

AI바라기의 인공지능
agent : 논문리뷰 : CogAgent: A Visual Language Model for GUI Agents 본문
Purpose of the Paper
- 기존 모델의 한계
기존의 Large Language Models (LLMs)은 HTML과 같은 텍스트 기반 입력을 처리하여 GUI와 상호작용하는 데 중점을 두었으나, GUI 특유의 시각적 요소(아이콘, 텍스트, 공간적 배열 등)를 효과적으로 이해하지 못했습니다. 특히, 고해상도 이미지를 효율적으로 처리하지 못해 작은 요소를 정확히 식별하기 어렵고, GUI 특화된 데이터셋이 부족하여 실제 환경에서의 일반화 성능이 제한적이었습니다. - 논문의 특별한 목적
본 논문은 GUI의 시각적 신호를 직접 이해하고 조작할 수 있는 Visual Language Model(VLM) 기반 GUI 에이전트인 CogAgent를 제안합니다. 특히, 고해상도 입력 처리를 효율화하며, GUI 특화 데이터셋(CCS400K)을 구축하여 GUI 상호작용 능력을 대폭 향상시키는 것을 목표로 합니다.
Key Contributions
- 고해상도 크로스 모듈 설계
- GUI 이미지의 고해상도 요소(텍스트, 작은 아이콘 등)를 효과적으로 처리하기 위해 고해상도 크로스 모듈을 설계.
- 기존 모델 대비 계산 비용(FLOPs)을 크게 줄이면서도 높은 성능을 유지.
- GUI 데이터셋 구축 및 활용
- GUI 환경에서의 학습을 위해 CCS400K 데이터셋을 구축.
- 스크린샷, DOM 요소, 위치 정보 등을 포함하여 GUI 관련 태스크의 일반화 능력을 강화.
- 범용 및 GUI 특화 성능 개선
- Text-VQA, DocVQA와 같은 VQA 태스크에서 SOTA 성능을 달성.
- Mind2Web, AITW와 같은 GUI 태스크에서 기존 LLM 기반 접근법을 능가하는 결과를 보임.
- 효율성 강화
- 고해상도 입력에도 기존 대비 최소 2배 이상의 계산 효율성을 확보.
Novelty
- 고해상도와 저해상도 통합 구조
- 저해상도와 고해상도 입력을 병렬 처리하는 크로스 모듈을 설계하여, 텍스트와 이미지를 동시 처리하면서도 계산 비용을 줄임.
- 특히, 1120×1120 해상도를 효과적으로 처리할 수 있는 경량화된 고해상도 인코더 도입.
- GUI 중심 데이터셋 설계
- 기존 자연 이미지 중심의 데이터셋과 달리, GUI 특화된 이미지와 DOM 정보를 활용한 다양하고 현실적인 데이터셋(CCS400K) 제공.
- GUI 전문 에이전트로의 확장 가능성
- GUI 환경에서의 자동화 태스크 수행(웹 탐색, 파일 관리 등)에 대한 최초의 VLM 기반 성공적인 접근.
Experimental Highlights
- VQA 벤치마크 성능
- Text-VQA: 기존 SOTA 대비 +4.7점 향상.
- DocVQA: 기존 SOTA 대비 +1.6점 향상.
- MM-Vet 및 POPE 데이터셋에서 대화형 QA와 객체 환각 문제에서 탁월한 성능.
- GUI 태스크 성능
- Mind2Web: 기존 LLM 기반 모델 대비 cross-domain, cross-task에서 평균 10% 이상의 성능 향상.
- AITW: 스마트폰 GUI 환경에서 기존 Auto-UI보다 2.61% 높은 정확도 달성.
- 효율적인 고해상도 처리
- 기존 CogVLM 대비 FLOPs를 50% 이상 절감하면서도 동일한 입력 해상도에서 더 나은 성능 제공.
Limitations
- 좌표 추정 정확성
- 일부 경우, GUI 상의 요소 좌표 추정에서 미세한 오차 발생.
- 멀티 이미지 처리 제약
- 단일 이미지만 처리 가능하며, 복잡한 멀티 이미지 작업에는 한계 존재.
- 텍스트-이미지 통합 성능 개선 필요
- 텍스트와 이미지를 통합적으로 처리하는 능력이 일부 태스크에서 제한적.
Future Work
- 멀티 이미지 처리 지원
- 여러 이미지를 동시에 처리할 수 있는 구조 확장.
- GUI 데이터셋 확장
- 다양한 GUI 환경(예: 비표준 웹페이지, 복잡한 스마트폰 UI 등)을 포함하는 데이터셋 구축.
- 실제 사용 사례로의 확대
- GUI 환경 외에 더 다양한 응용 분야(예: VR/AR 인터페이스)로 확장 연구.
Abstract
사람들은 컴퓨터 또는 스마트폰 화면과 같은 GUI (Graphical User Interface)를 통해 디지털 기기에 엄청난 시간을 소비하고 있습니다. ChatGPT와 같은 LLM (Large Language Model)은 이메일 작성과 같은 작업에서 사람들을 도울 수 있지만, GUI를 이해하고 상호 작용하는 데 어려움을 겪어 자동화 수준을 높이는 데 한계가 있습니다.
본 논문에서는 GUI 이해 및 탐색을 전문으로 하는 180억 개의 매개변수를 가진 VLM (Visual Language Model)인 CogAgent를 소개합니다. CogAgent는 저해상도 및 고해상도 이미지 인코더를 모두 활용하여 1120×1120 해상도의 입력을 지원하여 작은 페이지 요소와 텍스트까지 인식할 수 있습니다.
일반적인 vision-language model인 CogAgent는 VQAv2, OK-VQA, Text-VQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, POPE를 포함한 5개의 텍스트가 풍부한 VQA 벤치마크와 4개의 일반 VQA 벤치마크에서 state-of-the-art를 달성했습니다. CogAgent는 스크린샷만 입력으로 사용하여 PC 및 Android GUI 탐색 작업인 Mind2Web 및 AITW에서 HTML 텍스트를 추출하여 사용하는 LLM 기반 방법보다 성능이 뛰어나 state-of-the-art를 발전시킵니다.
1. Introduction
디지털 세계의 자율 에이전트는 많은 현대인들이 꿈꾸는 이상적인 비서입니다. 다음과 같은 시나리오를 상상해 보세요. 작업 설명을 입력한 다음, 편안하게 커피를 마시면서 온라인으로 티켓 예약, 웹 검색, 파일 관리, PowerPoint 프레젠테이션 생성과 같은 작업이 자동으로 완료되는 것을 지켜봅니다.
최근 LLM (Large Language Model) 기반 에이전트의 등장으로 이러한 꿈에 더 가까워지고 있습니다. 예를 들어, 150,000개의 스타를 보유한 오픈 소스 프로젝트인 AutoGPT는 ChatGPT를 활용하여 언어 이해를 Google 검색 및 로컬 파일 작업과 같은 사전 정의된 작업과 통합합니다. 연구자들은 또한 에이전트 지향적인 LLM을 개발하기 시작했습니다. 그러나 순수하게 언어 기반 에이전트의 잠재력은 실제 시나리오에서 상당히 제한적입니다. 대부분의 애플리케이션은 다음과 같은 관점에서 GUI (Graphical User Interface)를 통해 인간과 상호 작용하기 때문입니다.
- 상호 작용을 위한 표준 API가 종종 부족합니다.
- 아이콘, 이미지, 다이어그램 및 공간 관계를 포함한 중요한 정보를 단어로 직접 전달하기 어렵습니다.
- 웹 페이지와 같은 텍스트 렌더링 GUI에서도 캔버스 및 iframe과 같은 요소는 HTML을 통해 기능을 파악하기 위해 구문 분석할 수 없습니다.
VLM (Visual Language Model) 기반 에이전트는 이러한 한계를 극복할 수 있는 잠재력이 있습니다. HTML 또는 OCR 결과와 같은 텍스트 입력에만 의존하는 대신 VLM 기반 에이전트는 시각적 GUI 신호를 직접 인식합니다. GUI는 인간 사용자를 위해 설계되었기 때문에 VLM 기반 에이전트는 VLM이 인간 수준의 시각적 이해와 일치하는 한 인간만큼 효과적으로 수행할 수 있습니다. 또한 VLM은 일반적으로 대부분의 인간 사용자의 능력을 벗어나는 매우 빠른 읽기 및 프로그래밍과 같은 기술도 가능하여 VLM 기반 에이전트의 잠재력을 확장합니다. 몇 가지 이전 연구에서는 특정 시나리오에서 시각적 특징을 단순히 보조 수단으로 활용했습니다. 예를 들어, 주로 객체 인식 목적으로 시각적 특징을 사용하는 WebShop이 있습니다. VLM의 급속한 발전으로 시각적 입력에만 의존하여 GUI에서 자연스럽게 보편성을 달성할 수 있을까요?
이 연구에서 우리는 일반적인 cross-modality 작업에 대한 강력한 능력을 유지하면서 GUI 이해 및 계획을 전문으로 하는 visual language foundation model인 CogAgent를 제시합니다. 최근 오픈 소스 VLM인 CogVLM을 기반으로 구축된 CogAgent는 GUI 에이전트를 구축하기 위한 다음과 같은 과제를 해결합니다.
- Training Data. 현재 대부분의 VLM은 웹의 자연 이미지로 구성된 LAION과 같은 데이터 세트에서 pre-trained됩니다. 그러나 GUI 이미지는 자연 이미지와 다른 분포를 공유한다는 것을 알았습니다. 따라서 지속적인 pre-training을 위해 GUI 및 OCR에 대한 대규모 주석 데이터 세트를 구축합니다.
- High-Resolution vs. Compute. GUI에서 작은 아이콘과 텍스트는 어디에나 있으며 일반적으로 사용되는 224 × 224 해상도에서는 인식하기 어렵습니다. 그러나 입력 이미지의 해상도를 높이면 language model에서 시퀀스 길이가 상당히 길어집니다. 예를 들어, 패치 크기가 14인 경우 1120 × 1120 이미지는 6400 토큰의 시퀀스에 해당하므로 과도한 training 및 inference compute가 필요합니다. 이를 해결하기 위해 적절한 계산 예산 내에서 해상도와 hidden size 간의 trade-off를 허용하는 cross-attention branch를 설계합니다. 특히, CogVLM에서 사용되는 원래의 큰 ViT (4.4B 매개변수)와 새로운 작은 고해상도 cross-module (0.30B 매개변수의 이미지 인코더 포함)을 결합하여 시각적 특징을 공동으로 모델링할 것을 제안합니다.
우리의 실험은 다음을 보여줍니다.
- CogAgent는 AITW 및 Mind2Web을 포함한 인기 있는 GUI 이해 및 의사 결정 벤치마크에서 1위를 차지했습니다. 우리가 아는 한, 일반적인 VLM이 추출된 구조화된 텍스트를 사용하는 LLM 기반 방법보다 성능이 뛰어난 것은 이번이 처음입니다.
- CogAgent는 GUI에 중점을 두지만 VQAv2, OK-VQA, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet 및 POPE를 포함한 9개의 visual question-answering 벤치마크에서 state-of-the-art 일반 성능을 달성합니다.
- CogAgent에서 고해상도 및 저해상도 branch를 분리하여 설계하면 고해상도 이미지를 소비하는 데 드는 계산 비용이 크게 절감됩니다. 예를 들어 1120 × 1120 입력을 사용하는 CogAgent-18B의 FLOPs (floating-point operations) 수는 기본 490 × 490 입력을 사용하는 CogVLM-17B의 FLOPs 수의 절반 미만입니다.
2. 방법
이 섹션에서는 먼저 CogAgent의 아키텍처, 특히 새로운 고해상도 교차 모듈을 소개한 다음 pre-training 및 정렬 프로세스를 자세히 설명합니다.
2.1. 아키텍처
CogAgent의 아키텍처는 그림 2에 나와 있습니다.
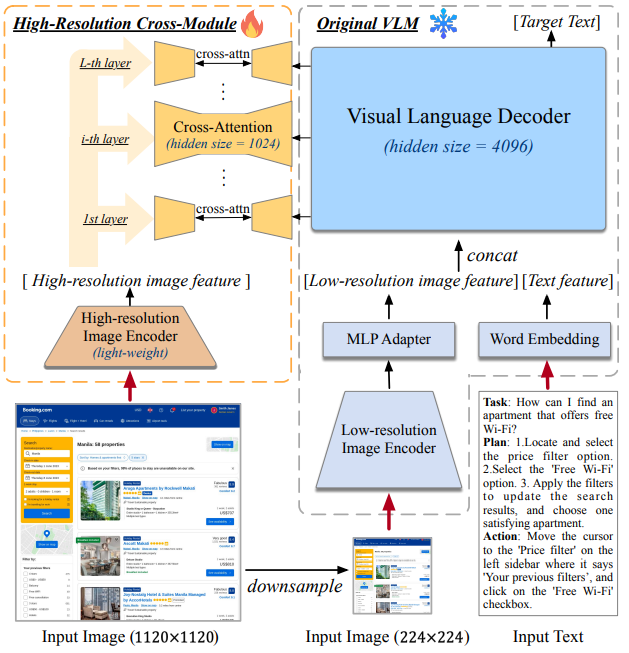
pre-trained된 VLM (이미지 오른쪽)을 기반으로 모델을 구축하고 고해상도 입력 (이미지 왼쪽)을 처리하기 위해 cross-attention 모듈을 추가할 것을 제안합니다. 기본 VLM으로 오픈 소스이며 최첨단 large vision-language model인 CogVLM17B를 선택합니다. 특히, 저해상도 이미지 (224×224 픽셀)의 인코더로 EVA2-CLIPE를 사용하고, 출력을 visual-language 디코더의 feature 공간에 매핑하는 MLP 어댑터를 보완합니다. pre-trained된 language model인 디코더는 시각적 및 언어적 feature의 심층 융합을 용이하게 하기 위해 Wang et al.이 도입한 visual expert 모듈로 향상되었습니다. 디코더는 저해상도 이미지 feature 시퀀스와 텍스트 feature 시퀀스의 결합된 입력을 처리하고 autoregressively 대상 텍스트를 출력합니다.
대부분의 VLM과 마찬가지로 원래 CogVLM은 컴퓨터 또는 스마트폰의 화면 해상도가 일반적으로 720p (1280 × 720 픽셀) 이상인 GUI의 요구 사항을 거의 충족하지 못하는 비교적 낮은 해상도 (224 또는 490)의 이미지만 수용할 수 있습니다. 이는 VLM 사이에서 흔히 발생하는 문제입니다. 예를 들어 LLaVA 및 PALI-X는 일반 도메인에서 224 × 224의 낮은 해상도로 pre-trained됩니다. 주된 이유는 고해상도 이미지가 엄청난 시간 및 메모리 오버헤드를 발생시키기 때문입니다. VLM은 일반적으로 텍스트와 이미지 feature 시퀀스를 디코더에 대한 입력으로 연결하므로 self-attention 모듈의 오버헤드는 시각적 토큰 (패치) 수에 따라 2차적이며 이미지의 측면 길이에 따라 2차적입니다. 고해상도 이미지의 비용을 절감하기 위한 몇 가지 초기 시도가 있습니다. 예를 들어, Qwen-VL은 이미지 feature를 압축하기 위해 position-aware vision-language 어댑터를 제안하지만 시퀀스 길이를 4분의 1로만 줄이고 최대 해상도는 448 × 448입니다. Kosmos-2.5는 이미지 시퀀스의 길이를 줄이기 위해 Perceiver Resampler 모듈을 채택합니다. 그러나 resampled된 시퀀스는 여전히 large visual-language 디코더 (2,048 토큰)에서 self-attention에 대해 길고 제한된 텍스트 인식 작업에만 적용할 수 있습니다.
따라서 고해상도에서 이해도를 높이기 위해 기존 구조를 효과적으로 보완하는 새로운 고해상도 교차 모듈을 제안합니다. 이 모듈은 고해상도 이미지에 직면하여 효율성을 유지할 뿐만 아니라 다양한 visual-language model 아키텍처에 유연하게 적응할 수 있습니다.
2.2. 고해상도 교차 모듈
고해상도 교차 모듈의 구조적 설계는 주로 다음과 같은 관찰을 기반으로 합니다.
- 224 × 224와 같은 적당한 해상도에서 이미지는 대부분의 객체와 레이아웃을 효과적으로 묘사할 수 있지만 해상도는 텍스트를 명확하게 렌더링하는 데 부족합니다. 따라서 새로운 고해상도 모듈은 GUI를 이해하는 데 중요한 텍스트 관련 feature를 강조해야 합니다.
- 일반 도메인의 pre-trained된 VLM은 종종 큰 hidden size (예: PALI-X 및 CogVLM에서 4,096, LLaVA에서 5,120)가 필요하지만 문서 OCR과 같은 텍스트 중심 작업을 위해 맞춤화된 VLM은 만족스러운 성능을 달성하기 위해 더 작은 hidden size가 필요합니다 (예: Kosmos-2.5 및 Pix2Struct에서 1,536). 이는 텍스트 관련 feature를 더 작은 hidden size를 사용하여 효과적으로 캡처할 수 있음을 시사합니다.
그림 2와 같이 고해상도 교차 모듈은 고해상도 입력을 위한 새로운 branch 역할을 하며 구현 시 1120 × 1120 픽셀 크기의 이미지를 허용합니다. 원래 저해상도 입력 branch와 달리 고해상도 교차 모듈은 훨씬 더 작은 pre-trained된 vision 인코더 (구현 시 EVA2-CLIP-L의 visual 인코더, 0.30B 매개변수)를 채택하고 작은 hidden size의 cross-attention을 사용하여 고해상도 이미지 feature를 VLLM 디코더의 모든 레이어와 융합하여 계산 비용을 절감합니다. 구체적으로 말하자면, 입력 이미지의 경우 1120 × 1120 및 224×224로 크기가 조정되고 각각 고해상도 교차 모듈과 저해상도 branch에 공급된 다음 두 개의 크기가 다른 이미지 인코더로 이미지 feature 시퀀스 Xhi 및 Xlo로 인코딩됩니다. 병렬로. visual language 디코더는 원래 계산을 유지하지만 유일한 변경 사항은 모든 디코더 레이어에서 Xhi와 hidden state 간의 cross-attention을 통합하는 것입니다.
공식적으로 디코더에서 i번째 attention 레이어의 입력 hidden state가 Xini ∈ R B×(LIlo+LT )×Ddec이고 교차 모듈의 이미지 인코더의 출력 hidden state가 Xhi ∈ R B×(LIhi )×Dhi라고 가정합니다. 여기서 B는 배치 크기이고 LIlo, LIhi 및 LT는 저해상도 이미지, 고해상도 이미지 및 텍스트 시퀀스의 길이이며 Ddec 및 Dhi는 각각 디코더와 고해상도 인코더 출력의 hidden size입니다. 각 레이어의 attention 절차는 다음과 같이 공식화할 수 있습니다.
X′
i = MSA(LN(Xini )), (1)
Xouti = LN(X′
i ) + MCA(LN(X′
i ), Ki
cross , Vi
cross ). (2)
여기서 MSA와 MCA는 visual expert를 사용한 multi-head self-attention과 multi-head cross-attention을 나타내고 X′ i와 Xouti i는 residual connection이 있는 각각의 출력 feature를 나타냅니다. 그들 사이에 cross-attention을 구현하기 위해 학습 가능한 변환 행렬 Wi Kcross , Wi Vcross ∈ R Dhi×Dcross 를 추가하여 Ki cross = XhiWi Kcross , V i cross = XhiWi Vcross ∈ R LIhi×Dcross 를 얻고 Wi Qcross ∈ R Ddec×Dcross 를 추가하여 Qi cross = X′ iWi Qcross ∈ R (LIlo+LT )×Dcross 를 얻습니다. 모든 디코더 레이어에서. Eq. 2의 residual connection을 사용하면 고해상도 이미지가 있는 cross-attention을 저해상도 이미지 feature의 보완으로 인식할 수 있으므로 이전의 pre-trained된 모델을 저해상도에서 효과적으로 활용할 수 있습니다.
계산 복잡성. cross-attention과 self-attention에서 attention head의 수를 Hcross와 Hdec라고 하고 각 head의 차원을 dcross = Dcross/Hcross와 ddec = Ddec/Hdec라고 합니다. 고해상도 교차 모듈을 사용하는 경우 attention의 계산 복잡성은 다음과 같습니다.
O(B(LIlo + LT )Ddec(Ddec + Dcross)Hdec
+ B(LIlo + LT )Dcross(LIhi + LIlo + LT )Hcross). (3)
dcross와 Hcross는 계산 예산과 모델 성능에 따라 유연하게 조정할 수 있습니다. 고해상도 교차 모듈을 활용하지 않고 저해상도 이미지를 고해상도 이미지로 직접 대체하는 경우 계산 복잡성은 다음과 같습니다.
O(B(LIhi + LT )Ddec(Ddec + Ddec)Hdec). (4)
구현 시 dcross = 32, Hcross = 32이고 CogVLM-17B에서 ddec = 128, Hdec = 32를 상속합니다. 고해상도 및 저해상도 인코더는 모두 14 × 14픽셀 패치로 이미지를 패치화하므로 LIhi = 6400, LIlo = 256입니다. 우리의 방법은 최소한 LIhi+LT LIlo+LT = 6400+LT 256+LT × 가속으로 이어집니다. 이는 엄격한 하한이며 동시에 메모리 오버헤드를 줄입니다. (자세한 내용은 부록 참조)
2.3. Pre-training
고해상도 이미지를 이해하고 GUI 애플리케이션 시나리오에 맞게 모델의 기능을 향상시키기 위해 pre-training 노력은 다음과 같은 측면에 중점을 둡니다. 고해상도 이미지에서 다양한 크기, 방향 및 글꼴의 텍스트를 인식하는 기능, 이미지에서 텍스트와 객체를 접지하는 기능, 웹 페이지와 같은 GUI 이미지에 대한 전문적인 이해 기능. 위에서 언급한 측면을 기반으로 pre-train 데이터를 세 부분으로 나누고 부록에 샘플을 제공합니다. 모든 pre-training 데이터는 공개적으로 사용 가능한 데이터 세트에서 파생됩니다. 구성 방법은 아래에 자세히 설명되어 있습니다.
텍스트 인식. 데이터에는 (1) 언어 pre-training 데이터 세트 (80M)의 텍스트를 사용한 합성 렌더링이 포함됩니다. 이는 Kim et al.의 Synthetic Document Generator와 유사하며 다양한 글꼴, 크기, 색상 및 방향의 텍스트와 LAION-2B의 다양한 이미지 배경이 있습니다. (2) 자연 이미지의 OCR (광학 문자 인식) (18M). COYO 및 LAION-2B에서 자연 이미지를 수집하고 Paddle-OCR을 사용하여 텍스트와 경계 상자를 추출하고 텍스트 상자가 없는 이미지를 필터링합니다. (3) 학술 문서 (9M). Nougat에 따라 arXiv에 대한 소스 코드 (LaTeX) 릴리스에서 텍스트, 공식 및 표를 포함한 이미지-텍스트 쌍을 구성합니다. (1)(3)의 경우 Nougat와 동일한 데이터 augmentation을 적용합니다. (2)의 경우 더 공격적인 회전 및 뒤집기 데이터 augmentation 기술을 추가로 사용했습니다.
시각적 접지. GUI 에이전트는 이미지 내의 다양한 요소를 정확하게 이해하고 찾을 수 있는 기능을 갖추는 것이 필수적입니다. CogVLM에 따라 캡션의 엔터티를 경계 상자와 연결하여 위치를 나타내는 LAION-115M에서 샘플링한 이미지-캡션 쌍이 있는 4천만 개의 이미지로 구성된 시각적 접지 데이터 세트를 사용합니다. 경계 상자의 형식은 [[x0, y0, x1, y1]]입니다. 여기서 (x0, y0)과 (x1, y1)은 [000, 999]로 정규화된 왼쪽 상단과 오른쪽 하단 모서리의 좌표를 나타냅니다. 단일 명사구로 여러 객체가 표시되는 경우 해당 상자는 이중 대괄호 안의 세미콜론으로 구분됩니다.
GUI 이미지. 우리의 접근 방식은 주로 자연 이미지를 특징으로 하는 LAION 및 COYO와 같은 데이터 세트에서 GUI 이미지의 부족과 관련성 제한을 혁신적으로 해결합니다. 입력 필드, 하이퍼링크, 아이콘 및 고유한 레이아웃 특성과 같은 고유한 요소가 있는 GUI 이미지는 특수한 처리가 필요합니다. GUI 이미지를 해석하는 모델의 기능을 향상시키기 위해 두 가지 선구적인 GUI 접지 작업을 개념화했습니다. (1) GUI Referring Expression Generation (REG) – 모델이 스크린샷의 지정된 영역을 기반으로 DOM (Document Object Model) 요소에 대한 HTML 코드를 생성하는 작업, (2) GUI Referring Expression Comprehension (REC) – 지정된 DOM 요소에 대한 경계 상자를 만드는 작업. GUI 접지에서 강력한 training을 용이하게 하기 위해 CCS400K (Common Crawl Screenshot 400K) 데이터 세트를 구축했습니다. 이 광범위한 데이터 세트는 최신 Common Crawl 데이터에서 URL을 추출한 다음 400,000개의 웹 페이지 스크린샷을 캡처하여 형성됩니다. 이러한 스크린샷과 함께 Playwright를 사용하여 모든 보이는 DOM 요소와 해당 렌더링된 상자를 컴파일하여 1억 4천만 개의 REC 및 REG 질문-답변 쌍으로 데이터 세트를 보완합니다. 이 풍부한 데이터 세트는 GUI 요소에 대한 포괄적인 training 및 이해를 보장합니다. 과적합의 위험을 완화하기 위해 다양한 기기에서 일반적으로 사용되는 해상도 목록에서 무작위로 선택한 다양한 화면 해상도를 렌더링에 사용합니다. 또한 HTML 코드가 지나치게 광범위하고 다루기 힘들어지는 것을 방지하기 위해 [16]에 설명된 방법에 따라 DOM 요소에서 중복 속성을 생략하여 필요한 데이터 정리를 수행합니다.
또한 pre-training 중에 LAION-2B 및 COYO-700M을 포함한 공개적으로 사용 가능한 텍스트-이미지 데이터 세트를 통합합니다 (깨진 URL, NSFW 이미지, 노이즈가 많은 캡션 및 정치적 편견이 있는 이미지 제거 후).
CogAgent 모델을 총 60,000회 반복하여 pre-train하고 배치 크기는 4,608이고 학습률은 2e-5입니다. 처음 20,000단계에서는 새로 추가된 고해상도 교차 모듈을 제외한 모든 매개변수를 고정하여 총 646M (3.5%)의 학습 가능한 매개변수를 생성한 다음 다음 40,000단계에서는 CogVLM의 visual expert의 고정을 추가로 해제합니다. 예비 실험에서 더 빠른 수렴과 더 안정적인 training으로 이어지는 것을 관찰했기 때문에 먼저 더 쉬운 텍스트 인식 (자연 이미지에 대한 합성 렌더링 및 OCR)과 이미지 캡션에 대해 training한 다음 더 어려운 텍스트 인식 (학술 문서), 접지 데이터 및 웹 페이지 데이터를 순차적으로 통합하여 커리큘럼 학습으로 워밍업합니다.
2.4. 멀티태스크 미세 조정 및 정렬
다양한 작업에 대한 모델의 성능을 향상시키고 GUI 설정에서 자유 형식의 인간 지침에 맞도록 모델을 추가로 미세 조정합니다. 휴대폰과 컴퓨터에서 2,000개가 넘는 스크린샷을 수동으로 수집했으며 각 스크린샷에는 인간 주석자가 질문-답변 형식으로 화면 요소, 잠재적 작업 및 작동 방법에 대한 주석이 달려 있습니다 (자세한 내용은 부록에 설명됨). 또한 웹 및 Android 동작에 중점을 둔 데이터 세트인 Mind2Web 및 AITW를 활용하여 작업, 작업 순서 및 해당 스크린샷을 구성하고 GPT-4를 사용하여 자연어 질문-답변 형식으로 변환합니다. 또한 다양한 작업을 포함하는 여러 공개적으로 사용 가능한 VQA (Visual Question-Answering) 데이터 세트를 정렬 데이터 세트에 통합합니다. 이 단계에서 모든 모델 매개변수를 고정 해제하고 배치 크기 1024 및 학습률 2e-5로 10k 반복에 대해 training합니다.
CogAgent 논문 2장 정리 노트
2. Method
이 장에서는 CogAgent의 구조, 특히 새롭게 도입된 고해상도 cross-module에 대해 소개하고, pre-training 및 alignment 과정을 자세히 설명합니다.
2.1. Architecture
CogAgent는 pre-trained된 VLM을 기반으로 하며, 고해상도 이미지 입력을 처리하기 위해 cross-attention 모듈을 추가했습니다. 기본 VLM으로는 오픈 소스이며 최첨단 large vision-language model인 CogVLM-17B를 사용했습니다.
- 저해상도 이미지 인코더: EVA2-CLIP-E (224x224 픽셀)
- visual-language 디코더: visual expert 모듈이 추가된 pre-trained language model
- 고해상도 이미지 처리: 대부분의 VLM이 저해상도 이미지만 처리 가능한 것과 달리, CogAgent는 고해상도 교차 모듈을 통해 1120x1120 해상도의 이미지까지 처리할 수 있도록 설계되었습니다. 이는 GUI 환경에서 작은 아이콘이나 텍스트를 인식하는 데 중요한 역할을 합니다.
- 고해상도 교차 모듈은 고해상도 이미지를 효율적으로 처리하면서 다양한 VLM 구조에 유연하게 적용 가능하도록 설계되었습니다.
2.2. High-Resolution Cross-Module
- 텍스트 관련 feature 강조: 224x224 해상도의 이미지는 객체와 레이아웃을 효과적으로 표현하기에 충분하지만, 텍스트를 명확하게 렌더링하기에는 부족합니다. 따라서 CogAgent의 고해상도 모듈은 GUI 이해에 필수적인 텍스트 관련 feature에 중점을 둡니다.
- 작은 hidden size 활용: 일반적인 VLM은 큰 hidden size를 필요로 하지만, 텍스트 중심적인 작업 (예: 문서 OCR) 에 특화된 VLM은 더 작은 hidden size로도 충분한 성능을 달성할 수 있습니다.
- 효율적인 계산: 고해상도 교차 모듈은 작은 pre-trained vision 인코더 (EVA2-CLIP-L, 0.30B 매개변수) 와 작은 hidden size의 cross-attention을 사용하여 계산 비용을 절감합니다.
- 기존 모델 활용: 고해상도 이미지의 cross-attention은 저해상도 이미지 feature를 보완하는 역할을 하여, 기존 pre-trained 모델을 효과적으로 활용합니다.
2.3. Pre-training
CogAgent는 고해상도 이미지 이해 능력을 향상시키고 GUI 애플리케이션에 적용하기 위해 다양한 크기, 방향, 글꼴의 텍스트 인식, 이미지 내 텍스트 및 객체 접지, GUI 이미지 (웹 페이지 등) 에 대한 특화된 이해 능력을 중점적으로 pre-training했습니다.
학습 데이터:
- 텍스트 인식: 합성 렌더링 (80M), 자연 이미지 OCR (18M), 학술 문서 (9M)
- 시각적 접지: LAION-115M에서 샘플링한 40M 이미지-캡션 쌍
- GUI 이미지: 웹 페이지 스크린샷 400,000개와 DOM 요소 간의 관계를 학습하는 CCS400K 데이터셋 (1억 4천만 개의 질문-답변 쌍)
- 데이터 augmentation: 텍스트 인식 및 시각적 접지 데이터에 다양한 augmentation 기법 적용
- 과적합 방지: 다양한 화면 해상도 사용, DOM 요소의 중복 속성 제거
- 추가 데이터: LAION-2B, COYO-700M (깨진 URL, NSFW 이미지, 노이즈 캡션, 정치적 편견 이미지 제거 후)
학습 과정:
- 총 60,000회 반복, 배치 크기 4,608, 학습률 2e-5
- 처음 20,000단계: 고해상도 교차 모듈 제외 모든 매개변수 고정 (646M, 3.5% 학습 가능)
- 다음 40,000단계: CogVLM의 visual expert 고정 해제
- 커리큘럼 학습: 쉬운 텍스트 인식 및 이미지 캡션 -> 어려운 텍스트 인식 -> 접지 데이터 -> 웹 페이지 데이터 순으로 학습
2.4. Multi-task Fine-tuning and Alignment
다양한 task에 대한 성능 향상 및 GUI 환경에서 인간의 자유 형식 지침에 대한 적응력을 높이기 위해 광범위한 task에 대해 모델을 미세 조정했습니다.
- 데이터:
- 수동으로 수집한 2,000개 이상의 스크린샷 (화면 요소, 잠재적 task, 작동 방법 주석 포함)
- Mind2Web, AITW (GPT-4를 사용하여 자연어 질문-답변 형식으로 변환)
- 다양한 task를 포괄하는 공개 VQA 데이터 세트
- 학습 과정: 모든 모델 매개변수 고정 해제, 10k 반복, 배치 크기 1024, 학습률 2e-5
3. Experiments
CogAgent의 기본적인 기능과 GUI 관련 성능을 평가하기 위해 다양한 데이터 세트에서 광범위한 실험을 수행했습니다. 먼저 8개의 VQA 벤치마크와 MM-Vet 및 POPE에서 평가를 수행하여 특히 텍스트 인식에 의존하는 모델의 향상된 시각적 이해 능력을 검증합니다. 그런 다음 두 가지 주요 GUI 시나리오인 컴퓨터와 스마트폰을 대표하는 Mind2Web 및 AITW 데이터 세트에서 모델을 평가합니다.
3.1. Foundational Visual Understanding
먼저 광범위한 시각적 장면을 포괄하는 8개의 VQA 벤치마크에서 CogAgent의 기본적인 시각적 이해 능력을 광범위하게 평가합니다. 벤치마크는 VQAv2 및 OK-VQA를 포함한 일반 VQA와 TextVQA, OCR-VQA, ST-VQA, DocVQA, InfoVQA 및 ChartQA를 포함한 텍스트가 풍부한 VQA의 두 가지 범주로 나눌 수 있습니다. 후자의 범주는 문서, 차트, 텍스트가 포함된 사진 등 시각적으로 위치한 텍스트에 대한 이해를 강조합니다. 작업 전반에서 모델의 다양성과 견고성을 입증하기 위해 모든 데이터 세트에서 동시에 모델을 집합적으로 미세 조정하여 단일 일반 모델을 생성합니다. 그런 다음 모든 데이터 세트에서 평가됩니다.
결과는 표 1에 나와 있습니다. 일반 VQA의 경우 CogAgent는 두 데이터 세트 모두에서 최첨단 일반 결과를 달성합니다. 텍스트가 풍부한 VQA의 경우 CogAgent는 6개 벤치마크 중 5개에서 최첨단 결과를 달성하여 일반 경쟁업체 (TextVQA+8.0, ChartQA+2.1, InfoVQA+2.3, DocVQA+16.2)를 크게 능가하고 작업별 최첨단 모델보다 성능이 뛰어납니다. TextVQA(+4.7), STVQA(+0.6) 및 DocVQA(+1.6)에서. 특히 CogAgent가 처음에 기반으로 하는 CogVLM의 일반 결과와 비교할 때 CogAgent는 일반 및 텍스트가 풍부한 VQA 작업 모두에서 특정 개선 사항을 보여 주어 제안된 모델 아키텍처 및 training 방법의 효능을 시사합니다.
또한 대화 질문-답변, 자세한 설명, 복잡한 추론 작업을 포함한 복잡한 작업에서 멀티 모달 기능과 일반화 성능을 측정하는 데 도움이 되는 MM-Vet 및 POPE 데이터 세트에서 모델의 zero-shot 테스트를 수행했습니다. MM-Vet는 복잡한 과제를 처리하는 데 있어 멀티 모달 모델의 숙련도를 평가하기 위해 6가지 핵심 작업으로 설계되었으며 POPE-adversarial은 환각에 대한 민감성에 대한 모델을 평가합니다.
표 2에 자세히 나와 있는 실험 결과는 우리 모델이 두 데이터 세트 모두에서 다른 기존 모델보다 성능이 훨씬 뛰어남을 보여줍니다. 특히 MM-Vet 데이터 세트에서 우리 모델은 52.8이라는 놀라운 점수를 달성하여 가장 가까운 경쟁자인 LLaVA-1.5를 상당한 차이 (+16.5)로 능가했습니다. POPE-adversarial 평가에서 우리 모델은 85.9점을 획득하여 다른 모델에 비해 환각을 탁월하게 처리하는 것으로 나타났습니다.
3.2. GUI Agent: Computer Interface
31개 도메인의 137개 실제 웹사이트에서 수집한 2,000개가 넘는 개방형 작업이 포함된 웹 에이전트용 데이터 세트인 Mind2Web에서 CogAgent를 평가합니다. 작업 설명, 현재 웹페이지 스냅샷 및 이전 작업을 입력으로 제공하면 에이전트는 후속 작업을 예측해야 합니다. 실험에서 Deng et al.의 설정을 따르고 단계 성공률 (단계 SR) 메트릭을 보고합니다.
이 벤치마크에서 여러 language model이 평가되었습니다. 예를 들어 AgentTuning 및 MindAct는 미세 조정된 설정에서 Llama2-70B 및 Flan-T5-XL을 평가했으며 컨텍스트 내 학습 설정에서 GPT-3.5 및 GPT-4를 평가했습니다. 그러나 language model의 입력 모달리티에 의해 제한되어 이러한 모델은 심하게 정리된 HTML만 화면 입력의 표현으로 사용할 수 있었습니다. 우리가 아는 한 이 벤치마크에서 시각 기반 웹 에이전트를 실험한 적이 없습니다.
training 세트에서 모델을 미세 조정하고 세 가지 도메인 외 하위 세트, 즉 교차 웹사이트, 교차 도메인 및 교차 작업에서 평가합니다. 또한 미세 조정된 LLM의 기준선으로 LLaMA2-7B 및 LLaMA2-70B를 추가로 미세 조정하고 Deng et al.과 동일한 HTML 정리 프로세스를 채택합니다. HTML 입력을 구성합니다. 결과는 섹션 3.2에 나와 있습니다. 다른 방법과 비교하여 우리의 접근 방식은 세 가지 하위 집합 모두에서 상당한 성능 향상을 달성하여 CogAgent의 거의 4배 규모인 LLaMA2-70B를 각각 11.6%, 4.7% 및 6.6% 능가했습니다. 이는 모델의 기능뿐만 아니라 컴퓨터 GUI 시나리오에서 visual agent를 사용하는 이점을 반영합니다.
3.3. GUI Agent: Smartphone Interface
다양한 스마트폰 인터페이스와 작업에서 모델을 평가하기 위해 Android 기기 에이전트용 대규모 데이터 세트인 Android in the Wild (AITW) 데이터 세트를 활용합니다. 다양한 Android 버전과 기기 유형을 포괄하는 715k 운영 에피소드로 구성됩니다. 데이터 세트의 각 에피소드는 자연어로 설명된 목표와 그 뒤에 일련의 작업과 해당 스크린샷으로 구성됩니다. training 목표는 주어진 목표, 과거 작업 및 스크린샷을 기반으로 다음 작업을 예측하는 것입니다. 각 작업에 대해 모델은 정확한 작업 유형을 예측해야 합니다. 탭, 스와이프 및 입력의 경우 모델은 각각 입력할 위치, 방향 및 내용을 예측해야 합니다.
두 가지 종류의 기준선과 비교를 수행합니다. 원래 데이터 세트에서 제공하는 UI 요소의 텍스트 설명 (텍스트 OCR 및 아이콘)을 화면 입력의 표현으로 사용하는 language model과 이미지를 화면 입력으로 사용하는 visual-language model. 모든 하위 집합에서 동시에 미세 조정하여 통합 모델을 생성한 다음 모든 테스트 집합에서 평가합니다. GoogleApps 하위 집합이 다른 하위 집합보다 10-100배 크기 때문에 데이터 불균형을 방지하기 위해 10%로 다운샘플링합니다.
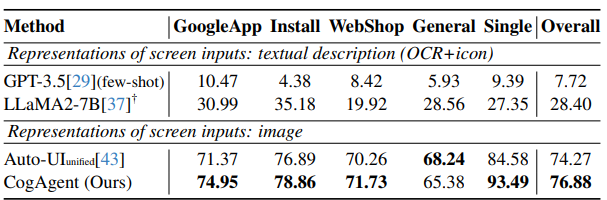
결과는 표 4에 나와 있습니다. CogAgent는 이전의 모든 방법과 비교하여 최첨단 성능을 달성합니다. 언어 기반 방법과 비교할 때 우리 모델은 두 기준선을 모두 큰 차이로 능가합니다. visual-language 기준선인 Auto-UI와 비교할 때 우리 모델은 전반적인 성능에서 +2.61 향상을 달성합니다. 부정확한 경우 수백 건의 사례를 무작위로 샘플링하고 재평가 시 40% 이상이 정확한 것으로 확인됩니다 (자세한 내용은 부록 참조). 이러한 다양성은 모바일 상호 작용에 내재된 여러 유효한 경로에서 발생하여 다양한 응답을 초래합니다.
3. Experiments
CogAgent의 기본적인 기능과 GUI 관련 성능을 평가하기 위해 다양한 데이터 세트에 대한 광범위한 실험을 수행했습니다.
3.1. Foundational Visual Understanding
다양한 시각적 장면을 포괄하는 8개의 VQA 벤치마크를 통해 CogAgent의 기본적인 시각적 이해 능력을 평가했습니다. 벤치마크는 일반 VQA (VQAv2, OK-VQA) 와 텍스트가 풍부한 VQA (TextVQA, OCR-VQA, ST-VQA, DocVQA, InfoVQA, ChartQA) 의 두 가지 범주로 나뉘며, CogAgent는 모든 데이터 세트에서 동시에 fine-tune 되어 단일 generalist model 로 평가되었습니다.
결과적으로 CogAgent는 일반 VQA 와 텍스트가 풍부한 VQA 모두에서 state-of-the-art 를 달성했습니다. 특히, 텍스트가 풍부한 VQA 에서 5개의 벤치마크에서 최첨단 결과를 달성, 일반 경쟁 모델들을 능가했을 뿐만 아니라 task-specific model 들보다도 뛰어난 성능을 보였습니다. 이는 CogAgent 가 기반으로 하는 CogVLM 과 비교했을 때도 일반 및 텍스트가 풍부한 VQA task 모두에서 향상된 성능 을 보여줍니다.
또한, MM-Vet, POPE 데이터 세트 에서 zero-shot test 를 수행하여 CogAgent 가 복잡한 task 에서 멀티 모달 기능과 일반화 성능이 뛰어남을 확인했습니다. 특히, MM-Vet 에서는 52.8점을 달성하여 가장 가까운 경쟁 모델인 LLaVA-1.5 를 +16.5점 차이로 능가했고, POPE-adversarial 평가에서는 85.9점을 달성하여 다른 모델들에 비해 환각을 탁월하게 처리하는 것으로 나타났습니다.
3.2. GUI Agent: Computer Interface
Mind2Web 데이터 세트를 사용하여 CogAgent 를 평가했습니다. 이 데이터 세트는 31개 도메인의 137개 실제 웹 사이트에서 수집된 2,000개 이상의 open-ended task 로 구성되어 있으며, CogAgent 는 task 설명, 웹 페이지 스냅샷, 이전 작업들을 입력으로 받아 다음 작업을 예측해야 합니다. 평가는 Deng et al. 의 설정을 따라 step success rate (step SR) 메트릭을 사용했습니다.
기존 연구에서는 AgentTuning, MindAct 와 같이 Llama2-70B, Flan-T5-XL, GPT-3.5, GPT-4 등의 language model 들이 Mind2Web 에서 평가되었지만, 입력 모달리티의 한계로 인해 정리된 HTML 만 입력으로 사용할 수 있었습니다. 본 연구에서는 처음으로 visually-based web agent 인 CogAgent 를 Mind2Web 에서 평가했습니다.
CogAgent 는 세 가지 out-of-domain 하위 세트 (cross-website, cross-domain, cross-task) 에서 모두 LLaMA2-70B 를 각각 11.6%, 4.7%, 6.6% 능가하는 등 뛰어난 성능 향상 을 보였습니다. 이는 CogAgent 모델의 뛰어난 성능뿐만 아니라 컴퓨터 GUI 환경에서 visual agent 를 사용하는 것의 이점을 보여줍니다.
3.3. GUI Agent: Smartphone Interface
다양한 스마트폰 인터페이스 및 task 에서 CogAgent 를 평가하기 위해 Android in the Wild (AITW) 데이터 세트를 사용했습니다. 이 데이터 세트는 다양한 Android 버전과 기기 유형을 포괄하는 715k operation episodes 로 구성되어 있으며, 각 에피소드는 자연어 목표, 작업 순서, 스크린샷으로 구성됩니다. CogAgent 는 주어진 목표, 과거 작업, 스크린샷을 기반으로 다음 작업을 예측해야 합니다.
두 가지 기준선 과 비교했습니다.
- UI 요소의 텍스트 설명 (텍스트 OCR, 아이콘) 을 입력으로 사용하는 language model
- 이미지를 입력으로 사용하는 visual-language model
GoogleApps 하위 세트 가 다른 하위 세트보다 훨씬 크기 때문에 데이터 불균형을 방지하기 위해 10% 로 down-sampling 했습니다.
결과적으로 CogAgent 는 모든 이전 방법들과 비교하여 최첨단 성능을 달성 했습니다. 특히, 언어 기반 방법들과 비교했을 때 CogAgent 는 두 기준선 모두를 큰 차이로 능가했으며, visual-language 기준선인 Auto-UI 와 비교했을 때는 전반적인 성능에서 +2.61 향상을 달성했습니다. 부정확한 사례들을 무작위로 샘플링하여 재평가한 결과, 40% 이상이 실제로는 다른 정답 인 것으로 확인되었습니다. 이는 스마트폰에서 하나의 기능을 수행하는 데 여러 가지 방법이 존재하기 때문입니다.


