

AI바라기의 인공지능
VLM : 논문 리뷰 : Mario: Multimodal Graph Reasoning with Large Language Models 본문
VLM : 논문 리뷰 : Mario: Multimodal Graph Reasoning with Large Language Models
AI바라기 2026. 4. 2. 18:45
용어 설명
- MMG (Multimodal Graph): 노드들이 text와 image 같은 여러 modality 속성을 가지며, edge를 통해 구조적으로 연결된 그래프 데이터.
- GVLM (Graph-conditioned Vision-Language Model): 단순한 image-text pair 단위의 정렬을 넘어, 그래프 상의 이웃 노드 정보(topology)를 주입하여 cross-modal alignment를 수행하는 Mario 모델의 1단계 핵심 구조.
- MAPR (Modality-Adaptive Prompt Router): 2단계에서 작동하는 경량화된 라우터. 각 노드와 주변 이웃의 특징을 분석하여, LLM에게 전달할 가장 적합한 modality 조합(text-only, image-only, text+image)의 prompt template을 동적으로 선택함.
- Cross-modal consistency: 서로 다른 modality(텍스트와 이미지) 간의 의미적 일치 정도. 실제 데이터에서는 텍스트가 이미지를 완벽히 설명하지 않거나 노이즈가 끼어 있어 이 일치도가 약한 경우가 많음.
- Heterogeneous modality preference: 그래프 내의 노드마다 정답을 맞추기 위해 더 중요하게 의존해야 하는 modality가 다르다는 성질. (예: 어떤 노드는 텍스트가 중요하고, 어떤 노드는 이미지가 중요함)
Purpose of the Paper
- 기존 연구의 한계: 대부분의 기존 모델은 multimodal 데이터를 고립된 image-text pair로만 취급하여 데이터가 자연스럽게 형성하는 관계형 구조(relational structure)를 낭비함. 반대로 기존 GraphLLM에 VLM을 결합하는 방식은 각 노드의 text와 image가 이미 완벽히 일치한다는 잘못된 가정을 바탕으로 단순 융합을 시도하여, 오히려 weak cross-modal consistency 문제를 증폭시키고 노드마다 유리한 modality가 다르다는 heterogeneous modality preference를 무시함.
- 새로운 문제 정의 및 접근 방식: LLM이 MMG 상에서 신뢰성 있는 reasoning을 수행하려면, 먼저 그래프 구조를 이용해 텍스트와 이미지 간의 불일치를 해소해야 하며, 각 노드의 특성과 이웃 정보에 맞춰 가장 유용한 modality 정보만을 선별해 제공해야 함을 주장함. 이를 위해 두 단계의 맞춤형 파이프라인으로 구성된 새로운 통합 프레임워크 Mario를 제안함.
Key Contributions
- Mario 프레임워크 제안: MMG reasoning의 두 가지 근본적 장애물인 cross-modal inconsistency와 heterogeneous modality preference를 동시에 해결하는 최초의 LLM 기반 프레임워크 설계.
- Stage 1: Graph-conditioned VLM (GVLM) 도입:
- 참신성: 기존의 구조 독립적인 VLM과 달리, Topology-Aware Multimodal Mixer를 통해 그래프 구조(multi-hop 이웃 정보)를 token embedding 단계부터 주입함. 이를 통해 이웃 노드의 문맥을 활용해 텍스트와 이미지 간의 미세한 간극을 좁히는 구조 인식형(structure-aware) cross-modal contrastive learning을 수행함.
- Stage 2: Modality-Adaptive Graph Instruction Tuning:
- 참신성: 모든 노드에 고정된 단일 template을 강제하는 기존 GraphLLM의 관행을 깨고, 학습 가능한 라우터(MAPR)를 도입함. 각 노드와 그 이웃의 특징을 분석해 가장 정보량이 많은 최적의 modality view(text, image, multimodal)를 동적으로 선택하여 LLM에 라우팅하는 새로운 tuning 체계를 구축함.
Experimental Highlights
- 실험 설정: Node classification (NC) 및 Link prediction (LP) tasks. Amazon (Movies, Toys, CDs, Arts), Reddit, Goodreads 등 다양한 도메인의 MMG datasets 사용. LLM backbone으로 주로 LLaMA3-8B 채택.
- State-of-the-Art 성능 달성 (Single-Focus): 모든 dataset에서 Text-only, Image-only, Text+Image 기반의 강력한 baselines(GNNs, MLaGA 등 최신 GraphLLMs)를 압도함. 예를 들어 CDs 데이터셋의 NC task에서 최고 baseline 대비 정확도를 56.45%에서 63.43%로 큰 폭으로 향상시킴.
- 강력한 Zero-Shot Transfer 능력: 완전히 학습되지 않은(unseen) MMG 환경에서도 탁월한 일반화 성능 입증. Toys에서 학습하고 Movies로 전이(Toys -> Movies)한 zero-shot NC 평가에서 최고 baseline 대비 1.64배 높은 정확도를 달성함.
- 라우터 효율성 및 Modality Homophily 시각화: MAPR을 적용한 동적 라우팅 방식은 단일 template 고정 방식보다 수렴 속도를 최대 2.3배 앞당김. 또한 시각화(t-SNE 등)를 통해 연결된 이웃 노드들끼리 동일한 modality preference를 공유하는 군집화(homophily) 패턴이 존재함을 최초로 규명함.
Limitations and Future Work
- Limitations:
- Two-stage 아키텍처의 복잡성: Stage 1(GVLM 사전 학습)과 Stage 2(Instruction tuning)가 순차적으로 분리되어 있어, 향후 end-to-end 학습으로 통합되지 않으면 모델 관리와 최적화 과정에서 계산 자원(compute budget) 오버헤드가 발생할 수 있음.
- Bimodal 한계: 현재 프레임워크는 Text와 Image라는 두 가지 modality 교차 검증에 집중되어 있어, Audio나 Video 등이 포함된 더 복잡한 형태의 MMG에 대한 즉각적 적용은 입증되지 않음.
- Future Work:
- 단순한 이웃 집계(1~2 hop)를 넘어, 대규모 지식 그래프(Knowledge Graphs) 수준의 복잡한 multi-hop reasoning 경로를 LLM이 스스로 탐색하고 modality를 선택하는 방향으로 확장이 필요함.
- 이 연구를 기반으로 파라미터 업데이트 없이도 이종 modality를 즉각적으로 정렬할 수 있는 범용적인 end-to-end Multimodal Graph Foundation Model로 발전할 잠재력이 큼.
Overall Summary
Mario는 실제 세계의 multimodal 그래프 데이터가 겪는 '모달리티 간 의미 불일치'와 '노드별 모달리티 편식 현상'을 정면으로 해결한 혁신적인 프레임워크입니다. 1단계에서 그래프 구조를 반영한 VLM으로 이미지와 텍스트의 의미를 정교하게 동기화하고, 2단계에서 동적 라우터를 통해 각 노드에 가장 유리한 모달리티 조합만 골라 LLM에게 지시(instruction)합니다. 이를 통해 기존의 단순 융합 모델들을 뛰어넘는 압도적인 지도 학습 및 Zero-shot 추론 성능을 증명했으며, 향후 LLM이 복잡한 관계망과 다양한 형태의 데이터가 혼재된 환경에서 어떻게 스스로 판단하고 추론해야 하는지에 대한 새로운 설계 패러다임을 제시했습니다.
쉬운 설명
학생(LLM)에게 시험 문제(노드)를 풀게 할 때를 상상해 보세요. 어떤 문제는 지문(Text)만 보는 게 낫고, 어떤 문제는 그림(Image)만 보는 게 낫고, 어떤 문제는 둘 다 봐야(Text+Image) 헷갈리지 않습니다.
Mario는 다음과 같이 작동합니다. 먼저 '족보(그래프의 이웃 정보)'를 활용해 지문과 그림이 서로 다른 이야기를 하는 것을 미리 교정해 놓습니다(GVLM). 그런 다음, 똑똑한 과외 선생님(MAPR 라우터)이 각 문제의 특성을 파악해서 학생에게 "이 문제는 그림만 봐!", "이 문제는 텍스트만 읽어!"라고 **맞춤형 힌트(Prompt)**를 던져줍니다. 쓸데없는 정보를 쳐내고 가장 확실한 힌트만 주었기 때문에, 학생(LLM)이 처음 보는 시험장(Zero-shot)에서도 압도적으로 높은 점수를 받을 수 있게 만든 시스템입니다.
Abstract
최근 large language models (LLMs)의 발전은 multimodal reasoning을 위한 새로운 장을 열었습니다. 그러나 대부분의 기존 방법들은 실제 세계의 multimodal 데이터가 자연스럽게 형성하는 관계형 구조를 무시한 채, 여전히 pretrained vision-language models (VLMs)에 의존하여 image-text pairs를 독립적으로 인코딩하고 있습니다. 이는 각 node가 텍스트 및 visual attributes를 가지고 edges가 structural cues를 제공하는 multimodal graphs (MMGs)에서의 reasoning에 대한 필요성을 부여합니다.
graph topology를 보존하면서 이러한 heterogeneous multimodal signals에 대해 LLM 기반 reasoning을 가능하게 하는 것에는 두 가지 주요 과제가 수반됩니다: 약한 cross-modal consistency를 해결하는 것과 heterogeneous modality preference를 처리하는 것입니다. 이를 해결하기 위해, 우리는 위의 두 가지 과제를 동시에 해결하고 MMGs에 대한 효과적인 LLM 기반 reasoning을 가능하게 하는 통합된 framework인 Mario를 제안합니다.
Mario는 두 가지 혁신적인 단계로 구성됩니다.
첫째, graph topology의 가이드를 받는 fine-grained cross-modal contrastive learning을 통해 텍스트 및 visual features를 공동으로 개선하는 graph-conditioned VLM 설계입니다.
둘째, aligned multimodal features를 graph-aware instruction views로 구성하고, learnable router를 활용하여 각 node와 그 이웃에 대해 LLM에게 가장 유용한 modality configuration을 제공하는 modality-adaptive graph instruction tuning mechanism입니다.
다양한 MMG benchmarks에 대한 광범위한 실험은 Mario가 node classification 및 link prediction을 위한 supervised 및 zero-shot 시나리오 모두에서 state-of-the-art graph models를 일관되게 능가함을 보여줍니다. code는 Mario를 통해 공개될 예정입니다.
1. Introduction
Large language models (LLMs)는 순수한 텍스트 처리기에서 instructions를 따르고, entities를 grounding하며, visual signals를 통합할 수 있는 범용 multimodal reasoners로 진화해 왔습니다. 그러나 현재의 대부분 pipelines는 multimodal 데이터가 고립된 image-text pairs로 처리되는 단순화된 input 형태를 계속해서 가정하고 작동합니다. 이러한 관점은 실제 환경에서 multimodal 데이터가 나타나는 방식과는 잘 맞지 않습니다. 고립된 image-text pairs라기보다는, 이러한 entities는 서로 연결되어 있으며 multimodal nodes의 구조화된 집합으로 더욱 충실하게 모델링됩니다. 그러한 데이터를 독립적이고 관련 없는 쌍으로 취급하는 것은 multimodal signal의 상당 부분을 사용하지 않은 채로 남겨두며, 특히 multimodal entities 간의 relations에 의해 전달되는 정보를 놓치게 만듭니다.
이러한 불일치는 최근 multimodal 데이터의 관계적 본질을 multimodal graphs (MMGs)로 캐스팅하여 명시적으로 만들고자 하는 일련의 연구를 촉발했습니다: 각 node는 textual 및 visual attributes를 전달하는 반면 edges는 추가적인 structural priors를 제공합니다. 그런 다음 겉보기에 자연스러운 해결책이 떠오릅니다: node-level modalities를 encode하기 위해 CLIP과 같은 강력한 vision-language models (VLMs)를 재사용하고, 이러한 embeddings를 propagation 및 reasoning을 위해 GNNs와 같은 graph-capable backbone에 전달하는 것입니다. 이 전략은 pretrained VLMs의 representational 강점을 보존하고 structural 부분만 graph model에 위임하기 때문에 매력적입니다. 그럼에도 불구하고, 이것은 각 node의 textual 및 visual views가 이미 의미론적으로 잘 동기화되어 있으며, 이를 graph에 주입해도 cross-modal mismatch를 증폭시키지 않을 것이라는 강력한 전제에 조용히 의존하고 있습니다.
그러나 현실적인 MMGs에서 node에 첨부된 image가 항상 text의 깔끔한 visual rendering인 것은 아니며, text가 항상 image의 충실한 caption인 것도 아닙니다; 독립적으로 볼 때, 어느 쪽이든 짧거나, noisy하거나, 의미론적으로 불충분할 수 있습니다. 이는 multimodal graph reasoning에서 우리의 첫 번째 과제를 발생시킵니다: C1: 약한 cross-modal consistency. 이러한 경우, 이웃 nodes는 종종 modality semantics를 명확히 하거나 누락된 정보를 보강하는 중요한 cues를 제공하며, 특히 modalities가 부분적으로만 겹칠 때 그러합니다. Fig. 1의 막대 그래프에 표시된 것처럼, graph topology를 alignment 과정에 통합함으로써 우리의 model Mario는 상당한 cross-modal consistency를 달성하여 frozen CLIP 대비 평균 68%의 이득과 node-wise fine-tuning 대비 추가적인 6%의 개선을 산출합니다. 이는 structureaware vision-language model의 설계가 LLMs가 multimodal graphs에서 신뢰할 수 있는 reasoning을 수행하기 위한 필수 전제 조건이라는 우리의 주장을 경험적으로 뒷받침합니다.
이러한 aligned multimodal features가 제자리에 있을 때 두 번째 어려움이 표면화됩니다—C2: heterogeneous modality preference. node inputs가 unimodal인 기존의 LLM-based Graph Model (GraphLLM) 설정에서는 모든 nodes에 대해 공유되는 instruction template을 사용하는 것이 합리적입니다. 그러나 이 가정은 MMGs에서는 실패하는데, 여기서는 각 modality의 정보성이 nodes 전반에 걸쳐 크게 다를 수 있고, 위의 alignment mechanisms는 주로 공통적인 cross-modal patterns에 초점을 맞추는 반면 aligned visual 및 textual features는 여전히 각각의 개별 부분을 유지하기 때문입니다. 일부 nodes는 풍부하게 설명되어 text-salient하고, 다른 nodes는 noisy한 text를 가지고 있어 독특한 visual cues에 의존해야 하며, 많은 경우 실제로 두 modalities 모두의 보완적인 증거를 필요로 합니다. 더욱이, local subgraphs에 대해 reasoning할 때 anchor node에 대한 효과적인 modality는 이웃의 noisy하거나 불완전하거나 중복되는 modalities에 의해 교란될 수 있습니다. Fig. 1의 벤 다이어그램이 보여주듯이, 적어도 하나의 template에 의해 올바르게 분류된 nodes 중에서 거의 30%가 세 가지 모두가 아닌 3개의 modality-specific templates 중 오직 1개나 2개에 의해서만 커버됩니다. 이는 one-size-fitsall prompting 전략이 사용 가능한 multimodal supervision을 충분히 활용하지 못한다는 것을 시사하며, adaptive하고 nodespecific prompting 전략의 필요성을 강조합니다. 이것은 다음의 질문을 던지게 합니다:
(Q) 우리가 graph structure를 활용하여 신뢰할 수 있는 cross-modal alignment를 강제하고, 그 위에 aligned representations를 사용하여 각 node와 그 local context에 대해 가장 유익한 modality를 적응적으로 선택하는 dynamic prompting policy를 구동할 수 있을까?
이 질문에 답하기 위해, 우리는 structure-aware cross-modal alignment를 instruction-tuned LLMs와 긴밀하게 결합하는 multimodal graphs 기반의 dual-stage Modality-Adaptive Reasoning framework인 Mario를 소개합니다. Stage 1은 graph-conditioned vision-language model의 역할을 합니다: 이것은 text 및 image features를 multi-hop structural guidance 하에 align하기 위해 GNN-nested 디자인에서 영감을 받은 topologyaware multimodal mixer가 증강된 dual-tower encoder를 사용하여, structure-aware하고 cross-modally coherent node representations를 산출합니다. 그런 다음 Stage 2는 이러한 aligned features를 multimodal instruction views의 제품군으로 구성하고 Modality-Adaptive Prompt Router를 LLM과 공동으로 trains하여, 각 node에 대해 Mario가 이를 통해 LLM에 표면화할 modality configuration을 결정하고 inference 중에 instance를 가장 예측력이 높은 view로 route할 수 있도록 합니다. 우리의 핵심 기여는 다음과 같이 요약됩니다:
- 우리는 MMGs에 LLM reasoning을 적용하는 연구를 수행하여, 이전에 덜 탐구되었던 두 가지 장애물인 cross-modal inconsistency와 heterogeneous modality preference를 식별하고, 두 가지 과제를 동시에 해결하는 새로운 framework인 Mario를 소개합니다.
- 우리는 image와 text를 topology 하에 align하여 두 modalities에 공동으로 기반을 둔 대칭적이고 structure-aware node representations를 산출하는 새로운 VLM paradigm인 graph-conditioned vision-language model을 소개합니다.
- 우리는 각 node를 가장 정보가 풍부한 modality로 routes하는 새로운 tuning scheme인 modalityadaptive graph instruction tuning을 도입함으로써, 고정된 modality template에 대한 GraphLLMs의 지배적인 의존성을 깹니다.
- 우리는 다양한 MMG benchmarks에 걸쳐 광범위한 평가를 수행하여, node classification 및 link prediction에서 Mario의 state-of-the-art performance를 입증합니다. 특히, Mario는 주요 baselines를 일관되게 능가하며, zero-shot transfer settings에서 최대 1.6배의 이득을 달성합니다.
1. Introduction 정리 노트
- 기존 연구의 한계
- 기존의 LLM 파이프라인은 multimodal 데이터를 고립된 image-text pairs로 취급함.
- 현실의 데이터는 엔티티들이 서로 연결된 Multimodal Graphs(MMGs) 구조를 띠고 있음.
- 기존 방식(미리 학습된 VLMs로 특징을 뽑아 GNNs에 태우는 방식)은 각 노드의 text와 image가 이미 의미론적으로 완벽히 동기화되어 있다는 강력하고 잘못된 전제에 의존함.
- MMG 기반 reasoning의 2가지 핵심 과제
- C1: Weak cross-modal consistency (약한 교차 모달 일관성)
- 현실의 MMG 노드에서 text와 image는 서로 불완전하거나 노이즈가 많음.
- 단순히 인코딩하여 결합하면 cross-modal mismatch가 증폭됨.
- C2: Heterogeneous modality preference (이질적 모달리티 선호도)
- 노드마다 유익한 modality(text 위주, vision 위주, 혹은 둘 다)가 다름.
- 기존 GraphLLMs의 단일 instruction template(일괄 적용 방식)은 제공되는 multimodal 정보를 온전히 활용하지 못함.
- C1: Weak cross-modal consistency (약한 교차 모달 일관성)
- 제안 모델: Mario
- MMG 상에서 LLM을 효과적으로 활용하기 위한 이중 단계(Dual-stage) 프레임워크.
- Stage 1: Graph-conditioned VLM
- Graph topology의 가이드를 받아 text와 image features를 정렬(alignment)함.
- 이웃 노드의 구조적(multi-hop) 정보를 바탕으로 노이즈를 줄이고 structure-aware node representation을 생성함.
- Stage 2: Modality-adaptive graph instruction tuning
- Modality-Adaptive Prompt Router를 학습시킴.
- 단일 템플릿을 버리고, 각 노드와 주변 컨텍스트에 가장 정보량이 많은 modality 조합(configuration)을 동적으로 선택해 LLM에게 제공함.
- 주요 기여점(Contributions)
- MMGs 상의 LLM reasoning에서 간과되었던 두 가지 과제(C1, C2)를 식별하고 이를 동시 해결하는 프레임워크 제안.
- 단순 인코딩을 넘어, topology 기반으로 두 모달리티를 정렬하는 새로운 VLM 패러다임 제시.
- 고정된 template 방식을 탈피한 새로운 튜닝 기법 도입.
- 다양한 MMG benchmarks의 node classification 및 link prediction 태스크에서 state-of-the-art 달성 (zero-shot 환경에서 최대 1.6배 성능 향상).
쉬운 설명 : 1. Introduction
이 논문은 복잡하게 얽혀있는 네트워크(그래프) 형태의 멀티모달 데이터를 LLMs가 어떻게 하면 더 똑똑하게 처리할 수 있을지에 대한 고민에서 출발합니다.
기존 연구들은 이미지와 텍스트가 하나로 묶여있으면 "당연히 둘 다 완벽하게 같은 내용을 담고 있겠지"라고 가정하고 모델을 설계했습니다. 하지만 실제 인터넷 데이터(예: SNS 게시글)를 보면 사진은 예쁜 카페인데 글은 "오늘 기분 우울하다"인 경우처럼 서로 내용이 엇나가거나 힌트가 부족한 경우(C1: Weak cross-modal consistency)가 아주 많습니다. 게다가 어떤 게시글은 텍스트가 훨씬 중요하고, 어떤 게시글은 사진이 결정적인 정보를 주는데, 기존 모델들은 이걸 구분하지 않고 똑같은 방식(C2: Heterogeneous modality preference)으로만 질문을 던졌습니다.
그래서 이 논문은 Mario라는 똑똑한 해결책을 제안합니다.
- 첫 번째로, 주변 친구들(연결된 이웃 노드들)의 정보를 싹 모아서 현재 노드의 이미지와 텍스트가 진짜 의미하는 바가 무엇인지 맥락을 파악하고 서로 아귀를 맞춰줍니다(Graph-conditioned VLM).
- 두 번째로, LLM에게 무작정 모든 정보를 던져주는 게 아니라, "이 노드는 사진이 중요하니까 사진 위주로 봐!", "이 노드는 텍스트가 핵심이야!"라고 똑똑한 라우터가 판단해서 LLM에게 가장 알맞은 정보만 쏙쏙 골라 제공하는 훈련(Modality-adaptive graph instruction tuning)을 시킵니다.
결과적으로 Mario는 기존 모델들보다 훨씬 똑똑하게 작동하며, 처음 보는 데이터(zero-shot)에서도 탁월한 성능을 보여주었다는 것이 이 서론의 핵심 내용입니다

제공해주신 이미지는 앞서 설명해드린 논문의 Figure 1입니다. 서론(Introduction)에서 제기했던 두 가지 핵심 과제(C1: 약한 교차 모달 일관성, C2: 이질적 모달리티 선호도)를 실험 결과를 통해 시각적으로 증명하는 중요한 자료입니다.
그래프의 각 부분에 대한 상세한 설명은 다음과 같습니다.
(a) Modality Consistency Bar Chart (모달리티 일관성 막대 그래프)
이 그래프는 4개의 서로 다른 데이터셋(Movies, Reddit, CDs, Arts)에서 모델별로 텍스트 임베딩과 이미지 임베딩 간의 코사인 유사도(Cosine Similarity)가 얼마나 되는지 비교합니다. 서론의 C1(Weak cross-modal consistency) 문제를 뒷받침합니다.
- CLIP (분홍색 빗금): 그래프 하단을 보면 유사도가 오히려 0 이하(약 -7~-8%)로 떨어져 있습니다. 이는 학습되지 않은 기존 모델을 그대로 썼을 때, 노드의 텍스트와 이미지 간의 의미적 연결이 매우 약하거나 엇나가 있음을 보여줍니다.
- Tuned CLIP (파란색 줄무늬): 노드 단위로 미세 조정을 거치면 유사도가 53~56% 수준으로 크게 상승합니다.
- Mario (Ours) (초록색 격자무늬): 논문에서 제안한 그래프 토폴로지 기반의 모델입니다. 모든 데이터셋에서 가장 높은 유사도(최대 66%)를 기록했습니다. 이는 주변 노드의 구조적 정보를 활용하는 Mario가 텍스트와 이미지의 짝을 가장 잘 맞춰준다는 것을 증명합니다.
(b) Modality Preference Venn Diagram (모달리티 선호도 벤 다이어그램)
이 다이어그램은 3가지 프롬프트 템플릿(Text-Only, Image-Only, Text+Image) 중 적어도 하나로 올바르게 분류된(정답을 맞춘) 노드들의 비율을 보여줍니다. 서론의 C2(Heterogeneous modality preference) 문제를 뒷받침합니다.
- 가운데 교집합인 70.96%의 노드는 어떤 템플릿을 쓰든(텍스트만 보든, 이미지만 보든, 둘 다 보든) 정답을 맞출 수 있는 쉬운 노드들입니다.
- 논문의 핵심 포인트는 나머지 약 30%의 노드들입니다. 이 노드들은 3가지 템플릿이 모두 통하지 않고, 특정 템플릿 조합이나 오직 하나의 템플릿으로만 정답을 맞출 수 있습니다.
- 예를 들어, 오직 텍스트로만 정답을 맞춘 비율이 2.65%, 오직 이미지만 보고 정답을 맞춘 비율이 2.05%입니다.
- 이는 노드마다 정답을 찾는 데 결정적인 역할을 하는 모달리티(Modality)가 다름을 의미합니다. 즉, 모든 노드에 똑같은 방식(One-size-fits-all)으로 질문을 던지는 기존 방식이 왜 비효율적인지를 명확히 보여주는 근거입니다.
핵심 요약
결론적으로 이 이미지는 **(a)**를 통해 단순한 VLM 인코딩이 왜 실패하는지(일관성 부족)를 보여주고, **(b)**를 통해 왜 각 노드의 특성에 맞춰 텍스트나 이미지 중 알맞은 것을 골라주는 똑똑한 라우터(Router)가 필요한지를 수치로 증명하고 있습니다.
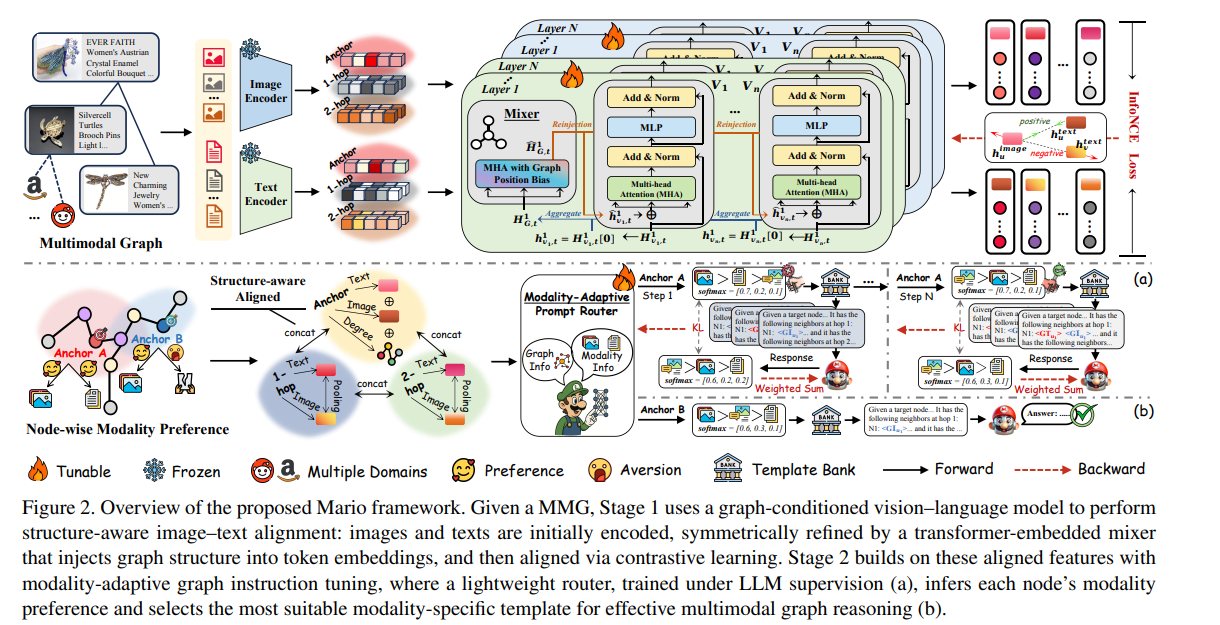
전체적인 흐름
- 입력 데이터 (왼쪽 상단): 이미지와 텍스트 설명이 포함된 제품들이 서로 연결된 '멀티모달 그래프'가 입력됩니다.
- Stage 1 (상단 민트색 영역): 그래프 구조 정보를 활용해 입력된 이미지 특징과 텍스트 특징을 서로 아귀가 맞게끔 정렬(Alignment)하고 세련되게 다듬습니다.
- Stage 2 (하단 영역): 정렬된 특징들을 바탕으로, 각 데이터(노드)에 가장 적합한 질문 방식(프롬프트 템플릿)을 동적으로 선택하여 LLM에게 전달하고 최종 정답을 얻습니다.
상세 설명
1. Stage 1: 그래프 조건부 비전-언어 모델 (Graph-Conditioned VLM)
이 단계의 목표는 이미지와 텍스트 임베딩(특징 벡터)이 그래프 구조 안에서 서로 긴밀하게 연결되도록 만드는 것입니다. 서론에서 언급한 '약한 교차 모달 일관성(C1)' 문제를 해결합니다.
- 인코딩 (Frozen Encoders): 입력된 이미지와 텍스트를 미리 학습된 고정된(눈송이 아이콘, Frozen) 인코더(예: CLIP)에 통과시켜 기초 특징을 뽑습니다.
- 이웃 샘플링 (Anchor, 1-hop, 2-hop): 특정 데이터(Anchor)만 보는 것이 아니라, 그래프 상에서 1단계, 2단계 떨어진 이웃 노드들의 정보도 함께 가져옵니다. 빨간색으로 표시된 특징 덩어리들이 이를 나타냅니다.
- 믹서 (Mixer - 학습 가능, 불꽃 아이콘): 이 프레임워크의 핵심 구성 요소입니다. 트랜스포머 레이어(Layer 1 to N)로 구성되어 있습니다.
- 가져온 이웃 정보들과 앵커 정보를 섞습니다(Aggregate).
- 중요한 점은 'MHA with Graph Position Bias' 블록입니다. 단순히 특징만 섞는 게 아니라, 그래프 상에서 얼마나 가깝고 멀리 있는지에 대한 위치 정보(Bias)를 고려하여 주의(Attention)를 기울입니다.
- 텍스트 정보가 이미지 특징을 다듬는 데 도움을 주고, 반대로 이미지 정보가 텍스트 특징을 다듬는 데 도움을 주는 대칭적인 구조(Reinjection arrows)를 가집니다.
- 손실 함수 (InfoNCE Loss): 마지막으로 이렇게 다듬어진 이미지 특징($h_u^{image}$)과 텍스트 특징($h_u^{text}$)이 서로 같은 노드에서 나왔다면 더 가까워지게(Positive), 다른 노드에서 나왔다면 더 멀어지게(Negative) 학습시킵니다. 이를 통해 '구조를 인식하는 일관된 표현력'을 갖게 됩니다.
2. Stage 2: 모달리티 적응형 그래프 인스트럭션 튜닝 (Modality-Adaptive Graph Instruction Tuning)
이 단계는 서론의 '이질적 모달리티 선호도(C2)' 문제를 해결합니다. 모든 노드에 똑같은 질문을 던지는 대신, 각 노드의 특성에 맞춰 가장 적절한 정보를 LLM에 제공합니다.
- 노드별 선호도 파악 (왼쪽 하단): 그래프 상의 노드들은 각자 선호하는 모달리티가 다릅니다. 어떤 건 텍스트가 중요하고(웃는 얼굴), 어떤 건 이미지가 중요합니다.
- 특징 통합 (Structure-aware Aligned): Stage 1에서 얻은 정렬된 특징들을 결합(Concat)하고 풀링(Pooling)하여, 그래프 구조와 멀티모달 정보가 모두 담긴 최종 벡터를 만듭니다.
- 라우터 (Modality-Adaptive Prompt Router - Luigi 캐릭터): Luigi로 표현된 이 가벼운 네트워크는 통합된 특징 벡터를 입력받아, 현재 노드에 어떤 프롬프트 템플릿이 가장 적합한지 확률(Softmax)을 계산합니다. 그림에서는 3가지 선택지(텍스트만 사용, 이미지만 사용, 둘 다 사용 등)에 대한 확률값([0.7, 0.2, 0.1] 등)을 내놓습니다.
- LLM과의 상호작용 및 학습 (오른쪽 하단):
- (a) 학습 단계 (빨간색 화살표): LLM(은행 아이콘, 템플릿 뱅크)은 라우터가 선택한 템플릿에 따라 답변을 생성합니다. 이 답변의 정확도(또는 그림의 KL 화살표로 표현된 손실값)를 바탕으로 라우터를 학습시킵니다. 즉, LLM이 "이 노드는 이미지를 보여줬을 때 정답을 더 잘 맞추네?"라는 피드백을 주면 라우터는 다음에 유사한 노드를 만나면 이미지 비중이 높은 템플릿을 선택하도록 학습됩니다.
- (b) 추론 단계 (검은색 화살표): 실제 사용 시, 새로운 노드(Anchor B)가 들어오면 라우터가 계산한 확률에 따라 템플릿들의 가중합(Weighted Sum)을 구합니다. 이렇게 만들어진 **'맞춤형 프롬프트'**를 최종 LLM(Mario 캐릭터)에게 전달하여 정답(Answer)을 얻습니다.
요약
이 그림은 Stage 1에서 이웃 노드 정보를 활용해 이미지와 텍스트의 짝을 잘 맞춰주는 고성능 인코더를 만들고, Stage 2에서 똑똑한 라우터(Luigi)를 학습시켜 각 데이터마다 LLM(Mario)에게 어떤 정보를 보여주는 게 가장 좋을지 동적으로 결정하게 만드는, 2단계 멀티모달 그래프 추론 시스템을 보여줍니다.
Related Work
Large Language Models for Graph Reasoning. 연구들은 LLMs가 graph representations를 증강시키고 contextualized textual information을 생성하여 semantic expressiveness를 향상시키고 downstream graph learning performance를 개선하는 잠재력을 보여주었습니다. 또 다른 연구 방향은 graph 또는 language models를 활용하여 graph tokens를 얻은 다음, 이를 instruction tuning을 위한 prompt templates에 삽입하거나 in-context learning(ICL)을 통해 graph structure와 관련된 더 많은 텍스트 정보를 LLMs에 직접 제공하여 training 없이 직접 추론(infer)하도록 합니다. graph instruction tuning을 적용할 때, 이는 LLMs가 이러한 structure-informed tokens를 이해하고 적절한 reasoning을 수행할 수 있게 하여 특정 graph-related tasks에서 더 나은 generalization을 이끌어냅니다. 그러나 이러한 연구들의 대부분은 오직 textual modality(text-attributed graphs)에서만 작동하며 multimodal graph reasoning에 대해서는 generalization이 제대로 이루어지지 않습니다. 더욱이, 그들의 instruction tuning은 일반적으로 고정된 modality inputs를 가진 단일 template에 의존하여, 다른 nodes가 다른 modality 정보를 선호할 수 있다는 점을 간과합니다.
Multimodal Graph Learning. Multimodal graph learning은 node/edge representations를 향상시키기 위해 여러 modalities, 주로 text와 images를 통합함으로써 기존의 graph representation learning을 확장합니다. 최근의 multimodal graph datasets 및 benchmarks와 일부 multimodal KG 연구들은 이 분야의 연구를 촉진했지만, 효과적인 multimodal graph models의 개발은 여전히 해결해야 할 과제로 남아 있습니다. 일반적인 접근 방식은 multimodal representation alignment를 활용하며, 주로 VLMs에 의존하여 multimodal node embeddings를 생성하고 downstream graph tasks를 수행합니다. 보다 최근에 MLaGA는 instruction tuning과 함께 graph-guided multimodal aligner를 사용하여 LLMs에 graph-aware multimodal tokens를 제공하지만, 이는 text와 image를 공유된 query representation으로 융합(fusing)한 후에만 정렬(align)합니다(per-modality가 아님). 결과적으로, 이는 암시적으로 동등한 modality 유용성을 가정하며 MMGs에서 node-level modality inconsistency 및 heterogeneous modality preference를 해결하지 못합니다. Graph4MM은 multi-hop structural 정보를 self-attention에 직접 주입하기 위해 hop-diffused attention을 도입하지만, 주로 누락된 modalities가 있는 MMGs를 목표로 하여 각 node가 text와 image를 모두 가지고 있는 널리 퍼진 fully observed 설정을 간과합니다. 결과적으로, 기존의 접근 방식들은 여전히 MMGs의 두 가지 핵심적인 현실을 놓치고 있습니다: (i) text-image consistency가 약할 수 있어 단순한 fusion/alignment를 신뢰할 수 없게 만들며, (ii) modality preference가 nodes마다 다릅니다.
2. Related Work 정리 노트
- Large Language Models for Graph Reasoning의 한계
- 기존 연구들은 LLM을 통해 graph representation을 강화하고 ICL이나 instruction tuning을 활용하지만, 대부분 Textual modality(텍스트 속성 그래프)에만 국한되어 있어 multimodal graph reasoning으로의 확장이 어려움.
- 결정적으로 고정된 modality input을 가지는 단일 템플릿(Single template)에만 의존함. 이는 노드마다 고유하게 선호하는 modality가 다르다는 점(Heterogeneous modality preference)을 완전히 간과한 방식임.
- Multimodal Graph Learning의 한계
- VLM을 활용해 multimodal node embedding을 생성하는 기존 접근법들이 가진 치명적인 맹점:
- MLaGA: 텍스트와 이미지를 개별적으로 다루지 않고, 먼저 하나의 공유된 representation으로 합친(fusing) 후에 정렬(alignment)을 수행함. 이는 두 modality의 유용성이 항상 동일하다고 암묵적으로 가정한 것으로, 노드 수준의 불일치성(Inconsistency)이나 이질적인 선호도 문제를 근본적으로 해결하지 못함.
- Graph4MM: Multi-hop 구조 정보를 활용하긴 하지만, 주로 modality가 '누락된' 특수 상황에만 초점을 맞춤. 즉, 각 노드가 텍스트와 이미지를 모두 온전히 가지고 있는 가장 일반적인 환경(Fully observed setting)은 다루지 않음.
- VLM을 활용해 multimodal node embedding을 생성하는 기존 접근법들이 가진 치명적인 맹점:
- 기존 연구들의 공통적인 맹점 (본 논문의 핵심 타겟)
- 현실의 MMG에서는 text-image consistency가 매우 약할 수 있어, 기존의 단순한 융합(Fusion)이나 정렬 방식은 신뢰성이 떨어짐.
- 노드마다 문제 해결에 유용한 Modality preference(텍스트 위주, 이미지 위주 등)가 다르다는 현실을 모델링하지 못함.
쉬운 설명 : 2. Related Work
이 섹션은 "왜 기존에 나온 훌륭한 AI 모델들로는 이 복잡한 멀티모달 그래프 문제를 제대로 풀 수 없는가?"를 비판적으로 짚어내는 부분입니다.
첫째, 기존의 그래프 추론 LLM들은 주로 '글자'로만 이루어진 데이터에 최적화되어 있습니다. 게다가 모든 데이터에 대해 똑같은 방식의 질문(단일 템플릿)만 던지는 융통성 없는 모습을 보입니다. 어떤 노드는 사진이 훨씬 중요할 수도 있는데 무조건 정해진 틀로만 질문하니 성능이 떨어질 수밖에 없습니다.
둘째, 이미지와 텍스트를 함께 다루는 최신 그래프 모델들(예: MLaGA, Graph4MM 등)도 헛점이 있습니다. 어떤 모델은 텍스트와 이미지가 무조건 똑같은 가치를 지닌다고 착각해서 일단 하나로 뭉뚱그려버립니다(단순 융합의 한계). 또 다른 모델은 정보가 '빠져있는' 상황을 복구하는 데만 집중하느라, 멀쩡하게 텍스트와 이미지가 다 있는 현실적인 상황은 제대로 다루지 못합니다.
결국 이 논문은 기존 연구들이 **"텍스트와 이미지가 서로 딴소리를 할 수 있다(일관성 부족)"**는 점과 **"데이터마다 텍스트가 더 결정적인 힌트일 수도, 이미지가 더 결정적일 수도 있다(선호도 차이)"**는 현실을 짚어내지 못했다는 것을 지적하며, 자신들이 제안하는 모델이 이 빈틈을 완벽하게 파고들었음을 강조하기 위해 이 섹션을 작성했습니다.
Preliminary
Multimodal Graph.
multimodal graph는 각 node가 여러 modalities와 연관된 structured data format입니다. 우리의 경우, 각 node는 textual description과 연관된 image를 가집니다. 형식적으로 graph는 $G=(V, E, A, X)$로 표시되며, 여기서 $V$는 node 집합, $E$는 edge 집합, $A \in \mathbb{R}^{N \times N}$은 $(v_i, v_j) \in E$이면 $A_{ij}=1$, 그렇지 않으면 $0$인 adjacency matrix입니다. $X$는 multimodal node features의 집합이며, 각 요소 $x_v \in X$는 structured pair $(x_v^{\text{text}}, x_v^{\text{image}})$이고, 여기서 $x_v^{\text{text}} \in \mathbb{R}^{d_t}$ 및 $x_v^{\text{image}} \in \mathbb{R}^{d_i}$는 node $v$의 textual 및 visual features를 나타냅니다.
Large Language Models and Instruction Tuning.
Large Language Models는 instruction tuning을 통해 downstream tasks에 적응될 수 있으며, 이는 model parameters $\theta$에 대한 parameter-efficient 또는 full updates를 가능하게 합니다. 기존의 fine-tuning과 달리, instruction tuning은 task-specific instructions와 선택적인 learnable soft tokens를 결합하는 structured prompts를 통해 LLMs를 향상시킵니다. textual tokens의 input sequence $X=x_1, x_2, \dots, x_p$가 주어지면, instruction function $T$는 structured prompt $T(X)$를 생성합니다. 이는 learnable soft token set $S=s_1, s_2, \dots, s_q$와 연결(concatenated)되어 augmented prompt $P=[T(X); S]$를 형성할 수 있습니다. 그런 다음 model은 $P$ 및 $X$를 조건으로 하여 output sequence $Y$를 생성합니다. Training은 $S$와 $\theta$를 공동으로 최적화하여 전체 model retraining의 필요성을 줄이면서 task adaptation을 개선합니다.
Methodology
이 섹션에서는 Figure 2에 설명된 Mario의 상세 architecture를 소개합니다. 이는 두 가지 새로운 stages로 구성됩니다: multimodal graphs에서 cross-modal consistency를 향상시키는 graph-conditioned vision-language model (Sec. 4.1) (C1 ✓)과 heterogeneous modality preferences에 맞춤화된 modality-adaptive graph instruction tuning scheme (Sec. 4.2) (C2 ✓)입니다. 마지막으로 model의 training 및 inference procedures에 대한 개요와 runtime complexity에 대한 논의(Sec. 4.3)로 마무리합니다.
4.1. Graph-conditioned Vision-Language Model
Objective.
모든 node $v$가 text sequence $T_v$와 image patch sequence $I_v$를 소유하는 multimodal graph $G$가 주어졌을 때, Stage 1은 (i) 동일한 node의 text 및 vision cues가 측정학적으로(metrically) 가깝고, (ii) fine-grained modality 정보를 보존하기 위해 structure-aware alignment가 수행되며, (iii) embeddings가 modality consistency를 향상시키기 위해 neighborhood dependencies를 존중하는 latent space를 학습합니다. 우리는 각 encoder가 Topology-Aware Multimodal Mixer를 갖추어 그 [CLS] summary가 graph guidance 하에 모든 tokens 및 patches에 attend하도록 하는 dual-tower architecture를 사용하는 graph-conditioned vision-language model (GVLM)을 소개합니다. 그런 다음 Bidirectional InfoNCE가 이러한 graph-conditioned [CLS] representations에 적용되어 structure-aware 방식으로 두 streams를 align합니다.
Modality Encoding.
우리는 각 modality마다 하나씩, 두 개의 별도 L-layer Transformers를 사용합니다. 주어진 node $v$에 대해 layer $l$에서의 hidden representation은 $\mathbf{H}{v,M}^l \in \mathbb{R}^{t_M \times d}$로 표시되며, 여기서 $M \in {t, i}$는 modality (text 또는 image)를 나타내고, $t_t = m$은 text tokens의 수, $t_i = n$은 image patches의 수입니다. 초기 Layer-0 embeddings는 CLIP과 같은 pretrained vision-language representations에서 파생되며, 후속 transformer layers를 지원하기 위해 position embeddings로 강화됩니다. [CLS] token embedding $\mathbf{h}{v,M}^l = \mathbf{H}_{v,M}^l[0]$은 다음 topology-aware multimodal mixer에서 사용되는 node representation 역할을 합니다.
Topology-Aware Multimodal Mixer.
modality $M \in \{t, i\}$ 및 layer $l$에 대해, 먼저 모든 graph nodes의 [CLS] summaries를 모아 node-by-feature matrix를 구축합니다:
(1)
각 attention head $h=1, \dots, H$는 다음을 통해 node representations를 queries, keys, 그리고 values로 project합니다:
(2)
여기서 각 $\mathbf{W}^{\cdot}{M,h} \in \mathbb{R}^{d\times (d/H)}$는 head $h$에 대한 trainable projection matrix입니다. 그런 다음 graph-aware position bias로 강화된 Scaled dot-product attention이 적용됩니다:
(3)
학습된 position bias $\mathbf{B}_h$는 graph structural roles를 encode하여 nodes 간의 관계를 구별하고, 일종의 상대적 위치 정보(relative positional information) 역할을 하며, shortest-path-distance buckets로 인덱싱된 head-specific learnable scalars로 구현됩니다. 모든 heads를 연결(Concatenating)하면 $\widehat{\mathbf{H}}^{l}{\mathcal{G},M} \in \mathbb{R}^{|\mathcal{V}|\times d}$가 산출되며, 여기서 $v$번째 행 $\widehat{\mathbf{h}}^{l}_{v,M}$은 node $v$에 대한 structure-aware representation을 encode합니다.
Reinjection for Multimodal Context Integration.
structure-aware representation $\widehat{\mathbf{h}}^{l}_{v,M}$을 token stream으로 다시 전파하기 위해, 이를 modality-specific sequence의 앞부분에 추가하여 이전 [CLS] token embedding을 대체함으로써 sequence length와 embedding dimension을 변경 없이 유지합니다. 이 augmented sequence는 다음 Transformer block에 의해 처리됩니다:
(4)
각 layer에서 새로운 [CLS] token이 생성되어, model이 새로 집계된(aggregated) graph context를 원본 token features와 혼합하여 node-level representation을 반복적으로 개선할 수 있게 합니다. 이 mixer-reinjection 연산을 $L$ layers 동안 반복하면 최종 structure-aware embeddings가 산출됩니다:
(5)
이것은 modality-specific 뉘앙스와 topology-aware signals를 모두 포착하며, 나중에 cross-modal contrastive alignment를 위한 GVLM prototypes로 사용될 것입니다.
Cross-Modal Contrastive Learning.
modalities 간의 간격을 더욱 좁히기 위해, 우리는 위에서 얻은 structure-aware modality embeddings에 대해 bidirectional contrastive objective를 수행하여 GVLM을 train합니다: batch $\mathcal{B}$의 각 node $v$에 대해, 그 text-image pair $(\mathbf{h}_v^{\text{text}}, \mathbf{h}_v^{\text{image}})$가 유일한 positive인 반면, batch 내에서 샘플링된 모든 cross-node 조합은 negatives 역할을 합니다. 이러한 embeddings는 이미 topology를 포함(fold in)하고 있기 때문에, 일반 text corpora에는 없는 neighbor signals가 cross-modal gap을 좁히는 핵심이 되어, model이 동시에 modality-aligned 및 structure-aware representations를 학습하도록 강제합니다. 우리는 대칭적인 temperature-scaled InfoNCE loss를 최소화합니다:
(6)
여기서 $s(u, v)$는 $\mathbf{h}_u^{\text{text}}$와 $\mathbf{h}_v^{\text{image}}$ 사이의 cosine similarity이며 $\tau$는 선명도(sharpness)를 제어합니다. 이 단계는 Stage 2의 adaptive instruction tuning에 직접 공급되는 modality-consistent, topology-aware representations를 제공하며 경험적으로 downstream cross-modal coherence를 높입니다.
4.2. Modality-Adaptive Graph Instruction Tuning
Objective.
Stage 1에서 얻은 features를 바탕으로, Stage 2는 LLM에 node-level modality adaptivity를 부여합니다. (i) 각 node에 대해, 우리는 그 features를 상위 1/2-hop neighbors와 혼합하여 세 가지 modality views (text, image, multimodal) 하에서 multimodal graph signals가 포함된 prompts를 구성합니다. (ii) probability-weighted LLM loss 및 KL term으로 학습된 Modality-Adaptive Prompt Router (MAPR)는 가장 낮은 loss를 산출하는 view로 probability를 재할당(reallocates)하여, LLM이 noisy한 modalities를 down-weighting하면서 정보가 풍부한 modalities를 활용할 수 있도록 합니다.
Multimodal Graph-Contextual Signals.
모든 node $v$에 대해, 우리는 LLM을 본질적인 multimodal features와 가장 관련성 높은 structural context 모두에 노출시킵니다. 우리는 두 개의 special tokens인 $\langle\text{GT}_v\rangle$과 $\langle\text{GI}_v\rangle$를 도입하여 prompt에 배치함으로써 LLM에 graph node $v$에 대한 text 및 image 정보를 제공합니다. 이들의 embeddings는 learnable shared projector $P$를 Stage-1 features $\mathbf{h}_v^{\text{text}}$ 및 $\mathbf{h}_v^{\text{image}}$에 적용하여 LLM token embedding space로 매핑함으로써 얻어집니다. neighborhood 증거로 prompt를 강화하기 위해, 우리는 training set에서 1-hop 및 2-hop neighbors $\mathcal{N}^1(v), \mathcal{N}^2(v)$를 조사하고 concatenated embeddings $[\mathbf{h}_u^{\text{text}} \parallel \mathbf{h}_u^{\text{image}}]$와 $[\mathbf{h}_v^{\text{text}} \parallel \mathbf{h}_v^{\text{image}}]$ 간의 cosine similarity를 기반으로 $v$에 상대적으로 중요한 hop 당 Top-$K$ nodes를 선택합니다. 선택된 각 neighbor $u$에 대해 우리는 anchor node $v$의 modality preference를 기반으로 $\langle\text{GT}_u\rangle$, $\langle\text{GI}_u\rangle$를 생성하고 선택적으로(optionally) 주입(inject)하며, LLMs를 위한 ICL paradigm을 따라 그 label $l_u$를 첨부하여 (inference 동안, 이 전체 절차는 training nodes로만 제한됩니다; validation/test nodes는 결코 in-context exemplars로 사용되지 않습니다), 따라서 다른 modality-specific templates를 형성합니다.
Prompt Template Bank.
node의 modality preference는 자신의 modalities와 local subgraph에 의해 공동으로 형성됩니다. 다른 preferences 하에서 보완적인 MMG 증거를 노출시키기 위해, 우리는 node $v$에 대해 세 가지 modality-specific special-token groups를 형성합니다:
여기서 $\langle\text{GT}_{\cdot}\rangle$ 및 $\langle\text{GI}_{\cdot}\rangle$은 앞서 정의된 graph-text 및 graph-image tokens입니다. 그런 다음 node $v$에 대한 prompt를 세 부분의 concatenation으로 정의합니다—$I$ (task instruction), $r_v$ (anchor node raw text), 그리고 $S_v^{(k)}$ (modality-specific special tokens)—즉, $P_v^{(k)} = I \oplus r_v \oplus S_v^{(k)}$이며, 여기서 $k \in {\text{txt}, \text{vis}, \text{mm}}$입니다. 여기서 $I$는 task를 지정하는 간결한 instruction (예: "node category를 예측하시오.")입니다; $r_v$는 fine-grained semantics를 보존하기 위해 anchor node의 원시 textual content를 전달합니다; 그리고 $S_v^{(k)}$는 $v$와 그 상위 1/2-hop neighbors로부터 modality-specific graph signals를 공급하며, 이는 multimodal graphs의 context에서 LLM의 in-context learning 잠재력을 해제(unlock)하기 위해 LLM으로 라우팅(routed)되기 전에 node-specific multimodal cues와 가장 정보가 풍부한 structural signals를 원활하게 결합(weaves together)합니다.
Modality-Adaptive Prompt Router.
그러나 더 나쁜 modalities의 영향을 최소화하면서 각 node의 modality preference를 결정하는 방법과 유리한 modality에 따라 LLM이 선택적으로 update되도록 만드는 방법은 여전히 해결되지 않은 문제입니다. 이를 위해 우리는 LLM 앞에 배치된 가볍지만 표현력이 풍부한 Modality-Adaptive Prompt Router (MAPR)를 도입합니다. 각 node $v$에 대해 Stage 1 multimodal embedding, mean-pooled 1-/2-hop context, 그리고 logarithmic degree term을 연결(concatenate)하여 input으로 사용합니다:
(7)
(8)
link prediction task의 node pairs의 경우, 먼저 두 nodes를 pool하고 이들을 단일 pseudo-node로 취급한 다음, 일반 nodes와 동일한 방식으로 input을 구성합니다. 그 후 template에서 이들의 common neighbors를 선택하고 해당 tokens를 embed합니다. training 동안 우리는 bank의 모든 templates를 LLM에 노출시켜 다른 modality 정보를 포함하는 prompts의 순위(rank)를 매기도록 학습시킵니다. 가벼운 MLP router는 다양한 정보를 하나의 feature로 융합(fuses)하고, routing probabilities $\mathbf{p}_v = \text{softmax}(\mathbf{s}_v) = [p_v^{(\text{txt})}, p_v^{(\text{vis})}, p_v^{(\text{mm})}]^{\top}$로 정규화된(normalised) modality-selection logits $\mathbf{s}_v \in \mathbb{R}^3$를 얻습니다. 각 template에 대해 LLM은 다음 함수를 통해 negative causal language modeling loss를 생성합니다:
(9)
우리는 이를 performance posterior $\mathbf{q}_v=\mathrm{softmax}!\bigl ( -[\ell^{(\text{txt})}_v,\ell^{(\text{vis})}_v,\ell^{(\text{mm})}_v] \bigr )$로 변환하고 MAPR updates를 guide하는 데 사용합니다. Training은 다음 composite loss를 최소화합니다:
(10)
여기서 첫 번째 항(term)은 loss에서 추론된 posterior $\mathbf{q}_v$에 비례하여 gradient를 각 template으로 route하는 performance-weighted objective이며, KL 항은 predictive distribution $\mathbf{p}_v$를 $\mathbf{q}_v$와 일치시켜 router를 regularize합니다. 이 teacher-student coupling은 probability mass를 더 낮은 loss의 templates로 이동시켜, LLM이 정보가 풍부한 modalities에 의존하고 noisy한 modalities를 down-weighting하도록 장려합니다. MAPR은 supervisory signal을 modality preference에 맞춤화하여 불일치하는(mismatched) modalities로부터의 gradients를 약화시킴으로써 optimization을 안정화하고 generalization을 향상시킵니다.
4.3. Discussion
Training & Inference Strategy.
Mario는 순차적인(sequential) 루틴을 채택합니다. (i) Stage 1 pre-training. 우리는 먼저 cross-modal InfoNCE loss $\mathcal{L}{\text{S1}}$을 사용하여 수렴할 때까지 GVLM을 최적화하여 $\Theta^{\star}{\text{S1}}$을 얻습니다. (ii) Stage 2 instruction tuning. $\Theta^{\star}{\text{S1}}$을 고정(fixed)한 채로, 우리는 composite loss $\mathcal{L}{\text{S2}}$를 사용하여 MAPR과 함께 LoRA를 사용하여 LLM을 fine-tune합니다. 두 training stages에서 사용된 datasets는 동일하게 유지됩니다. inference 시간에 MAPR은 training에서 사용된 soft routing에서 hard policy로 전환하여 template $k^{\star} = \arg \max p_v^{(k)}$를 선택하고 해당하는 prompt만 LLM에 공급하므로, 단일 템플릿(single-template) pipeline과 비교하여 추가 계산(extra compute)이 발생하지 않습니다.
Complexity Analysis.
(i) Stage 1. 각 multimodal mixer layer는 graph bias와 함께 모든 nodes의 [CLS] tokens에 attend하여 layer 당 $\mathcal{O}(|\mathcal{V}_s|^2d)$의 비용을 산출하며, 여기서 $\mathcal{V}_s$는 샘플링된 node set을 나타내고 일반적으로 $|\mathcal{V}s| \ll |\mathcal{V}|$입니다. 그러나 실제로 alignment 수렴에 도달하는 데는 1-2 layers만으로도 충분하므로, 전체 training 시간은 더 깊은 vanilla Transformer stack과 비교하여 적당하게 유지됩니다. (ii) Stage 2. 모든 training sample에 대해 우리는 세 번의 forward-backward passes(template 당 하나씩)를 실행하여 $\mathcal{O}(3f{\text{LLM}})$의 비용을 산출합니다. 경험적으로, router는 단일 템플릿(single template) baseline이 필요로 하는 epochs의 대략 절반만에 더 낮은 losses로 model이 수렴하도록 허용하며, 이는 단계별 추가 계산(extra per-step computation)을 상쇄(offset)합니다 (Figure 3의 empirical training curve 참조).
4. Methodology 정리 노트
Stage 1: Graph-conditioned Vision-Language Model (GVLM)
- 핵심 목표: 노드 내 이미지-텍스트 간의 Weak cross-modal consistency를 그래프 구조(Topology)를 이용해 강제 정렬.
- Topology-Aware Multimodal Mixer:
- 단순 VLM 인코딩이 아니라, 각 레이어에서 Graph Position Bias가 가미된 Attention을 수행.
- Shortest-path-distance 기반의 learnable bias를 통해 이웃 노드들과의 거리에 따른 상대적 중요도를 반영하여 [CLS] 토큰을 업데이트.
- Reinjection Mechanism:
- 업데이트된 구조 인지적(Structure-aware) [CLS] 표현을 다시 토큰 스트림의 맨 앞에 주입하여 다음 트랜스포머 레이어로 전달.
- 이를 통해 모달리티 고유의 뉘앙스와 그래프 구조 정보를 반복적으로 융합.
- Bidirectional InfoNCE Loss:
- 그래프 구조 정보가 이미 녹아든 $\mathbf{h}^{\text{text}}_v$와 $\mathbf{h}^{\text{image}}_v$ 사이의 대조 학습을 수행하여, 구조적으로 일관된 멀티모달 잠재 공간 생성.
Stage 2: Modality-Adaptive Graph Instruction Tuning
- 핵심 목표: 노드마다 최적의 정보원(텍스트 vs 이미지 vs 둘 다)이 다르다는 점을 반영한 Dynamic Prompting.
- Prompt Template Bank:
- $\mathcal{S}_v^{\text{txt}}$, $\mathcal{S}_v^{\text{vis}}$, $\mathcal{S}_v^{\text{mm}}$ 세 가지 뷰를 미리 생성.
- 단순 노드 정보뿐 아니라 유사도가 높은 상위 K개의 이웃 정보(In-context exemplars)를 함께 주입.
- Modality-Adaptive Prompt Router (MAPR):
- 입력: Stage 1 임베딩 + 주변 이웃의 평균 풀링 특징 + 노드 Degree의 로그값.
- Teacher-Student coupling: LLM이 각 템플릿으로 계산한 실제 손실값($\mathbf{q}_v$, Teacher)을 바탕으로 라우터의 예측 확률($\mathbf{p}_v$, Student)을 KL Divergence로 학습.
- LLM은 정보량이 많은 모달리티에는 높은 가중치를, 노이즈가 많은 모달리티에는 낮은 가중치를 두도록 유도됨.
훈련 및 추론 전략
- Efficiency: 추론 시에는 가장 확률이 높은 단일 템플릿만 사용하므로 단일 템플릿 모델과 계산 복잡도가 동일함 (Hard policy).
- Convergence: 라우터 덕분에 단일 템플릿 모델보다 약 2배 빠른 수렴 속도를 보임.
쉬운 설명 : 4. Methodology
이 논문의 핵심 알고리즘은 "서로 딴소리 하는 데이터 짝을 맞추고(Stage 1), 상황에 맞는 질문지를 골라주는(Stage 2)" 과정입니다.
1. 엇갈린 짝꿍 맞추기 (Stage 1)
인터넷 데이터는 사진과 글이 따로 노는 경우가 많습니다. Mario는 이를 해결하기 위해 '주변 친구(이웃 노드)'들을 살핍니다. "이 사진이 뭔지 모르겠는데, 옆에 연결된 노드들의 글을 보니 이건 '클래식 카메라'구나!"라고 주변 맥락을 통해 자기 노드의 이미지와 글을 일치시킵니다. 특히 레이어마다 이 정보를 다시 주입(Reinjection)해서 아주 정교하게 짝을 맞춘 특징 벡터를 만들어냅니다.
2. 똑똑한 비서 Luigi 고용하기 (Stage 2)
이제 잘 정리된 데이터를 LLM에게 보여줄 차례인데, 무작정 "그림이랑 글 다 봐!"라고 하는 건 비효율적입니다. 그래서 MAPR이라는 똑똑한 비서(라우터)를 둡니다. 이 비서는 데이터를 미리 훑어보고 "이 노드는 사진이 선명하니까 사진 위주의 질문지를 주자", "이건 글이 더 정확하니까 글 위주로 물어보자"라고 결정합니다.
학습할 때는 LLM(선생님)이 "네가 골라준 질문지로 푸니까 진짜 정답률이 높네!"라고 피드백을 주면 비서(라우터)가 그 방식을 배우게 됩니다. 나중에 실제 서비스를 할 때는 비서가 딱 하나의 최적 템플릿만 골라주기 때문에 계산량도 늘어나지 않으면서 훨씬 정확한 답을 낼 수 있게 됩니다.
노드 : 각 데이터
노드의 값.
텍스트 피쳐, 이미지 피쳐
엣지 : 연결성
연결 관계 (이건 텍스트 이미지 피쳐를 컨캣해서 다른 노드랑 유사도를 구해서 topk정도 뽑아둠
연결된 애들 중에서
2hop도 그냥 2hop이랑 다이렉트로 계산해버림 top k개
근데 이건 스테이지2 전용)
노드는 연결된 엣지를 통해 1개연결, 과 직접은 아니지만 2다리 걸쳐 연결된 노드들 을 k개씩 뽑음 그게 이웃 정보인데, 그거까지 인풋으로 쓰임
학습은 투스테이지로 진행
사전학습단계인 GVLM이라는 친구 먼저 진행
이땐 K개 이런거 없음
걍 하나뽑고 걔랑 연결된애들 싹잡아와서 10개정도 채워서 사용
텍스트에서 0번 인덱스가 cls토큰인데, 이를 10개 떼어서 각각 쿼리 키 밸류를 만들어서 어텐션 해주고 그 스코어에 칸수에 따른 가중치를 주게됨
이미지도 똑같이 cls 토큰따서 어텐션 쌔려버림
대신 바로 하면 정보 없으니까 셀프어벤션 몇번 쌔리고 해야함
딴건 다시 넣음. 뭐 주입이니 뭐니 하는데 그냥 어텐션 하고 제자리로 돌아가는느낌
이제 내부에서 셀프어텐션 또 때림.
끝나면 다시 cls토큰 떼서 같은 노드의 텍스트랑 이미지만 파지티브로 하고 나머지는 오답으로 해버림.
파지티브쪽 유사도가 1이 되게끔 loss를 흘림
그래서 텍스트랑 이미지가 잘 얼라인이 되게끔 학습이됨
이제 스테이지2
아까 말한 topk를 여기서 사용.
텍스트만
이미지만
텍스트+이미지 (요건 컨캣으로 사용하는 것 같음)
타켓 + 이웃들로 모아서 3 템플릿을 준비
프롬프트에서 부를땐 이상한 토큰을 사용하는데 별로 안중요함
그 정보들을 그냥 라우터에 때려서 뭘 쓸지 정보를 얻음
학습떈 근데 llm 에게 전부 정보를 줘서 풀게 해보고 제일loss낮은 조합이 정답이라고 가정하고 라우터를 학습
실제 인퍼런스에선 라우터 학습