다. Additionally, self-select training을 통해, 우리의 model은 multiple samples에서 superior solution을 도출하여 test-time computation을 통해 performance를 더욱 boosting할 수 있습니다.
우리는 charts, geometry, commonsense, science, mathematics 등을 포함한 wide range의 multimodal reasoning benchmarks에 걸쳐 experiments를 수행합니다. R³V는 MLLMs의 reasoning ability를 점진적으로 향상시켜 GPT distillation에 비해 23%-60%의 relative accuracy improvement를 제공하며, strong self-training baseline인 STaR을 consistently 능가합니다. Moreover, 우리의 test-time selection은 robust하고 효과적이며, OOD scenarios에서도 Pass@1과 majority voting을 consistently 능가합니다.
우리의 main contributions는 다음과 같습니다:
• 우리는 self-improvement를 위해 MLLM 자체에 의해 bootstrapped된 CoT를 leverage하는 iterative self-training framework R³V를 소개합니다. To our knowledge, 이것은 vision-language reasoning에 self-training을 적용하려는 첫 번째 시도입니다.
• 우리는 reasoning performance를 더욱 향상시키기 위해 test-time computation에 대한 support와 함께 self-reflection을 통해 mistakes로부터 학습하는 것을 제안합니다.
• 우리는 R³V의 effectiveness를 validate하기 위해 6개의 different multimodal domains에 걸쳐 extensive evaluations를 수행합니다. 우리의 analysis는 multimodal self-training의 success를 driving하는 key factors를 reveal합니다.
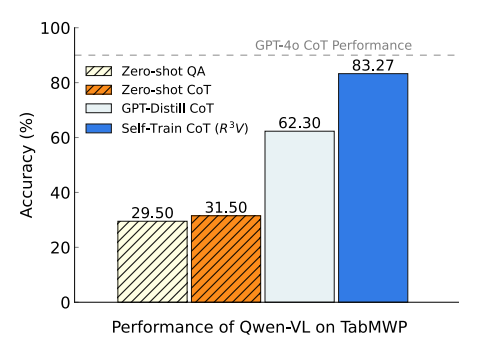
Figure 1: TabMWP, visual mathematical reasoning dataset에서 Qwen-VL의 결과. Qwen-VL은 weak zero-shot CoT reasoning performance를 보이며, 반면 우리의 R³V는 iterative하게 self-improves하여, GPT-distilled baseline을 large margin으로 surpass합니다.
논문 'R³V: Self-Training for Vision-Language Reasoning by Reflecting on CoT Rationales' Introduction 섹션 정리 노트 (AI 연구자용)
🔥 핵심 키워드: Multimodal LLM (MLLM), Vision-Language Reasoning, Chain-of-Thought (CoT), Self-Training, Reflection, Bootstrapping, Error Correction
🎯 문제점:
- MLLM의 CoT reasoning 능력 부족: Textual domain LLM에서는 CoT가 효과적이지만, MLLM 특히 open-source MLLM은 visual 정보를 CoT reasoning에 효과적으로 통합하지 못함. (Figure 1에서 Qwen-VL의 CoT 성능 미미)
- Multimodal CoT 데이터 부족: Pre-training 데이터에서 text-based CoT는 풍부하나, multimodal CoT 데이터는 매우 부족하여 MLLM reasoning potential 제한.
- Manual CoT annotation의 한계: Multimodal CoT 데이터 구축을 위한 manual annotation은 비용 & 확장성 문제.
- 기존 방식의 한계:
- 단순 CoT prompting은 MLLM 성능 향상에 미미한 효과.
- Positive sample 기반 fine-tuning은 reasoning path exploration 부족으로 suboptimal policy 가능성.
- Corrupted prompt 이용 negative sample 생성 방식은 reasoning-aligned CoT solution 생성에 부적합.
💡 제안하는 아이디어: R³V 프레임워크 (Self-Training & Reflection)
- 핵심 컨셉: MLLM 스스로 생성한 CoT Rationales에 대한 Reflection 기반 Self-Training을 통해 Vision-Language Reasoning 능력 향상.
- R³V 작동 방식:
- Iterative Bootstrapping: MLLM의 (weak하지만 존재하는) CoT 능력을 활용하여 Question에 대한 Rationales & Answers를 bootstrap. Answer correctness 기반으로 positive/negative solution 자동 생성.
- Reflection Mechanism (Negative Solution 활용): Mistakes로부터 학습하기 위해 negative solution에 대한 reflection mechanism 도입.
- Self-Refine Loss: Flawed rationale 수정 유도.
- Self-Select Loss: Rationale 후보 비교 통해 correct answer 도출 유도.
- Synergistic Iteration: 향상된 샘플은 MLLM reasoning 능력 향상, 강화된 모델은 더 나은 rationale 생성. (Self-improvement loop)
- Test-time Computation: Self-select training 통해 multiple sample에서 superior solution 선택 가능, test-time performance 향상.
🚀 R³V의 차별점 및 기여:
- Vision-Language Reasoning에 Self-Training 최초 적용 시도: MLLM 자체 CoT bootstrapping 활용 self-improvement framework (R³V) 제시.
- Mistake로부터 학습하는 Self-Reflection 메커니즘 제안: 단순히 데이터 증강이 아닌, error correction 관점의 학습 방식 제시. Test-time computation을 통한 추가 성능 향상 도모.
- 다양한 Multimodal Reasoning Task에서 효과 검증: Charts, geometry, commonsense 등 6개 multimodal domain에서 R³V 효과 입증. GPT distillation baseline 및 STaR 능가.
📝 연구 의의:
R³V는 MLLM의 Vision-Language Reasoning 능력 향상을 위한 새로운 방향 제시. 특히, labeled multimodal CoT 데이터 부족 문제 극복 및 MLLM 스스로 학습 능력 강화 가능성을 보여줌. Self-training 및 reflection 개념을 multimodal reasoning에 성공적으로 적용한 선구적인 연구.
🤔 생각해볼 점:
- R³V 프레임워크의 각 loss function (self-refine, self-select) 구체적인 디자인 및 효과 분석 필요.
- Bootstrapping 과정에서 발생하는 noise 및 self-correction 한계점 존재 가능성.
- 다양한 MLLM architecture 및 task에 대한 R³V framework generalization 연구 필요.
2 Related Work
Vision-Language Reasoning
Extensively studied unimodal reasoning을 넘어서, multimodal reasoning은 최근 인간 지능의 필수적인 부분으로서 상당한 관심을 받고 있습니다. MLLMs는 general vision-language benchmarks에서 좋은 performance를 보이지만, reasoning process에 visual cues를 통합하는 것은 특히 open-source models에게 unique challenges를 제기합니다. 몇몇 연구들은 model을 fine-tune하고 visual-language reasoning capabilities를 향상시키기 위해 rationale datasets를 사용하는 것을 탐구했습니다. 예를 들어, (Gao et al., 2023; Zhang et al., 2024b)는 GPT distillation을 사용하여 기존의 mathematical datasets를 rationales로 augmented했으며, (Yang et al., 2024)는 manually collected CoT annotations를 통해 performance를 향상시켰습니다. In this work, 우리는 MLLMs가 self-improve하여 resource-heavy rationale annotations에 대한 reliance를 줄이는 것을 advocate합니다.
Self-Training Methods
Self-training은 model이 자체적으로 generated outputs로부터 학습하도록 도와주며, labor-intensive human annotations의 필요성을 줄여줍니다. Prior works는 LLM의 reasoning capacity를 향상시키는 데 focused해왔습니다. Typical approach는 multiple rationales를 sampling하고 answers를 기반으로 positive 및 negative solutions를 filtering하는 것을 포함합니다. 그런 다음 LLM은 positive samples에 대해 fine-tuned되거나 preference learning (예: DPO)을 사용하여 improved됩니다. Recent advances는 또한 self-training을 agents 및 neural symbolic scenarios로 extended했습니다. In this paper, 우리는 vision-language reasoning에서 self-training의 exploration을 pioneer하고, multimodal settings에서 DPO의 failure를 investigate하며, 우리의 R³V framework로 이러한 challenges를 address합니다.
논문 'R³V: Self-Training for Vision-Language Reasoning by Reflecting on CoT Rationales' Related Work 섹션 정리 노트 (AI 연구자용)
🔥 핵심 키워드: Multimodal Reasoning, Vision-Language (VL), Self-Training, Rationale Datasets, DPO (Direct Preference Optimization)
📌 Vision-Language Reasoning 분야 선행 연구 동향:
- Multimodal Reasoning 중요성 증가: Unimodal reasoning 연구는 활발했으나, 인간 지능의 핵심 요소인 multimodal reasoning에 대한 관심 급증.
- MLLM의 VL 성능과 한계: General VL benchmarks에서는 MLLM 성능 우수. 그러나, open-source MLLM은 visual cues를 reasoning process에 통합하는 데 여전히 challenge 존재.
- Rationale Datasets 활용 연구:
- Fine-tuning & VL Reasoning 향상: Rationale datasets를 활용하여 MLLM fine-tuning 시도 증가.
- GPT Distillation 활용: Mathematical datasets에 GPT distillation으로 생성한 rationales를 증강 (e.g., Gao et al., Zhang et al.).
- Manual CoT Annotation 활용: 수동으로 구축한 CoT annotations으로 성능 향상 시도 (e.g., Yang et al.).
- 본 논문의 차별점: Resource-heavy rationale annotations에 대한 의존성 감소, MLLM의 self-improvement 방향 제시. 기존 연구들이 외부 데이터 (GPT 생성 또는 수동 annotation)에 의존하는 반면, 본 연구는 MLLM 자체 능력 향상에 집중.
📌 Self-Training 분야 선행 연구 동향:
- Self-Training의 장점: Human annotation 필요성 감소, model 스스로 생성한 output으로부터 학습.
- LLM Reasoning 능력 향상에 Self-Training 활용:
- Typical Approach: Multiple rationales sampling -> answer 기반 positive/negative solutions filtering -> positive samples fine-tuning or preference learning (DPO) 활용.
- Agent 및 Neural Symbolic 분야 확장: Self-training 적용 분야 확장 추세.
- 본 논문의 차별점 및 기여:
- Vision-Language Reasoning에 Self-Training 최초 탐구: LLM text reasoning 중심 self-training 연구에서 VL reasoning으로 영역 확장.
- Multimodal 환경에서 DPO failure 지적 및 분석: 기존 self-training의 preference learning 방식인 DPO의 multimodal setting 한계점 지적.
- R³V Framework 제시: Multimodal DPO의 문제점을 해결하고 VL reasoning self-training을 효과적으로 구현하는 R³V 프레임워크 제안.
🔑 핵심 요약:
본 논문은 기존 VL reasoning 연구들이 external rationale data에 의존하는 한계를 지적하며, MLLM self-improvement를 위한 self-training framework R³V를 제시. 특히, text domain 중심 self-training 연구를 VL reasoning으로 확장하고, multimodal 환경에서 DPO의 문제점을 극복하는 새로운 접근 방식이라는 점에서 차별성을 가짐. Rationale annotation cost 문제 해결 및 MLLM 자체 reasoning 능력 강화에 기여할 것으로 기대.
3 Methodology
Our self-training framework는 두 가지 alternating components로 구성됩니다: (1) multimodal questions에 대한 large number의 positive and negative CoT solutions bootstrapping (Section 3.1); (2) rationales에 대해 reflect하고 mistakes로부터 learn하기 위해 위에서 sampled된 solutions를 사용하는 것 (Section 3.2). 이 iterative process는 MLLM을 weak에서 strong으로 변화시킵니다. 전체 framework는 Figure 2에 illustrated되어 있습니다.
3.1 Preliminaries
vision-language reasoning에서, image I와 question x가 주어졌을 때, multimodal large language model은 reasoning을 위해 image와 question 모두로부터 information을 integrate하고, CoT rationale r을 generating한 다음 final answer a를 derive해야 합니다. However, high-quality rationale data를 collecting하는 데 어려움이 있기 때문에, large-scale (I, x, r, a) pairs를 constructing하는 것은 significant challenges를 presents합니다. 이것은 fine-tuning을 통한 MLLM reasoning capacities의 enhancement를 hinders합니다.
이러한 limitation을 overcome하기 위해, 우리는 widely available vision question answering data (I, x, a)로부터 (I, x, r, a) pairs를 iteratively augment하기 위해 MLLM의 pre-existing but weak CoT capability를 leveraging하여 model이 self-improve하도록 propose합니다.
STaR을 Following하여, MLLM self-training process는 self-generated rationale data에 대한 iterative fine-tuning을 involves합니다. Each iteration t에서, training set D = {(I, x, aˆ)}로부터 question x가 주어졌을 때, MLLM M은 먼저 answer a와 함께 CoT rationale r을 generate하며, {(ri, ai)}|D|i=1로 formulated됩니다. 이러한 intermediate outputs은 original training set과 combined되어, rationales를 includes하는 augmented dataset을 result합니다:
Dr = {(Ii, xi, ri, ai)}|D|i=1 (1)
correct answers로 이어지는 rationales는 그렇지 않은 rationales에 비해 higher quality라고 assuming하면, 우리는 answers의 correctness를 기반으로 Dr을 positive 및 negative sample sets로 divide할 수 있습니다:
D+r = {(Ii, xi, ri, ai) | ai = ˆai}|D|i=1 (2)
D−r = {(Ii, xi, ri, ai) | ai ̸= ˆai}|D|i=1 (3)
그런 다음 우리는 negative log-likelihood objective를 사용하는 supervised fine-tuning (SFT)을 사용하여 filtered positive CoT samples D+r에 대해 model M을 fine-tune합니다:
LSF T = −∑(I,x,y)∼Dt logM(y | x, I), (4)
여기서 y = (r, a)는 model에 의해 generated된 solution입니다. 우리는 performance가 plateaus될 때까지 newly fine-tuned model로 new rationales를 generating하면서 위의 process를 continue repeating합니다.
3.2 R³V: Reflection on Rationales
위의 self-improvement process는 positive solutions를 사용하여 model을 strengthens하는 반면, negative solution들은 typically discarded됩니다. However, negative samples는 sampled된 solutions의 large portion을 comprise하고 further model enhancement를 위한 valuable insights를 offer합니다. 우리의 preliminary experiments에서, 우리는 multimodal scenarios에서 CoT의 noisy nature가 DPO를 사용할 때 suboptimal performance로 이어진다는 것을 found했습니다. humans의 error-driven learning에서 inspired되어, 우리는 model에게 자신의 mistakes를 correct하고 correct solution을 identify하기 위해 multiple reasoning paths에 대해 reflect하도록 teaching하는 rationales에 대한 reflection을 introduce합니다. Specifically, 우리는 multi-task learning을 위해 additional self-refine (Section 3.2.1) 및 self-select (Section 3.2.2) losses를 propose합니다. Our framework는 self-training에서 positive and negative samples의 continuous production을 harnesses하여, mistakes로부터 learning하기 위한 robust하고 effective solution을 offering합니다. Appendix E는 R³V의 different components의 examples를 provides합니다.
3.2.1 Self-Refine
문제를 solve하는 데 failing하는 경우, human students는 자신의 solutions에서 errors를 analyze하고 어떻게 correct할지 reflect할 것입니다. 이것에서 inspired되어, 우리는 model이 자신의 generated solutions에서 flaws를 correct하도록 encourage하기 위해 self-refine mechanism을 designed했습니다.
self-training 동안 sampled된 Multiple positive and negative solutions는 same problem에 대한 model의 repeated reasoning으로 viewed될 수 있으며, self-refine training에 well-suited하게 만듭니다. Specifically, 우리는 다음과 같이 self-refine를 위한 dataset을 construct합니다:
DREF = {(Ii, xi, y+i, y−i) | ∃ y+i, y−i}|D|i=1, (5)
여기서 y+i 및 y−i는 preceding iterations에서 obtained된 positive and negative samples입니다. Next, self-refine loss는 self-generated answers에서 errors를 correcting하는 데 model을 guide하기 위해 employed됩니다:
LREF = −∑(I,x,y+,y−)∼DREF logM(y+ | y−, x, I) (6)
self-training iterations throughout에서, self-refine를 위한 samples는 higher-quality positive solutions와 harder negative solutions를 incorporate하기 위해 continuously updated됩니다.
3.2.2 Self-Select
Our early explorations는 MLLM reasoning에서 key challenge를 reveal합니다: current MLLMs는 frequently chart numbers misreading 또는 calculation mistakes와 같은 simple errors를 make하지만, autoregressive model은 them을 correct할 mechanism이 없어 suboptimal performance로 이어집니다. In contrast, human reasoners는 implicitly multiple reasoning paths를 simulate하고, errors를 check하고, best one을 select합니다.
이것에서 inspired되어, 우리는 MLLMs가 multiple candidate solutions에서 correct answer를 derive하도록 guiding하는 self-selection mechanism을 introduce합니다.
sampled rationales의 set이 주어지면, model은 their differences를 analyze하고 finally correct answer를 select해야 합니다. Specifically, 우리는 다음과 같이 self-select dataset을 construct합니다:
DSEL = {(Ii, xi, aˆi, Ci) | ∃ Ci }|D|i=1, (7)
여기서 aˆ는 ground truth이고 Ci = (y1i, y2i, ..., yNi)는 N sampled rationale-answer pair의 set입니다. 우리의 experiments에서, N은 by default 3으로 set됩니다. 우리는 candidate set C가 model이 final correct answer를 select할 수 있도록 at least one positive solution y+를 contains하는 것을 ensure합니다. Then, self-select loss는 다음과 같이 defined됩니다:
LSEL = −∑(I,x,a, ˆ C)∼DSEL logM(ˆa|x, I, C) (8)
Finally, our framework는 MLLM reasoning을 enhance하기 위해 multi-task training setup에서 three loss functions를 combines합니다 (Appendix D의 algorithm 참조):
LR³V = LSF T + LREF + LSEL (9)
Another perspective에서, 우리는 이 multi-task training이 MLLMs가 easy에서 hard로 reasoning을 learn하도록 enable한다고 argue합니다: multiple candidates에서 correct solution을 selecting, existing rationales를 refining, and eventually solutions를 directly generating.
3.2.3 Test-Time Selection
self-select training을 통해, our framework는 MLLMs가 자신의 self-generated solutions에 reflect하고 multiple reasoning paths에서 final answer를 select하도록 enable합니다. inference during에서, question x와 corresponding image I가 주어지면, 우리는 먼저 candidate set C를 form하기 위해 multiple reasoning solutions를 sample합니다. Next, MLLM은 이러한 candidate solutions에서 best answer를 select하도록 prompted됩니다: a = M(x, I, C).
Test-time selection은 complex multimodal reasoning을 tackle하기 위해 MLLMs를 위한 novel approach를 offers합니다. directly answer를 generating하는 instead of, model은 different reasoning paths를 comparing하고 most likely correct solution을 identify하기 위해 errors (예: visual recognition, calculation, or reasoning mistakes)를 checking하여 elimination method를 applies합니다. In this way, our approach는 test-time computation을 통해 reasoning performance를 further boosts합니다.
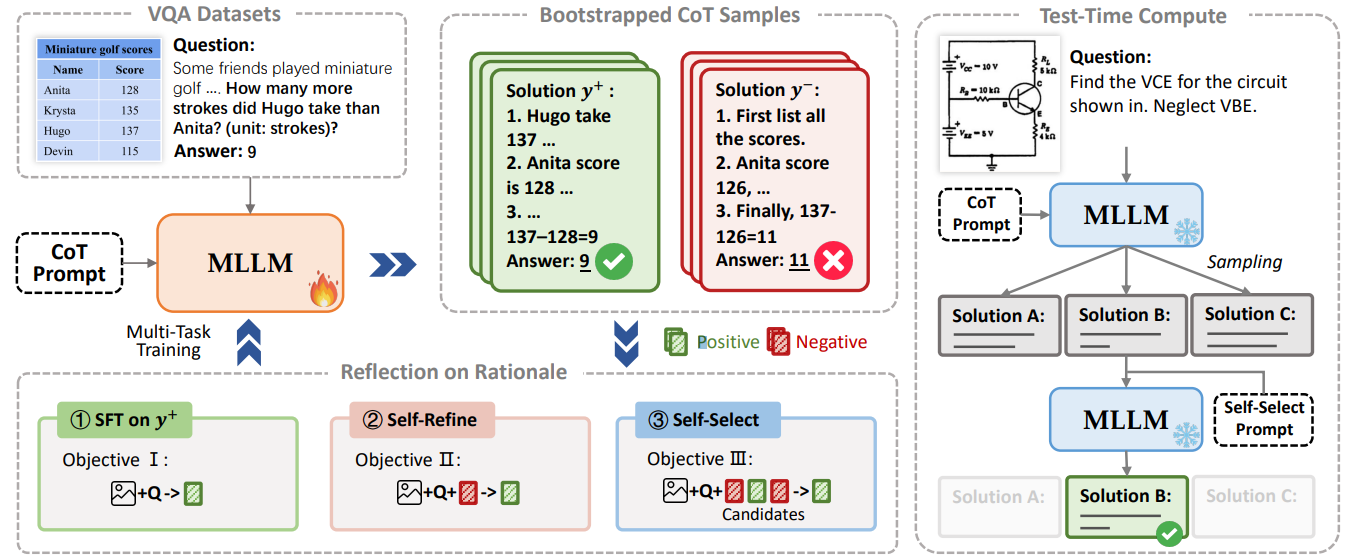
Figure 2: 우리 multimodal self-training framework인 R³V의 개요. R³V는 bootstrapped CoT rationales에 대한 iterative reflection을 통해 vision-language reasoning을 향상시키고, test-time computing을 통해 self-reflection을 가능하게 합니다.
논문 'R³V: Self-Training for Vision-Language Reasoning by Reflecting on CoT Rationales' Methodology 섹션 정리 노트 (AI 연구자용)
🔥 핵심 아이디어: Reflection 기반 Self-Training (R³V)를 통한 MLLM Vision-Language Reasoning 능력 강화
🛠️ R³V 프레임워크 구성: 2-Phase Iterative Process
Phase 1: CoT Solution Bootstrapping (Preliminary Stage)
- 목표: Multimodal QA 데이터 (I, x, a)로부터 Self-Training에 필요한 대규모 CoT rationale 데이터 (I, x, r, a) 자동 생성.
- 방법:
- MLLM의 pre-trained된 weak CoT 능력 활용.
- 입력 (Image I, Question x)에 대해 CoT rationale r과 answer a를 함께 생성.
- Answer correctness (generated answer a vs. ground truth ˆa) 기준으로 Positive (D+r) & Negative (D−r) CoT solution set 분리.
- 핵심: Labeled CoT 데이터 부족 문제 극복, MLLM 자체 생성 데이터 활용 Self-Training 기반 마련. (STaR 방법론 VL 영역 확장)
Phase 2: Reflection on Rationales (Error Correction & Refinement)
- 핵심 컨셉: Negative CoT solutions (mistakes)를 단순 폐기하는 대신, Error-Driven Learning & Rationale Reflection 메커니즘 도입하여 MLLM 학습 효과 극대화.
- Loss Function 구성 (Multi-Task Learning):
- LSFT (Supervised Fine-Tuning Loss): Positive CoT solutions (D+r) 기반 SFT. 기본적인 Reasoning 능력 강화.
- LSF T = −∑(I,x,y)∼Dt logM(y | x, I) (y = (r, a))
- LREF (Self-Refine Loss): Flawed rationale 수정 학습. Positive solution (y+) 생성을 위해 Negative solution (y−) 정보 활용.
- DREF = {(Ii, xi, y+i, y−i) | ∃ y+i, y−i}
- LREF = −∑(I,x,y+,y−)∼DREF logM(y+ | y−, x, I)
- Novelty: Negative sample을 단순 폐기 대신, refinement 과정에 활용. Error correction 능력 학습 유도.
- LSEL (Self-Select Loss): Multiple CoT candidate solutions (C)에서 정답 (ˆa) 선택 학습. Human-like error checking & best solution selection 모방.
- DSEL = {(Ii, xi, aˆi, Ci) | ∃ Ci } (Ci = {y1i, y2i, ..., yNi}, N=3 default)
- LSEL = −∑(I,x,a, ˆ C)∼DSEL logM(ˆa|x, I, C)
- Novelty: Autoregressive MLLM의 단순 오류 (계산 실수, 오독 등) 보정 메커니즘 부재 문제 해결. Multiple reasoning path 비교 & 최적 해 선택 능력 학습.
- LSFT (Supervised Fine-Tuning Loss): Positive CoT solutions (D+r) 기반 SFT. 기본적인 Reasoning 능력 강화.
- 종합 Loss: LR³V = LSF T + LREF + LSEL (Multi-task learning, Appendix D 알고리즘 참조)
- 학습 진행: Iterative bootstrapping & reflection 과정을 반복하며 MLLM 점진적 성능 향상.
🧪 Test-Time Selection (Inference 시 활용)
- Self-Select 학습 효과 활용: Inference 시, multiple CoT solutions (C) sampling 후, MLLM에게 최적 answer 선택하도록 prompt.
- 장점: Direct answer generation 방식 대비, 복잡한 Multimodal Reasoning task에서 Error Elimination & Performance Boost 효과.
🔑 핵심 기여 및 의의:
- Vision-Language Reasoning Self-Training 프레임워크 R³V 제시: Multimodal CoT 데이터 부족 문제 해결, MLLM 자체 Self-Improvement 가능성 제시.
- Reflection Mechanism (Self-Refine & Self-Select Loss) 도입: Negative samples를 활용한 Error Correction & Multiple Reasoning Path 고려 학습 방식 Novelty.
- Test-Time Selection: Inference 단계에서 Self-Select 학습 효과 활용, 추가적인 성능 향상 도모.
- Multimodal Reasoning Task 성능 대폭 향상: 실험적으로 R³V 효과 입증 (GPT distillation baseline, STaR 능가).
🤔 추가적으로 고려할 점:
- 각 Loss function의 hyperparameter tuning 및 ablation study 분석 필요.
- Self-training iteration 횟수 및 수렴 조건에 대한 연구.
- R³V framework의 다양한 MLLM architecture 및 downstream task 적용 가능성 탐색.