VLM : 논문리뷰 : ImagePiece: Content-aware Re-tokenization for Efficient Image Recognition
ImagePiece: Content-aware Re-tokenization for Efficient Image Recognition 정리 노트
Purpose of the Paper (논문의 목적)
기존 Vision Transformer (ViT)의 효율성 개선 연구들은 주로 토큰 가지치기(token pruning)나 토큰 병합(token merging)에 집중했지만, ViT의 기본적인 토큰화 방식인 비겹침 그리드 패치(non-overlapping grid patches)는 개별 토큰이 충분한 의미 정보를 담고 있지 못하다는 근본적인 문제를 안고 있습니다. 이러한 비효율적인 토큰화 방식은 효율적인 ViT를 만드는데 걸림돌이 됩니다.
ImagePiece 논문은 이러한 문제점을 해결하고자 새로운 Content-aware Re-tokenization 전략을 제시합니다. 핵심 아이디어는 NLP의 MaxMatch 토큰화 전략을 이미지에 적용하여, 의미적으로 불충분하지만 지역적으로 일관성 있는 토큰들을 의미 있는 단위로 재구성하는 것입니다. 이를 통해 ViT가 효율적이면서도 효과적으로 이미지 인식을 수행하도록 돕는 것을 목표로 합니다. 단순히 속도 향상뿐만 아니라, 토큰의 의미론적 풍부성을 높여 성능 향상까지 도모하는 것이 이 논문의 특별한 목적입니다.
Key Contributions (핵심 기여)
- ImagePiece Re-tokenization Strategy: ViT의 효율성을 높이기 위한 새로운 재토큰화 전략 제시.
- 의미적으로 불충분한 토큰들을 응축하여 의미 있는 토큰으로 재구성.
- 재토큰화 후 토큰의 의미를 재평가하고, 문맥 정보를 통해 의미를 획득한 토큰들을 재조직화.
- Local Coherence Bias Module: 시각적 장면의 지역적 귀납 편향(local inductive bias)을 활용하기 위한 모듈 도입.
- 겹침 컨볼루션 레이어(overlapping convolution layers)를 사용하여 위치적으로 가까운 비의미적 토큰들을 응축하도록 유도.
- 시각적 장면의 지역적 특징을 고려하여 토큰들이 의미 있는 정보(예: 물체의 부분)를 형성하도록 도움.
- Superior Performance and Robust Hyper-speed Inference: ImageNet 분류 실험에서 ImagePiece의 우수한 성능과 속도 향상 입증.
- DeiT-S 모델에 적용 시, 54%의 속도 향상과 0.39%의 정확도 향상 달성.
- Hyper-speed inference 시나리오에서 기존 baseline 대비 높은 정확도 유지 및 능가.
- Compatibility with Token-Pruning: ImagePiece는 기존 토큰 가지치기 방법들과 높은 호환성을 가짐.
- 재토큰화 후에도 토큰 가지치기 기법을 효과적으로 적용 가능.
- 기존 토큰 가지치기 방법들과 결합하여 성능 향상 및 효율성 극대화.
Novelty (새로움)
- Content-aware Re-tokenization: 기존 ViT 토큰화 방식의 한계를 극복하고, 이미지 내용에 기반한 새로운 토큰화 접근 방식 제시.
- 단순히 토큰 수를 줄이는 것이 아니라, 토큰 자체의 의미를 풍부하게 만드는 데 집중.
- NLP의 subword tokenization 방식 (MaxMatch)을 이미지 도메인에 성공적으로 적용.
- Local Coherence Bias: 시각적 정보의 특성을 고려한 지역적 귀납 편향 모듈 도입.
- 이미지 패치들의 지역적 연관성을 활용하여 의미 있는 토큰을 형성하도록 유도.
- ViT가 시각적 장면을 더 잘 이해하도록 돕고, 재토큰화 과정의 효과를 증대시킴.
- Re-evaluation of Token Semantics: 초기 중요도 평가 후, 재토큰화를 통해 의미를 획득한 토큰들을 재평가하는 과정 도입.
- 초기에는 비의미적으로 보였던 토큰이 문맥 정보를 통해 중요한 의미를 가질 수 있음을 고려.
- 토큰 가지치기 과정에서 정보 손실을 최소화하고, 모델의 성능을 유지하는 데 기여.
Experimental Highlights (실험 결과 하이라이트)
- ImageNet Classification: DeiT-Ti 및 DeiT-S 모델에 ImagePiece 적용 결과, 기존 baseline 모델 대비 높은 정확도와 향상된 throughput 달성. 특히 DeiT-S의 경우, 54%의 속도 향상과 함께 0.39%의 정확도 향상이라는 놀라운 결과 기록.
- Comparison with Prior Methods: 기존 토큰 가지치기 (DynamicViT, EViT) 및 토큰 병합 (ToMe, Token Pooling, Token Learner) 방법들과 비교 실험. ImagePiece가 모든 baseline 방법들을 능가하는 성능 입증. 특히 토큰 병합 방법들과 비교 시, 평균 3.65% 높은 정확도를 보임.
- Hyper-speed Inference: 다양한 속도 조건에서 성능 평가. ImagePiece는 속도가 빨라질수록 baseline 모델과의 성능 격차가 커지는 경향을 보이며, hyper-speed inference 환경에서 뛰어난 robustness 입증. DeiT-S 대비 2.51배 빠른 속도에서 DynamicViT, EViT, ToMe는 각각 20.05%, 13.99%, 9.24% 정확도 감소를 보였지만, ImagePiece는 6.28% 감소에 그침.
- Robustness to Random Masking Noise: 랜덤 마스크 노이즈 환경에서의 robustness 평가. ImagePiece는 노이즈가 증가하는 상황에서도 baseline 모델 대비 높은 성능 유지. 특히 마스크 수가 7개일 때, baseline 대비 1.4% 높은 정확도를 보였으며, 마스크 수가 증가할수록 격차가 더욱 커짐 (최대 5.2%).
- Ablation Study: Local Coherence Bias 모듈의 효과 분석. 해당 모듈 제거 시 성능이 감소하는 것을 확인하여, Local Coherence Bias 모듈이 ImagePiece 성능에 중요한 역할을 수행함을 입증 (79.81% vs 80.22%).
Limitations and Future Work (한계점 및 향후 연구)
논문에서 명시적인 한계점 섹션은 없지만, 실험 결과 및 분석을 통해 다음과 같은 한계점 및 향후 연구 방향을 추론할 수 있습니다.
- Hyperparameter Tuning: ImagePiece는 여러 hyperparameter (e.g., non-semantic token 비율 p, 유사도 병합 비율, 가지치기 비율 r)를 사용합니다. 이러한 hyperparameter들이 성능에 미치는 영향에 대한 심층적인 분석 및 최적화 연구가 필요합니다. 논문에서는 특정 hyperparameter 설정 (p=0.3, merging ratio=0.08, pruning ratio=0.8)을 사용했지만, 다른 설정에 대한 탐색 및 자동 hyperparameter 튜닝 방법 연구가 필요할 수 있습니다.
- Generalizability to Other ViT Architectures: ImagePiece는 DeiT 모델을 기반으로 실험이 진행되었습니다. 향후 Swin Transformer, MobileViT 등 다양한 ViT architecture에 대한 적용 가능성 및 효과를 검증하는 연구가 필요합니다. 특히 architecture별 최적의 Local Coherence Bias 모듈 구조 및 hyperparameter 설정에 대한 연구가 필요할 수 있습니다.
- Application to Other Vision Tasks: ImagePiece는 ImageNet 이미지 분류 task에 집중하여 성능을 검증했습니다. Semantic segmentation, object detection 등 다른 vision task에 대한 적용 가능성 및 효과를 탐색하는 연구가 필요합니다. Task별 최적의 재토큰화 전략 및 Local Coherence Bias 모듈 구조에 대한 연구가 필요할 수 있습니다.
- Deeper Analysis of Local Coherence Bias: Local Coherence Bias 모듈의 구조 (컨볼루션 레이어 구성)가 비교적 단순합니다. 향후 더 효과적인 Local Coherence Bias 모듈 구조 (e.g., attention mechanism 기반, deformable convolution 활용 등)를 탐색하고, 시각적 장면 이해에 미치는 영향을 심층적으로 분석하는 연구가 필요합니다.
- Beyond MaxMatch Strategy: ImagePiece는 NLP의 MaxMatch 전략에서 영감을 얻었지만, 더 정교하고 효과적인 재토큰화 전략을 탐색할 수 있습니다. 예를 들어, semantic segmentation 정보를 활용한 content-aware 토큰 병합, attention mechanism을 활용한 adaptive re-tokenization 등 다양한 접근 방식을 연구해볼 수 있습니다.
Overall (총평)
ImagePiece 논문은 ViT의 효율성 및 성능 향상을 위한 새로운 Content-aware Re-tokenization 전략을 성공적으로 제시했습니다. 특히 Local Coherence Bias 모듈과 재토큰화 후 토큰 의미 재평가라는 novelty를 통해 기존 방법들의 한계를 극복하고, ImageNet 분류 task에서 뛰어난 성능과 속도 향상을 입증했습니다. Hyper-speed inference 및 noise robustness 실험 결과는 ImagePiece의 실용적인 가치를 더욱 높여줍니다. 향후 다양한 ViT architecture 및 vision task에 대한 적용 연구, 그리고 재토큰화 전략 및 Local Coherence Bias 모듈 개선 연구를 통해 ImagePiece의 잠재력을 더욱 확장할 수 있을 것으로 기대됩니다.
Abstract
Vision Transformers (ViTs)는 다양한 컴퓨터 비전 작업에서 놀라운 성과를 거두었습니다. 그러나 ViTs는 multi-head self-attention (MHSA)에 대한 본질적인 의존성으로 인해 막대한 계산 비용이 발생하며, 이는 실질적인 적용을 위해 ViTs를 가속화하려는 노력을 촉발시켰습니다. 이를 위해, 최근 연구들은 주로 토큰을 효과적으로 가지치기(pruning)하거나 병합하는 방법에 초점을 맞춰 토큰 수를 줄이는 것을 목표로 합니다. 그럼에도 불구하고, ViT 토큰은 겹치지 않는 그리드 패치에서 생성되기 때문에 일반적으로 충분한 의미를 전달하지 않아 효율적인 ViTs와 호환되지 않습니다. 이 문제를 해결하기 위해, 우리는 Vision Transformers를 위한 새로운 re-tokenization 전략인 ImagePiece를 제안합니다. NLP 토큰화의 MaxMatch 전략을 따라, ImagePiece는 의미적으로 불충분하지만 국부적으로 일관된 토큰을 의미를 전달할 때까지 그룹화합니다. 이 간단한 re-tokenization은 이전 토큰 감소 방법과 매우 호환되며, 관련 토큰을 크게 좁혀 DeiT-S의 추론 속도를 54% 향상(거의 1.5배 더 빠름)시키면서 ImageNet 분류 정확도에서 0.39%의 개선을 달성합니다. 초고속 추론 시나리오(251% 가속)의 경우, 우리의 접근 방식은 다른 baseline보다 8% 이상 높은 정확도를 능가합니다.
Introduction
“반짝인다고 모두 금은 아니며, 방황하는 자가 모두 길을 잃은 것은 아니다.” — J.R.R. Tolkien
Tokenization은 텍스트를 토큰이라고 하는 더 작은 단위(예: 단어)로 분해하는 것을 포함하며, 거의 모든 Natural Language Processing (NLP) 작업에 중요한 전처리 단계입니다. BERT , GPT , XLNet 과 같은 최신 NLP models은 텍스트를 하위 단어 단위로 토큰화합니다. 이러한 하위 단어 단위는 단어와 문자 사이의 균형을 유지하여 언어적 의미를 보존하는 동시에 비교적 작은 어휘로도 어휘 부족 문제를 최소화합니다. wordpiece 와 같은 하위 단어 tokenizer는 탐욕적 최장 일치 우선(longest-match-first) 전략을 사용하여 어휘 토큰과 일치하는 나머지 텍스트의 가장 긴 접두사를 반복적으로 선택합니다. 이 방법을 Maximum Matching 또는 MaxMatch라고 합니다.
NLP의 WordPiece와 비교한 ImagePiece 파이프라인의 그림입니다. 텍스트는 의미 있는 토큰으로 토큰화되는 반면, 패치의 이미지 토큰은 종종 관련이 없거나 비의미적 정보를 포함합니다. ImagePiece의 retokenization은 이러한 비의미적 토큰이 특히 retokenization 후에 의미가 있을 가능성이 있는 경우 의미 있는 토큰으로 병합될 수 있도록 합니다.
Natural Language Processing에서 Transformers의 선구적인 성공에 이어, Vision Transformers 는 광범위한 컴퓨터 비전 작업에서 놀라운 성능을 보여주었습니다. 이미지의 맥락에서, tokenization은 이미지를 겹치지 않는 그리드 패치로 분할하고 이러한 패치의 linear embeddings의 sequence를 Transformer에 공급하는 것을 포함합니다. 여기서 이미지 패치는 NLP의 토큰(단어)과 유사하게 취급됩니다. 그러나 대부분의 요소가 이해에 기여하는 의미를 포함하는 하위 단어에서 비롯된 텍스트 토큰과 달리, 이미지 패치 기반 토큰은 1) 전체 의미와 전혀 관련이 없는 의미를 포함하거나(예: 도로, 하늘, 배경) 2) 의미를 전달하기 위해 더 넓은 맥락이 필요한 경우가 많기 때문에 크게 다릅니다(예를 들어, 그림 1에서 파란색 패치 자체(a)는 의미를 거의 포함하지 않지만, 근처 패치(b)와 함께 수집하면 '버스'로 올바르게 인식될 수 있습니다).
이 현상은 ViTs를 간소화하는 추가 작업, 즉 입력 토큰 수를 줄이는 작업에서 더 심각한 문제가 됩니다. ViTs에서 토큰 감소는 주로 1) 토큰 가지치기(pruning): 주의를 기울이지 않는 토큰 제거 또는 2) 토큰 병합: 중복(또는 유사한) 토큰을 새로운 추상화로 융합하는 두 가지 주요 방법을 통해 달성됩니다. 두 접근 방식 모두 Vision Transformers (ViTs)의 복잡성을 효과적으로 줄입니다. 그러나 패치 기반 토큰화의 한계로 인해, 이로 인해 1) 의미가 완전히 맥락화되기 전에 토큰을 너무 성급하게 버리거나 2) 의미 토큰을 가장 가까운 유사성의 비의미적 노이즈와 조기에 평활화하여 특정 장면에서 토큰 가지치기(pruning)보다 더 심각한 성능 저하를 초래합니다.
이 문제를 해결하기 위해, 우리는 Vision Transformers를 위한 새로운 re-tokenization 전략인 ImagePiece를 제안합니다. NLP 토큰화의 MaxMatch 전략에 따라, ImagePiece는 의미적으로 불충분한(하위 k개) 토큰을 의미를 전달하는 수준까지 그룹화합니다. 시각적 장면에 대한 국소적 귀납적 편향을 추가하기 위해, 우리는 겹치는 convolution layers로 구성된 국소적 일관성 편향 모듈을 추가하여 유사한 위치를 가진 비의미적 패치가 더 높은 유사도를 갖도록 강화합니다. 이를 통해 re-tokenization은 근처의 비의미적 토큰을 의미 있는 토큰이 형성될 때까지(또는 전체 의미와 관련이 없게 될 때까지) 병합하도록 촉진합니다. 그런 다음, 주의를 기울이지 않는 토큰의 의미적 추상화의 attention score가 다시 측정됩니다. 추상화가 전체 시각적 의미와 관련성을 얻으면 토큰이 다시 구성됩니다. 추가적인 효율성을 위해, 우리의 re-tokenization 후에도 최종 의미에 참여하지 않는 토큰은 버려집니다.
ImagePiece는 다음과 같은 몇 가지 주요 이점을 제공합니다. 1) 흩어져 있는 주의를 기울이지 않는 토큰의 국소적으로 일관된 덩어리가 의미론적으로 의미 있는 추상화를 형성하도록 병합되어, 모델이 잘 informed된 contextualization 또는 가지치기(pruning)를 수행할 수 있도록 합니다. 2) 의미적으로 중요한 정보를 포함하는 주의 토큰은 병합(또는 평활화)되지 않도록 보존되어 이전 토큰 병합 파이프라인의 한계를 완화합니다. 이러한 이점 덕분에 ImagePiece는 관련 토큰을 크게 좁혀 DeiT-S의 추론 속도를 54%(거의 1.5배 더 빠름) 향상시키면서 ImageNet 분류 정확도에서 0.39%의 개선을 달성할 수 있습니다. 이는 효율적인 ViTs의 다른 baseline들이 이러한 속도 향상을 위한 절충안으로 무시할 수 없는 성능 저하를 겪는다는 점을 고려할 때 주목할 만합니다. 우리의 기여는 세 가지입니다.
- 우리는 의미적으로 관련 없는 토큰을 압축하는 효율적인 vision transformers를 위한 새로운 retokenization 전략인 ImagePiece를 소개합니다. 압축 후, 토큰의 의미는 더 많은 맥락적 정보를 얻음으로써 의미를 얻은 토큰을 재구성하면서 재평가됩니다.
- 국소적 일관성 편향을 통해, 위치적으로 가까운 비의미적 토큰이 함께 압축되어 시각적 장면에 대한 국소적 귀납적 편향을 추가합니다. 여러 번의 반복 후에도 관련성이 없는 압축된 토큰은 효율성을 위해 버려집니다.
- 우리의 방법은 ImageNet 분류에서 우수한 성능을 달성하고, 기존 baseline을 능가하는 초고속 추론에서 robust한 성능을 보여줍니다.
1. 문제의식: ViT 토큰화의 비효율성
- 기존 ViT의 문제점:
- ViT는 이미지를 겹치지 않는(non-overlapping) 그리드 패치로 나누어 토큰화합니다.
- 이 방식은 NLP의 subword 토큰화와 달리, 개별 패치 토큰이 충분한 의미를 담지 못하는 경우가 많습니다. (e.g., 하늘, 도로, 배경 등)
- 특히, ViT의 연산량을 줄이기 위해 토큰 수를 줄이는(token reduction) 연구들에서 이 문제는 더욱 심각해집니다.
- Token Reduction의 딜레마:
- Token Pruning: 의미가 완전히 파악되기 전에 토큰을 성급하게 제거할 위험.
- Token Merging: 의미 있는 토큰을 주변의 비의미적 노이즈와 섣불리 섞어버릴 위험. (특정 상황에서는 pruning보다 심각한 성능 저하 초래 가능)
2. ImagePiece: ViT를 위한 새로운 Re-tokenization
- 핵심 아이디어: NLP의 MaxMatch 전략에서 영감을 받아, 의미적으로 불충분한 토큰들을 "의미를 가질 때까지" 국부적으로(locally) 결합하는 re-tokenization 방법론, ImagePiece를 제안합니다.
- MaxMatch in Vision:
- NLP의 MaxMatch는 어휘(vocabulary) 내에서 최장 일치하는 토큰을 찾는 방식입니다.
- ImagePiece는 "의미적으로 불충분한 (하위 k개)" 토큰들을 대상으로 MaxMatch와 유사한 방식으로 결합을 시도합니다.
- 국소적 일관성 편향 (Local Coherence Bias):
- 단순히 MaxMatch를 적용하는 것이 아니라, 시각적 장면에 대한 inductive bias를 추가합니다.
- Overlapping convolution 연산을 통해 공간적으로 인접한 비의미적 토큰들이 더 잘 결합되도록 유도합니다. (e.g., 하늘, 도로 조각들이 더 잘 합쳐지도록)
3. ImagePiece의 작동 방식 및 이점
- Re-tokenization & Re-evaluation:
- 의미가 불충분했던 토큰들이 결합하여 새로운 추상화를 형성합니다.
- 이 추상화의 attention score를 다시 계산하여, 전체 이미지의 의미와 관련성이 높아졌는지 평가합니다.
- 관련성이 높아졌다면 해당 토큰을 유지, 그렇지 않으면 가지치기(pruning)합니다.
- 주요 이점:
- 정보에 입각한(well-informed) contextualization 또는 pruning 가능.
- 의미 있는 토큰이 주변 노이즈와 섞이는 것을 방지.
4. 성능 및 기여
- DeiT-S 기준: 추론 속도 54% 향상 (약 1.5배), ImageNet 분류 정확도 0.39% 개선.
- 핵심 기여:
- 의미적으로 관련 없는 토큰을 효율적으로 압축하는 새로운 re-tokenization 전략, ImagePiece 제안.
- 국소적 일관성 편향을 통해 비의미적 토큰의 결합을 촉진.
- 초고속 추론 시나리오에서도 견고한 성능 달성.
결론: ImagePiece는 ViT의 고질적인 문제였던 비효율적인 토큰화 문제를 "re-tokenization"이라는 새로운 관점으로 접근하여, 성능과 효율성을 모두 향상시킨 혁신적인 연구입니다. 특히, 시각적 장면에 특화된 inductive bias를 추가하여 토큰 결합의 효율성을 높인 점이 주목할 만합니다. 이 연구는 ViT의 실용성 증대에 크게 기여할 것으로 예상됩니다.
Related Work
Vision Transformers. 원래 NLP에서 널리 사용되었던 Transformers는 최근 long-range dependencies를 모델링하는 뛰어난 능력으로 인해 computer vision에서 큰 주목을 받고 있습니다. Vision Transformers (ViTs)는 computer vision 분야에 Transformer 백본을 처음 도입했으며, 아키텍처 개선에서 최적화 기술에 이르기까지 다양한 측면에서 ViTs에 대한 다양한 연구가 그들의 성공을 입증했습니다.
Transformers의 NLP 및 computer vision 적용 간의 핵심 차이점 중 하나는 입력 데이터가 토큰화되는 방식에 있습니다. NLP에서는 WordPiece 및 SentencePiece 와 같은 방법이 텍스트를 하위 단어나 문자로 토큰화하며, 각 토큰은 의미 있는 의미론적 내용을 전달합니다. 반대로, 이미지가 ViTs를 위해 패치로 분할될 때, 이러한 패치는 토큰으로 취급되지만, 각 개별 패치는 종종 고유한 의미론적 의미가 부족합니다. 이러한 근본적인 차이는 이러한 도메인에서 transformers가 어떻게 적용되는지에 대한 독특한 과제와 기회를 제공합니다.
Efficient Transformers. NLP 및 computer vision 영역 모두에서 최근 transformers models의 효율성을 높이려는 노력이 급증했습니다. 이러한 노력에는 효율적인 attention 메커니즘 개발, transformer 헤드 또는 features 가지치기(pruning), vision-specific 모듈 통합 등이 포함됩니다. NLP 및 computer vision의 여러 최근 접근 방식은 transformers의 입력 불가지론적(input-agnostic) 특성으로 인해 토큰 수를 줄이려고 시도했습니다. 특히, ViTs의 경우, 토큰 가지치기(pruning) 및 토큰 병합과 같은 다양한 접근 방식을 통해 토큰 수를 줄이려는 최근 연구가 등장했습니다. 토큰 가지치기(pruning)에서, DynamicViT는 추가 훈련 파라미터를 사용하여 완전히 pre-trained된 ViT에 대한 토큰을 가지치기(pruning)하는 방법을 소개합니다. EViT는 class token attention에 따라 주의를 기울이지 않는 토큰을 결정하고, 이러한 토큰을 버려서 이미지 토큰을 재구성합니다. ToMe 와 같은 토큰 병합 접근 방식은 유사한 토큰 쌍을 새로운 토큰으로 결합하여 토큰 수를 줄입니다. 우리의 접근 방식은 비의미적 토큰을 의미론적으로 의미 있는 덩어리로 초기에 병합하여 시각적 장면과의 관련성을 올바르게 측정하는 retokenization을 제안함으로써 효율적인 ViTs에 대한 새로운 관점을 제공합니다.
1. Vision Transformers (ViTs) 개괄
- Long-range dependencies 모델링: NLP에서 성공을 거둔 Transformers가 computer vision 분야에도 도입되어 장거리 의존성(long-range dependencies) 모델링 능력을 보이며 주목받고 있습니다.
- 다양한 ViT 연구: 아키텍처 개선, 최적화 기법 등 다양한 방향으로 연구가 진행 중입니다.
- NLP와의 핵심 차이: Tokenization:
- NLP: WordPiece, SentencePiece 등을 이용한 subword/character 단위 토큰화. 각 토큰이 의미를 지님.
- ViT: 이미지를 패치로 나누어 토큰화. 각 패치가 독립적으로 의미를 갖기 어려움.
2. Efficient Transformers 연구 동향
- Transformer 효율성 개선 연구: NLP와 computer vision 양쪽 분야에서 활발히 진행 중입니다.
- 주요 접근법:
- Efficient attention mechanisms 개발
- Transformer heads/features pruning
- Vision-specific modules 통합
3. ViTs를 위한 Token Reduction 연구
- Input-agnostic 특성: Transformers의 입력에 구애받지 않는(input-agnostic) 특성으로 인해, NLP와 computer vision 모두에서 토큰 수 감소 연구가 진행 중입니다.
- ViTs에 특화된 Token Reduction:
- Token Pruning:
- DynamicViT: pre-trained ViT에서 추가 학습 파라미터를 이용해 토큰 가지치기(pruning)를 수행합니다.
- EViT: class token attention을 기반으로 불필요한 토큰을 제거하고 이미지 토큰을 재구성합니다.
- Token Merging:
- ToMe: 유사한 토큰 쌍을 병합하여 토큰 수를 줄입니다.
- Token Pruning:
4. ImagePiece vs. 기존 Token Reduction 연구
- ImagePiece의 차별성: 기존 연구들이 "어떤 토큰을 제거/병합할지"에 집중했다면, ImagePiece는 "비의미적 토큰을 의미 있는 덩어리로 묶는 retokenization" 이라는 새로운 접근법을 제시합니다.
- Retokenization의 이점:
- 단순히 토큰을 제거하거나 병합하는 것이 아니라, 토큰의 의미를 재평가(re-evaluate)할 수 있는 기회를 제공합니다.
- 시각적 장면에 대한 관련성을 보다 정확하게 측정할 수 있습니다.
결론: ImagePiece는 단순한 토큰 수 감소를 넘어, "의미 있는 토큰" 을 구성하는 새로운 방법을 제시함으로써 기존의 Efficient ViT 연구들과 차별화됩니다. 특히, retokenization이라는 개념은 ViT의 근본적인 문제점(비의미적 토큰)을 해결하려는 시도로, Efficient ViT 연구에 새로운 방향성을 제시했다는 점에서 의의가 있습니다.
Preliminary
이 예비 섹션에서는 먼저 Vision Transformers (ViTs)의 기본 개요, 즉 이미지가 Transformer 아키텍처를 위해 어떻게 패치화되고 토큰화되는지에 대해 설명합니다. 다음으로, 각 패치 토큰을 평가하는 데 관련된 기본 개념을 설명합니다. 마지막으로, 이전 토큰 감소 방법이 직면한 과제를 설명합니다.
ViT 개요. ViT는 먼저 입력 이미지를 겹치지 않는 p x p 패치로 나누고 각 패치를 토큰 임베딩으로 투영합니다. 일반적으로 16x16(p=16)의 패치 크기와 224x224의 이미지 크기로 196개의 이미지 토큰을 얻습니다. 추가 클래스 토큰은 [CLS]로 표시되며, 최종 분류를 위한 전역 이미지 정보의 집계자 역할을 하도록 이미지 토큰 sequence에 추가됩니다. 모든 토큰이 위치 임베딩과 결합된 후, 패치 임베딩은 transformer encoder에 공급됩니다.
토큰 중요도 평가. (Liang et al. 2022)의 선행 연구에 따라, 우리는 클래스 토큰과 이미지 토큰 간의 상호 작용 척도로서 클래스 attention score를 정의하며, 이는 이미지의 전체 의미에 기여하는 각 토큰의 중요도를 나타냅니다. D와 N을 각각 쿼리 벡터의 길이와 입력 토큰의 수라고 하며, 여기서 각 transformer 블록의 입력 토큰은 클래스 토큰과 나머지 이미지 토큰을 나타냅니다. 토큰 sequence X는 쿼리 행렬 Q ∈ R^(N×D), 키 행렬 K ∈ R^(N×D), 값 행렬 V ∈ R^(N×D)로 투영됩니다. 클래스 attention score와 클래스 토큰의 출력은 다음과 같습니다.
x_class = Softmax( (Q_class * K^T) / √D ) * V = A_class * V, (1)
여기서 Q_class는 클래스 토큰의 쿼리 벡터를 나타냅니다. 결과적으로, x_class로 표시된 클래스 토큰의 출력은 값 벡터 V=[v1, v2, · · · , vN ]^⊤의 선형 조합입니다.
이 조합의 계수는 식 (1)의 A_class로 표시되며, 모든 토큰에 대한 클래스 토큰의 attention 값입니다.
토큰 감소의 과제. 토큰 가지치기(pruning) 및 토큰 병합을 포함한 토큰 감소 기술은 토큰 수를 줄여 ViTs를 가속화하는 데 필수적입니다. 토큰 가지치기(pruning) 및 토큰 병합은 ViT 가속화의 가장 대표적인 두 가지 갈래입니다. 토큰 가지치기(pruning) 방법은 고정된 하이퍼 파라미터를 기반으로 덜 주의를 기울이는 토큰을 제거하여 중요하지 않은 것으로 간주되는 고정된 하위 k개 토큰 또는 미리 결정된 임계값 미만의 토큰을 대상으로 합니다. 그러나 토큰은 [CLS] 토큰과의 attention score에 따라 중요하거나 중요하지 않은 것으로 취급되기 때문에, 의미적으로 중요한 정보를 수반할 수 있는 국소적으로 일관된 토큰이 종종 버려집니다. 토큰 가지치기(pruning)에서 종종 발생하는 정보 손실을 보상하기 위해, 토큰 병합 접근 방식은 원래 토큰을 제거하는 대신 가장 유사한 상위 k개 쌍을 선택하여 가장 유사도가 높은 토큰 쌍을 병합하여 ViTs를 가속화하려고 시도했습니다. 그러나 병합 프로세스가 진행됨에 따라 유사도가 낮은 토큰이 병합되기 쉬우며, 그 결과 의미적으로 필수적인 토큰이 관련 없는 두 표현의 의미적으로 관련 없는 보간으로 희석됩니다.
1. ViT 개요: 생략
- 일반적인 ViT의 패치화, 토큰화 과정은 생략합니다. (AI 연구자들은 이미 알고 있을 것이라 가정)
2. 토큰 중요도 평가: Class Attention Score
- 핵심 지표: ImagePiece는 토큰의 중요도를 평가하기 위해 "Class Attention Score"를 사용합니다.
- Class Attention Score:
- Class token ([CLS])과 다른 이미지 토큰들 간의 상호작용을 측정합니다.
- 각 토큰이 이미지의 전체적인 의미에 얼마나 기여하는지를 나타냅니다.
- 수식 (1)을 통해 계산됩니다: x_class = Softmax( (Q_class * K^T) / √D ) * V = A_class * V
- A_class는 class token이 다른 모든 토큰에 주는 attention 가중치를 나타냅니다.
3. 토큰 감소 (Token Reduction)의 어려움: Pruning과 Merging의 한계
- Token Reduction의 필요성: ViT 가속화를 위해 필수적입니다.
- 두 가지 주요 접근법:
- Token Pruning:
- 방법: 고정된 하이퍼 파라미터 (e.g., 하위 k개, 임계값)를 기준으로 덜 중요한 토큰을 제거합니다.
- 문제점: 국소적으로는 의미 있는 정보를 담고 있을 수 있는 토큰들이 [CLS] 토큰과의 attention score가 낮다는 이유로 버려질 수 있습니다.
- Token Merging:
- 방법: 유사도가 높은 토큰 쌍을 병합합니다.
- 문제점: 병합이 진행될수록, 유사도가 낮은 토큰들도 병합될 가능성이 높아지고, 이로 인해 의미 있는 토큰이 무관한 토큰과 섞여 희석될(diluted) 위험이 있습니다.
- Token Pruning:
4. ImagePiece는 이러한 한계를 어떻게 극복하려 하는가? (암시)
- Preliminary 섹션의 암시: ImagePiece는 단순한 pruning이나 merging을 넘어서는 새로운 접근법을 제시할 것이라는 암시를 줍니다.
- 핵심 차별화 (추측):
- 토큰의 "의미"를 고려하여, 국소적인 맥락에서 토큰을 재구성(re-organize)하는 전략을 사용할 것으로 예상됩니다.
- 단순히 attention score가 낮은 토큰을 제거하는 것이 아니라, 이들을 "의미 있는 덩어리"로 묶어 (retokenization) 그 가치를 재평가(re-evaluate)할 것입니다.
결론: ImagePiece는 기존의 토큰 감소 방법들이 "attention score"만을 맹신하여 중요한 정보를 잃을 수 있다는 한계를 인식하고, 이를 극복하기 위해 "retokenization"이라는 새로운 전략을 도입합니다. Preliminary 섹션은 이러한 문제의식과 새로운 접근법에 대한 힌트를 제공하며, 이어지는 Method 섹션에 대한 기대감을 높입니다.
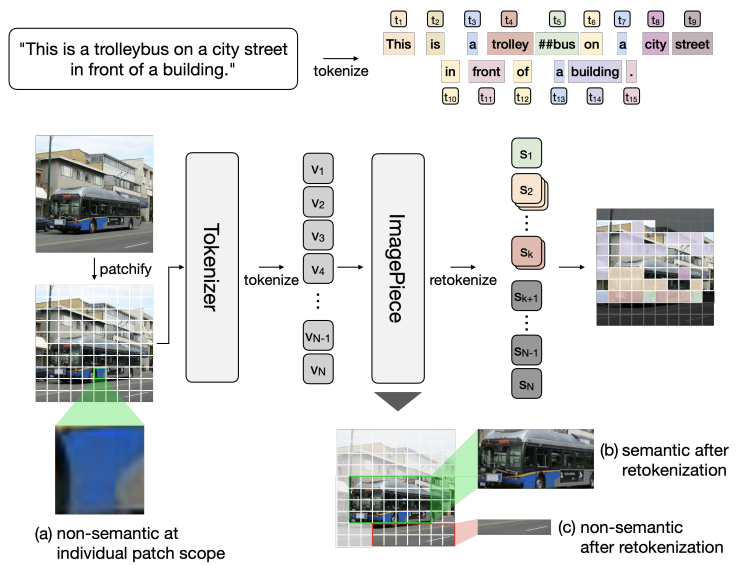
ImagePiece
우리는 이미지 패치 토큰을 (의미를 전달하는 최소 단위인) 하위 단어와 유사하게 만드는 새로운 re-tokenization 전략인 ImagePiece를 소개합니다. 그림 2는 제안된 ImagePiece의 전체 아키텍처를 보여줍니다.
Re-tokenizing Non-semantic Tokens. WordPiece 토큰화의 MaxMatch 전략에 따라, ImagePiece는 의미적으로 불충분한(하위 k개) 토큰을 의미를 전달하는 수준으로 그룹화하는 ViTs에 대한 retokenization을 수행합니다. 자세히 살펴보면, re-tokenization은 세 단계 절차를 반복적으로 따릅니다. 1단계, 각 토큰의 전체 의미에 대한 중요도는 식 (1)과 같이 [CLS] 토큰과의 attention score에 의해 평가됩니다. 2단계, 하위 k개 토큰은 두 개의 동일한 크기의 하위 집합으로 나뉘며, attention에 의해 구성된 토큰은 각 그룹에 번갈아 할당됩니다(편의상 이러한 그룹을 A와 B라고 함). 그런 다음, 그룹 A의 각 토큰은 bipartite soft matching을 사용하여 그룹 B에서 가장 유사한 토큰과 병합됩니다. 3단계, 일치된 토큰의 의미적 추상화와 나머지 비하위 k개 토큰의 attention score가 다시 계산됩니다. 전체 시각적 의미와 관련성을 얻은 추상화 토큰은 다시 구성됩니다.
Local Coherence Bias. 그림 1에서 볼 수 있듯이, 개별 범위에서 의미를 구별하기 어려운 패치는 주변 패치와 함께 맥락화될 때 의미 있는 의미를 수집할 수 있습니다(즉, 국소적 귀납적 편향). 이 편향을 시각적 토큰에 추가하기 위해, 우리는 overlapping convolution layers로 구성된 국소적 일관성 편향 모듈을 추가합니다. 인접한 패치가 겹치는 features와 얽혀 있기 때문에, 기하학적으로 가까운 비의미적 패치는 더 높은 유사도를 갖도록 장려됩니다. 이를 통해 retokenization은 근처의 비의미적 토큰을 의미 있는 토큰이 형성될 때까지(또는 전체 의미와 관련이 없게 될 때까지) 병합하도록 촉진합니다.
Compatibility with Token-Pruning. ViTs는 입력 토큰의 2차 복잡성과 square-grid 패치 토큰화기 (일반적으로 관련이 없거나 중복된 패치의 높은 부분을 포함)로 인해 어려움을 겪기 때문에, 이전 연구에서는 시각적 장면의 전체 의미에 기여하지 않는 토큰을 제거(drop-out)하기 위한 가지치기(pruning) 전략을 고안했습니다. 그러나 적절한 맥락화 없이 의미를 결정하기 어려운 패치는 토큰이 중간 ViT 계층에서 버려지는 점진적 가지치기(pruning) 전략으로 인해 초기 계층에서 버려지기 쉽습니다. 반면에, 이러한 점진적 아키텍처로 인해 ImagePiece는 기존 토큰 가지치기(pruning) 방법과의 강력한 호환성을 보여줍니다. 왜냐하면 비의미적 토큰은 기하학적으로 가까운 토큰과 빠르게 병합되어 초기 transformer 계층에서 의미를 형성하기 위한 강력한 국소적 편향의 이점을 얻기 때문입니다(그림 3 참조).
Competitiveness with Token-Merging. ImagePiece는 토큰 병합의 변형으로 취급될 수 있습니다. 토큰 병합에 대한 이전 연구는 주로 Vision Transformers의 효율성을 높이기 위해 (높은 feature 유사도를 가진) 중복 토큰을 결합하는 데 중점을 두었습니다. 그러나 이 전략은 심각한 단점을 수반합니다. 예를 들어, 상위 k개 유사한 토큰 쌍 간의 유사도가 충분히 높지 않은 경우, 위의 병합 파이프라인은 의미적으로 관련된 토큰을 관련 없는 토큰과 함께 평활화합니다. 이는 시각적 장면의 중요한 의미를 오히려 손상시킵니다. 표 7은 이전 토큰 병합 방법을 사용할 때 의미적으로 관련된 토큰이 초기 ViT 계층에서 자주 병합(따라서 의미적으로 희석됨)된다는 실증적 증거를 보여줍니다. 반대로, ImagePiece는 의미 있는 의미적 표현에 기여할 때까지 비의미적 토큰을 retokenizes합니다. 실험 결과는 이러한 전략적 차이로 인해 ImagePiece가 의미적으로 필수적인 토큰을 간섭하지 않고 성공적으로 보존한다는 것을 보여줍니다.
이 노트는 "ImagePiece" 논문의 핵심인 ImagePiece 방법론을 AI 연구자들이 빠르게 이해할 수 있도록 작성되었습니다. 기존 ViT의 토큰화 및 효율화 기법들과의 차별성을 중심으로, ImagePiece만의 독창적인 아이디어와 그 효과를 집중 조명합니다.
1. ImagePiece: Re-tokenization for Meaningful Visual Tokens
- 핵심 아이디어: 이미지 패치 토큰을 NLP의 subword처럼 "의미를 전달하는 최소 단위"로 만드는 새로운 re-tokenization 전략입니다.
- 목표: 비의미적(non-semantic) 토큰들을 모아 의미 있는 덩어리(meaningful chunks)로 재구성(re-organize)합니다.
2. Re-tokenization Process: MaxMatch in Vision
- WordPiece의 MaxMatch 전략 차용: NLP에서 널리 쓰이는 WordPiece 토큰화의 MaxMatch (greedy longest-match-first) 전략에서 영감을 받았습니다.
- 3단계 Iterative Process:
- Importance Evaluation: [CLS] 토큰과의 attention score (식 1)를 기반으로 각 토큰의 중요도를 평가합니다.
- Grouping & Matching: 중요도가 낮은 하위 k개 토큰을 두 그룹(A, B)으로 나누고, 각 그룹 내에서 attention score 순서대로 정렬 후, bipartite soft matching을 통해 A 그룹의 토큰을 B 그룹의 가장 유사한 토큰과 짝지어 줍니다.
- Re-evaluation: 병합된 토큰 (의미적 추상화)들과 나머지 토큰들의 attention score를 다시 계산하여, 전체 이미지 의미와의 관련성이 높아진 토큰들을 보존합니다.
3. Local Coherence Bias: Inductive Bias for Vision
- 문제 인식: 개별 패치 단위로는 의미 파악이 어렵지만, 주변 패치들과 함께 고려하면 의미가 명확해지는 경우가 많습니다. (e.g., Figure 1)
- 해결책: Overlapping convolution 연산을 도입하여, 공간적으로 인접한 패치들이 높은 유사도를 갖도록 유도합니다.
- 효과: 비의미적 토큰들이 주변 토큰들과 더 잘 묶이도록 하여, re-tokenization 과정에서 의미 있는 덩어리를 형성하도록 촉진합니다.
4. Compatibility with Token-Pruning: Early Meaning Formation
- 기존 Pruning의 한계: 의미 파악이 어려운 토큰들이 초반 layer에서 제거될 위험이 있습니다.
- ImagePiece의 강점:
- 비의미적 토큰들을 초반 layer에서 빠르게 주변 토큰과 결합하여 의미를 형성하도록 돕습니다.
- 이를 통해, 점진적 가지치기(pruning)를 수행하는 기존 ViT 모델에서도 중요한 정보가 보존될 가능성을 높입니다. (Figure 3)
5. Competitiveness with Token-Merging: Preserving Semantic Tokens
- 기존 Merging의 한계: 유사도가 낮은 토큰들이 병합되면서, 의미 있는 토큰이 무관한 토큰과 섞여 희석될(diluted) 위험이 있습니다. (Table 7)
- ImagePiece의 강점:
- 비의미적 토큰만을 대상으로 re-tokenization을 진행하기 때문에, 의미 있는 토큰은 보존됩니다.
- 실험적으로도 ImagePiece가 의미 있는 토큰을 잘 보존함을 보였습니다.
결론: ImagePiece는 ViT의 효율성 향상을 위해 "re-tokenization"이라는 새로운 패러다임을 제시합니다. 특히, (1) MaxMatch 기반의 반복적 토큰 재구성, (2) Local Coherence Bias를 통한 시각적 inductive bias의 활용, (3) 기존 pruning 및 merging 기법과의 차별화 를 통해, 의미 있는 정보를 보존하면서도 효율적으로 ViT를 가속화하는 혁신적인 방법론입니다. 이 연구는 ViT의 성능 및 효율성 개선에 크게 기여할 것으로 기대됩니다.