

AI바라기의 인공지능
VLM : 논문리뷰 : MM-REACT : Prompting ChatGPT for Multimodal Reasoning and Action 본문
VLM : 논문리뷰 : MM-REACT : Prompting ChatGPT for Multimodal Reasoning and Action
AI바라기 2024. 8. 17. 17:32Abstract
MM-REACT를 제안합니다. 이는 ChatGPT와 다수의 vision experts를 통합하여 multimodal reasoning 및 action을 달성하는 시스템 패러다임입니다.
본 논문에서는 기존 vision 및 vision-language models의 능력을 넘어서는 흥미롭지만 해결하기 어려운 고급 vision tasks 목록을 정의하고 탐구합니다. 이러한 고급 시각 지능을 달성하기 위해 MM-REACT는 텍스트 설명, textualized spatial coordinates 및 이미지 및 비디오와 같은 dense visual signals에 대한 aligned file names를 나타낼 수 있는 textual prompt design을 도입합니다.
MM-REACT의 prompt design은 language models가 multimodal 정보를 수용, 연관 및 처리할 수 있도록 하여 ChatGPT와 다양한 vision experts의 시너지 효과적인 결합을 촉진합니다. Zero-shot 실험은 MM-REACT가 특정 관심 기능을 해결하는 데 있어 효과적이며 고급 visual understanding이 필요한 다양한 시나리오에 널리 적용될 수 있음을 보여줍니다. 또한, MM-REACT의 시스템 패러다임을 joint finetuning을 통해 multimodal 시나리오를 위한 language models를 확장하는 다른 접근 방식과 비교하고 논의합니다. 코드, 데모, 비디오 및 시각화 자료를 제공합니다.

그림 1. MM-REACT는 ChatGPT와 함께 특수 목적 vision experts를 할당하여 멀티모달 추론 및 액션을 통해 까다로운 시각적 이해 작업을 해결합니다. 예를 들어, 시스템은 여러 개의 업로드된 영수증에서 정보를 연결하여 총 여행 비용을 계산할 수 있습니다("Multi-Image Reasoning"). 여기서는 핵심 정보만 강조하고 전체 MM-REACT 응답은 그림 4-14에서 다루겠습니다.
Introduction
최근 몇 년 동안 향상된 network architecture, 대규모 model training 및 기타 요인 덕분에 computer vision은 상당한 발전을 이루었습니다. 그러나 서로 다른 vision 문제는 일반적으로 서로 다른 models를 필요로 하며, 이는 종종 각 사용 사례에 대해 개별 models를 수동으로 선택하고 구성해야 합니다.
예를 들어, 이미지에 "사람"이 포함되어 있는지 확인할 때 image tagging model을 선택하고 예측된 태그 목록에 "사람"이 포함되어 있는지 확인할 수 있습니다. "사람"이 존재하는 경우 celebrity model을 선택하여 유명인이 등장하는지, 누구인지 추가로 파악할 수 있습니다.
한 가지 연구 방향은 Flamingo, PaLM-E와 같이 vision 및 language modules를 하나의 end-to-end model로 결합하여 최종 사용자에게 dialogue-based 경험을 제공하는 것입니다. 즉, 사용자는 자연어를 사용하여 이미지 콘텐츠를 중심으로 model과 상호 작용할 수 있습니다.
vision module은 vision signals을 language module이 이해할 수 있는 특수 텍스트 토큰 또는 features로 인코딩하여 시스템이 language module을 활용하여 사용자 쿼리를 이해하고 응답을 제공할 수 있도록 합니다.
그러나 이러한 joint finetuning 접근 방식은 특정 기능을 활성화하기 위해 많은 양의 컴퓨팅 리소스와 annotated data를 필요로 합니다. 이 연구에서는 그림 1에 설명된 것처럼 복잡한 visual understanding 문제를 해결하기 위해 기존 개별 vision models를 language model과 보다 유연한 방식으로 결합하는 것을 목표로 합니다.
ChatGPT와 같은 Large language models (LLMs)는 텍스트를 입력 및 출력으로 사용하는 인상적인 dialogue 기능을 보여주었습니다. 최근 NLP 연구 (예: REACT)는 검색 엔진 및 수학 계산기와 같은 외부 NLP tools를 적절한 지침에 따라 LLM과 통합하는 효과를 보여줍니다.
특히 REACT는 LLM이 복잡한 문제를 중간 단계로 분해하는 reasoning texts와 이러한 단계를 해결하기 위한 NLP tools를 할당하는 action texts를 생성하도록 요청합니다.
한 가지 예는 LLM이 최신 인터넷 정보를 가져오기 위해 최신 검색 엔진에 텍스트 쿼리를 제안하고 사전 training corpus에 없는 정보를 사용자에게 반환할 수 있다는 것입니다. LLM 및 NLP tools를 사용한 reasoning 및 acting의 효능에서 영감을 얻아 vision expert tools와 LLM의 통합을 모색합니다.
이를 위해, 수많은 vision experts를 ChatGPT와 결합하여 multimodal reasoning 및 action을 수행하는 시스템 패러다임인 MM-REACT를 제시합니다.
이미지와 비디오를 입력으로 사용하기 위해 파일 경로를 ChatGPT의 입력으로 사용합니다. 파일 경로는 placeholder 역할을 하므로 ChatGPT가 이를 black box로 처리할 수 있습니다. 유명인 이름 또는 box coordinates와 같은 특정 속성이 필요할 때마다 ChatGPT는 특정 vision expert에게 도움을 요청하여 원하는 정보를 식별할 것으로 예상됩니다.
ChatGPT에 vision experts 사용법에 대한 지식을 주입하기 위해 각 expert의 기능, 입력 인수 유형 및 출력 유형에 대한 지침과 각 expert에 대한 몇 가지 in-context 예제를 ChatGPT prompts에 추가합니다. 또한 특수 watchword가 지시되어 regex expression matching을 사용하여 expert를 적절하게 호출할 수 있습니다.
그림 1에서 MM-REACT의 대표적인 visual understanding 기능을 보여줍니다. 예를 들어, MM-REACT는 여러 업로드된 영수증의 정보를 연결하여 총 여행 비용을 계산하고("Multi-Image Reasoning"), "morel mushrooms"에 대한 질문을 인식하고 답변하며("Open-World Concept Understanding"), 긴 비디오를 대표적인 thumbnails로 요약할 수 있습니다("Video Summarization and Event Localization").
이러한 visual intelligence features는 multimodal GPT-4 및 PaLM-E와 같은 최근 models에서 볼 수 있는 features와 유사하지만 추가 multimodal training이 아닌 prompting을 통해 달성됩니다. MM-REACT 시스템은 module 업그레이드에 추가적인 유연성을 제공할 수 있으며, celebrity recognition 및 dense captioning과 같은 기존의 특수 vision experts를 더 잘 활용하여 특정 visual understanding tasks에서 효과적일 수 있습니다.
Related Work
LLMs Prompting Methods. Large language models (LLMs)는 복잡한 문제를 해결 가능한 중간 단계로 분해할 수 있는 강력한 chain-of-thought (CoT) 기능을 보여줍니다. 반면, 연구에 따르면 다양한 외부 NLP tools를 갖춘 LLM은 지식 또는 수학 문제를 해결하기 위해 검색 또는 수학 tools를 사용하는 것과 같이 문제 해결을 위한 tools를 선택하고 활용하는 action planners 역할을 효과적으로 수행할 수 있습니다.
그러나 reasoning을 위한 LLM과 action을 위한 LLM은 독립적으로 사용될 때 문제를 추론을 통해 분해하고 계획된 action을 통해 하위 단계를 해결해야 하는 복잡한 tasks를 해결하지 못합니다. 최근 연구에서는 고급 계획 및 추론이 필요한 복잡한 tasks를 해결하는 LLM의 기능을 향상시키기 위해 action 및 reasoning 단계를 병합하려고 시도했습니다. REACT는 reasoning text 생성을 실행 가능한 action으로 취급하고 NLP tasks를 위한 reasoning 및 action의 시너지 효과적인 조합을 달성하는 대표적인 연구입니다. 이 연구에서는 thought를 모델링하고 vision tools를 실행 가능한 action으로 호출하여 이러한 흥미로운 속성을 multimodal 시나리오로 확장하는 방법을 모색합니다.
Vision+LLMs. MM-REACT는 language models를 확장하여 시각적 입력을 이해하도록 하는 이전 연구와 관련이 있습니다. 대표적인 프레임워크는 language model이 이해할 수 있는 representations로 시각적 입력을 투영하는 vision module을 추가합니다. 이러한 representations는 discrete text words 또는 textual feature space에 투영된 continuous features일 수 있습니다. 최근 vision-language 연구에서는 multimodal 설정에서 chain-of-thought 기능을 탐구합니다. MM-CoT는 ScienceQA 데이터 세트에 annotated된 reasoning chain에 대해 finetuning하여 과학 질문 답변 tasks에서 CoT 기능을 달성합니다. KOSMOS-1 및 PaLM-E는 대규모 training을 통해 zero-shot multimodal CoT 기능을 보여줍니다.
Multimodal Reasoning and Action. MM-REACT와 위에서 논의된 이전 vision+LLM 연구의 주요 차이점은 MM-REACT는 시각적 입력에 conditioned된 텍스트 생성에 LLM을 사용하는 것뿐만 아니라 다양한 vision experts를 할당하기 위해 LLM의 high-level planning 능력을 활용한다는 것입니다.
MM-REACT는 최근 동시 작업인 Visual ChatGPT 및 ViperGPT와 밀접한 관련이 있습니다. 비교하자면, Visual ChatGPT는 주로 이미지 생성 및 편집에 중점을 두는 반면 MM-REACT는 주로 visual understanding에 중점을 둡니다. ViperGPT는 one-round query answering을 위한 Python 코드를 생성하도록 LLM에 지시합니다. 반대로 MM-REACT는 강력한 QA model을 vision experts 중 하나로 통합할 수 있는 multi-round, dialogue-based 시스템입니다.
MM-REACT Prompting
MM-REACT의 목표는 수많은 vision experts를 구성하여 ChatGPT에 visual understanding 기능을 부여하는 것입니다. vision expert는 이미지를 입력으로 받아 다양한 관점에서 콘텐츠를 해석하는 computer vision model입니다. 예를 들어, image captioning expert는 자연어 설명을 생성하고, OCR expert는 이미지에서 scene text를 추출하며, celebrity recognition model은 유명인 이름을 식별하고, object detection model은 bounding box 위치와 함께 salient object를 추출합니다. 현재는 특정 사용 사례에 대해 어떤 vision experts를 사용할지 수동으로 결정하고 수동으로 구성해야 할 수도 있습니다. 대신, 자연어로 된 사용자 쿼리의 요구 사항을 기반으로 이 프로세스를 자동화하는 것이 목표입니다.
ChatGPT는 visual understanding 없이 텍스트를 입력 및 출력으로 사용하는 인공지능 챗봇입니다. 그러나 ChatGPT는 강력한 instruct learning 기능을 보여주므로 어떤 vision expert를 호출해야 하고 어떤 이미지를 처리해야 하는지 ChatGPT가 올바르게 결정하도록 지시할 수 있습니다.
그림 2는 MM-REACT 시스템의 흐름도를 보여줍니다. thought 및 action request라는 용어는 ChatGPT가 문제를 분해하거나 vision experts를 호출하기 위해 생성하는 reasoning 및 action-oriented 텍스트를 나타냅니다. Observation은 action request text에서 요청된 action 실행 후 vision expert의 응답을 나타냅니다. 다음으로 흐름도의 각 단계를 자세히 설명합니다.
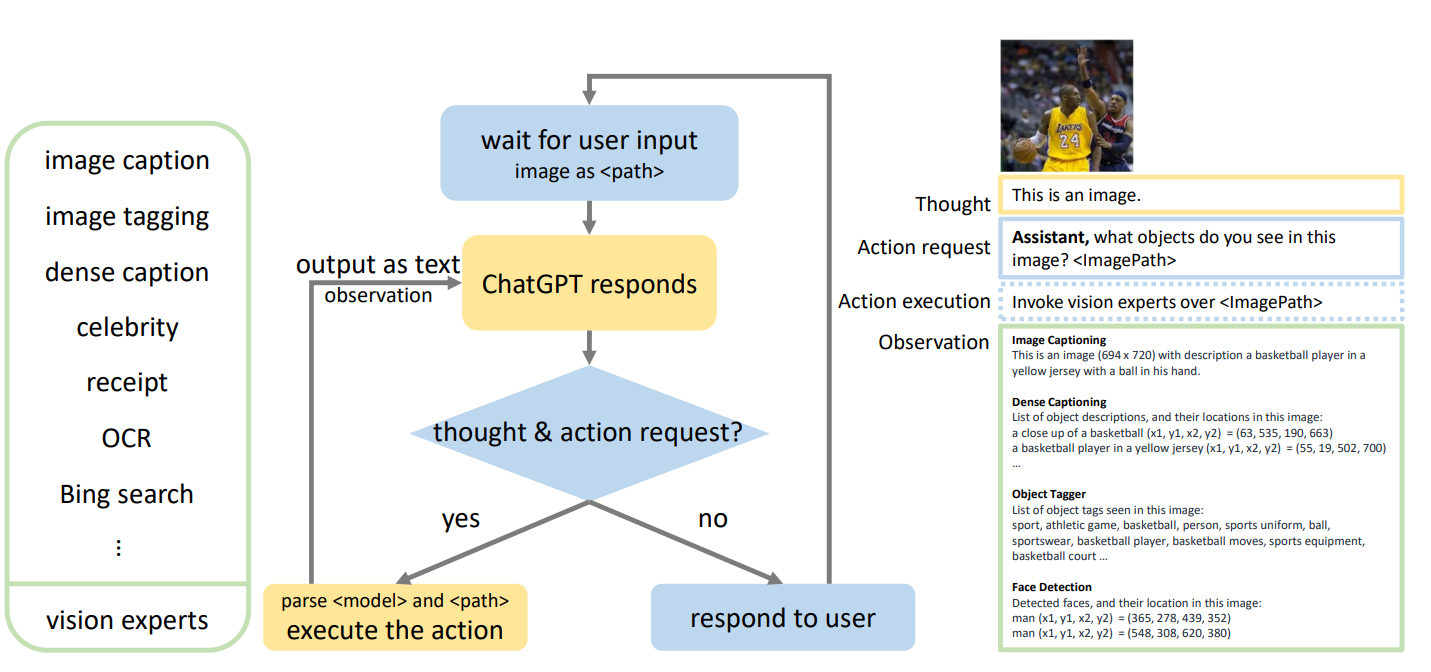
그림 2. ChatGPT를 통한 향상된 visual understanding을 위한 MM-REACT의 흐름도. 사용자 입력은 텍스트, 이미지 또는 비디오 형식일 수 있으며, 후자 두 개는 파일 경로 문자열로 표시됩니다. ChatGPT는 vision expert가 시각적 입력을 해석해야 하는 경우 action request에 특정 watchword를 말하도록 지시됩니다. Regular expression matching을 적용하여 expert의 이름과 파일 경로를 구문 분석하고, 이를 사용하여 vision expert를 호출합니다(action execution). expert의 출력(observation)은 텍스트로 직렬화되어 history와 결합되어 ChatGPT를 추가로 활성화합니다. 추가 experts가 필요하지 않은 경우 MM-REACT는 최종 응답을 사용자에게 반환합니다. 오른쪽 그림은 single-round vision expert execution을 보여주며, 이는 그림 3에 설명된 전체 실행 흐름을 구성하는 구성 요소입니다.
3.1. User Input
ChatGPT는 텍스트만 입력으로 받아들이기 때문에 첫 번째 과제는 여러 이미지 및 비디오와 같은 텍스트가 아닌 입력을 어떻게 수용할 것인가입니다. 대부분의 vision experts는 파일 경로 또는 URL을 받아들이므로 경로 문자열을 사용하여 텍스트가 아닌 입력을 나타냅니다. 파일 경로 자체는 의미가 없으며 본질적으로 placeholder입니다. 파일 경로로 직접 visual recognition task를 수행할 수는 없지만 ChatGPT는 감지된 사람의 유명인 이름을 식별하는 등 다양한 관점에서 이미지 콘텐츠를 이해하기 위해 여러 vision experts의 도움을 받을 수 있습니다. 제공된 파일 경로를 텍스트 출력에 포함함으로써 ChatGPT는 vision expert가 어떤 이미지를 처리해야 하는지 나타낼 수 있습니다.
3.2. ChatGPT Response
사용자의 입력이 주어지면 ChatGPT는 두 가지 종류의 응답을 제공할 것으로 예상됩니다.
첫 번째는 vision experts의 도움을 받는 것이고,
두 번째는 사용자에게 직접 응답하는 것입니다.
핵심 과제는 언제 vision expert를 호출해야 하는지 알 수 있도록 프로토콜을 설정하는 것입니다. REACT에서 영감을 얻아 특정 vision expert가 필요한 경우 "Assistant, 이미지에 어떤 objects가 있나요?"와 같은 특정 watchword로 응답하도록 ChatGPT에 지시합니다. 구현에서는 "Assistant"라는 키워드를 사용하여 vision expert가 필요한지 여부를 구분합니다.
성능을 더욱 향상시키기 위해 외부 tool이 필요한 이유를 강조하는 thought (reasoning) 프로세스를 ChatGPT가 보여주도록 권장합니다. 또한 이러한 reasoning을 통합하는 것이 NLP 연구에서 유익한 것으로 나타났습니다.
3.3. Vision Experts
ChatGPT의 action request가 주어지면, regular expression matching을 사용하여 expert 이름과 파일 경로를 구문 분석하고 action (vision expert execution)을 호출합니다.
expert의 출력은 다양한 형식일 수 있지만 ChatGPT가 이해할 수 있도록 텍스트 형식으로 표준화됩니다. captioning model 또는 celebrity model과 같은 특정 experts의 경우 출력을 텍스트로 나타내는 것은 간단합니다. 그러나 다른 experts의 경우 표준화가 덜 직관적입니다. 예를 들어, detection model은 bounding box 위치가 있는 object 이름 목록을 출력합니다. 이 경우 모든 상자를 연결하며, 각 상자는 (x1, y1), (x2, y2)가 각각 왼쪽 상단 및 오른쪽 하단 모서리의 좌표인 <x1>, <y1>, <x2>, <y2>로 표시됩니다. 마지막 네 개의 숫자 값의 의미를 설명하는 추가 텍스트 설명이 추가됩니다. 어떤 경우에는 ChatGPT가 이러한 좌표를 이해할 수 있다는 것을 알 수 있습니다(예: 어떤 object가 왼쪽에 있는지 식별).
vision experts의 텍스트 형식 출력은 ChatGPT가 vision expert를 호출하는 action의 결과로 발생하는 observation으로 해석될 수 있습니다. observations를 chat history와 결합하면 ChatGPT는 추가 experts를 호출하거나 최종 답변을 사용자에게 반환할 수 있습니다. 4.2절 및 그림 3에서 전체 실행 흐름의 예를 제공합니다.
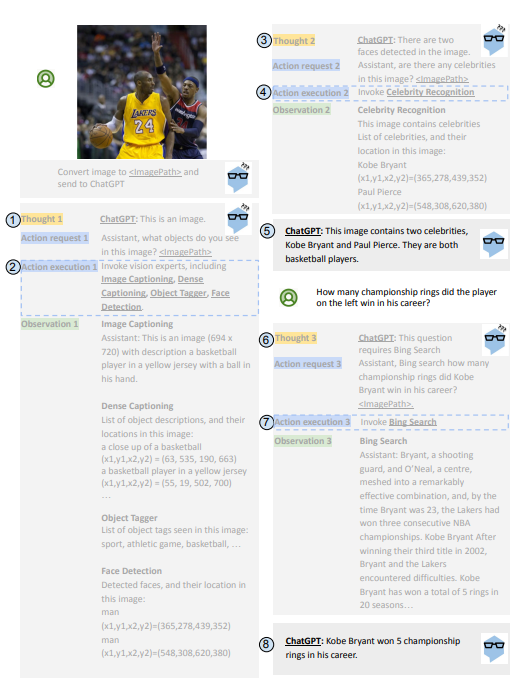
그림 3. MM-REACT의 전체 실행 흐름 예시.
번호가 매겨진 인덱스가 있는 파란색 원은 서로 다른 models가 호출되는 순서(즉, executions)를 나타냅니다. 굵은 밑줄로 강조 표시된 executions는 ChatGPT 호출(예: "ChatGPT:") 또는 하나 이상의 선택된 vision experts 실행(예: "Image Captioning")일 수 있습니다.
expert execution을 이해하는 데 도움이 되는 commentary text action execution을 dashed boxes에 추가했습니다. 각 ChatGPT execution은 이전 텍스트를 입력으로 사용하고 다음 execution까지 이어지는 텍스트를 생성합니다(예: Execution 1의 경우 "This is an image. Assistant, what . . . image?"). 회색 텍스트는 MM-REACT의 thoughts 또는 vision experts의 actions 및 outputs를 나타내며 사용자에게는 보이지 않습니다. 이 multimodal reasoning 및 action 프로세스는 behind the scene에서 발생하여 사용자에게 최종 응답을 생성하는 데 필요한 정보를 수집하며, 이는 검은색으로 표시됩니다.
다양한 vision experts 사용법에 대한 지식을 주입하기 위해 ChatGPT를 prompting할 때 prefix에 지침과 in-context 예제를 모두 추가합니다. 각 expert는 model 이름, 기능에 대한 일반적인 설명, 입력 데이터 형식 및 출력 정보로 설명됩니다. 각 expert를 설명한 후 몇 가지 in-context 대화 예제를 추가하여 성능을 향상시킵니다. 주입된 지식을 통해 ChatGPT는 하나 이상의 vision experts를 효과적으로 선택하여 다양한 관점에서 이미지 또는 비디오를 이해할 수 있습니다.
3.4. Extensibility
우리의 체계는 NLP 분야에서 다양한 tools를 호출하는 REACT에서 동기를 얻었습니다. 텍스트만 포함되므로 다른 modalities를 통합하기 위한 특별한 설계가 필요하지 않습니다.
이 작업에서는 MM-REACT를 vision domain으로 확장합니다. 핵심은 텍스트가 아닌 modality를 경로 문자열로 대체하여 ChatGPT가 특정 vision experts에게 시각적 콘텐츠를 인식하도록 요청할 수 있도록 하는 것입니다.
따라서 MM-REACT를 음성 및 오디오와 같은 다른 modalities로 더 확장할 수 있습니다. 한편, 출력을 텍스트 형식으로 formatting하여 더 많은 tools를 쉽게 통합할 수도 있습니다.
ChatGPT는 기본 구현에서 기본 LLM 역할을 하지만 4.5절에서 설명하는 GPT-4와 같은 더 강력한 LLM으로 간단하게 업그레이드하여 성능을 더욱 향상시킬 수 있습니다.
Experiments
4.1. Experiment Setup
MM-REACT를 LangChain codebase를 기반으로 구현하고 ReAct의 아이디어를 참조했습니다.
Azure "gpt-3.5-turbo" API를 통해 ChatGPT에 액세스하며, 이 API는 토큰 길이 제한이 4,096입니다. 또한 Azure Cognitive Services API를 통해 공개적으로 사용 가능한 vision experts를 활용합니다.
여기에는 image captioning, image tagging, dense captioning, optical character recognition (OCR) 및 celebrities, receipts 등에 대한 specialized recognition models가 포함됩니다. spatial understanding 및 image editing을 위한 customized tools와 Bing search 및 PAL math와 같은 다른 modalities의 tools를 사용하여 toolset을 더욱 확장합니다.
4.2. MM-REACT’s Full Execution Flow
그림 3은 MM-REACT의 전체 실행 흐름을 보여주는 예시를 제공합니다. 번호가 매겨진 파란색 원으로 서로 다른 models를 호출하는 정확한 순서(즉, executions)를 강조 표시합니다. 굵은 밑줄로 강조 표시된 executions는 ChatGPT 호출(예: "ChatGPT:") 또는 하나 이상의 선택된 vision experts의 실행(예: "Image Captioning")일 수 있습니다. vision expert execution을 이해하는 데 도움이 되는 commentary text action execution을 dashed boxes에 추가했습니다.
action execution은 MM-REACT 흐름에서 실제 입력 또는 출력이 아닙니다. ChatGPT executions는 vision experts를 할당하는 thought (reasoning) 및 action texts를 생성하거나(사용자에게 보이지 않음) 사용자에게 최종 응답을 생성하는 데 사용될 수 있습니다.
각 ChatGPT execution은 이전 텍스트를 입력으로 사용하고 다음 execution까지 이어지는 텍스트를 생성합니다(예: Execution 1의 경우 "This is an image. Assistant, what objects do you see in this image?"). ChatGPT는 3.3절에 자세히 설명된 대로 prompt prefix의 지침 및 in-context 예제를 기반으로 생성할 적절한 텍스트를 "학습"합니다. reasoning 및 execution 절차에 대한 추가 예시는 그림 18-22에 나와 있습니다.
4.3. MM-REACT Capabilities and Applications
그림 4-14는 MM-REACT가 보여주는 대표적인 기능 및 응용 시나리오를 보여줍니다.
구체적으로, visual math 및 text reasoning(그림 4), visual-conditioned jokes 및 memes 이해(그림 5), spatial 및 coordinate understanding, visual planning 및 prediction(그림 6), multi-image reasoning(그림 7), bar charts(그림 8), floorplans(그림 9), flowcharts(그림 10), tables(그림 11)에 대한 multi-hop document understanding, open-world concept understanding(그림 12) 및 video analysis 및 summarization(그림 13, 14)에서 MM-REACT의 기능을 검토합니다. 그림 18에서 unfolded steps의 예시를 제공합니다.
4.4. Capability Comparison with PaLM-E
MM-REACT는 기존 vision experts를 ChatGPT와 결합하는 training-free 체계인 반면, PaLM-E는 image encoder와 text decoder를 전용 데이터 세트와 결합하는 vision-language model을 training합니다. 그림 15-17은 MM-REACT가 PaLM-E에 필적하는 결과를 얻을 수 있음을 보여줍니다. 그림 21, 22에서 완전한 multimodal reasoning 및 action 절차를 추가로 설명합니다.
4.5. MM-REACT Extensibility
그림 23 및 24에서 MM-REACT의 LLM을 ChatGPT("gpt-3.5-turbo")에서 GPT-4(language-only)로 향상시키는 것을 살펴봅니다. ChatGPT 웹 사이트를 통해 language-only GPT-4에 액세스하고 비교를 위해 OpenAI에서 제공하는 multimodal GPT-4 데모를 참조합니다. 이러한 예시는 MM-REACT의 확장성의 이점을 보여줍니다. GPT-4가 장착된 MM-REACT는 물리 질문에 정확하게 답변하는 반면(그림 23), ChatGPT(GPT-3.5)가 있는 버전은 실패합니다. 또한 MM-REACT는 training 없이 새로운 tools를 통합할 수 있는 유연성을 갖도록 설계되었습니다. 그림 25는 multi-round, dialogue-based 이미지 편집을 위해 X-decoder의 image editing tool을 연결하는 사례 연구를 제공합니다.
4.6. Limitations
다음과 같은 한계를 확인했습니다.
1). 실제 환경에서의 인식 기능을 고려할 때 annotated benchmarks가 부족하여 구체적인 정확도 수치로 성능을 체계적으로 평가하기 어렵습니다. 따라서 이러한 시스템의 성능을 효과적으로 평가하는 방법에 대한 노력을 기울일 가치가 있습니다.
2). vision 기능은 통합된 vision experts에 의해 제한됩니다. 한편으로는 통합된 experts가 실수를 할 수 있고, 다른 한편으로는 필요한 experts가 없으면 시스템이 실패할 수 있습니다.
3). vision experts의 지식을 prefix에 주입하므로 experts의 수는 ChatGPT의 context window(4096 tokens)에 의해 제한됩니다.
4). 시각적 신호는 ChatGPT가 이해할 수 있도록 텍스트 단어로 변환되며, 이는 특정 vision tasks에 대한 최적의 솔루션이 아닐 수 있습니다.
5). MM-REACT에는 수동 prompt engineering이 필요합니다. 연구 작업을 통해 이 프로세스를 자동화하여 시스템 개발을 더욱 쉽게 만들 수 있기를 기대합니다.
Conclusion
복잡한 visual understanding 문제를 해결하기 위해 multimodal reasoning 및 action을 시너지 효과적으로 활용하는 시스템 패러다임인 MM-REACT를 제시했습니다. MM-REACT는 LLM에 다수의 vision experts를 활용할 수 있는 간단하고 유연한 방법을 제시합니다. 광범위한 zero-shot 실험을 통해 MM-REACT가 multi-image reasoning, multi-hop document understanding, open-world concept understanding, video summarization 등과 같은 광범위한 challenging understanding tasks를 해결하는 능력을 입증했습니다.



